
本文转载自机器之心
原作者:Sharon Goldman
编辑:蛋酱、杜伟
深度学习未来会更好还是走下坡路?AI 圈先驱们展开了设想。
自 2012 年,以 AlexNet 为代表的深度学习技术突破开始,至今已有 10 年。10 年后,如今已经成为图灵奖得主的 Geoffrey Hinton、Yann LeCun,ImageNet 挑战赛的主要发起人与推动者李飞飞如何看待过去十年的 AI 技术突破?又对接下来十年的技术发展有什么判断?近日,海外媒体 VentureBeat 的一篇专访文章,让 AI 社区开始讨论起这些问题。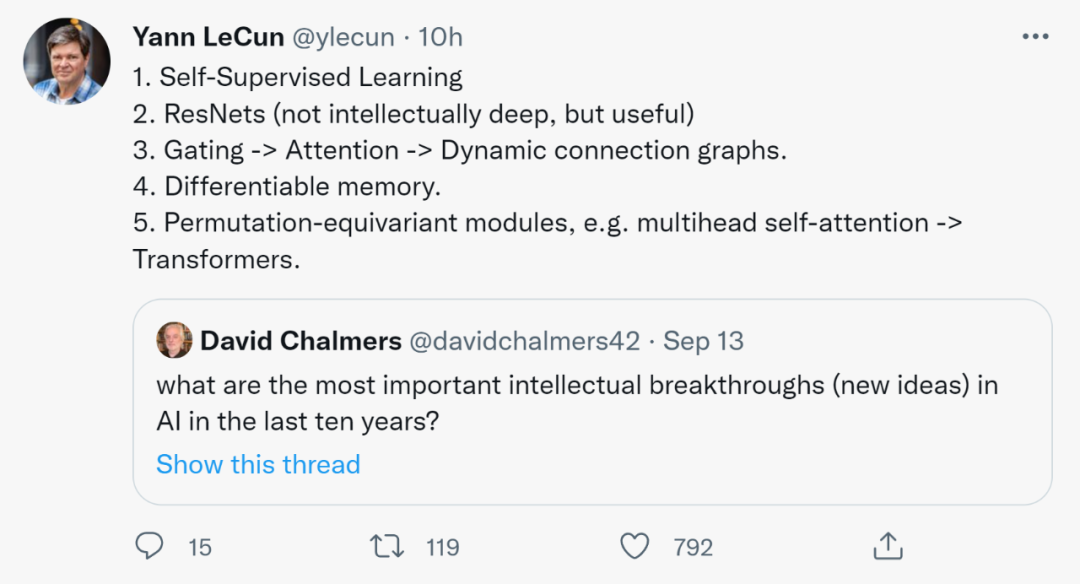
在LeCun看来,过去十年最重要的成果包括自监督学习、ResNets、门-注意力-动态连接图、可微存储和置换等变模块,例如多头自注意力-Transformer。
Hinton 认为,AI 领域的快速发展势头将继续加速。此前,他与其他一些 AI 领域知名人士对「深度学习已经碰壁」这一观点进行了反驳。Hinton 表示,「我们看到机器人领域出现了巨大进步,灵活、敏捷且更顺从的机器人比人类更高效、温和地做事情。」

Geoffrey Hinton。图源:https://www.thestar.com/LeCun 和李飞飞赞同 Hinton 的观点,即 2012 年基于 ImageNet 数据集的一系列开创性研究开启了计算机视觉尤其是深度学习领域的重大进步,将深度学习推向了主流,并引发了一股难以阻挡的发展势头。李飞飞对此表示,自 2012 年以来的深度学习变革是她做梦也想不到的。
李飞飞
不过,成功往往会招致批评。最近,很多观点纷纷指出了深度学习的局限性,认为它的成功仅限于很小的范围。这些观点认为深度学习无法实现其宣称的根本性突破,即最终帮助人类实现期望的通用人工智能,其中 AI 的推理能力真正地类似于人类。
知名 AI 学者、Robust.AI 创始人 Gary Marcus 在今年三月发表了一篇《深度学习撞墙了》的文章,他认为纯粹的端到端深度学习差不多走到尽头了,整个 AI 领域必须要寻找新出路。之后,Hinton 和 LeCun 都对他的观点发起了驳斥,由此更引发了圈内热议。
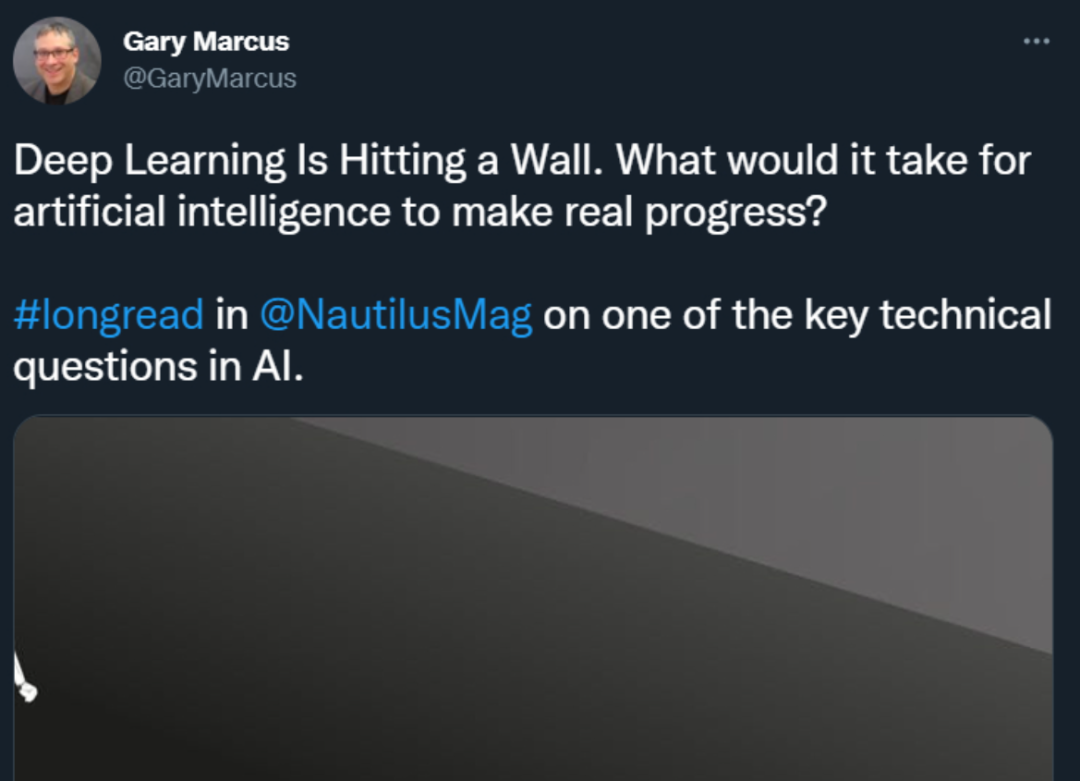
虽然批评的声音不断,但他们不能否认计算机视觉和语言等关键应用已经取得了巨大进展。成千上万的企业也见识到了深度学习的强大力量,并在推荐引擎、翻译软件、聊天机器人以及更多其他领域取得了显著的成果。2022 年了,当我们回顾过往蓬勃发展的 AI 十年,我们能从深度学习的进展中学到什么呢?这一改变世界的变革性技术未来会更好还是走下坡路呢?Hinton、LeCun、李飞飞等人对此发表了自己的看法。一直以来,Hinton 坚信深度学习革命的到来。1986 年,Hinton 等人的论文《Learning representations by back-propagating errors》提出了训练多层神经网络的反向传播算法,他便坚信这就是人工智能的未来。之后,1989 年率先使用反向传播和卷积神经网络的 LeCun 对此表示赞同。Hinton 和 LeCun 以及其他人认为多层神经网络等深度学习架构可以应用于计算机视觉、语音识别、自然语言处理和机器翻译等领域,并生成媲美甚至超越人类专家的结果。与此同时,李飞飞也提出了自己深信不疑的假设,即只要算法正确,ImageNet 数据集将成为推进计算机视觉和深度学习研究的关键。到了 2012 年,Alex Krizhevsky、Ilya Sutskever 和 Hinton 的论文《ImageNet Classification with Deep Convolutional Neural Networks》问世,使用 ImageNet 数据集创建了今天大家非常熟悉的 AlexNet 神经网络架构,并获得了当年的 ImageNet 竞赛冠军。这个在当时具有开创性意义的架构在分类不同的图像方面比以往方法准确得多。
论文地址:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf可以这么说,这项研究在 ImageNet 数据集和更强大 GPU 硬件的加持下,直接促成了下个十年的主要 AI 成功案例,比如 Google Photos、Google Translate、Amazon Alexa、OpenAI DALL-E 和 DeepMind AlphaFold 等。在 AlexNet 推出的 2012 年,也有其他人和机构开始转向深度学习研究领域。Google X 实验室构建了一个由 16000 个计算机处理器组成的神经网络,它具有 10 亿个连接,并逐渐能够识别类猫(cat-like)特征以及高度准确地识别 YouTube 上的猫视频。与此同时,Jeffrey Dean 和 Andrew Ng 也在大规模图像识别领域进行突破性工作。Dan Ciregan 等人中稿 CVPR 2012 的论文显著提高了卷积神经网络在多个图像数据集上的 SOTA 性能。
论文地址:https://arxiv.org/pdf/1202.2745.pdf总而言之,到了 2013 年,「几乎所有的计算机视觉研究都转向了神经网络,」Hinton 说,他从那时起就在 Google Research 和多伦多大学之间分配时间。他补充说,从最近的 2007 年算起,几乎发生了一次人工智能的彻底改变,遥想当时,「在一次会议上发表两篇关于深度学习的论文甚至是不合适的」。李飞飞表示,她深度参与了深度学习的突破——在 2012 年意大利佛罗伦萨会议上亲自宣布了 ImageNet 竞赛的获胜者——人们认识到那一刻的重要性也就不足为奇了。「ImageNet 是一个始于 2006 年的愿景,当时几乎没有人支持,」李飞飞补充说,它后来「在事实上以如此具有历史意义的重大方式获得了回报。」自 2012 年以来,深度学习的发展速度惊人,深度也令人印象深刻。 「有一些障碍正在以令人难以置信的速度被清除,」LeCun 说,他引用了自然语言理解、文本生成翻译和图像合成方面的进展。有些领域的进展甚至比预期中要快。对于 Hinton 来说,这种进展包括在机器翻译中使用神经网络,其在 2014 年取得了长足的进步。「我本认为那会是很多年,」他说。李飞飞也承认了计算机视觉的进步——比如 DALL-E——「比我想象的要快。」然而,并不是所有人都同意深度学习的进展令人瞠目结舌。2012 年 11 月,Gary Marcus 为《纽约客》写了一篇文章,他这么说:「套用一句古老的寓言,Hinton 建造了一个更好的梯子,但更好的梯子并不一定能让你登上月球。」Marcus 认为深度学习没有比十年前更接近「月球」,此处的月球是指通用人工智能或人类水平的人工智能。「当然有进步,但为了登上月球,你必须解决因果理解和自然语言理解及推理,」他说。「在这些事情上没有太大进展。」Marcus 认为将神经网络与符号 AI(在深度学习兴起之前主导该领域的 AI 分支)相结合的混合模型是对抗神经网络极限的前进方向。不过 Hinton 和 LeCun 都驳斥过 Marcus 的批评。「深度学习没有撞墙——如果你看看最近的进展,那真是太棒了,」Hinton 说,尽管他曾承认深度学习在它可以解决的问题范围内是有限的。LeCun 补充说,「没有被撞到的墙」。「我认为有一些障碍需要清除,而这些障碍的解决方案并不完全清楚,」他说。「但我根本没有看到进展放缓…… 进展正在加速。」不过,Bender 并不相信。「在某种程度上,他们只是在谈论根据 ImageNet 等基准提供的标签对图像进行分类的进展,看来 2012 年取得了一些质的突破。但如果他们在谈论比这更宏大的事情,那都是炒作。」
在其他方面,Bender 也认为人工智能和深度学习领域已经走得太远了。「我确实认为,将非常大的数据集处理成可以生成合成文本和图像的系统的能力(计算能力 + 高效算法)已经让我们在几个方面脱轨了,」她说。比如,人们似乎陷入了一个循环:发现模型有偏见,并提议尝试去掉偏见,不过公认的结果是,目前并没有完全去偏见的数据集或模型。此外,她表示希望看到该领域遵守真正的问责标准,无论是针对实际测试还是产品安全——「为此,我们需要广大公众了解以及如何看穿人工智能炒作的说法都处于危险之中,我们将需要有效的监管。」然而,LeCun 指出,这些都是人们倾向于简化的复杂而重要的问题,而且很多人「有恶意的假设」。他坚持认为,大多数公司「实际上都想做正确的事」。此外,他还抱怨了那些不参与人工智能技术和研究的人。「这是一个完整的生态系统,但一些人在看台上射击,」他说,「基本上只是在吸引注意力。」尽管辩论看起来很激烈,但李飞飞强调,这些是科学的全部内容。「科学不是真理,科学是寻求真理的旅程。这是发现和改进的旅程——所以辩论、批评、庆祝都是其中的一部分。」然而,一些辩论和批评让李飞飞觉得「有点做作」,无论是说 AI 都是错误的,还是说 AGI 即将来临,都属于极端情况。「我认为这是一场更深入、更微妙、更细微、更多维度的科学辩论的相对普及版本。」当然,李飞飞指出,在过去十年中,人工智能的进步令人失望——而且并不总是与技术有关。LeCun 承认,一些人们投入大量资源的 AI 挑战尚未得到解决,例如自动驾驶。「我会说其他人低估了它的复杂性,」他说,并补充说他没有将自己归入这一类别。「我知道这很难,而且需要很长时间,」他声称。「我不同意一些人的说法,他们说我们基本上已经弄清楚了…… 这只是让这些模型更大的问题。」事实上,LeCun 最近发布了一份创建「自主机器智能」的蓝图,这也表明他认为当前的人工智能方法并不能达到人类水平的人工智能。但他也看到了深度学习未来的巨大潜力,表示自己最兴奋的是让机器更高效地学习,更像动物和人类。LeCun 表示,对他本人来说,最大的问题是动物学习的基本原则是什么,这也是他一直提倡自监督学习等事物的原因之一。「这一进展将使我们能够构建目前遥不可及的东西,比如可以在日常生活中助力智能系统,就好像它们是人类助手一样。这是我们将需要的东西,因为所有人都将戴上 AR 眼镜,我们将不得不与其互动。」Hinton 同意深度学习正在取得更多进展。除了机器人技术的进步,他还相信神经网络的计算基础设施将会有另一个突破,因为目前的设施只是用非常擅长做矩阵乘法器的加速器完成数字计算。他说,对于反向传播,需要将模拟信号转换为数字信号。 「我们会找到在模拟硬件中工作的反向传播的替代方案,」他说。「我非常相信,长远来看我们几乎所有的计算都将以模拟方式完成。」李飞飞认为,对于深度学习的未来,最重要的是交流和教育。「在 Stanford HAI,我们实际上花费了过多的精力来面对商业领袖、政府、政策制定者、媒体、记者和记者以及整个社会,并创建专题讨论会、会议、研讨会、发布政策简报、行业简报。」 对于如此新的技术,李飞飞比较担心的是缺乏背景知识无助于传达对这个时代的更细致和更深思熟虑的描述。对于 Hinton 来说,深度学习在过去十年取得了超出想象的成功,但他也强调了,这种巨大的进步应该被归功于「计算机硬件的进步」。Marcus 是一位批评者的角色,他认为深度学习虽然取得了一些进展,但之后看来这可能是一种不幸。「我认为 2050 年的人们会从 2022 年开始审视这些系统,并且会说:是的,它们很勇敢,但并没有真正发挥作用。」但李飞飞希望过去十年将被铭记为「伟大的数字革命的开端」:「它让所有人而不仅仅是少数人或部分人类的生活和工作更好了。」她还补充道,作为一名科学家,「我永远不会认为今天的深度学习是人工智能探索的终结。」在社会层面,她说她希望将人工智能视为「一种令人难以置信的技术工具,它以最以人为本的方式被开发和使用——我们必须认识到这种工具的深远影响,并接受以人为本的思维框架以及设计和部署人工智能。」最后,李飞飞表示:「我们如何被记住,取决于我们现在正在做什么。」 https://venturebeat.com/business/10-years-on-ai-pioneers-hinton-lecun-li-say-deep-learning-revolution-will-continue/
新版微信更改了公众号推荐规则,不再以时间排序,而是以每位用户的阅读习惯为准进行算法推荐。在此情况下,学术头条和“学术菌”们的见面有如鹊桥相会一样难得(泪目)
那么,如果在不得不屈服于大数据的当下,你还想保留自己的阅读热忱,和学术头条建立长期的暧昧交流关系,将学术头条纳入【星标】,茫茫人海中也定能相遇~
点这里👇关注我,记得标星~










