
碳点作为一种零维发光材料,具备荧光可调、水溶性好、毒性较低、合成简便等优点。近年来,荧光碳点发展迅速,已广泛用于生物传感、细胞成像、药物递送等领域。因此,精确控制碳点合成条件并获得具备良好发光性能的碳点对该领域的发展具有重要意义。近日,华东理工大学钱若灿副教授(李大伟教授和钱若灿副教授课题组)利用XGBoost二叉树算法,构建了可对碳点发光性能进行精准预测的机器学习模型,为简化碳点合成步骤提供了新思路。相关成果发表于美国化学会(ACS)旗下杂志《材料化学》(Chemistry of Materials)。
目前,碳点的主要合成方法包括化学氧化法、水热/溶剂热法、微波辅助法、直接碳化法等。碳点的发光性质受反应条件影响,然而碳点的荧光机制仍有争议,因此通过调节反应参数来获得理想碳点仍然面临挑战,合成过程通常需要进行大量实验,耗时耗力。近年来,人工智能技术发展迅速,支持向量机、随机森林、神经网络等机器学习算法已成功用于物理学、化学和生物学等学科。受到机器学习启发,此前本课题组基于一维卷积神经网络(DCNN)模型对碳点性质进行了预测(Chem. Commun., 2021, 57, 532-535)。如图2所示,将合成条件如反应物质的量、组成原子个数、合成方法、温度、溶剂等作为输入特征,荧光颜色和是否激发依赖作为输出,构建可用于机器学习的数据集,然后将其按训练集:验证集为9:1的比例拆分,输入DCNN模型并进行训练。在对模型的超参数进行网格搜索优化后,模型达到拟合,在验证集上准确率达到0.82。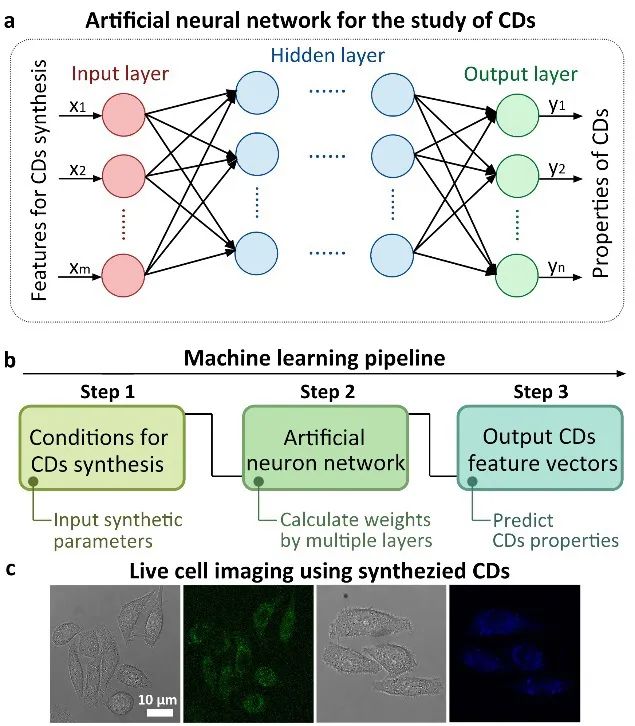
基于上述工作合成碳点,可在设计实验时将各种参数自由组合,用DCNN模型对这些组合进行预测,根据预测结果来设计确定合成方案,有利于减少重复劳动。尽管如此,上述模型准确率仍有待提高,这可能是由于数据集来源于不同文献,合成策略不尽相同,收集的数据难以直接比较。因此,在之前工作的基础上,本工作以对苯醌(PBQ)和乙二胺(EDA)作为碳点前驱体,构建更精准、更适合机器学习的数据集。PBQ可在室温下与EDA发生席夫碱缩合并形成荧光碳点,而前驱体用量、反应时间、溶剂种类都会影响产物的发光性质。因此通过改变合成参数,可在实验室内合成并得到大量发光性质各异的碳点,所构建的数据集更为纯净、可靠。模型采用近年来大放异彩的XGBoost。该算法于2014年被首次提出,在处理中低维数据时拥有无可比拟的优势。如图3所示,本工作在实验室中合成了多达400种碳点,并分别测试得到最大荧光强度。将经过预处理的数据输入到XGBoost模型中进行训练,结果显示模型在训练集和测试集上表现优异。与其他机器学习模型(卷积神经网络,随机森林及支持向量机等)相比,XGBoost拥有最高的决定系数(R2)、皮尔逊相关系数(r)和最低的均方根误差(rmse)。此外,作者利用算法评估了不同输入特征对预测结果的影响,发现PBQ和EDA两种前驱体用量的重要性占比最高,这可能是由于前驱体的结构极大地决定了最后产物的性质。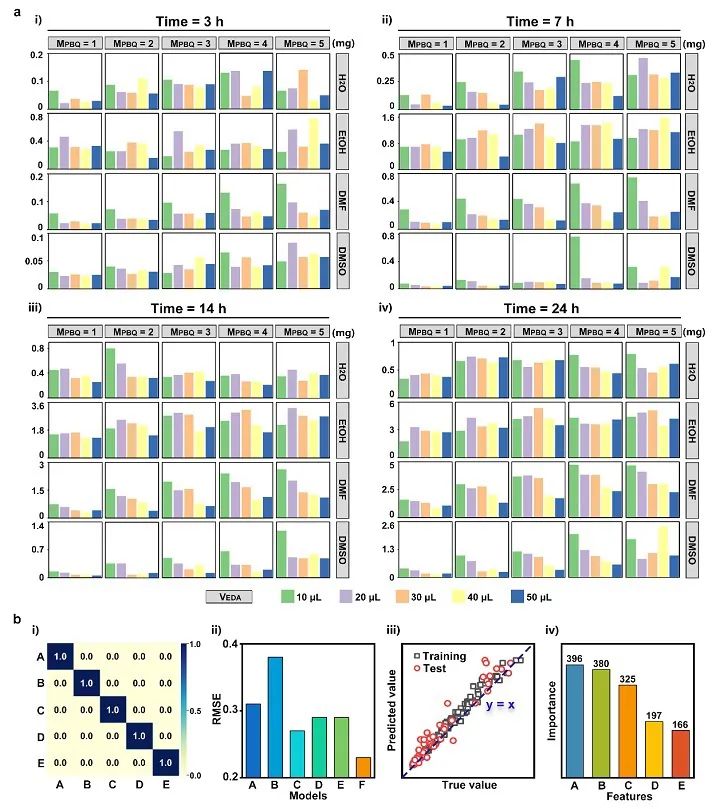
在验证集上成功预测碳点的光学性质后,进一步对模型进行了可视化处理,深入理解模型对于不同输入参数的决策过程。模型一共包含200棵决策树,其中一棵如图4所示,椭圆内数字代表碳点合成过程中的参数选择,最后一行方框内数字代表对应路线的结果,数值越大意味着荧光强度也越大。最后的预测结果由两百棵树加和获得。为了验证模型在实际应用中的效果,作者根据两种前驱体的用量、溶剂和反应时间,共设计了16000种组合,并用经训练的模型对这些参数组合进行预测,挑选其中预测结果显示高荧光强度的参数,然后依据这些参数合成相应碳点,发现其荧光性质与预测结果高度吻合。他们从合成的碳点中筛选了四种性能各异的代表性碳点,分别应用于Fe3+检测、药物缓释、全细胞成像和PVA膜制备(图5),结果显示经机器学习指导合成的碳点性能优异,充分展示了XGBoost模型在定制功能化碳点方面的潜力。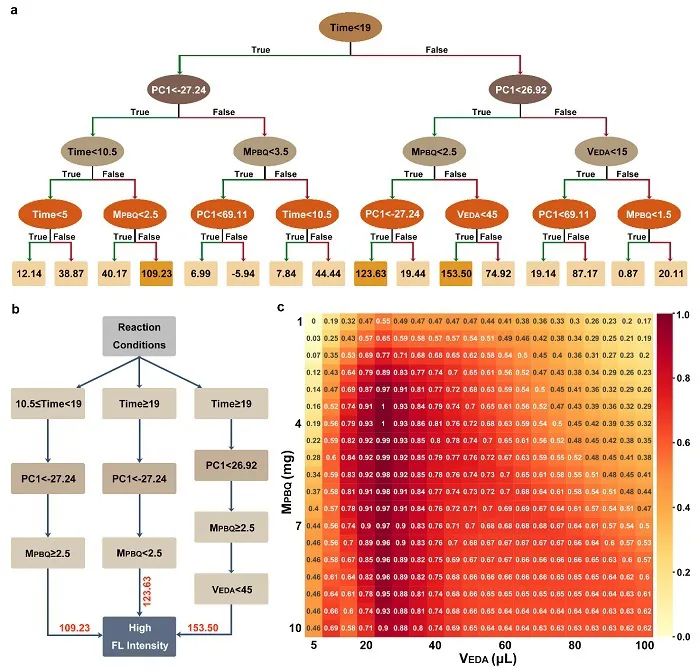
图4. XGBoost模型在荧光强度数据集上的可视化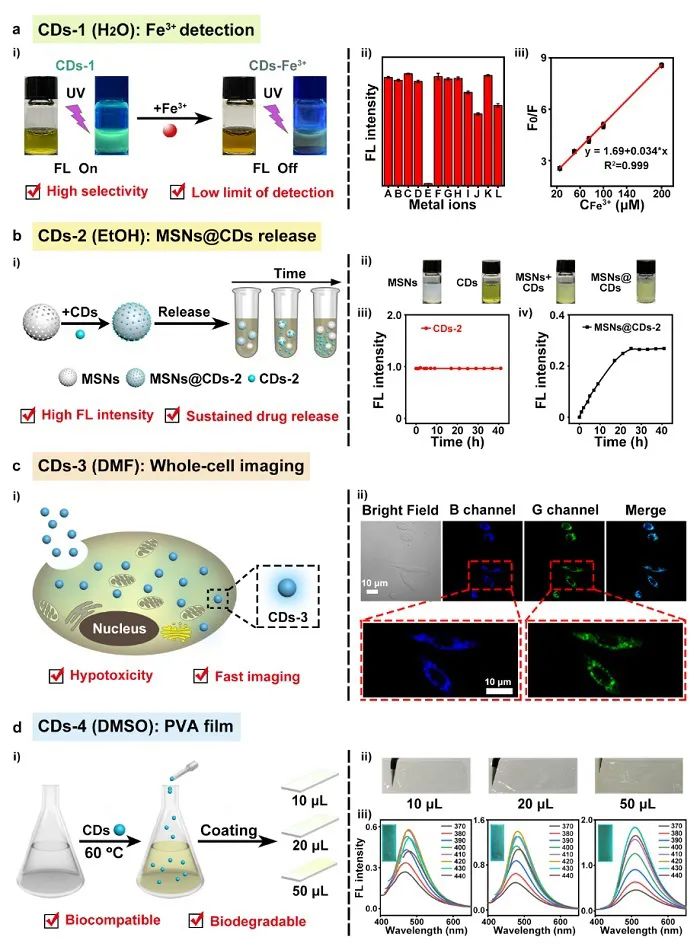
上述研究工作由华东理工大学硕士研究生汪肖原和洪琴在钱若灿副教授指导下完成。洪琴、汪肖原为论文的共同第一作者,钱若灿副教授为单独通讯作者。该工作得到了华东理工大学李大伟教授的建议和帮助,并得到了结构可控先进功能材料及其制备教育部重点实验室、费林加诺贝尔奖科学家联合研究中心的支持以及国家自然科学基金、国家科技重大专项等项目资助。Customized Carbon Dots with Predictable Optical Properties Synthesized at Room Temperature Guided by Machine LearningQin Hong, Xiao-Yuan Wang, Ya-Ting Gao, Jian Lv, Bin-Bin Chen, Da-Wei Li, and Ruo-Can Qian*Chem. Mater., 2022, DOI: 10.1021/acs.chemmater.1c03220https://github.com/xiaoyuan-sudo/CDshttps://github.com/qinhong1/XGBoost/tree/master

钱若灿,华东理工大学化学与分子工程学院副教授。本硕博就读于南京大学化学化工学院,于2014年获分析化学博士学位,同年10月进入华东理工大学化学与分子工程学院从事博士后研究工作,2016年留校任特聘副研究员、硕士生导师,2019年任副教授。在学术方面,一直致力于分析化学与生物学交叉前沿方面的研究,尤其是细胞相关的生命分析。以活细胞为研究对象,借助纳米制备技术和超微电化学调控技术,结合荧光/暗场/单颗粒光谱多通道成像方法,从识别原理、成像模式和信息解析方面进行创新,构建了一系列基于化学纳米制备技术与超微电化学调控的单细胞分析新方法。以第一作者或通讯作者身份在J. Am. Chem. Soc.(3篇)、Angew. Chem. Int. Ed.(2篇)、Anal. Chem.(5篇)等高水平学术期刊上发表论文37篇,其中3篇论文入选Nature Index的Research Highlight专栏。获2016年上海市“晨光学者”称号,国家发明专利授权4项。

李大伟,华东理工大学化学与分子工程学院教授,上海市浦江人才计划入选者(2017年度)。致力于以表面增强拉曼散射为基础,开展环境检测和生物分析新材料、新方法与新器件等研究。在Angew. Chem. Int. Ed.、Anal. Chem.等国际著名学术期刊上发表第一或通讯作者SCI论文60余篇,发表文章近5年被SCI刊物他引近3000次;授权发明专利5项,PCT专利1项;获中国分析测试协会科学技术奖特等奖1项(第三完成人)。

点击“阅读原文”,查看 化学 • 材料 领域所有收录期刊










