HI,大家好,我是晨曦。
这期是晨曦碎碎念的第九期内容,经过上一期,我们构建了机器学习的宏观基础框架。
了解了什么是机器学习、机器学习的分类以及数据挖掘和机器学习的关系等一系列比较基础,但是又总会困扰我们的知识。
接下来,我们就正式进入机器学习各类算法的介绍,而我们今天的主角就是——KNN算法。
本系列推文带有作者强烈的主观认知,欢迎各位在评论区讨论,互相学习,共同进步,本推文中的很多例子来自Machine learning with R。
晨曦碎碎念系列传送门
想白嫖单细胞生信文章?这五大源头数据库,是你发文章的源泉!高频预警!你一定要收藏!
盘活国自然的新思路!你研究的热点真的是热点吗?大数据帮你定位!
好家伙!90%以上审稿人都会问到的问题,今天帮你解决!就是这么齐齐整整!
没想到!生信分组还有这个大坑!你被坑过吗?!
关于富集分析这件事,我有话想说。。。
好御好高级!CNS级别美图是如何炼成的?看这篇就懂了!
化繁为简!一文帮你彻底搞懂机器学习!想发高分文章,这篇是基础!
这里呢,晨曦依旧并不准备论述一些官方的答案,因为这些答案往往各位小伙伴自己私底下可能就已经搜索了很多,这里晨曦想用一个例子概括KNN算法的本质
长有羽毛的鸟往往聚在一起,也就是说相似的事物可能具有相似的属性,正所谓物以类聚,人以群分。
所以,根据上面的思想,KNN算法可以帮助我们对原始数据进行分类,将其放到最相似或者可以说是“最近”的类别中。
晨曦解读
提问:KNN算法属于机器学习分类中的哪个分类?
回答:KNN算法属于机器学习中有监督学习里的分类算法
提问:KNN算法我们应该什么时候去使用?
回答:这个问题其实大家应该在看完后面的内容后会有一个比较深刻的认知,这里晨曦先总一个简单的讲解,我们现在包括以后可能介绍到的一系列算法,其实你个人有选择性的主动使用的机会其实并没有你一开始学习的时候想象的多,更多的时候,这些机器学习的算法和思想会植入在后续分析过程中的每一个可能出现的角落,我们往往只需要去选择方法或者选择某些参数足以
截止到这里,想必各位小伙伴应该对KNN算法有了一个比较笼统或者说比较模糊的概念了吧,那么我们趁热打铁抓紧把概念进行深化,KNN算法的本质其实就是通过分配给有标记的例子来定义未标记的例子
晨曦解读
提问:曦曦,你能说一个生活中的例子来帮助我们更好的理解吗?
回答:比如说我们可以通过KNN算法来预测一个人是否喜欢被推荐的电影、识别遗传数据中的表达模型或者用于检测特定的蛋白质或疾病等等,机器学习并不仅仅只在生信分析中大放异彩,它存在的领域远比我们想象的要广阔。
举个更加生活的例子,大家应该都刷过抖音或者快手,为什么我们感兴趣的内容会持续的给我们推送,为什么我们停留在某个短视频的同时点击搜索会弹出和我们所停留的短视频相关或者说相似的内容呢,这一切的一切其实都是机器学习带给我们的,更确切的说是贝叶斯算法所实现的产物,至于什么是贝叶斯,那就是我们下一期要学习的内容啦~
晨曦解读
提问:曦曦,我知道KNN算法了,那么KNN算法适合什么情况或者说我应该什么时候选择KNN算法呢?
回答:首先我们来解决第一个问题,KNN算法适合特征与目标之间的关系众多、复杂或在其它方面极其难以理解的分类任务,如果上面的不理解,我们就再来直接的总结一下,通俗来说就是一个概念很难定义,但是你一眼看就知道它是什么,那么这个时候KNN算法就会很适合,而我们什么时候选择,大概率KNN算法都会拟合在一些函数或者一些分析流程之中,你所要做的只是顺着流程分析以及选择K值,至于什么是K值以及如何选择,就是我们下面要讨论的内容了
至此,这一部分介绍完毕
滴滴,其实了解完KNN算法的基本概念以后,如果对于过长的文字,各位小伙伴没有看下去的欲望,那么也可以跳过这个阶段,这个阶段我们将举一个生活中的例子来帮助大家更加深刻的理解KNN算法
话说有这么一天,晨曦来到了一家很高级的餐厅吃饭,为什么会说是很高级呢,因为这个餐厅不光贵,同时这个餐厅的用餐方式也十分的特别会把客人的眼睛和耳朵蒙上,然后让客人在这种无视觉和听觉的情况下用餐

这个时候问题自然就来了,这样做会让食物更好吃吗?
显然有可能,但是更多的,晨曦觉得会变得更贵,这个时候服务生端来了一盘菜肴,我吃到嘴里,尽管口感和味道与原本的食材发生了改变,但是我依然知道我吃的番茄,这一个过程我们就可以理解为KNN算法的实现
怎么可以这么理解呢?
我们继续把这个过程细分下去,首先,在我吃这份佳肴之前的十几年我肯定是保持着最少一日三餐的频率(Ps:这可能是个废话~),那么我就已经积累了很多“数据”,这些数据在这里我人为的赋予了它们两种特征——脆度和甜度(即我通过这两个特征就可以定位到我吃的究竟是什么)
并且我通过不断的“学习”(吃饭),显然已经掌握了大部分食材的脆度和甜度的信息,比如说胡萝卜很脆但不是很甜,哈密瓜不是很脆但是很甜等等这些信息,那么我这里就可以绘制一个上述的信息作为我们的一个输入数据(训练集)
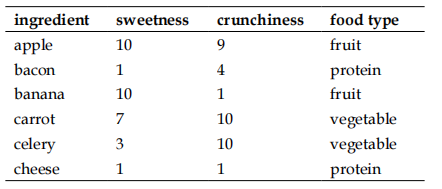
举个例子:苹果甜度为10分,脆度为9分,它属于苹果,这个表格其实就是在我们模型中很常见的一种形式,包含各个特征信息和结局变量的输入数据或者我们可以把它成为训练集
那么我既然接受了这些资料,那么在我把菜肴吃进嘴里后,我的大脑会发生什么事情呢?
其实我们可以这么想,我们的大脑无时无刻都会存在下面这个坐标轴
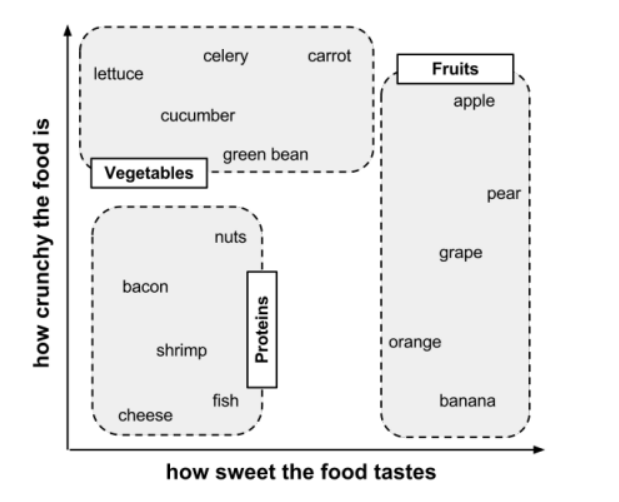
并且我们可以很清楚的看到,相似的食物总会被划分到一起,即苹果、橘子、香蕉都是属于水果的
那么这个时候,我送进嘴里的食物本身就携带着两种特征,这个时候这两种特征所代表的食物也会在这个坐标轴中被定位一个位置,如下所示:
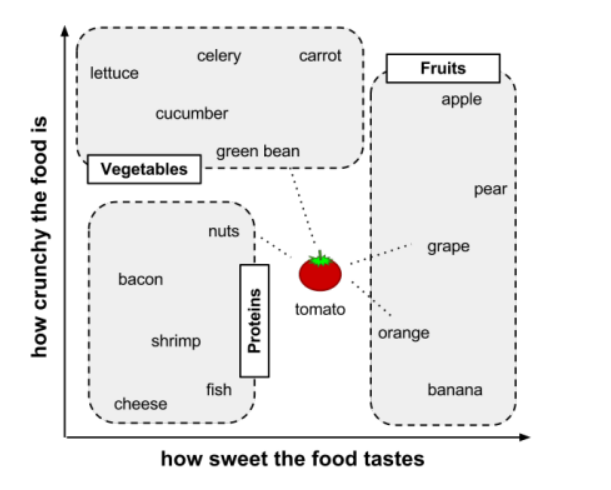
这个时候,我们就可以对我们吃进的食物进行归类了,空间距离最近的就会赋予这个我们食用的食物一个最终结局,很显然,当我们选择唯一最近距离的时候,离水果比较近,所以我们吃的就是水果,而且如果我们知道我们吃的是番茄的话,那么番茄自然就是属于水果的
晨曦解读
提问:那么KNN中的K值是什么意思?
回答:这里我展开说一下,首先当我们计算出距离后,我们为了将番茄进行归类,我们首先需要指定番茄与哪一个单一的物体最为相近,这个被称为1NN分类,也就是K=1的时候得到的,我们可以从图上很清楚的看到,距离orange最近,因为orange归属为水果,所以当K=1的时候,认为番茄是一种水果,那么这时候有意思的事情来了,比如我们让K=3,肯定会获得三个最近的物体,那么该如何选择呢?
比如这里我们让K=3,计算的距离中发现,橘子、葡萄和坚果这三个物体,那么我们就按照最朴素的法则,投票选择,因为有2个水果,所以番茄还是被归类为水果
到这里,我们应该算是对KNN算法有了一个全面的了解了,那么下面就是代码实战部分,同时也会告诉大家如何对K值进行选择
#准备输入数据library(MASS)data(biopsy)#这个数据是用各种特征来预测肿瘤良性/恶性的数据str(biopsy)biopsy #无论机器学习方法是什么,ID变量都应该始终排除,因为ID可以用来唯一地“预测”每个例子。因此,包含标识符的模型很可能会出现过拟合,并且不太可能很好地推广到其他数据#变量进行重命名names(biopsy) = c("thick", "u.size", "u.shape", "adhsn", "s.size", "nucl", "chrom", "n.nuc", "mit", "class")#thick:细胞浓度#u.size:细胞大小均匀度
#u.shape:细胞形状均匀度#adhsn:边黏着度#s.size:但上皮细胞大小#nucl:裸细胞核#chrom:平和染色质#n.nuc:正常核仁#mit:有丝分裂状态#class:结局指标(良性&恶性)#去除缺失值df #观察终点结局table(df$class)#benign malignant # 444 239
许多R机器学习分类器要求将目标特征编码为一个因子,因此我们需要重新编码诊断变量。我们还将借此机会使用标签参数为benign和malignant值提供更多信息的标签
#结局变量因子化df$class #观察结局变量占比round(prop.table(table(df$class)) * 100, digits = 1)
这里我们需要注意,因为kNN的距离计算严重依赖于输入特征的测量尺度,对于我们纳入的特征中数据过大的变量可能会给我们的分类器带来潜在的问题,所以让我们对于过大的变量应该归一化来将特征重新缩放到一个标准的值范围内(我们本次选择的特征并没有这种情况,所以不需要标准化)
#参考步骤(本次示例数据并没有运行)#创建函数进行标准化normalize return ((x - min(x)) / (max(x) - min(x)))}#很显然我们标准化并不能只标准一个变量,应该把所有变量一起进行标准化df #当然也有很多现成的函数或者R包可以做到这一点,比如SVA包或者limma包中的函数都有相关的~
尽管所有683 活检都被标记为良性或恶性状态,但预测我们已经知道的情况并不是很有趣
机器学习追求的永远是我们最终形成的算法是否具有泛化性,我们的算法在一个未标记数据的数据集上的表现如何。如果我们有实验室,我们可以将我们的最后生成的算法应用于接下来100个未知癌症状态的测量,看看机器学习者的预测与使用传统方法获得的诊断相比效果如何
但是显然我们目前并没有这样的实验条件,我们可以通过将数据分成两部分来模拟这个场景:一个用于构建kNN模型的训练数据集和一个测试用于估计模型预测精度的数据集
一般来说是训练集占到七成,验证集占到三成
这里我们直接提取这个数据集的前七成也可以,但是我们可以尝试一种更加随机的方式
#构建训练集和测试集set.seed(123) #random number generatorind #这里的sample函数第一个参数正确的形式为1:2,但是也可以简写为2train test str(test) #confirm it worked#分别查看一下训练集和测试集的结局变量分布table(train$class)#benign malignant # 302 172 table(test$class)#benign malignant # 142 67 #两个数据集的比例可以接受,不是那种特别不均衡的情况就可以#我们要想使用KNN算法,我们还需要把结局变量提取出来并且单独存储成因子的形式,但是我们这里也可以不提取,而是在使用KNN算法的时候进行取子集的选择我们已经获得了数据以后,其实我们就可以开始进行后续的KNN部分对于kNN算法,训练阶段实际上不涉及模型构建——训练像kNN这样的懒惰学习者的过程只涉及以结构化格式存储输入数据#使用KNN算法install.packages("class")library(class)#该R包中包含KNN函数#对于测试数据中的每个实例,该函数将使用欧氏距离来识别k个最近邻,其中k是用户指定的数字。测试实例通过在k个最近邻中“投票”进行分类
我们已经有了将kNN算法应用于这些数据所需的几乎所有东西
我们将数据分成训练数据集和测试数据集,每个数据集都具有完全相同的数字特征
训练数据的标签存储在一个单独的因子向量中
唯一剩下的参数是k,至于K值如何选择,我们提出两点建议:
1. k被设置在3到10之间
2. 设置k等于训练示例数量的平方根(由于我们的训练数据包括302个实例,我们可以尝试k=17,大约等于302的平方根)
#加载R包library(gmodels)#我们可以创建一个交叉表,指示两个向量之间的一致性。指定prop.chisq=false将从输出中删除不需要的卡方值CrossTable(x = test$class, y = test_pre, prop.chisq=FALSE)# Cell Contents#|-------------------------|#| N |#| N / Row Total |#| N / Col Total |#| N / Table Total |#|-------------------------|
#Total Observations in Table: 209
# | test_pre
# test$class | benign | malignant | Row Total | #-------------|-----------|-----------|-----------|# benign | 140 | 2 | 142 | # | 0.986 | 0.014 | 0.679 | # | 0.993 | 0.029 | | # | 0.670 | 0.010 | | #-------------|-----------|-----------|-----------|# malignant | 1 | 66 | 67 | # | 0.015 | 0.985 | 0.321 | # | 0.007 | 0.971 | | # | 0.005 | 0.316 | | #-------------|-----------|-----------|-----------|#Column Total | 141 | 68 | 209 | # | 0.675 | 0.325 | | #-------------|-----------|-----------|-----------|
这个结果如何解读呢,我们这就来捋一下表中的单元格百分比表示属于四类的值的比例
在左上角的格子中,是真正的阴性结果。这209个值中的140个表明肿块是良性的病例,并且kNN算法正确地识别了肿块为良性的病例。右下角的格子中,表示真正的阳性结果,其中分类器和临床确定的标记同意该肿块是恶性的。在209个预测中,总共有66个是正确的阳性结果。
落在另一条对角线上的单元格包含了kNN方法与真实标签不一致的例子的计数
左下格子中的1例为假阴性结果;在本例中,预测值为良性,而肿瘤实际上为恶性。在这个方向上犯的错误可能是极其昂贵的,因为它们可能会导致病人相信自己没有癌症,而实际上疾病可能会继续进展。
右上的格子如果有,则会包含假阳性结果。当模型将肿块归类为恶性时,而实际上它是良性的。虽然这些错误不如假阴性结果危险,但也应避免它们,因为它们可能会给卫生保健系统带来额外的经济负担,或给患者带来额外的压力,因为可能需要提供额外的检测或治疗。
#我们可以通过代码判断一下准确性correct = sum(as.numeric(test_pre)==as.numeric(test$class))/nrow(test)correct#[1] 0.9856459#可以很清楚的看到是一个非常高的准确性
总共有2%,即100个质量中有2个被kNN方法错误地分类。虽然对于几行R代码来说,98%的准确率似乎令人印象深刻,但我们可以尝试另一次模型迭代,看看我们是否可以提高性能并减少被错误分类的值的数量,特别是由于错误是危险的假阴性。
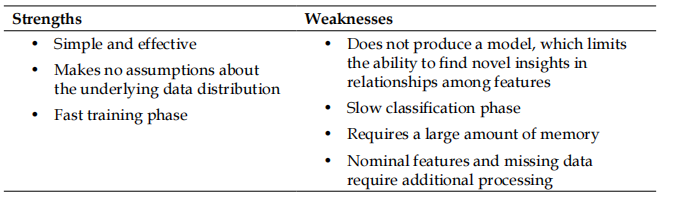
其实到这里我们就已经完成了我们的KNN算法的研究,我们也得到了一个比较好的正确性,尽管KNN算法并不会生成模型,但是我们依旧想要帮这个算法尽可能调整至完美,所以我们接下来可以尝试从两方面进行调整。
#方面一#前面我们应用自定义的函数来标准化我们的数据#归一化用于kNN分类,但它可能并不总是重新缩放特征的最合适的方法。因为z分数标准化值没有预定义的最小值和最大值,所以极值不会被压缩到中心。有人可能会怀疑,对于恶性肿瘤,我们可能会看到一些非常极端的异常值,因为肿瘤的生长无法控制。因此,允许在距离计算中进一步加权异常值可能是合理的,这里就应用到了我们的内置函数scale()函数df_z #然后我们再进行和上述一样的操作即可运用上面这个方法并不是一定能提高准确率,只不过是一个可以修改的方面#方面二#我们可以通过检查k值的不同值的性能来做得更好。使用归一化的训练和测试数据集,使用几个不同的k值对相同的209条记录进行分类。每次迭代都显示了假阴性和假阳性的数量for(i in 1:round(sqrt(dim(train)[1]))) { test_pre = knn(train[, -10], test[, -10], cl = train[, 10],k=i) Freq print(1-sum(diag(Freq))/sum(Freq)) #误差率 }#[1] 0.0430622#[1] 0.03349282#[1] 0.01913876#[1] 0.02870813#[1] 0.02392344#[1] 0.02392344#[1] 0.01435407#[1] 0.01913876#[1] 0.009569378#[1] 0.01435407#[1] 0.01913876#[1] 0.01913876#[1] 0.01435407#[1] 0.01913876#[1] 0.01435407#[1] 0.01435407#[1] 0.01435407#[1] 0.02392344#[1] 0.02392344#[1] 0.02392344#[1] 0.02870813#[1] 0.02870813#但是如果样本数量过大,以上的K值确定方法就比较困难了,也正验证了knn不适合大样本数据的说法#上面的结果是错误率,我们选择最小的对应的K值即可
讲到这里其实整体的KNN算法就结束了,因为KNN并不会生成模型,或者说并不会生成参数,所以这类的分类方M法在临床上运用的并不是十分广泛,因为随时需要储存大量数据本身就是一个不是很方便的方式。
讲到这里大家是不是对KNN算法有了一个更好的理解呢,我们下面再来对KNN算法中的注意事项进行强调
那么,到这里,我们第一种机器学习算法——KNN算法就给给位小伙伴介绍到了这里本篇推文中的内容绝大多数都是晨曦通过学习Machine learning with R以及网络上很多相关资料总结而成,算的上是晨曦的学习笔记了,也欢迎各位小伙伴在评论区讨论哦~Ps:回复“晨曦碎碎念09”可以获得本期推文的全部代码及示例哦~
晨曦单细胞笔记系列传送门
1. 首次揭秘!不做实验也能发10+SCI,CNS级别空间转录组套路全解析(附超详细代码!)
2. 过关神助!99%审稿人必问,多数据集联合分析,你注意到这点了吗?
3. 太猛了!万字长文单细胞分析全流程讲解,看完就能发文章!建议收藏!(附代码)
4. 秀儿!10+生信分析最大的难点在这里!30多种方法怎么选?今天帮你解决!
5. 图好看易上手!没有比它更适合小白入手的单细胞分析了!老实讲,这操作很sao!
6. 毕业救星!这个R包在高分文章常见,实用!好学!
7. 我就不信了,生信分析你能绕开这个问题!今天一次性帮你解决!
晨曦单细胞数据库系列传送门
1. 宝儿,5min掌握一个单细胞数据库,今年国自然就靠它了!(附视频)
2. 审稿人返修让我补单细胞数据咋办?这个神器帮大忙了!
3. 想白嫖、想高大上、想有高大上的SCI?这个单细胞数据库,你肯定用得上!(配视频)
4. What? 扎克伯格投资了这个数据库?炒概念?跨界生信?
5. 不同物种也能合并做生信?给你支个妙招,让数据起死回生!
6. 零成本装逼指南!单细胞时代,教你用单细胞数据库巧筛基因,做科研!
7. 大佬研发的单细胞数据库有多强? 别眼馋 CNS美图了!零基础的小白也能10分钟学会!
8. 纯生信发14分NC的单细胞测序文章,这个北大的发文套路,你可以试下!实在不行,拿来挖挖数据也行!
9. 如何最短时间极简白嫖单细胞分析?不只是肿瘤方向!十分钟教你学会!
10. 生信数据挖掘新风口!这个单细胞免疫数据库帮你一网打尽了!SCI的发文源头!

欢迎大家关注解螺旋生信频道-挑圈联靠公号~