Extreme Gradient Boosting(XGBoost)是一个开放源代码库,它提供了梯度提升算法的有效实现。
尽管该方法的其他开放源代码实现在XGBoost之前就已存在,但XGBoost的发布似乎释放了该技术的力量,并使得应用机器学习社区更普遍地注意到了梯度提升。在开发并首次发布后不久,XGBoost成为了首选方法,并且通常是赢得机器学习竞赛中的分类和回归问题解决方案的关键组成部分。在本教程中,您将发现如何开发用于分类和回归的极端梯度增强合奏。完成本教程后,您将知道:- 极端梯度提升是随机梯度提升集成算法的高效开源实现。
- 如何使用scikit-learn API开发用于分类和回归的XGBoost集成。
- 如何探索XGBoost模型超参数对模型性能的影响。
梯度提升是指一类集成机器学习算法,可用于分类或回归预测建模问题。集成是根据决策树模型构建的。一次将一棵树添加到集合中,并进行调整以纠正由先前模型造成的预测误差。这是一种集成机器学习模型,称为Boosting。使用任何任意的微分损失函数和梯度下降优化算法对模型进行拟合。这给该技术起了名字,称为“梯度提升”,因为随着模型的拟合,损耗梯度被最小化,非常类似于神经网络。有关梯度增强的更多信息,请参见教程:https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/极端梯度增强(简称XGBoost)是梯度增强算法的一种有效的开源实现。因此,XGBoost是一个算法,一个开源项目和一个Python库。它最初是由Tianqi Chen开发的,并由Chen和Carlos Guestrin在其2016年的论文“ XGBoost:可扩展的树增强系统”中进行了描述。它被设计为既计算效率高(例如执行速度快)又高效,也许比其他开源实现更有效。使用XGBoost的两个主要原因是执行速度和模型性能。通常,与其他梯度提升实现相比,XGBoost速度很快。Szilard Pafka执行了一些客观基准测试,将XGBoost的性能与梯度提升和袋装决策树的其他实现进行了比较。他在2015年5月的博客文章“对随机森林实施进行基准测试”中写下了自己的结果。他的结果表明,XGBoost几乎总是比R,Python Spark和H2O的其他基准实现更快。在分类和回归预测建模问题上,XGBoost主导结构化或表格数据集。证据表明,它是Kaggle竞争数据科学平台上竞赛获胜者的首选算法。XGBoost可以作为独立库安装,并且可以使用scikit-learn API开发XGBoost模型。第一步是安装XGBoost库(如果尚未安装)。这可以在大多数平台上使用pip python软件包管理器来实现。例如:sudo pip install xgboost
然后,您可以确认XGBoost库已正确安装,并且可以通过运行以下脚本来使用。# check xgboost version
import xgboost
print(xgboost.__version__)
运行脚本将打印您已安装的XGBoost库的版本。您的版本应该相同或更高。如果不是,则必须升级XGBoost库的版本。
1.1.1
您可能对库的最新版本有疑问。不是你的错。有时,该库的最新版本会带来其他要求,或者可能不太稳定。如果您在尝试运行上述脚本时确实出错,建议您降级至1.0.1版(或更低版本)。这可以通过指定要安装到pip命令的版本来实现,如下所示:sudo pip install xgboost==1.0.1
如果您看到警告消息,则可以暂时将其忽略。例如,以下是您可能会看到并可以忽略的警告消息的示例:FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
如果您需要针对您的开发环境的特定说明,请参阅教程:https://xgboost.readthedocs.io/en/latest/build.html
XGBoost库具有自己的自定义API,尽管我们将通过scikit-learn包装器类使用该方法:XGBRegressor和XGBClassifier。这将使我们能够使用scikit-learn机器学习库中的全套工具来准备数据和评估模型。两种模型的操作方式相同,采用的参数相同,这会影响如何创建决策树并将其添加到集合中。随机性用于模型的构建。这意味着算法每次在相同数据上运行时,都会产生一个略有不同的模型。当使用具有随机学习算法的机器学习算法时,优良作法是通过在多次运行或交叉验证重复期间平均其性能来评估它们。在拟合最终模型时,可能需要增加树的数量,直到在重复评估中减小模型的方差为止,或者拟合多个最终模型并对它们的预测求平均值。让我们看一下如何为分类和回归开发XGBoost集成。在本节中,我们将研究如何使用XGBoost解决分类问题。首先,我们可以使用make_classification()函数创建具有1,000个示例和20个输入功能的综合二进制分类问题。# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
(1000, 20) (1000,)
接下来,我们可以在该数据集上评估XGBoost模型。我们将使用重复的分层k折交叉验证(具有3个重复和10折)对模型进行评估。我们将报告所有重复和折叠中模型准确性的均值和标准差。# evaluate xgboost algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = XGBClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到具有默认超参数的XGBoost集成在此测试数据集上实现了约92.5%的分类精度。Accuracy: 0.925 (0.028)
我们还可以将XGBoost模型用作最终模型,并进行分类预测。首先,将XGBoost集合拟合到所有可用数据上,然后可以调用prepare()函数对新数据进行预测。重要的是,此函数希望数据始终以NumPy数组的形式作为矩阵提供,每个输入样本一行。下面的示例在我们的二进制分类数据集中展示了这一点。# make predictions using xgboost for classification
from numpy import asarray
from sklearn.datasets import make_classification
from xgboost import XGBClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = XGBClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
row = asarray([row])
yhat = model.predict(row)
print('Predicted Class: %d' % yhat[0])
运行示例可以使XGBoost集成模型适合整个数据集,然后用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。Predicted Class: 1
现在,我们已经熟悉使用XGBoost进行分类了,让我们看一下用于回归的API。在本节中,我们将研究如何使用XGBoost解决回归问题。首先,我们可以使用make_regression()函数创建具有1000个示例和20个输入要素的综合回归问题。下面列出了完整的示例。# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
(1000, 20) (1000,)
接下来,我们可以在该数据集上评估XGBoost算法。正如我们在上一节所做的那样,我们将使用重复的k倍交叉验证(三个重复和10倍)来评估模型。我们将报告所有重复和折叠的模型的平均绝对误差(MAE)。scikit-learn库使MAE变为负数,以便最大化而不是最小化。这意味着较大的负MAE会更好,并且理想模型的MAE为0。# evaluate xgboost ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from xgboost import XGBRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = XGBRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error'
, cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到具有默认超参数的XGBoost集成达到了约76的MAE。MAE: -76.447 (3.859)
我们还可以将XGBoost模型用作最终模型,并进行回归预测。首先,将XGBoost集合拟合到所有可用数据上,然后可以调用prepare()函数对新数据进行预测。与分类一样,单行数据必须以NumPy数组格式表示为二维矩阵。下面的示例在我们的回归数据集中展示了这一点。# gradient xgboost for making predictions for regression
from numpy import asarray
from sklearn.datasets import make_regression
from xgboost import XGBRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = XGBRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
row = asarray([row])
yhat = model.predict(row)
print('Prediction: %d' % yhat[0])
运行示例可以使XGBoost集成模型适合整个数据集,然后用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。Prediction: 50
现在,我们已经熟悉使用XGBoost Scikit-Learn API评估和使用XGBoost集成体,现在让我们来看一下配置模型。在本节中,我们将仔细研究一些您应该考虑为Gradient Boosting集成进行调优的超参数及其对模型性能的影响。XGBoost集成算法的一个重要的超参数是集成中使用的决策树的数量。回想一下,决策树被顺序地添加到模型中,以纠正和改进现有树的预测。因此,越多的树通常越好。可以通过“ n_estimators”参数设置树的数量,默认为100。下面的示例探讨值在10到5,000之间的树木数量的影响。# explore xgboost number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100
, 500, 1000, 5000]
for n in trees:
models[str(n)] = XGBClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
首先运行示例将报告每个已配置数量的决策树的平均准确性。注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到该数据集的性能有所提高,直到大约500棵树为止,此后性能似乎趋于稳定或下降。>10 0.885 (0.029)
>50 0.915 (0.029)
>100 0.925 (0.028)
>500 0.927 (0.028)
>1000 0.926 (0.028)
>5000 0.925 (0.027)
创建箱须图以分配每种配置数量的树的准确性得分。我们可以看到增加模型性能和集合大小的总体趋势。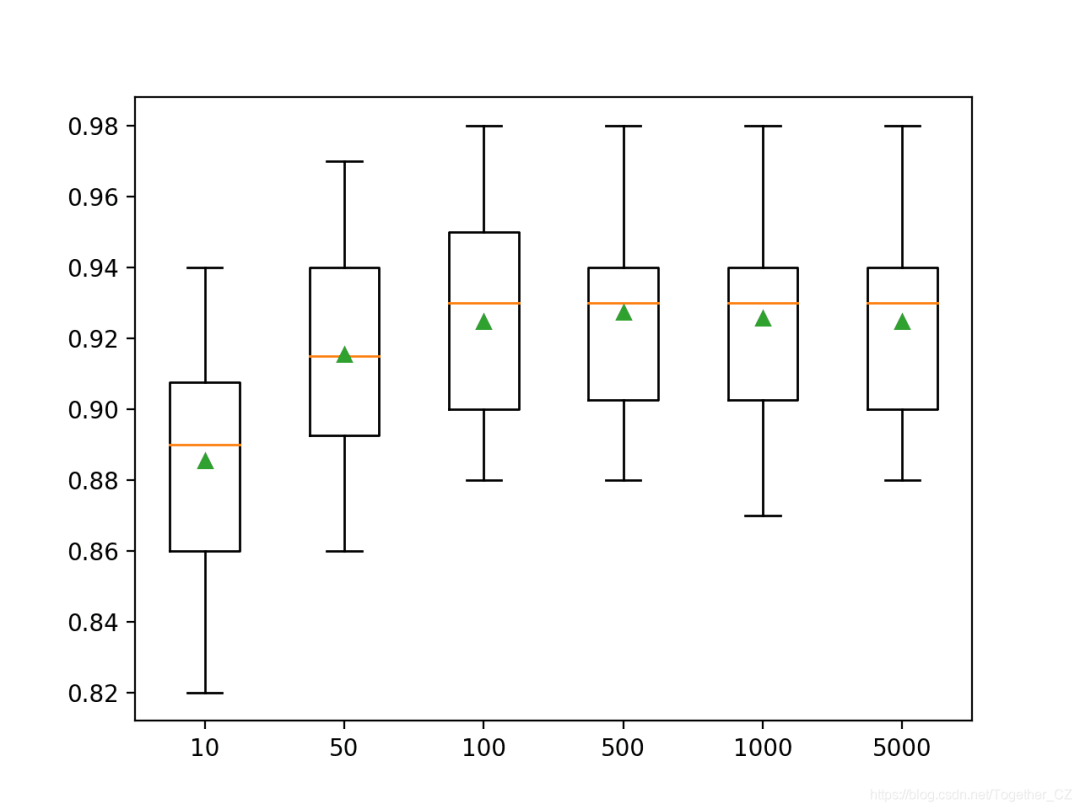
改变添加到集合中的每棵树的深度是用于梯度增强的另一个重要的超参数。树的深度控制着每棵树对训练数据集的专业化程度:树的一般程度或过拟合程度。首选的树不是太浅且太普通(例如AdaBoost),而又不是太深且专用(例如自举聚合)。渐变增强通常在深度适中的树上表现良好,从而在技巧和通用性之间找到平衡。树的深度通过“ max_depth”参数控制,默认为6。下面的示例探讨了1到10之间的树深及其对模型性能的影响。# explore xgboost tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = XGBClassifier(max_depth=i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到性能随着树的深度而提高,可能是在3到8的深度处偷看,之后,更深,更专业的树会导致性能变差。>1 0.849 (0.028)
>2 0.906 (0.032)
>3 0.926 (0.027)
>4 0.930 (0.027)
>5 0.924 (0.031)
>6 0.925 (0.028)
>7 0.926 (0.030)
>8 0.926 (0.029)
>9 0.921 (0.032)
>10 0.923 (0.035)
我们可以看到随着树的深度增加模型性能达到一定程度的总体趋势,此后性能开始趋于平稳,或者由于过度专业化的树而降低。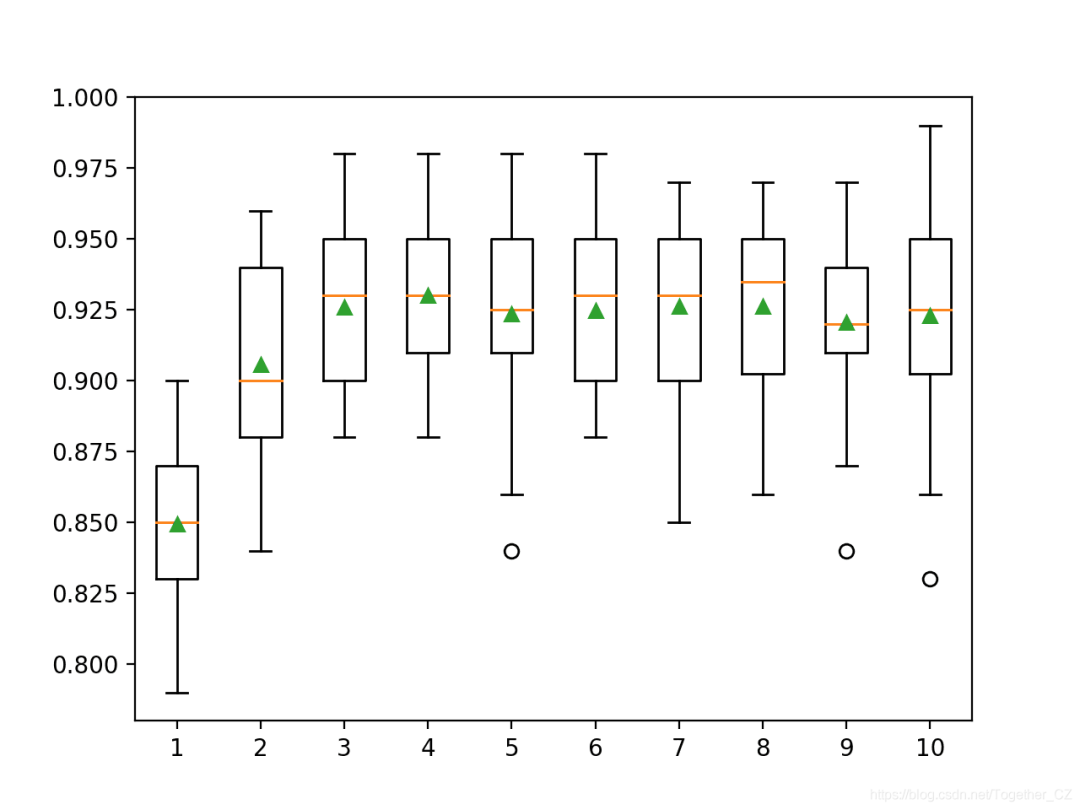
学习率控制着每个模型对整体预测的贡献量。较低的费率可能需要集合中的更多决策树。可以通过“ eta”参数控制学习率,默认为0.3。下面的示例探索学习率,并比较值在0.0001和1.0之间的效果。# explore xgboost learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = XGBClassifier(eta=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到,较高的学习率会导致此数据集的性能更高。我们希望为较小的学习率在合奏中添加更多的树会进一步提高性能。这突出了树的数量(训练速度)和学习率之间的权衡,例如 我们可以通过使用更少的树和更大的学习率来更快地拟合模型。>0.0001 0.804 (0.039)
>0.0010 0.814 (0.037)
>0.0100 0.867 (0.027)
>0.1000 0.923 (0.030)
>1.0000 0.913 (0.030)
创建箱须图以分配每种配置的学习率的准确性得分。我们可以看到随着学习率增加0.1,模型性能提高的总体趋势,此后性能下降。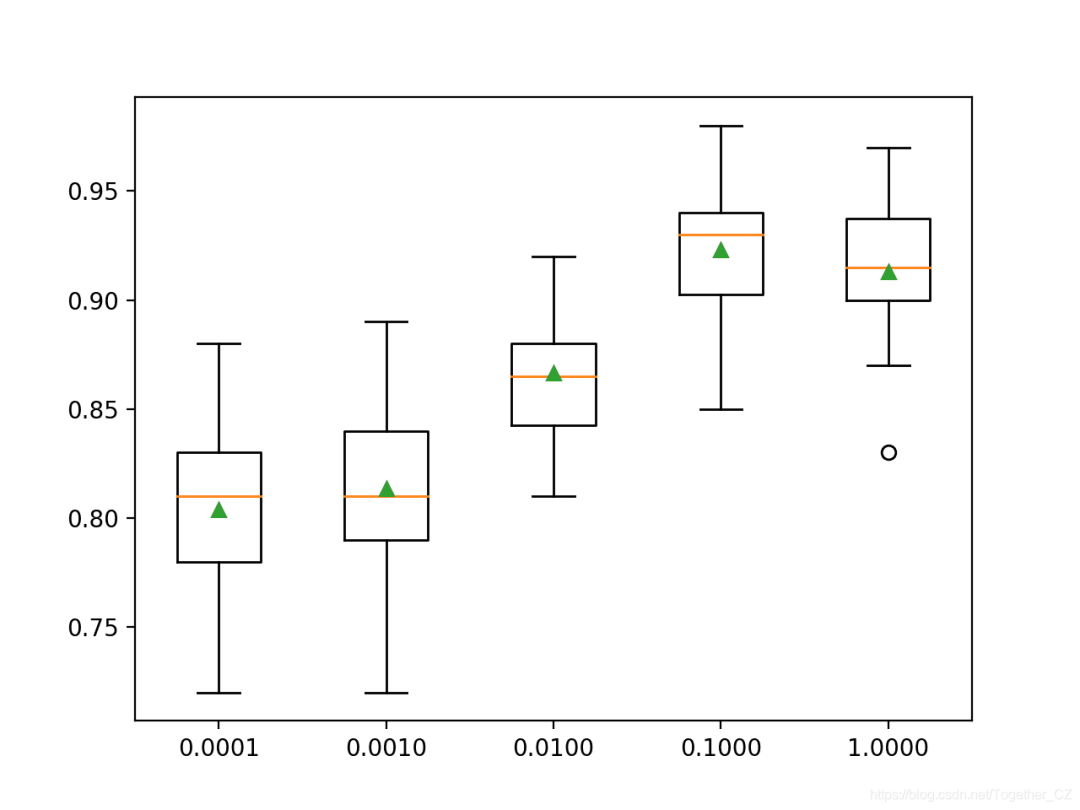
用于拟合每棵树的样本数量可以变化。这意味着每棵树都适合于训练数据集的随机选择子集。使用较少的样本会为每棵树引入更多方差,尽管它可以改善模型的整体性能。用于拟合每棵树的样本数量由“子样本”参数指定,并且可以设置为训练数据集大小的一小部分。默认情况下,将其设置为1.0以使用整个训练数据集。下面的示例演示了样本大小对模型性能的影响,比率从10%到100%以10%的增量变化。# explore xgboost subsample ratio effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in arange(0.1, 1.1, 0.1):
key = '%.1f' % i
models[key] = XGBClassifier(subsample=i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到,平均性能对于覆盖大多数数据集(例如80%或更高)的样本量可能是最好的。>0.1 0.876 (0.027)
>0.2 0.912 (0.033)
>0.3 0.917 (0.032)
>0.4 0.925 (0.026)
>0.5 0.928 (0.027)
>0.6 0.926 (0.024)
>0.7 0.925 (0.031)
>0.8 0.928 (0.028)
>0.9 0.928 (0.025)
>1.0 0.925 (0.028)
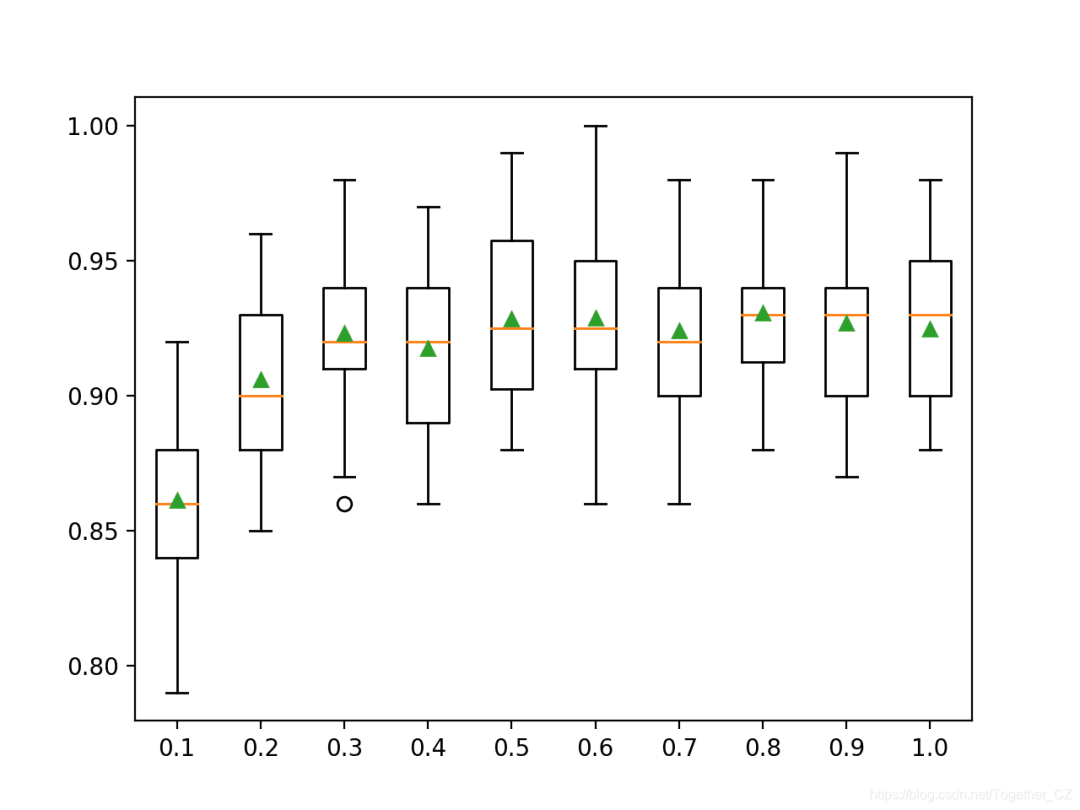
我们可以看到模型性能不断提高的总体趋势,可能达到约80%的峰值并保持一定水平。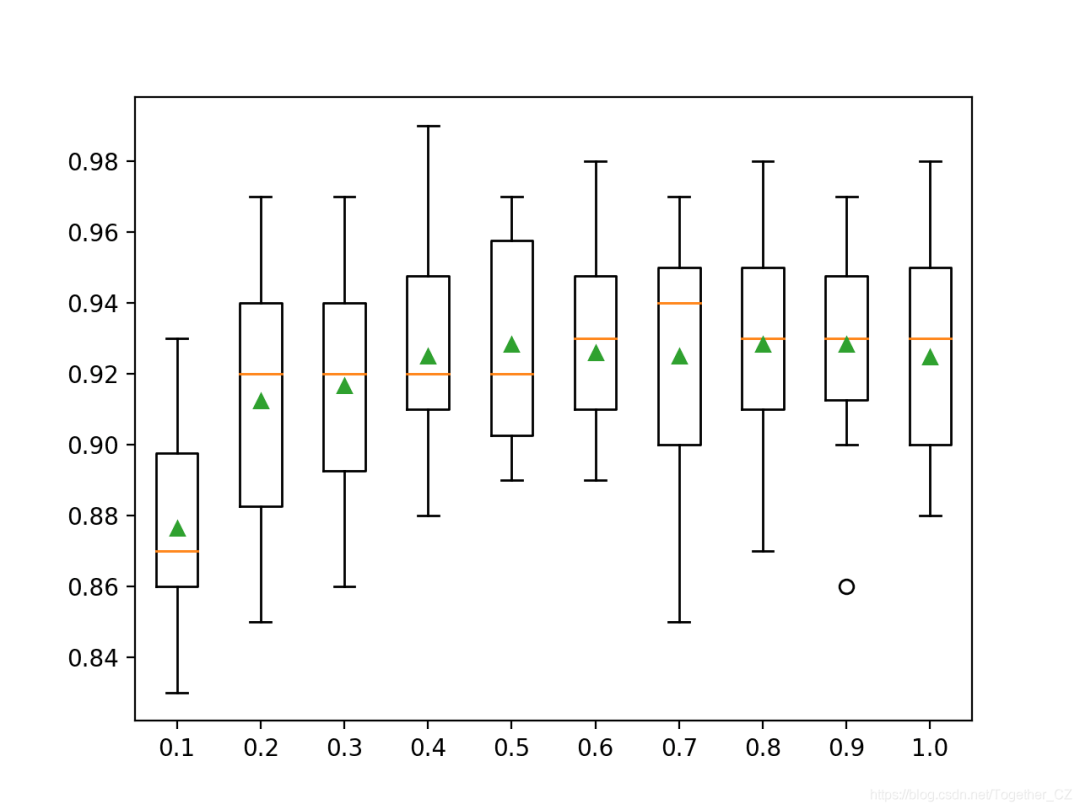
用于适应每个决策树的功能部件的数量可以变化。与更改样本数量一样,更改要素数量也会在模型中引入额外的方差,尽管可能需要增加树的数量,但可以提高性能。每棵树使用的特征数量取为随机样本,并由“ colsample_bytree”参数指定,并且默认为训练数据集中的所有特征,例如 100%或1.0的值。您还可以为每个拆分采样列,这由“ colsample_bylevel”参数控制,但是在此我们将不讨论此超参数。下面的示例探讨了特征数量对模型性能的影响,比率从10%到100%以10%的增量变化。# explore xgboost column ratio per tree effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in arange(0.1, 1.1, 0.1):
key = '%.1f' % i
models[key] = XGBClassifier(colsample_bytree=i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。在这种情况下,我们可以看到平均性能提高到功能数量的一半(50%),并在此之后保持一定水平。令人惊讶的是,每棵树删除一半的输入变量影响很小。>0.1 0.861 (0.033)
>0.2 0.906 (0.027)
>0.3 0.923 (0.029)
>0.4 0.917 (0.029)
>0.5 0.928 (0.030)
>0.6 0.929 (0.031)
>0.7 0.924 (0.027)
>0.8 0.931 (0.025)
>0.9 0.927 (0.033)
>1.0 0.925 (0.028)
创建箱须图以分配每个配置的列比率的准确性得分。
我们可以看到提高模型性能的总体趋势可能达到60%的峰值并保持一定水平。