1. 本文介绍
今天为大家介绍以下内容:
- Ⅰ Python原生切片,与numpy数组切片,有哪些不同?
2. Python原生切片,与numpy数组切片,有哪些不同?
这里有两个概念,大家需要了解一下。
- 浅拷贝:相当于B将A的数据,复制了一遍,并在本地从新开了一片内存区域,用于存放B。此时,改变A/B中的数据,并不会影响对方;
- 视图:相当于B和A共用一块儿内存区域,当改变A/B中的数据,对方也会跟着改变;
① 数组切片,返回的是原始数组的视图
list1 = [1,2,3]
print(list1)
list2 = list1[1:]
print(list2)
# 此时,修改list2中某一个元素,查看原始列表的元素是否发生变化?
list2[0] = 666
print(list2)
print(list1)
结果如下:
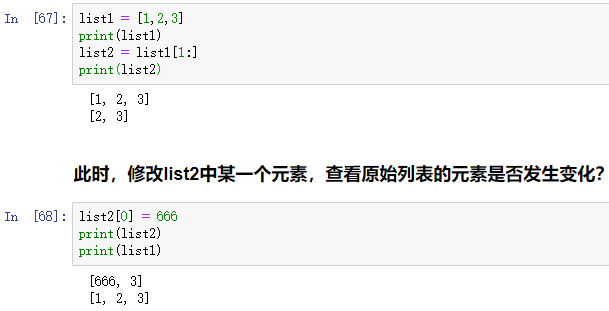
可以发现:修改list2中的元素后,list1中的元素并没有改变。
② 原生python切片,返回的是原始数组的浅拷贝
array1 = np.array([1,3,5,2,4])
print(array1)
array2 = array1[2:]
print(array2)
# 此时,修改array2中某一个元素,查看原始数组的元素是否发生变化?
array2[0] = 888
print(array2)
print(array1)
结果如下:

可以发现:修改array2中的元素后,array1中的元素跟着改变了。
③ 调用数组对象的copy方法,实现底层数据的复制,而不是返回底层数据的视图
array3 = np.array([1,2,3,4,5,6])
print(array3)
array4 = array3.copy()
print(array4)
array4[2] = 666
print(array4)
print(array3)
结果如下:

可以发现:修改array4中的元素后,array3中的元素没有变。
3. numpy中,应该如何使用切片?
切片的使用,不管是原生python切片,还是数组切片,语法基本上是相同的。
- 参数:start代表起始索引,stop代表终止索引,step代表步长;
对于切片,这里有几点需要注意的。
- 注意1:索引是左臂右开区间,比如说x[0:9:1],只能是取到索引等于0处的元素到索引等于8处的元素,而取不到索引等于9的这个元素。记住元素索引都是0开始的,第一个亓素的索引是0.第一个亓素的索引是1,以此类推下去。
- 注意2:当不写start代表从起始索引处取数,当不写stop代表一直取数到最后位置。当不写step步长,代表使用默认步长1。
- 注意3:start、stop、step都可以是负数,具体什么含义,最好在下面的例子中好好体会。
黄同学做了一张图,帮你理解“切片”。

下面用几个例子,来好好练习一下吧!
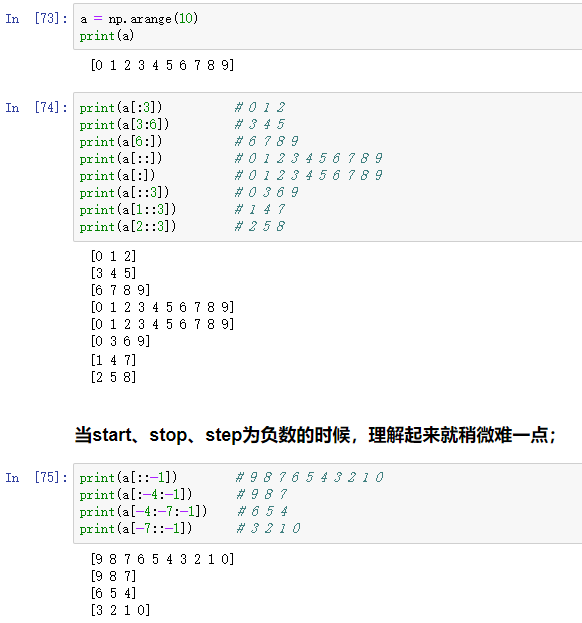
a = np.arange(10)
print(a) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(a[:3]) # 0 1 2
print(a[3:6]) # 3 4 5
print(a[6:]) # 6 7 8 9
print(a[::]) # 0 1 2 3 4 5 6 7 8 9
print(a[:]) # 0 1 2 3 4 5 6 7 8 9
print(a[::3]) # 0 3 6 9
print(a[1::3]) # 1 4 7
print(a[2::3]) # 2 5 8
# 当start、stop、step为负数的时候,理解起来就稍微难一点;
print(a[::-1]) # 9 8 7 6 5 4 3 2 1 0
print(a[:-4:-1]) # 9 8 7
print(a[-4:-7:-1]) # 6 5 4
print(a[-7::-1]) # 3 2 1 0
结果如下:


点击下方阅读原文加入社区会员








