最近量化基金蓬勃发展,不少认识的kaggle的朋友都从互联网转去量化年入百万了,入行早的kaggler一年拿几百万的bonus的传说也有。
那么机器学习炒股到底靠不靠谱呢,由于这个行业属于闷声发大财类型的,我问在行业内的朋友,都不能给一个确定的答复。最近kaggle上有很多量化相关的比赛,那么正好可以通过这些量化比赛管中窥豹。
时序比赛的结果通常来说都存在一定的shake(抖动)。我对时序比赛的一贯观点是:好的模型不一定有好的效果,好的效果不一定是好的模型,但是好的模型一定有更大概率取得好的效果。评价shake的比赛,我一般是按照从top里有多少competition GM,master幸存来看的。这里先回顾一下之前统计的信息。
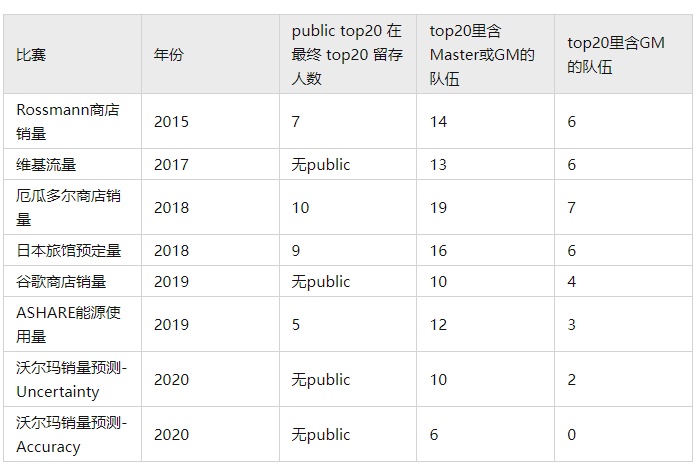
相比于量化,预测网页流量、产品销量等等更容易拿到肯定的效果,因此这些场景本身都存在时间上的周期性,比如白天和晚上,工作日和周末,春夏秋冬,只要抓住这些简单的周期feature,就能确保机器学习模型好于简单的规则,而金融市场的预测并没有这样保底的效果。对于一般的时序比赛,A的模型提升了10%,B的模型提升了9%,结果因为数据的variance是2%,最后test表现上B反超了A,虽然排名上不那么准确,但A和B的模型的都是很有价值的。
想要在时序比赛中的shake幸存,最理想的是甩开其他对手一大截。我目前所认识的套路有两种,一个是metric优化,因为lgb这一类树模型在回归问题只对类MSE这种表现较好,其他metric表现不佳,通过改为深度学习模型或其他处理技巧可产生显著提升;第二个是过拟合test和train之间的bias,来获取提升。当然如果模型和特征足够强,也可以甩开人一截,但是这在kaggle这里还是比较难的.这几次量化比赛的Metric都比较特别,而且金融场景数据分布变化很大,不知道能否在此做文章。
下面是kaggle量化比赛top里有多少competition GM,master幸存统计情况.还有一些非常早的比赛就不统计了,这里只统计线上infer的比赛。
| 比赛 | 年份 | Metric | top20里含Master或GM的队伍 | top20里含GM的队伍 |
|---|
| Ubiquant | 2022 | Pearson相关系数 | 9 | 1 |
| G-Research | 2022 | Pearson相关系数 | 9 | 0 |
| Optiver | 2021 |
RMSPE | 13 | 4 |
| Jane Street | 2021 | 自定义函数 | 5 | 0 |
| Two Sigma | 2019 | 自定义函数 | 1 | 1 |
从这份统计表里可以看出,表现最稳定的比赛是Optiver,这主要是因为这个比赛有一个leak可挖掘,导致比赛变成没有运气成分,变成了挖掘能力的比拼。从业务角度来说这个比赛方案没有意义,从竞技角度来说这个比赛最考验参赛者的能力:我个人的观点如果这么一个明显的leak都挖掘不出来,怎么去挖掘金融那些深层次的信息呢,见仁见智吧。其次看起来最靠谱的居然是这次的Ubiquant,虽然听说这个比赛过程中,主办方各种坑,被疯狂吐槽,但还是有一部分参赛者克服了这些坑,取得了不错成绩。再来复盘这些比赛的选手,于是点开每个比赛top20的profile,看看他们的过往相关量化及时序比赛的成绩记录:
Ubiquant:首先是Ubiquant的第三名,也是国内参加此次比赛的最高排名的hyd ,kdd2017亚军,在国内比赛圈被称为“把握之神”,最近刚打几个月kaggle就达到了pre-GM的水平,是一位非常擅长在看起来各种不靠谱感觉抽奖的比赛里取得好成绩的玩家,应该对这类数据有独到的研究。第四名cmanning ,也是 G-Research的第四名,连续两个比赛进入奖金区,不能用运气来解释了。第七名Wenrui Kong 和第十三名 Lindada 是职业quant。第十名Jacoby Jaeger ,Optiver第二十五名。十一名 Ouranos ,本次比赛唯一GM,在另一个看似抽奖的时序比赛沃尔玛销量预测M5取得第二名的成绩,这让我要重新评价M5这个比赛了,可能并不是抽奖赛。还有几位top20的参赛者在G-Research取得了top100的成绩。
G-Research:Eduardo Peynetti 的第一名是Optiver的第三名,可见有实力挖得到Optiver的leak的,一样能在没有leak的比赛出成绩,第二名Nathaniel Maddux 是我认为最有含金量时序比赛 Web Traffic Time Series Forecasting 第五名,第十名mark4h则是另一个我过去文章介绍过的shake大赛(四位数样本) vsb的冠军,15名A.Sato 是optiver的第四名。还有几位top20在optiver取得了top100的成绩。
Optiver:前两名是公认实力很强的GM,三四名前面介绍了在接下来的 G-Research取得了很好的成绩。第六名Light 在之前kaggle的两个时序比赛获得第二名。18名是H2Oai的gm,19名M5取得top20,在还有好几个top20在G-Research取得了top100的成绩.
Jane Street & Two Sigma :可能由于这两个比赛与其他比赛间隔时间较长,除了Two Sigma的第二十名是Kaz以外,没有看到这两个比赛的top20在其他量化或时序比赛取得top20.
通过上文的top20的比赛记录分析,可以看出 Ubiquant,G-Research,Optiver这三个间隔时间较短的量化比赛相关性很强,也就是说,在其中一个比赛取得好成绩,也非常有可能在另两个比赛取得不错的成绩。并不像大家印象中的那样是抽奖比赛。通过分析这些量化比赛结果,依然适用我对时序比赛的观点:好的模型不一定有好的效果,好的效果不一定是好的模型,但是好的模型一定有更大概率取得好的效果。当然不用看这些比赛,光看最近一年量化私募疯狂从互联网挖AI人才也能看出没少从AI上吃到甜头了。最近很多认识的kaggler都高薪加入了量化公司,希望他们能用自己的能力在新的领域取得好的成绩。
包大人总结:
最近有很多以前打比赛的朋友转行量化,听说他们都获得了不菲的回报,也在公司用业绩证明了自己。
量化这个行业,有着很大的信息不对称,存在着严重的闷声发大财的现象,当然也有打掉牙往自己肚子里咽的存在。由于行业分散,竞争格局不像互联网这么马太效应,因此各家差异比较大,据我了解作为一个DL研究员,九坤和幻方的工作模式和工作体验就相差极大。
前两天跟一个曾经总榜top3国人第一的大佬交流,Kaggler最近两年成为量化猎头的新宠,这背后除了简历的差异化竞争之外,有一个很大的原因是,量化行业,更接近一个预测预估任务的本质,用互联网的拉通对齐是没法赚钱的。
根据之前的kaggle上的量化比赛来看,很难一招鲜,吃遍天。不给过
可以看出 Ubiquant,G-Research,Optiver这三个间隔时间较短的量化比赛相关性很强,也就是说,在其中一个比赛取得好成绩,也非常有可能在另两个比赛取得不错的成绩。并不像大家印象中的那样是纯抽奖比赛。量化讲究相对优势,持续跑赢,最后搞出一条漂亮的净值曲线。我们通过这些比赛已经能看出十分契合这种现象。







