来源:矽说
首先解释一下标题:Google Brain近日在Blog上发布了其最新的研究,该研究使用了机器学习的方法来加速芯片架构设计,而在该研究中的芯片是一款机器学习加速芯片,因此整个逻辑就变成了“机器学习(主语)加速(谓语)机器学习加速芯片(宾语)”。
芯片架构设计的痛点之一就是设计空间很大,参数很多,形成一个高维度优化问题。举例来说,Google Brain在本研究中用的架构例子就是机器学习加速芯片中的基本模块PE Array,这个PE Array中包含一个共享存储单元(主要负责weight和activation的存储),可以供所有PE访问;此外每个PE中还有乘加单元(MAC)以及每个PE专用的core memory。
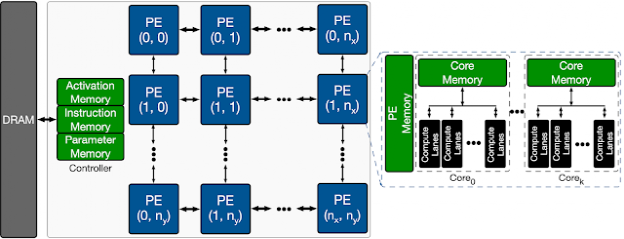
即使在这个基本的PE Array中,设计空间都包括多个设计参数:-共享存储单元的空间大小
-PE数量
-每个PE中MAC数量
在给定芯片尺寸的设计约束下,每个设计参数之间都是互相耦合的。例如,PE中MAC数量增加,那么存储的空间比如会下降。另外,每个参数与最终性能之间的关系是复杂的,例如在存储空间不同的情况下,增加MAC数量对性能的改善都不一样。最后,评估一组设计参数的代价很高:不少朋友一定都尝试跑过电路级的芯片仿真,如果要跑完一个机器学习网络的benchmark的话会需要很多时间。换句话说,如果使用暴力搜索的话大概率没法在合理的时间内找到最优设计,而需要去找一些合理的优化方法。
芯片架构设计的设计空间探索问题其实和机器学习领域的网络架构搜索(network architecture search,NAS)很接近。NAS是目前机器学习领域常见的设计方法,可以用来自动搜索最优的神经网络设计,目前不少SOTA的模型(例如EfficientNet)都是使用NAS找到的。神经网络设计的设计空间也很大,例如常见的神经网络模型层数到50-100层很正常,而每一层的通道数量(channel #)和kernel size都是一个可变的设计参数;此外,每个神经网络模型的验证代价也很高,其训练过程常常需要一天以上。
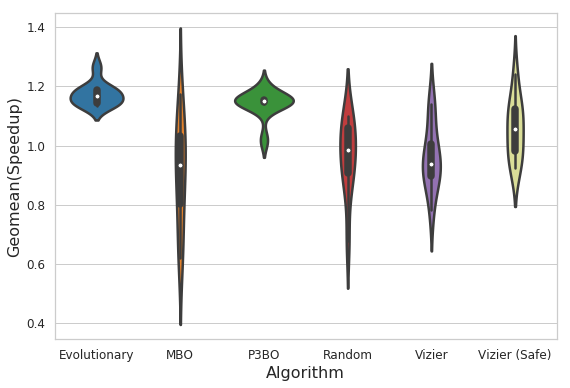
既然神经网络设计和芯片架构设计都是高维设计空间优化问题,而NAS在神经网络领域获得了很大的成功,那么Google Brain就想到了把NAS中的方法应用到了芯片架构设计上面。在具体设计中,Google Brain尝试了几种优化方法,包括暴力随机搜索,贝叶斯方法,进化算法,以及P3BO(多种算法ensemble)等。最后的结果显示,进化算法和ensemble相对简单的随机搜索来说,不仅能增加最佳搜索结果,此外每次搜索的结果分布基本都集中在最佳结果附近,而随机搜索则每次的结果十分分散,大概率会搜索到很差的结果。
首先,这个研究很有意思,非常精确地抓住了神经网络设计和芯片架构设计的共同点,并且把机器学习领域常见的NAS方法应用到了芯片架构设计领域,且取得了不错的效果。接下来这个领域应该会成为研究论文灌水的热点,比如目前面向的是PE Array,未来换一个目标芯片(例如Genomics,或者codec等等)就是一个新的研究;此外,目前效果最好的进化算法事实上并不算机器学习算法,我认为很快就会有人用强化学习等NAS中常见的机器学习方法应用到芯片架构搜索中。
另外,随着异构计算和加速器逐渐成为主流,这样的设计方法会越来越有价值。与传统的通用型处理器不同,加速器通常针对明确的几种算法并且有确定的benchmark目标,因此很容易定义优化的目标并且使用这类自动优化方法。
最后,这类利用机器学习算法(以及其他算法)的架构搜索和应用如何与目前的工具链相整合也是一个很值得我们关注的方向。目前在架构设计层面的工具大多数提供的是架构性能的评估,尚没有工具能帮助架构师去寻找和优化设计。未来几年,随着各种加速器设计越来越普及,EDA厂商是否会跟进去加入架构级的优化工具值得我们期待。










