转自 AI有道
 作者 | Peter
作者 | Peter
编辑 | AI有道
系列文章:
吴恩达《Machine Learning》精炼笔记 1:监督学习与非监督学习
吴恩达《Machine Learning》精炼笔记 2:梯度下降与正规方程
吴恩达《Machine Learning》精炼笔记 3:回归问题和正则化
吴恩达《Machine Learning》精炼笔记 4:神经网络基础
吴恩达《Machine Learning》精炼笔记 5:神经网络
吴恩达《Machine Learning》精炼笔记 6:关于机器学习的建议
吴恩达《Machine Learning》精炼笔记 7:支持向量机 SVM
吴恩达《Machine Learning》精炼笔记 8:聚类 KMeans 及其 Python实现
吴恩达《Machine Learning》精炼笔记 9:PCA 及其 Python 实现
吴恩达《Machine Learning》精炼笔记 10:异常检测
吴恩达《Machine Learning》精炼笔记 11:推荐系统
本周主要是介绍了两个方面的内容,一个是如何进行大规模的机器学习,另一个是关于图片文字识别OCR 的案例
大规模机器学习(Large Scale Machine Learning)
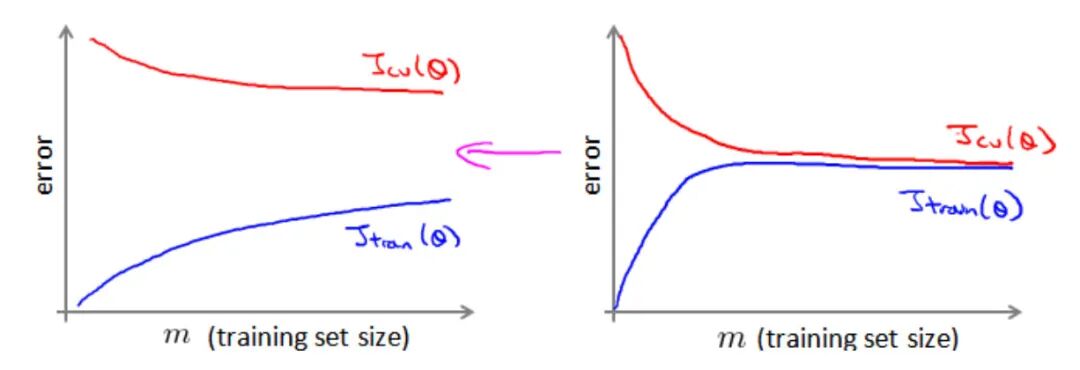
在低方差的模型中,增加数据集的规模可以帮助我们获取更好的结果。但是当数据集增加到100万条的大规模的时候,我们需要考虑:大规模的训练集是否真的有必要。获取1000个训练集也可以获得更好的效果,通过绘制学习曲线来进行判断。
随机梯度下降法Stochastic Gradient Descent
如果需要对大规模的数据集进行训练,可以尝试使用随机梯度下降法来代替批量梯度下降法。随机梯度下降法的代价函数是
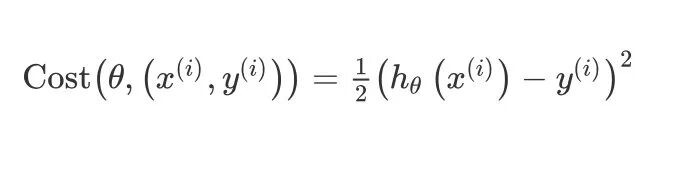
具体算法的过程为
先对训练集进行随机的洗牌操作,打乱数据的顺序
重复如下过程:
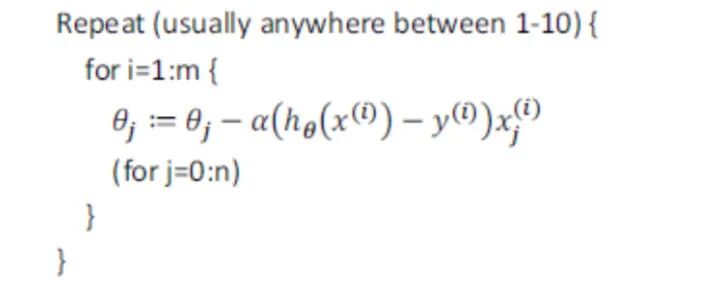
随机梯度下降算法是每次计算之后更新参数θ,不需要现将所有的训练集求和。
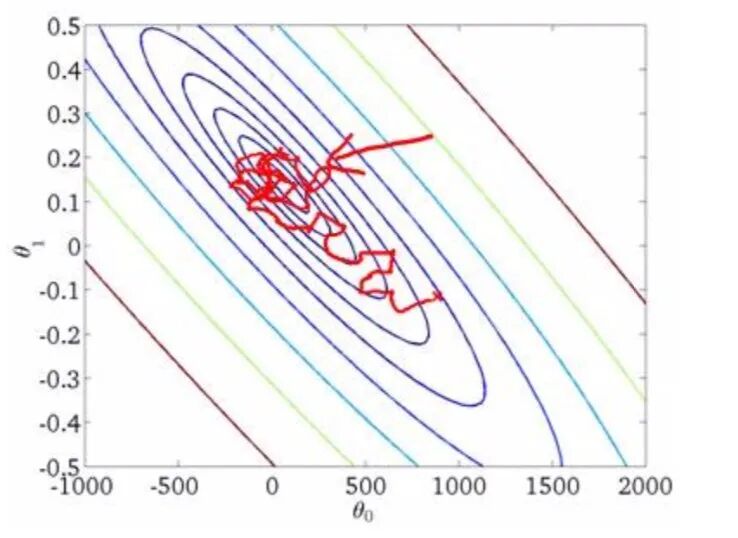
算法可能存在的问题
不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全 局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
小批量梯度下降 Mini-Batch Gradient Descent
小批量梯度下降算法是介于批量梯度下降算法和梯度下降算法之间的算法。每计算常数b次训练实例,便更新一次参数θ。参数b通常在2-100之间。

随机梯度下降收敛
随机梯度下降算法的调试和学习率α的选取
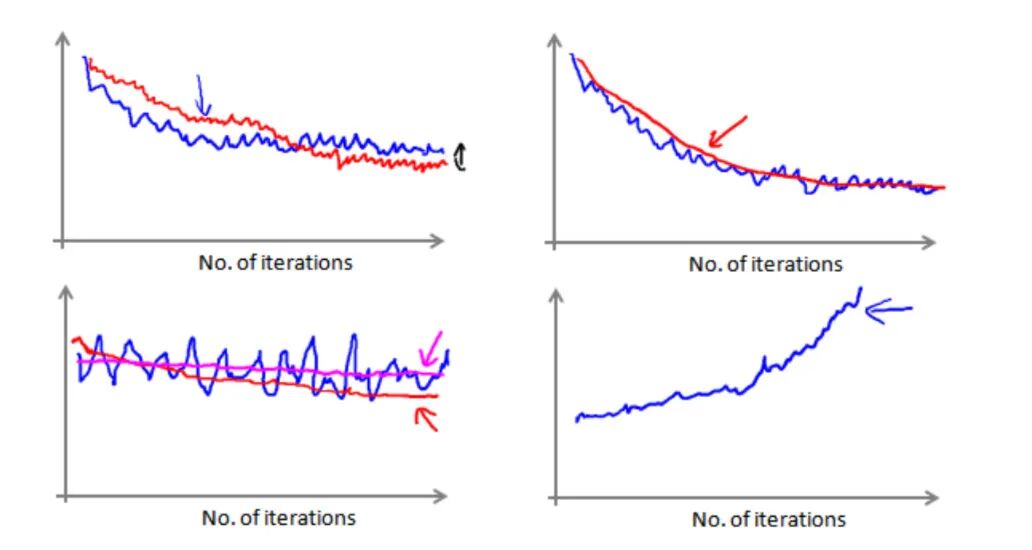
随着不断地靠近全局最小值,通过减小学习率,迫使算法收敛而非在最小值最近徘徊。
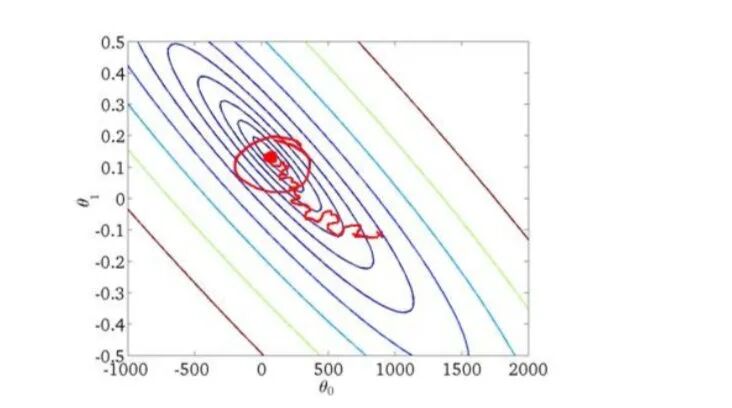
映射化简和数据并行Map Reduce and Data Parallelism
映射化简和数据并行对于大规模机器学习问题而言是非常重要的概念。如果我们能够将我们的数据集分配给不多台 计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样 的方法叫做映射简化。
如果任何学习算法能够表达为对训练集的函数求和,那么便能将这个任务分配给多台计算机(或者同台计算机的不同CPU核心),达到加速处理的目的。比如400个训练实例,分配给4台计算机进行处理:

图片文字识别(Application Example: Photo OCR)
问题描述和流程图
图像文字识别应用所作的事是从一张给定的图片中识别文字。

基本步骤包含:
文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
字符切分(Character segmentation)——将文字分割成一个个单一的字符
字符分类(Characterclassification)——确定每一个字符是什么 可以用任务流程图来表
每项任务可以有不同的团队来负责处理。

滑动窗口Sliding windows
图片识别
滑动窗口是一项用来从图像中抽取对象的技术。看一个栗子:
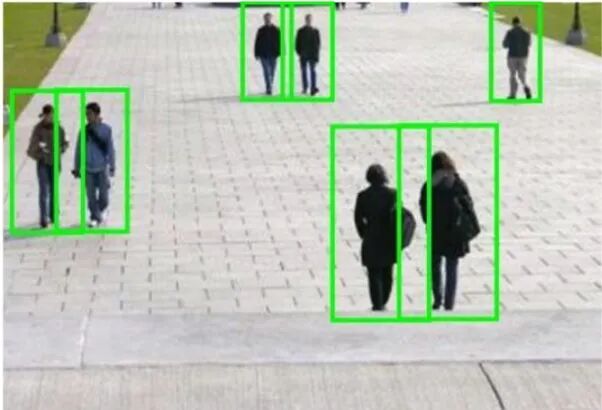
如果我们需要从上面的图形中提取出来行人:
文字识别
滑动窗口技术也被用于文字识别。

上述步骤是文字侦察阶段,接下来通过训练出一个模型来讲文字分割成一个个字符,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。

训练完成之后,可以通过滑动窗口技术来进行字符识别。该阶段属于字符切分阶段。

最后通过利用神经网络、支持向量机、或者逻辑回归等算法训练出一个分类器,属于是字符分类阶段。
获取大量数据和人工数据
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果。
获取大量数据的方法有
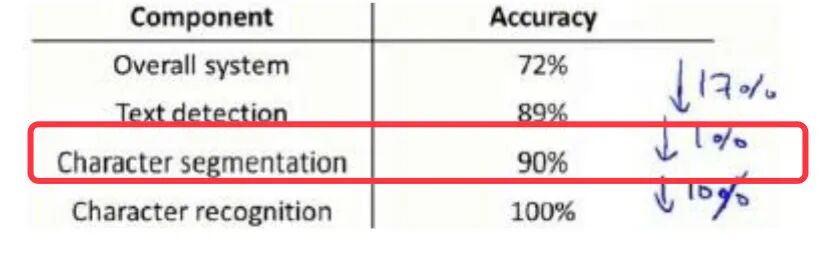
上限分析Ceiling Analysis
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够 知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到文字识别的应用中,流程图如下:
我们发现每个部分的输出都是下个部分的输入。在上限分析中,我们选取其中的某个部分,手工提供100%争取的输出结果,然后看整体的效果提升了多少。
扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)









