欢迎大家关注有三AI的视频课程系列,我们的视频课程系列共分为5层境界,内容和学习路线图如下:
第1层:掌握学习算法必要的预备知识,包括Python编程,深度学习基础,数据使用,框架使用。
第2层:掌握CV算法最底层的能力,包括模型设计基础,图像分类。
第3层:掌握CV算法最核心的方向,包括图像分割,目标检测,图像生成,目标跟踪。
第4层:掌握CV算法最核心的应用,包括人脸图像,图像质量,视频分析,图像编辑。
第5层:掌握算法落地的关键技术,包括模型优化,模型部署。
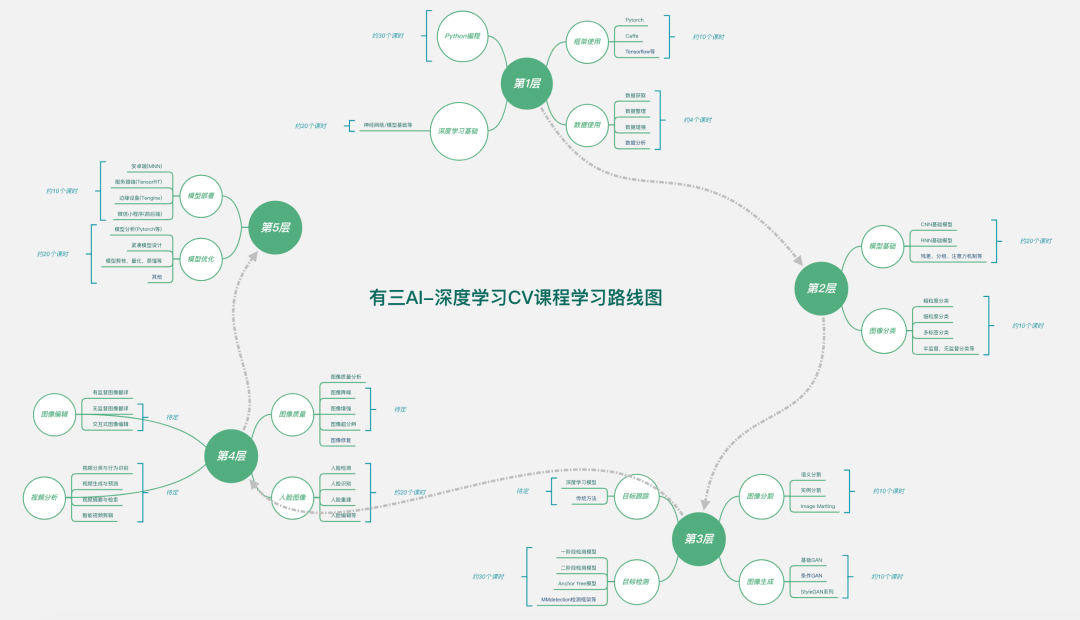
其中部分课程的主体内容已经更新完毕,比如数据使用/图像分类/图像分割/目标检测/图像生成/视频分类;部分课程正在重制更新中,比如模型优化/模型部署,部分课程正在计划上线中,比如图像编辑/视频分析,请大家及时关注!
本次给大家介绍的课程内容是《深度学习之视频分类》,目标是帮助大家掌握好基于深度学习的视频分类与行为识别相关模型的理论与实践。
随着图像识别相关领域的研究与应用逐渐成熟,当下视频分析相关的研究和应用所占比例越来越大,其技术也更加复杂。视频分类和行为识别在视频监控与检索,网络直播、推荐系统等行业中有着广泛的应用,是深度学习在视频分析领域中最底层的问题之一,非常值得关注和学习。
为了帮助初学者深入学习视频分类与行为识别相关内容,本次推出了《深度学习之视频分类》系列课程,目前已完成约5个小时的理论课与实践课程,并仍在持续更新中,为学员深入解读视频分类基础理论原理及经典网络结构,经合实际项目,将所学理论应用于实践。
子欲学视频处理,视频分类与行为识别是必学基础!我们这一门课期望帮大家彻底搞定视频分类与行为识别的学习问题!下面请听课程的详细介绍!
本课程内容将包括视频分类的各个经典算法理论与实践,下面是当前已有课程的大纲脑图(本月还在持续新增内容,请大家保持关注):
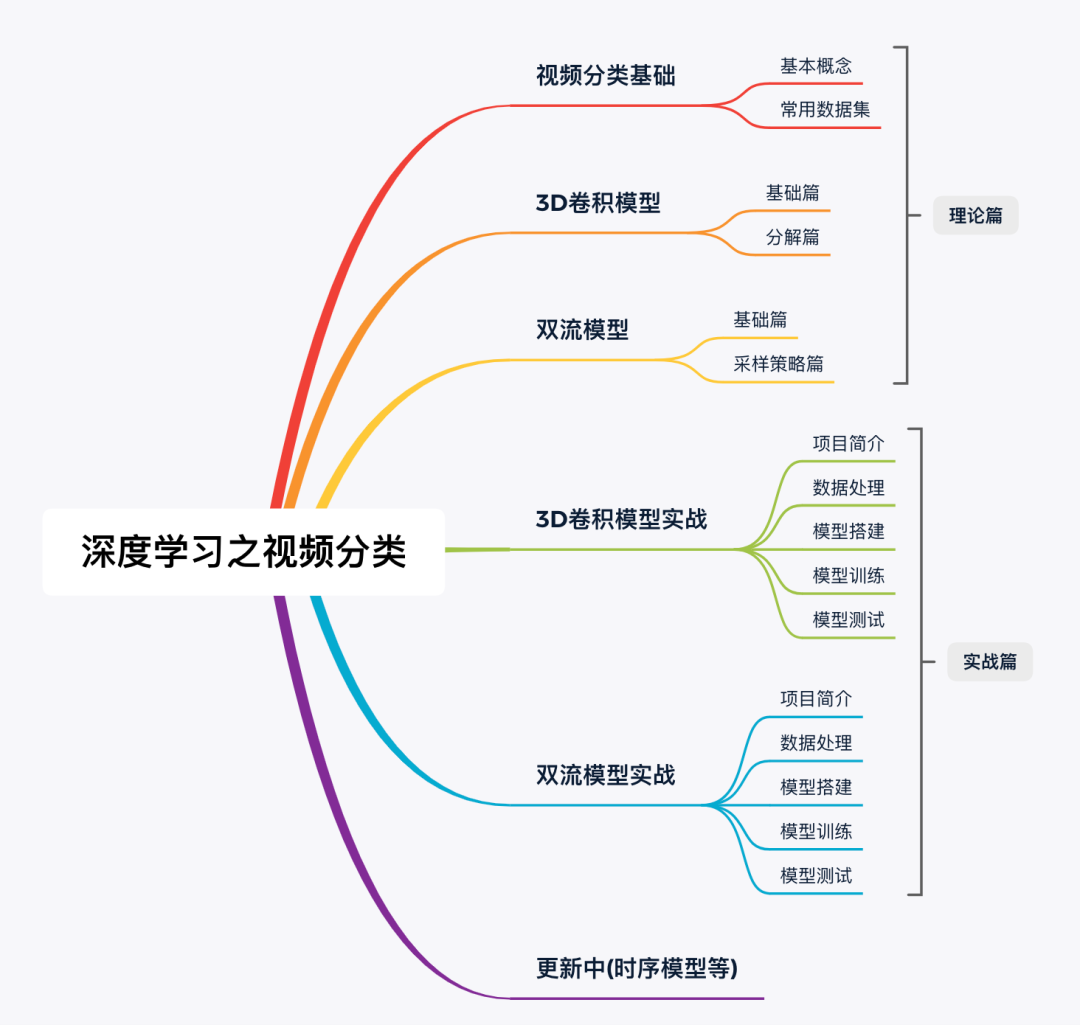
(1) 理论部分内容包括:涵盖了深度学习之视频分类的主要模型,如3D卷积模型,双流模型,RNN时序模型等,既有足够的宽度,也具备有足够的深度。我们会非常详细地讲解算法中的细节,帮助彻底消化算法原理;
(2) 实践非常丰富。本次课程中一共已经包含了2个实践案例,分别为基于3D卷积模型的视频分类实战,基于双流模型的视频分类实战,后续还会增加其他方向的实战内容,1个案例结果图如下:

下面简单了解一下各部分的内容:
(1) 视频分类基础讲解,包括视频分类的基本概念,常见数据集介绍,约20分钟,本部分内容可以免费收听。

(2) 3D卷积模型(基础篇),包括3D卷积原理,基础3D卷积模型与深度3D卷积模型,约30分钟,本部分内容可以免费收听。
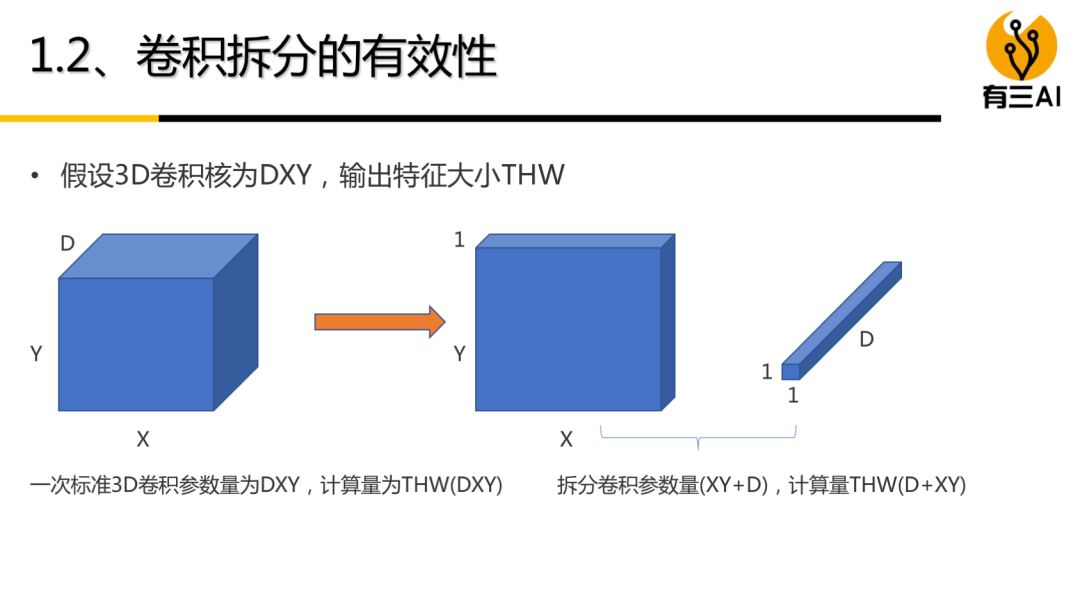
(3) 3D卷积模型(分解篇),包括卷积拆分原理,经典的3D卷积分解模型及其探索,约40分钟。
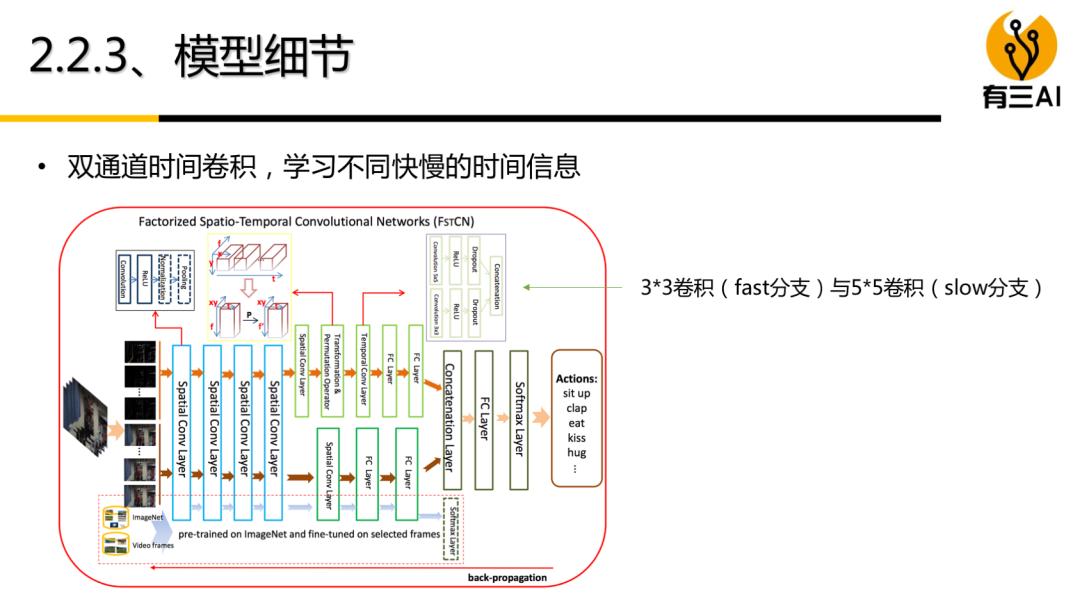
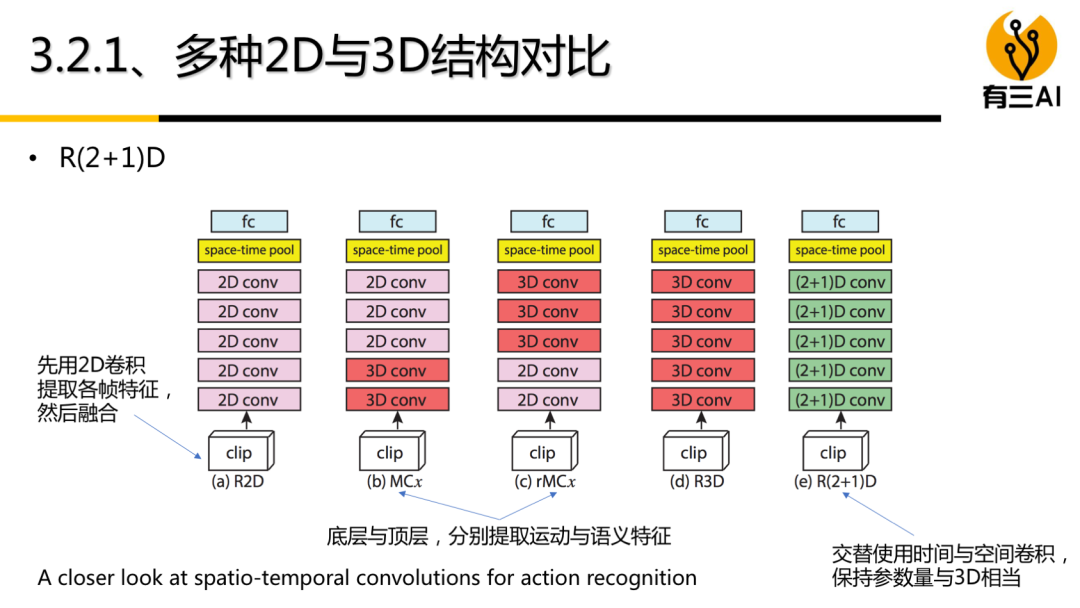
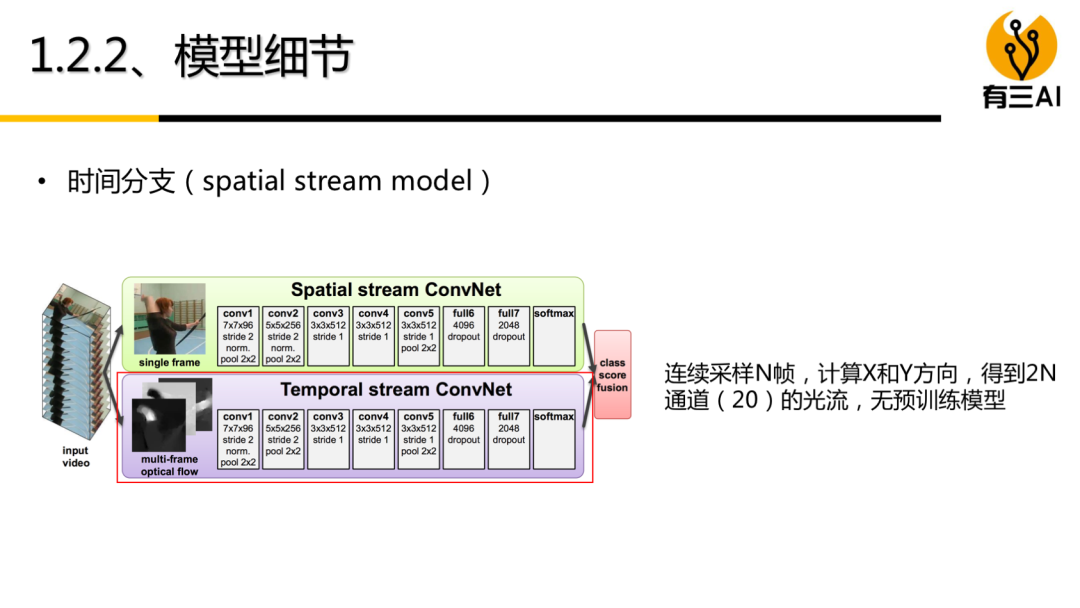
(4) 双流模型(基础篇)讲解,包括基本的双流模型,双流模型融合策略,3D双流模型,约30分钟。
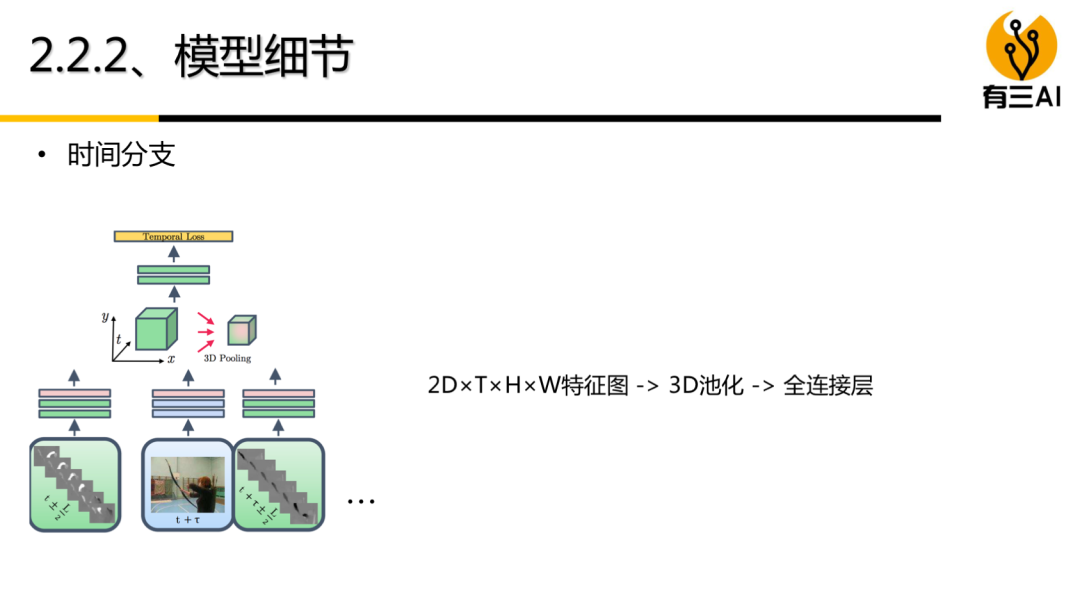
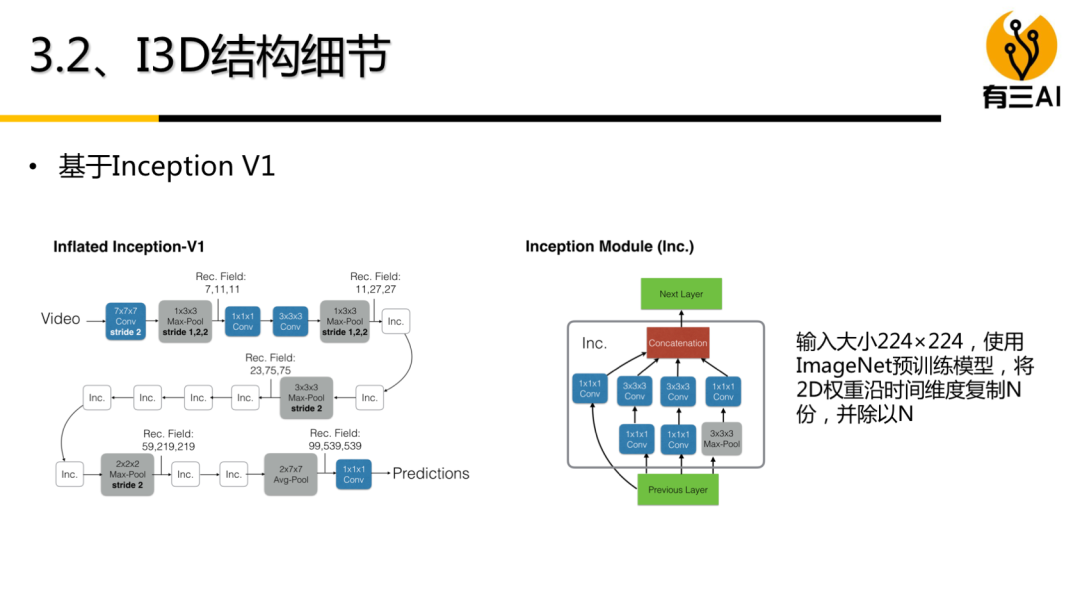
(5) 双流模型(采样篇)讲解,包括时序分段采样模型,时序分频采样模型,约35分钟。

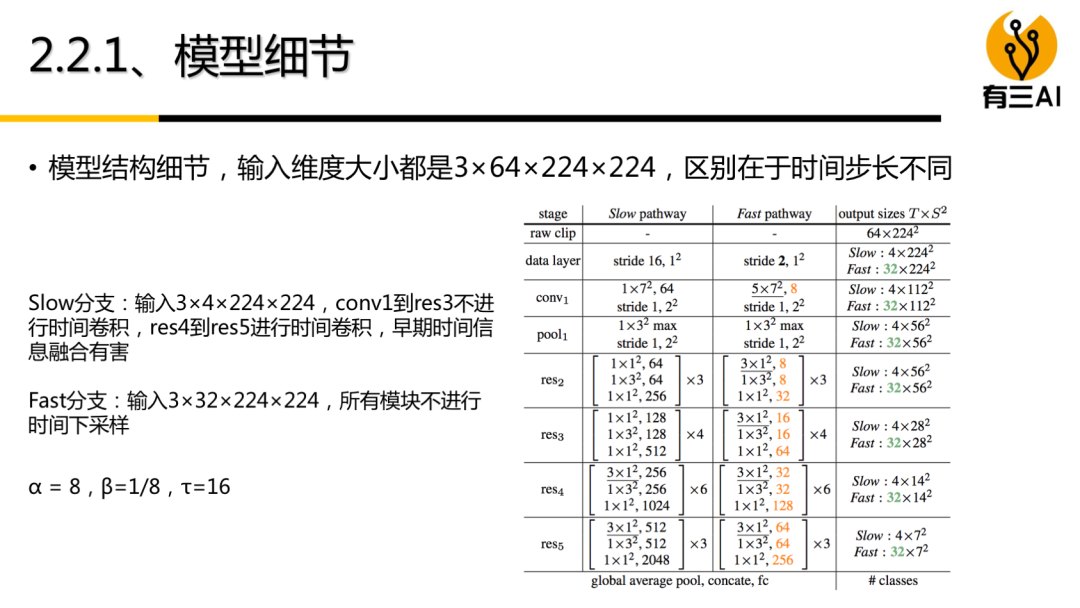
(6) 3D卷积模型实战,包括项目简介,数据处理,模型定义,模型训练,模型测试,约80分钟。
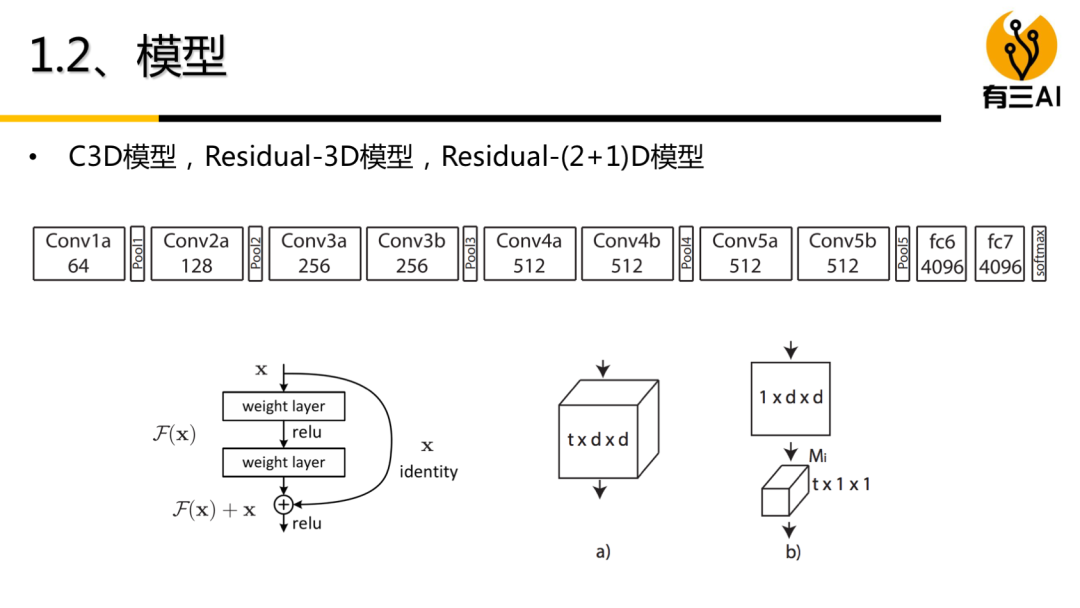



(7) 双流模型实战,包括项目简介,数据处理,模型定义,模型训练,模型测试,约60分钟。
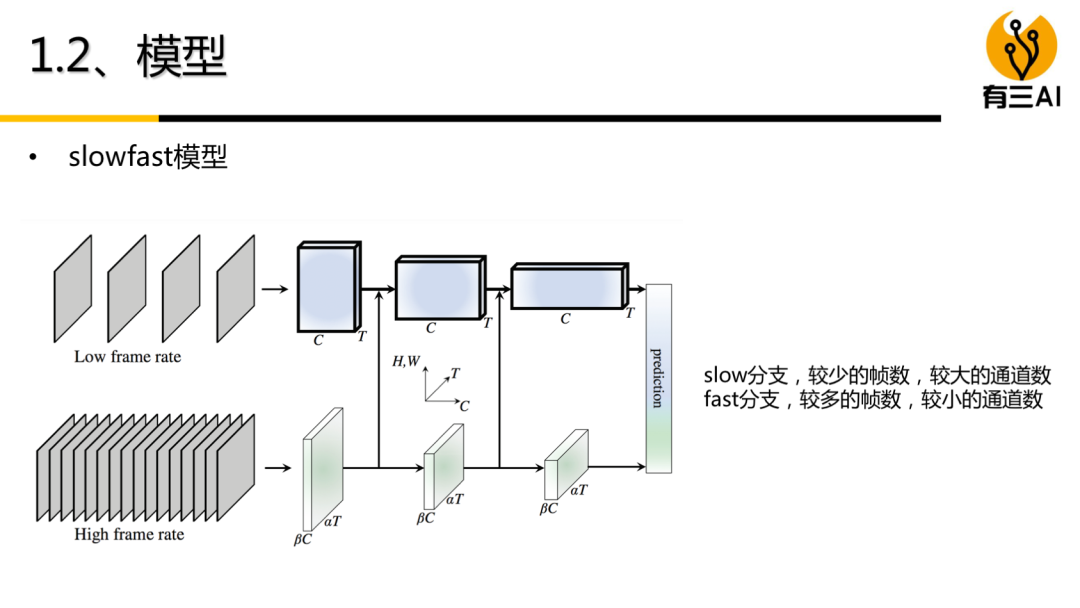
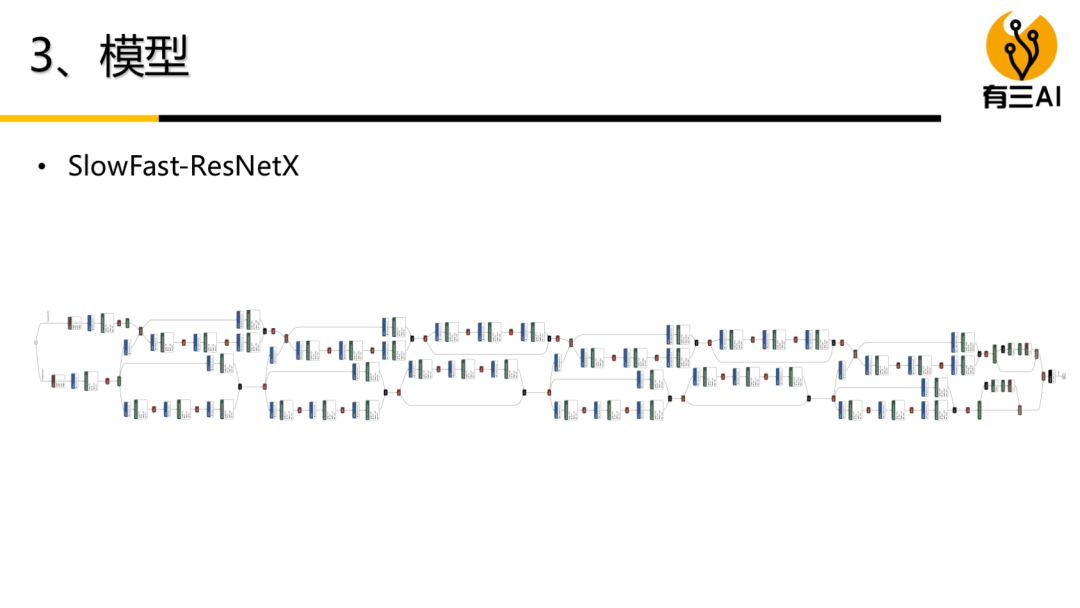
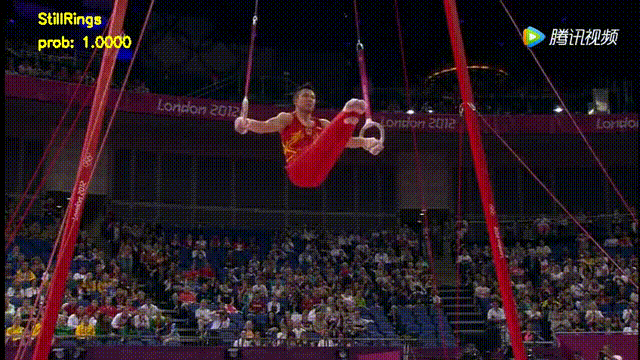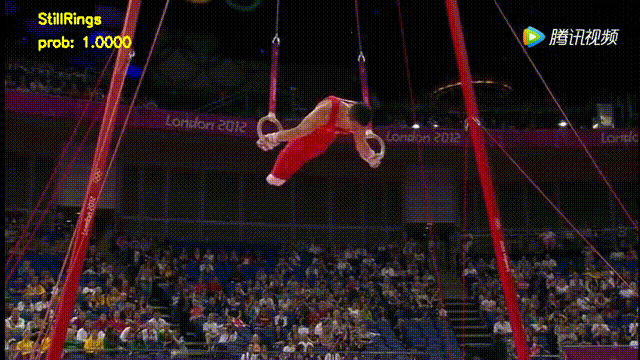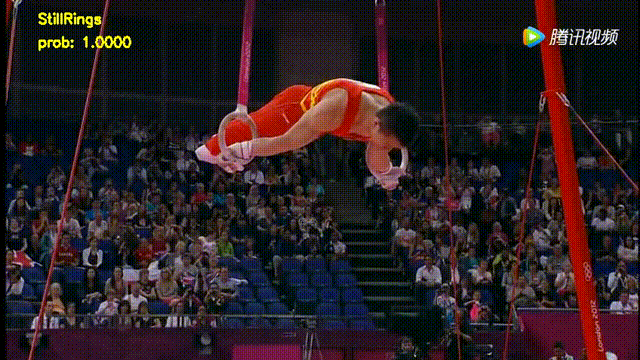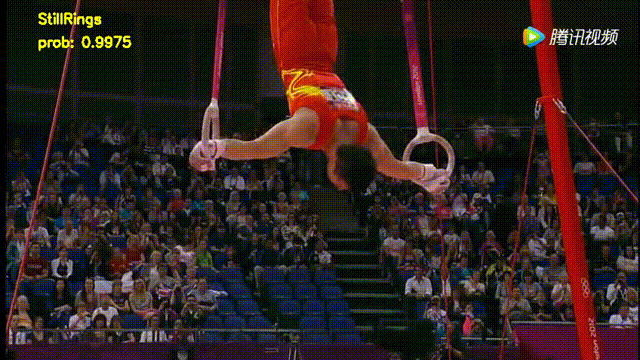
(8) 本周会继续新增的内容,包括RNN/LSTM模型理论与实践,以及其他时空卷积模型。

言有三
龙鹏,笔名言有三,技术社区《有三AI》创始人。先后就读于华中科技大学(2008-2012),中国科学院半导体研究所神经网络实验室(2012-2015),先后就职于奇虎360人工智能研究院(2015.7-2017.5),陌陌科技深度学习实验室(2017.5-2019.3),深度学习算法专家,阿里云MVP,华为云MVP。
拥有超过7年的计算机视觉从业经验,拥有丰富的传统图像算法和深度学习计算机视觉项目经验,著有书籍《深度学习之图像识别:核心技术与案例实战》(机械工业出版社2019.4),《深度学习之模型设计:核心算法与案例实践》(电子工业出版社2020.6),《深度学习之人脸图像处理:核心算法与案例实战》(机械工业出版社2020.7),《深度学习之摄影图像处理:核心算法与案例精粹》(人民邮电出版社2021.4),拥有10余项发明技术专利与学术论文。
擅长领域:Caffe,Tensorflow,Pytorch等主流深度学习平台。神经网络与深度学习理论,深度学习模型设计与优化,计算机视觉的基础领域,AI美学,2D与3D人脸算法,生成对抗网络GAN等领域。
订阅《深度学习之视频分类》专栏,本专栏定价为199,随着后续内容增加会进行价格调整,感兴趣的请提前订阅,链接如下:
前30名下单用户点击下方链接可以领取50优惠券,先到先得!










