
锂离子电池的精确寿命预测对于高效电池开发至关重要,从而实现盈利的电动汽车和向零排放移动性的可持续转型。然而,由于锂离子电池的复杂退化,受到电池设计以及操作和存储条件的强烈影响,限制仍然存在。寿命预测的建模方法从物理化学模型到经验模型都有。这些模型通常由一个单一的函数组成,该函数源自主要的退化机制并适合老化数据。然而,由于对老化机制的了解有限,这些预定义的函数会损害模型的通用性。
为了克服这些问题,德国斯图加特大学Kai Schofer课题组开发了一个基于遗传编程的符号回归的机器学习框架。这种演化算法能够从电池老化数据中推断出物理上可解释的模型,而不需要领域知识。本工作将这种新的方法与案例研究中已有的方法进行了比较,这些案例代表了基于104个汽车锂离子电池周期和日历老化数据的寿命预测的常见任务。平均而言,对存储时间和能量吞吐量的推断的预测精度分别提高了38%和13%。对于其他应力因素的预测,误差减少高达77%。此外,演化生成的老化模型满足了关于适用性、可推广性和可解释性的要求。这突出了演化算法在提高电池老化预测以及洞察力方面的潜力。相关论文以题为:“Machine Learning-Based Lifetime Prediction of Lithium-Ion Cells”发表在Advance Science上。

· 为了克服当前对电池老化的理解所带来的限制,本工作创新性的将演化算法引入锂离子电池的寿命预测中,大大提高了预测精度。
· 本工作表明,这种新颖的方法通过执行多个演化过程,从随机生成的初始模型中可靠地开发出具有高预测精度和低复杂性的老化模型。
· 本工作通过案例研究来评估这种方法,这些案例研究代表了寿命预测的常见任务。使用统一的建模方法在每个类别中取得有竞争力的结果强调了本工作方法的多功能性和稳定性。
日历和周期老化通常单独研究和建模,然后通过叠加组合。为了对建模方法进行详尽的比较,本工作使用来自具有质量和范围代表车辆开发的实验的数据。为了在不需要先验领域知识的情况下推断模型结构和参数,这项工作通过遗传编程实现了多基因符号回归,作为寿命预测机器学习框架的核心。
遗传编程是演化算法的一个子类,它是受达尔文生物演化理论启发的随机优化算法。它们的共同概念是由优化问题的可能解决方案(个体)组成的群体的世代演化。在多基因符号回归中,这些个体是通常表示为一个或多个缩放树和一个偏差项的数学方程。每棵树都由作为外部节点的数值常数和变量以及作为内部节点的数学运算组成。这个概念在图1中以典型的半经验日历老化模型为例进行了展示。为了进一步降低非确定性算法带来的风险,每个阶段都在两个独立的实验中进行评估。在每个阶段之后,选择机制旨在选择更合适的实验。
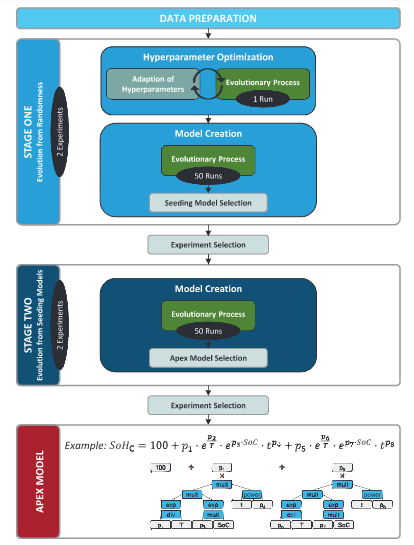
图1. 演化生成寿命预测模型的框架结构
本工作在案例研究中评估建模方法,以便对预测性能进行详尽且公正的检查。每个案例研究由各种测试用例组成,它们代表了日历和循环老化寿命预测的主要任务。为此,老化数据按照实验部分的说明进行准备,并分为不同的训练、验证和测试集。日历老化案例研究检查存储时间的外推(图2a)和存储条件的预测(图2b):虽然测试案例Cal Int1和Cal Int2研究存储条件之间的插值,但Cal ExtT和Cal ExtSoC分别研究了T和SoC的外推。在图2中,本工作框架的预测错误通过顶点模型的交叉和代表选择风险的框来可视化。对于大多数测试用例,多阶段算法结构和精心选择机制的结合确保了几乎可以忽略不计的选择风险,因此具有很高的可靠性。
与(半)经验基准模型的比较显示,在存储时间(图2a)和 ETP(图2c)中外推的平均改进分别为38%和13%。此外,日历老化的适度插值(Cal Int1)和组合预测(Cal Ext20/Int2)(图2b)分别提高了58%和30%。这些进步源于对应力因素的更好考虑,如图3中Cal Ext50的示例所示。该测试用例的顶点模型描述了SoHC对温度和SoC(日历老化的主要压力因素)的依赖性,比半经验基准模型在学习和测试数据方面更加准确。本工作的方法带来的性能改进不仅使预测更加准确,而且大大减少了测试工作量。此外,通过改进对不同操作和存储条件对电池老化的影响的预测,更复杂的电池操作策略成为可能。
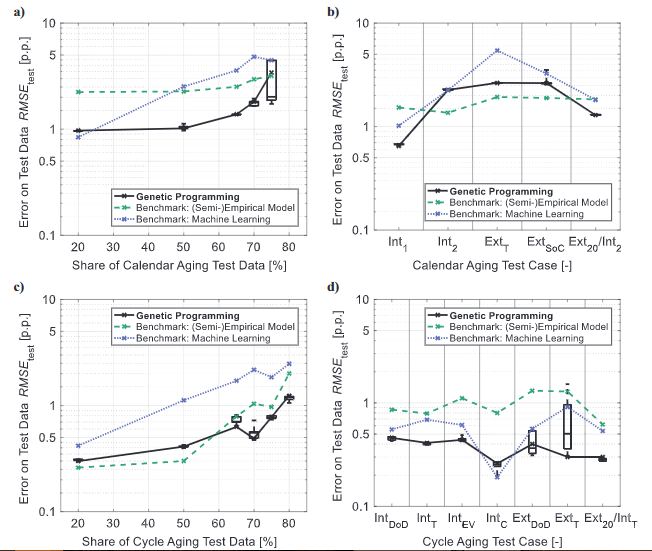
图2. 案例研究的结果:寿命预测的典型任务
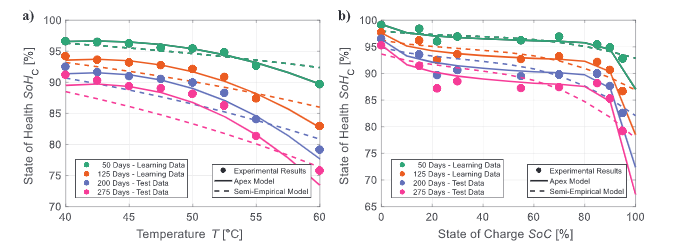
图3. 应力因素的表示
为了在车辆开发中实现这些优势,顶点模型需要满足适用性和通用性的要求。此外,它们必须显示出可解释性的潜力,以便对电池老化产生新的见解。因此,下面对演化的老化模型的评价主要集中在这三个方面。
首先是模型适用性。在车辆开发中,运行配置文件的负载集合经常用于寿命预测。如图4中Cal Ext20顶点模型的温度依赖性示例所示,所有老化趋势在相同负载点处收敛到相同的SoHC。这种交换行为出现在所有压力因素和研究的测试用例中。因此,本工作的框架生成的模型可以被认为是路径独立的,并用于分析负载集合。
其次是模型普遍性。可用数据的结果表明,本工作的算法可以灵活地为各种用例开发通用性良好的模型:每个测试用例的顶点模型代表一般老化趋势而不描述噪声。为了更详细地分析普遍性,对可用数据之外的假设数据进行了老化模拟(图5a),并与普遍接受的物理化学关系(例如阿伦尼乌斯温度依赖性)进行了比较。如图5b所示,Cal Ext50的顶点模型准确地拟合了可用的学习和测试数据。然而,对于低于40°C的温度(假设数据),基于Arrhenius依赖关系的半经验模型的相反趋势证明,对远远超出学习相关性的老化条件进行外推可能具有挑战性。本工作发现,混合方法并没有充分发挥本工作算法的潜力,但大大提高了它的鲁棒性。因此,针对机器学习优化的实验有望进一步提高普遍性。
最后是模型可解释性。本工作的算法在物理解释方面显示出巨大的潜力。与随机初始化相比,他们揭示了相似的预测准确性,但也增加了选择风险。这可能是由于播种而将搜索空间过快地限制在局部最优值。然而,这项研究的顶点模型类似于种子模型,因此突出了用本工作的算法增强现有理论的机会。因此,未来更好地整合领域知识的工作可以促进对各种老化条件对电池老化的影响的新见解。
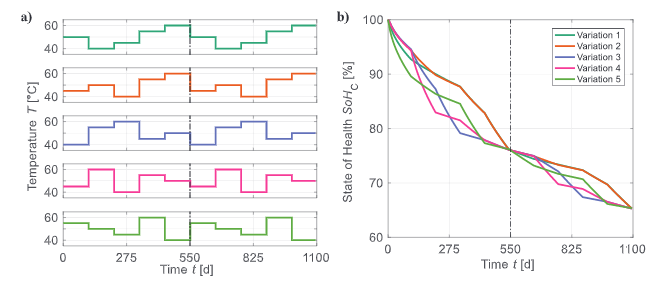
图4. 演化生成寿命预测模型的路径独立性验证
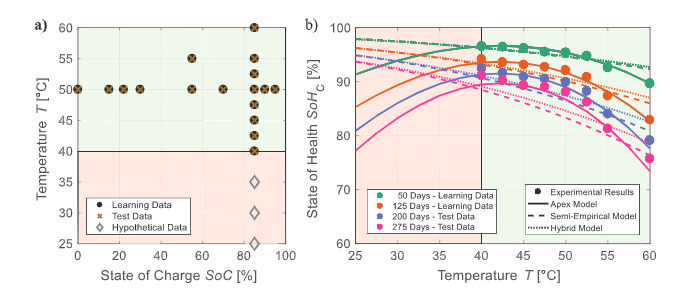
图5. 日历老化模型的普遍性
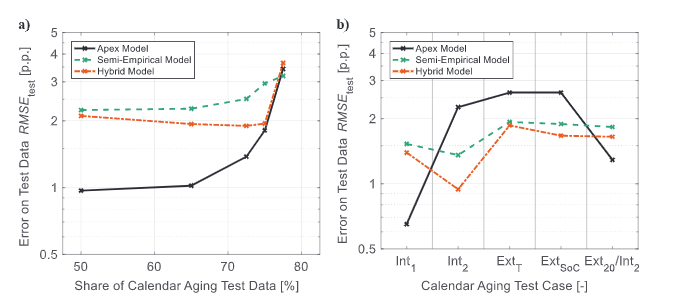
图6. 杂交的预测性能
在本工作的框架下,本工作通过遗传编程引入符号回归,作为锂离子电池寿命预测的一种有前途的方法。本工作的框架应用演化概念从随机性中生成老化模型。为此,它使用汽车锂离子软包电池(石墨/NMC)的常规日历和循环老化数据来代表典型客户行为的条件。与最先进的半经验模型和常见的机器学习方法相比,调查寿命预测相关任务的案例研究揭示了显著提高的预测准确性。虽然研究的数据集对于电池老化来说很大,但它们不利于机器学习。尽管如此,与最佳适用的半经验模型相比,对于存储时间和ETP的外推,预测准确度平均分别提高了38%和13%。对于其他压力因素的预测,可实现高达77%的改进。这是可能的,因为可以更好地表示各种压力因素的相互依赖影响。由于本工作的数据驱动建模概念还满足适用性和通用性的要求,它可以实现更高效的电池开发和更复杂的操作策略。此外,演化生成模型的可解释性使本工作的新方法能够增强对电池衰老的理解。总的来说,这项工作突出了数据驱动建模的潜力,不仅可以解决锂离子电池的老化问题,还可以解决目前受领域知识不足限制的其他复杂问题。
第一作者:Kai Schofer
通讯作者:Kai Schofer
通讯单位:德国斯图加特大学
论文doi:
https://doi.org/10.1002/advs.202200630
本文由温华供稿。











