
从事深度学习的同学相信你们已经看了很多研究领域的相关论文,在你心中是否有 idea 最惊艳的论文呢?(欢迎在评论区留言)
我来分享几篇NLP语义解析方向的惊艳工作:Transformer、BERT、X-SQL、M-SQL、RAT-SQL,它们代代相传,依次继承了前人的亮点与精华。
前2个是NLP领域的基础工作,早已“走向世界”,在CV,ASR中有了广泛应用。后3个基于前两项工作进行了创新和推广,在语义解析子任务Text2SQL上大放光彩。
提出Transformer模块的论文《Attention is all you need》想必NLPer不能再熟悉了吧,最初在机器翻译领域被证明效果显著,随后几乎通吃了NLP各项下游任务,并在CV和ASR等领域中取得了显著成果。
传统CNN网络受限于局部感受野,卷积核无法捕捉全局特征;RNN/LSTM网络由于自回归结构,虽然可以建模长距离依赖却无法并行计算,且容易产生梯度消失与爆炸问题。而基于自注意力机制的Transformer模块,通过引入n*n(n表示序列长度)的Attention矩阵,虽然将空间复杂度提升为 ,却巧妙避开了CNN/RNN各自的不足。
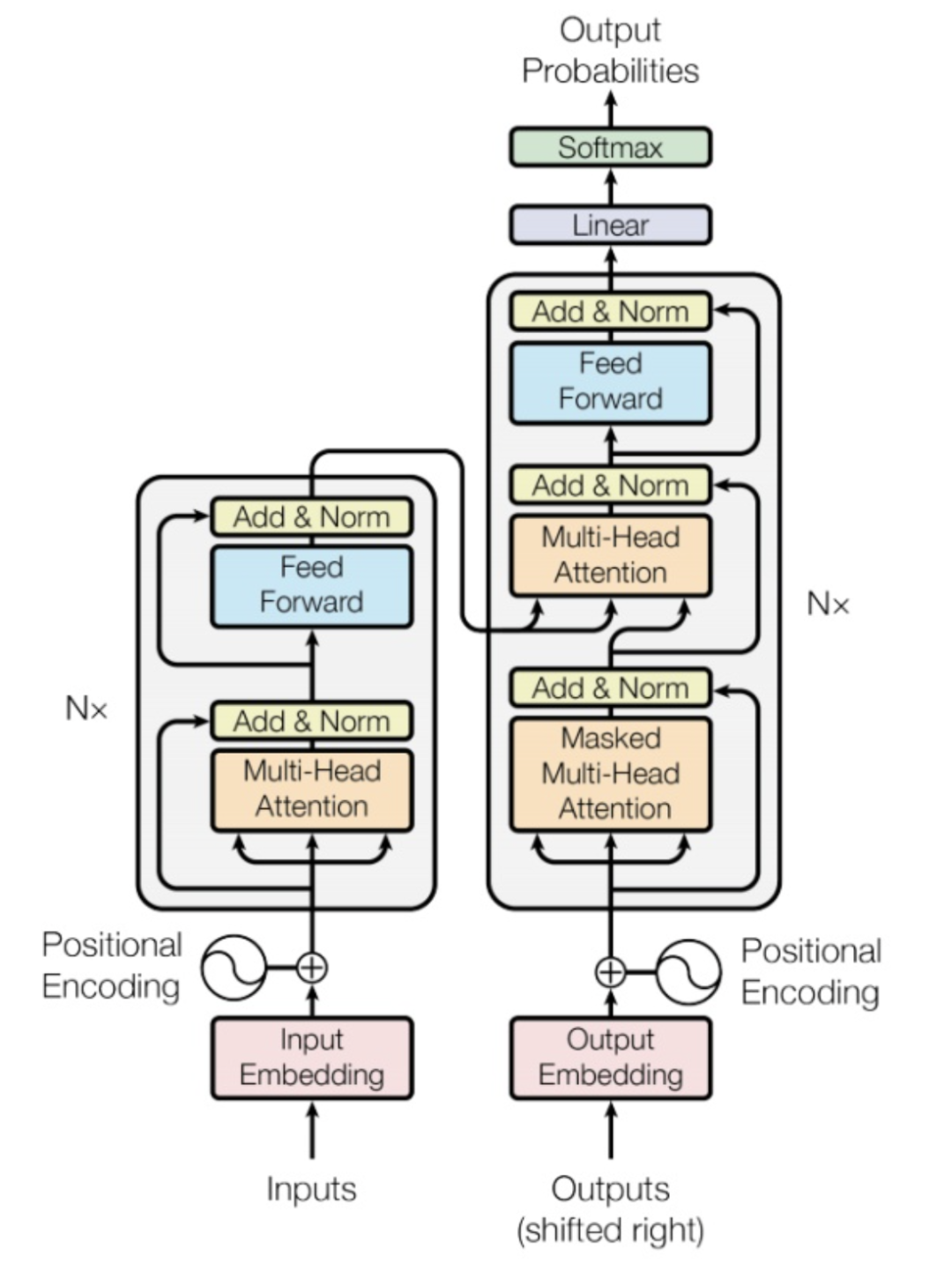
从17年发表到今天,该篇paper引用量已经突破22,000次,在多个领域绽放光彩,有可能在今后成为大一统模型。
相比于Word2Vec/Glove等传统词向量,以双向Transformer为核心的预训练语言模型BERT绝对是核弹级改进武器。
一方面,BERT及其众多后续工作(ERNIE,RoBERTa等),颠覆了NLP界的游戏规则,在众多下游任务频繁刷新SOTA。另一方面,BERT的出现大幅降低了NLP的入门门槛,了解并会使用BERT,很多传统NLP任务已经被解决的八九不离十。
为什么BERT效果会这么好呢?这本质上得益于论文中创新性提出的“MLM”预训练任务。
BERT本质上是一个自编码语言模型,为了能见多识广,BERT使用3亿多词语训练,采用12层双向Transformer架构。其主要训练目标,是被称为掩码语言模型的MLM。即输入一句话,给其中15%的字打上“mask”标记,经过Embedding输入和12层Transformer深度理解,来预测“mask”标记原本是哪个字。
input: 欲把西[mask]比西子,淡[mask]浓抹总相宜output: 欲把西[湖]比西子,淡[妆]浓抹总相宜
例如我们输入“欲把西[mask]比西子,淡[mask]浓抹总相宜”给BERT,它需要根据没有被“mask”的上下文,预测出掩盖的地方是“湖”和“妆”。
MLM任务的灵感来自于人类做完形填空。挖去文章中的某些片段,需要通过上下文理解来猜测这些被掩盖位置原先的内容。
对BERT还不熟悉或0基础的同学,推荐你阅读另一篇文章:
如何通俗易懂地让女朋友明白什么是语言模型?
从18年底提出至今,BERT论文引用量突破了20,000次。它和Transformer都是非常经典出色的论文,值得每一位从事深度学习工作的同学好好阅读。
X-SQL和M-SQL,RAT-SQL都是NLP语义解析子任务Text2SQL的代表性工作。
Text2SQL任务是将用户的自然语言直接转换为相应的SQL序列,自动完成查表工作。它打破了人与结构化数据库之间的壁垒,具有很强的应用&研究价值。
X-SQL是最早将预训练语言模型引入该领域的工作之一,既使用了BERT来增强文本与数据库模式(如列名)的联合编码,又巧妙利用了SQL的语法规则,将SQL序列拆分为多个片段。
通过Multi-Task结构,X-SQL显著降低了SQL解码难度,提升了生成结果的可控性,在第一个大规模标注的Text2SQL数据集WikiSQL上获得了SOTA。
M-SQL是首个基于中文Text2SQL数据集并取得了SOTA的工作,它的整体思路和前辈X-SQL一脉相承,类似的Multi-Task框架,Encoder-Decoder结构;同时完善了SQL模版,可以支持更加复杂的查询条件。

M-SQL各个子任务在TableQA上都取得了超过95%的准确率,最终SQL生成准确率超过了90%,为Text2SQL在实际业务中落地带来了可能。

其中,仅在编码器中使用BERT代替word2vec,就带来了超过10%的绝对提升,证明了预训练语言模型强大的编码能力,即使是在文本和表格的跨模态任务中,也有出色表现。
RAT-SQL是去年微软研究院的工作,曾经在Text2SQL最权威的榜单Spider上霸榜半年之久。
RAT-SQL也是Encoder-Decoder的思路,其中在编码器中除了引入BERT,还额外使用了关系敏感型注意力机制,来显式编码文本token和数据库表名、列名间存在的关系。
例如上图Query中的“青秀南城百货”和数据库中的“商户名称”有对应关系,模型在生成SQL前会捕捉这种关系来辅助解码。
解码器部分,RAT-SQL采用了抽象语法树,把SQL关键字(SELECT, WHERE, ...)和表名、列名等抽象为树的结点,最终递归生成SQL的过程相当于对语法树做了一次深度优先搜索(DST)。
我们发现,这些效果优异的模型往往同时结合了神经网络和规则,既利用了神经网络的深层特征提取能力,又借助规则压缩搜索空间,提高输出结果的可控性,是一种非常robust的思路。
当然,在深度学习让我惊艳的论文还有很多。这里抛砖引玉,针对之前钻研过的Text2SQL领域分享自己的一二观点,如有不足,欢迎指正!
我是叶琛,一个爱旅行,懂养生的算法工程师兼干货博主,也是个喜欢用接地气的文风为年轻朋友分享互联网经验和算法知识的人。
硬核码字不易,如果觉得有帮助请一键三连或点个赞哟!
加入技术交流群请添加AINLP小助手微信(id: ainlper)
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏








