
在树模型建模的过程中的树模型的超参数会影响模型的精度,那么如何调整超参数呢?可以提前限制模型的超参数,也可以在训练模型之后再调整。本文将介绍树模型的预剪枝和后剪枝的实践过程。
原始模型
使用基础数据集和基础的树模型进行训练,然后查看树模型在训练集和测试集的精度:
df = pd.read_csv('https://mirror.coggle.club/dataset/heart.csv')
X = df.drop(columns=['output'])
y = df['output']
x_train,x_test,y_train,y_test = train_test_split(X,y,stratify=y)
clf = tree.DecisionTreeClassifier(random_state=0)
clf.fit(x_train,y_train)
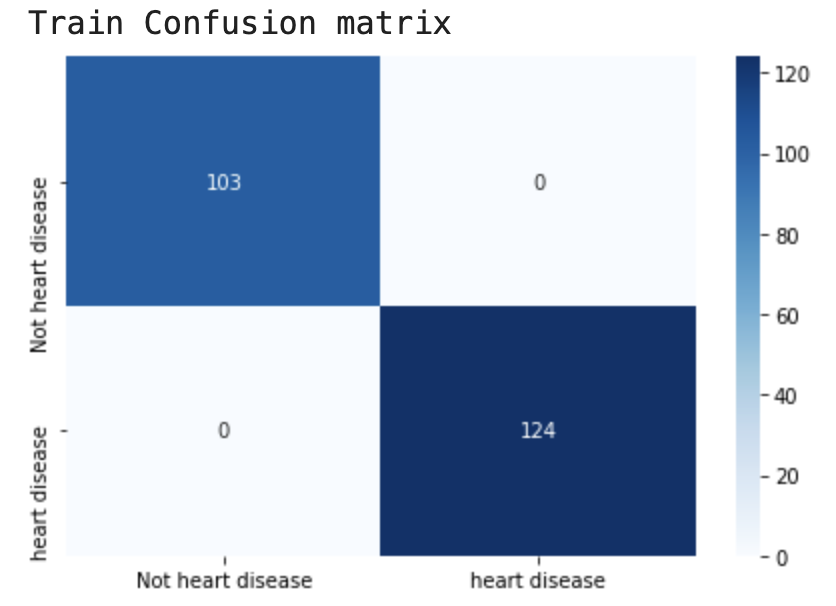
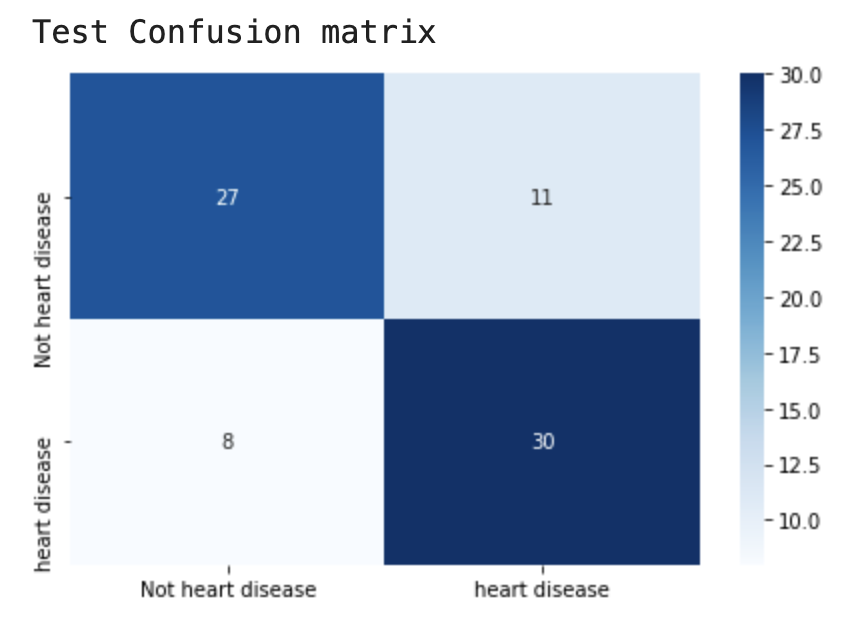
模型在训练集上准确率100%,但在测试集上存在19个错误样本。
预剪枝
预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,如果当前结点的划分不能带来决策树模型泛化性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
停止决策树生长最简单的方法有:
可以调节的对应超参数为:
params = {'max_depth': [2,4,6,8,10,12],
'min_samples_split': [2,3,4],
'min_samples_leaf': [1,2]}
clf = tree.DecisionTreeClassifier()
gcv = GridSearchCV(estimator=clf,param_grid=params)
gcv.fit(x_train,y_train)
model = gcv.best_estimator_
model.fit(x_train,y_train)
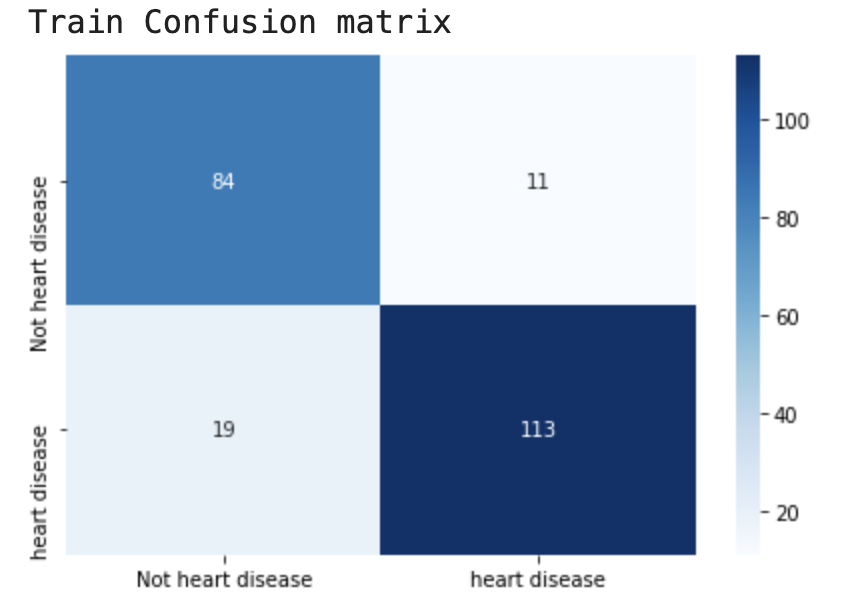
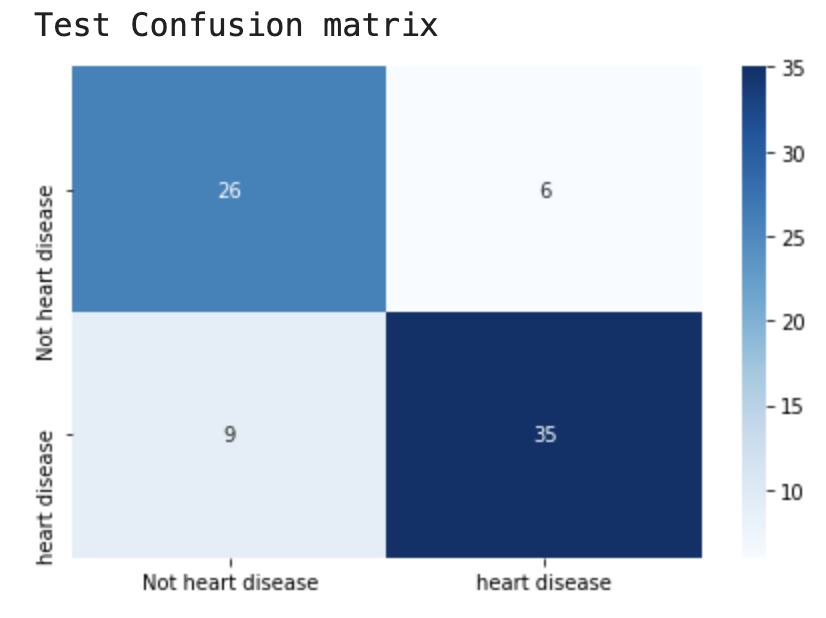
模型在训练集上有30个错误样本,但在测试集上只存在15个错误样本。
后剪枝
使用后剪枝方法需要将数据集分为测试集和训练集。用测试集来判断将这些叶节点合并是否能降低测试误差,如果是的话将合并。
- Reduced-Error Pruning(REP)
- Pesimistic-Error Pruning(PEP)
- Cost-Complexity Pruning(CCP)
CCP对应的超参数为 alpha,我们将获得这棵树的 alpha 值。首先计算可选的alpha,并计算对应的模型的精度。
path = clf.cost_complexity_pruning_path(x_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
clfs = []
for ccp_alpha in ccp_alphas:
clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(x_train, y_train)
clfs.append(clf)
train_acc = []
test_acc = []
for c in clfs:
y_train_pred = c.predict(x_train)
y_test_pred = c.predict(x_test)
train_acc.append(accuracy_score(y_train_pred,y_train))
test_acc.append(accuracy_score(y_test_pred,y_test))
plt.scatter(ccp_alphas,train_acc)
plt.scatter(ccp_alphas,test_acc)
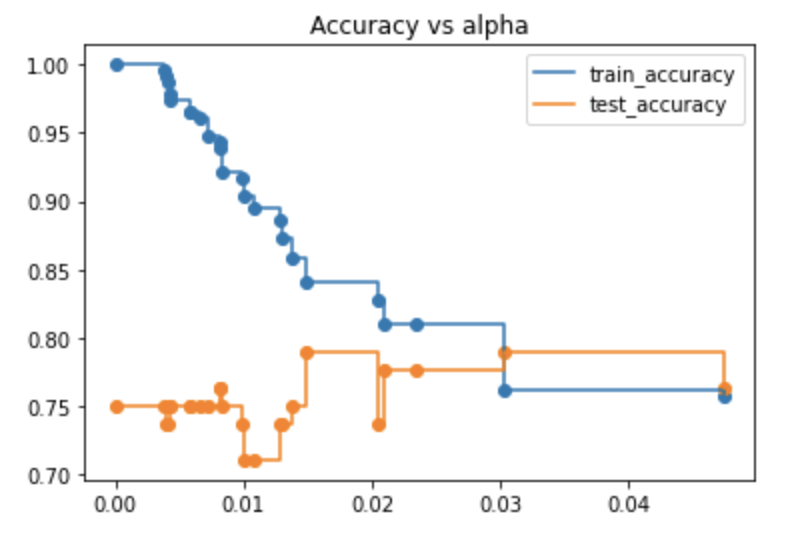
从结果可知如果alpha设置为0.2得到的测试集精度最好,我们将从新训练模型:
clf_ = tree.DecisionTreeClassifier(random_state=0,ccp_alpha=0.020)
clf_.fit(x_train,y_train)
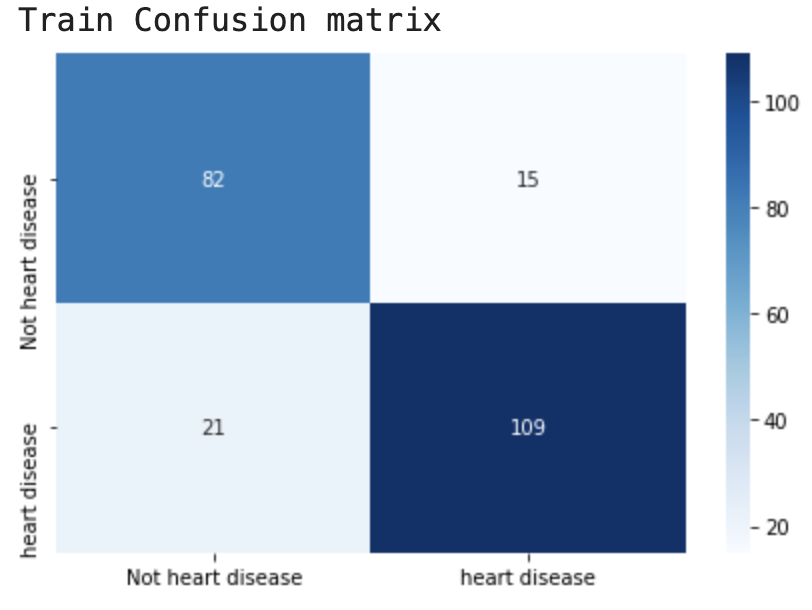
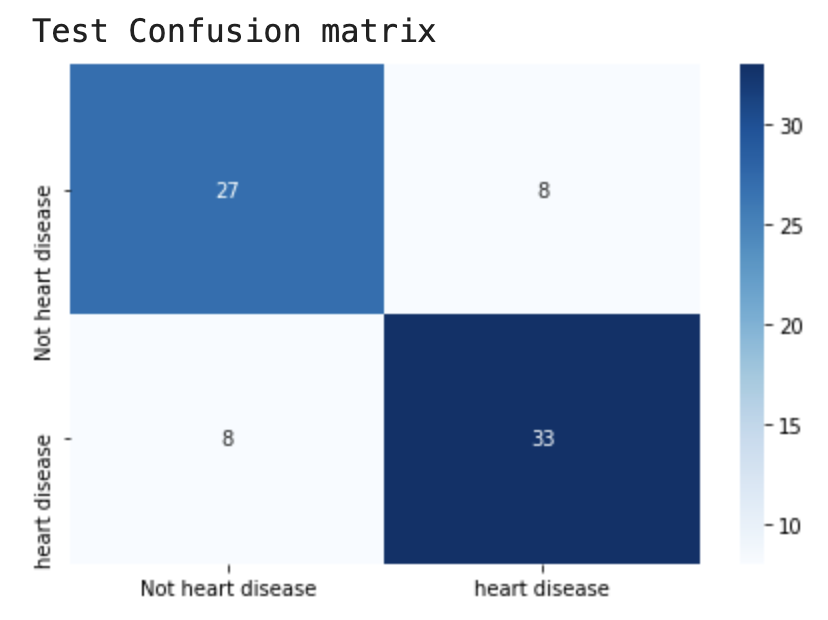
模型在训练集上有36个错误样本,但在测试集上只存在16个错误样本。
进技术交流群请添加AINLP小助手微信(id: ainlp2)
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏








