
最近一段时间,关于“深度学习”我听到了两种截然不同的声音:
1)深度学习相关的算法岗太卷了,劝退劝退劝退;
2)深度学习现在门槛好低哦,快来一起冲冲冲呀!
孰是孰非,咱们来聊一聊深度学习“门槛低”的话题,以及该不该对算法岗劝退。
故事起因
深度学习门槛“变低”应该是从18年前后开始的,Google、OpenAI等巨头们为我们造好了轮子,使得广大普通科研爱好者可以站在巨人的肩膀上,一目千里。
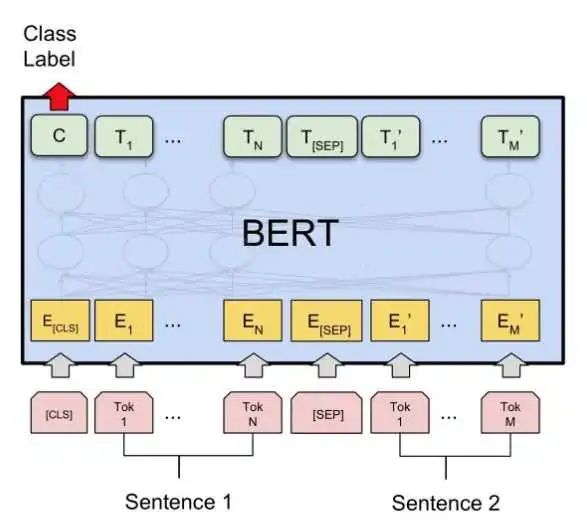
以自然语言处理领域的殿堂级模型 BERT 为例,虽然包含了12层Transformer网络,1.1亿参数量,但借助 huggingface 开源的 transformers 库,普通深度学习用户使用 BERT 瞬间轻松加愉快:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello world!")
outputs = model(inputs)
5行代码实现了深度学习NLP领域几乎最牛B的模型,你说这门槛能不低吗?
据说计算机视觉领域强大的模型,也只需要少于10行代码就能实现。
再举一个例子,文本匹配同样是NLP最底层的核心任务之一,目的是衡量输入的两个句子之间的关系,例如是否相似等等。
18年没有 BERT 之前,典型的文本匹配模型可以用“花式酷炫”来形容,咱们随便看几个:
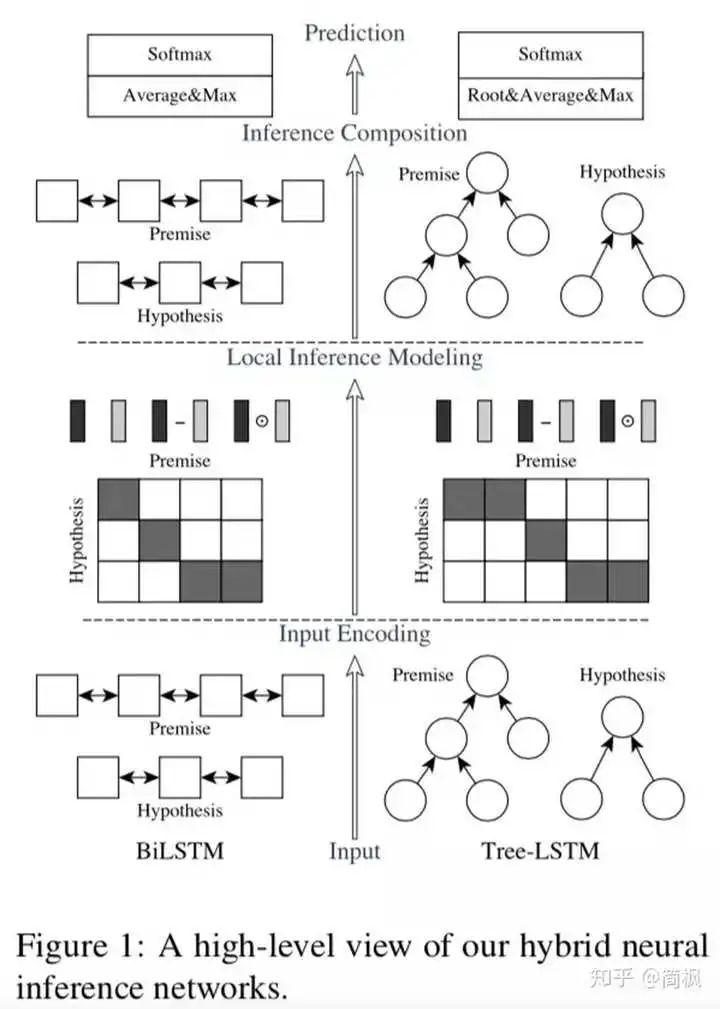
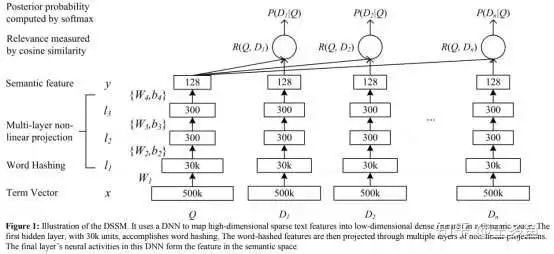
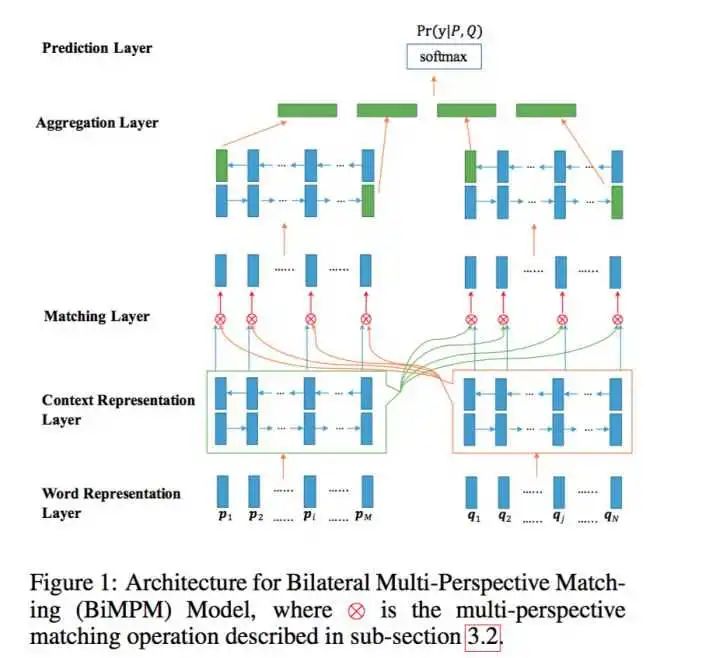
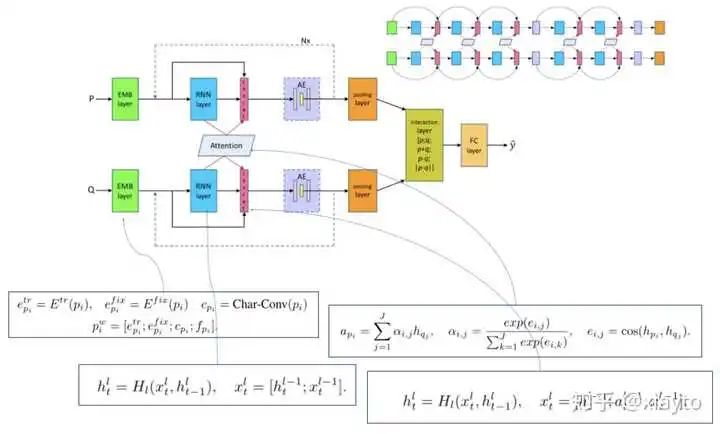
从上到下,分别是ESIM、DSSM、BiMPM、DRCN文本匹配模型。
看完有没有一种头晕目眩感?不同的模型感觉长得很像,却并不相同,又好像是在拿各种网络搭积木。
可别小看这些看似繁琐的模型,当年它们可都是各个数据集的SOTA,而且大多来自ACL这样的顶会
。
然而在 BERT 出现后,原来的所谓“长/短文本匹配利器们”,几乎统统被下面一个模型取代了:
原因很简单,BERT 结构简单而统一,效果还能吊打传统复杂模型,何乐而不为?
低门槛的真相
上面客观介绍了“门槛低”的原因,因为巨头们的工作让我们避免了重复造轮子。那深度学习真的已经成为低门槛了吗?很明显不是的。
如果同学只会前文介绍的 api 调用就开始做深度学习、硬刚大厂算法岗,很容易直接被卷没了,因为人真的太多了。会调包是最基础的能力,估计只能刷掉1%的天真无邪小白。
深度学习背后是庞大的知识体系,涉及了编程、算法、概率论、统计、线性代数等多个学科分支。
如果想从事深度学习工作,简单概括至少需要具备下面的知识点:
1)熟悉最基本的深度学习框架(pyTorch, Keras, TF等)和IDE(pycharm, VSCode, Jupyter等),并具备 debug 错误排查能力;
2)熟悉至少一门主流编程语言,数据资源稀缺时可能还要通过爬虫去抓取语料;
3)能手撕前向/反向传播,熟悉微积分中的链式法则求导;例如给一个两层的MLP和简单的二维向量,能推导出 forward propagation,再用 chain rule 推导出 back propagation;
4)了解常见的损失函数,激活函数和优化算法,明白它们各自的区别优劣,例如 relu 相比 sigmoid 的优点在哪,Adam对于SGD做了哪些改进;
5)对一些经典的论文和方法了如指掌,最好能给刚入行的同学讲解清楚(这样才算是真懂了),例如做NLP,如果会调包却不知道 BERT 三个嵌入层分别是什么、Transformer 有哪些核心模块,肯定要被 pass;
6)遍地开花不如单点突破,精通自己的研究领域;知道领域内SOTA方法是什么,有哪些算法设计理念、数据集、应用场景等,精通一个领域可以提高自己的不可替代性,胜过蜻蜓点水什么都会一点却样样不精的人;
7)加分项:名校背景,paper,比赛SOTA,独角兽/大厂实习经验,发明专利等,可以为你的简历锦上添花,更快从简历池中脱颖而出。
总的来看,深度学习门槛看似降低了,却对入行的从业人员提出了更高的专业要求,优胜劣汰的自然法则在几乎任何一个领域都是适用的。
相比于科研发paper,工业界对理论基础和项目经验更加看重,从近几年各大厂的简历投递/录用比来看,深度学习的门槛不降反升了。
不过大家也不用慌,只要掌握了正确的方法和套路,拿下深度学习offer也不是什么难事儿,具体可以参考0顶会入场大厂算法岗的正确姿势!最后祝大家秋招顺利哈。
进技术交流群请添加AINLP小助手微信(id: ainlper)
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏










