
转载声明:本文转载自「EAWorld」,搜索「eaworld」即可关注。
原文标题:The Gravity of Kubernetes
原文作者:Jeff Meyerson
普元云计算架构师宋潇男点评:
Kubernetes已在容器编排之战中取胜,未来很可能会成为“多云”之上的标准层,进而为分布式系统的分发和运行带来根本性的改变,而其自身则会慢慢变得像Linux Kernel一样,成为一种系统底层的支撑,不再引人注目。
原文的标题是The Gravity of Kuberrnetes,但是从内容上看,更像是近些年流行的“XXX is dead. Long live XXX.”的风格,所以在翻译标题的时候我们恶搞了一下。
本文金句:
Kubernetes已成为部署分布式应用的标准方式。
在不远的将来,任何新成立的互联网公司都将用到Kubernetes,无论其是否意识到这点。许多旧应用也正在迁移到Kubernetes。
在Kubernetes之前,特定的分布式系统平台还没有一个标准。正如Linux是针对单个节点的标准的服务器侧操作系统那样,Kubernetes已成为编排应用节点的标准方式。
通过Kubernetes,分布式系统工具将拥有网络效应。每当人们为Kubernetes制作出新的工具,都会让所有其它工具更完善。因此,这进一步巩固了Kubernetes的标准地位。
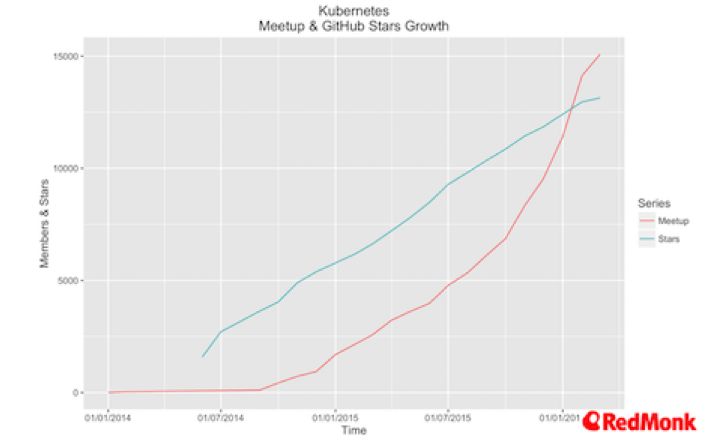
谷歌、微软、亚马逊和IBM都有自己的Kubernetes即服务产品,这让我们在大型云提供商之间切换基础设施变得更加简单。我们将很有可能看到Digital Ocean、Heroku和其它长尾型云提供商开始提供受管理的和托管Kubernetes服务。
在这边文章中,我将探讨以下问题:
标准化的软件平台有利有弊。
标准让开发者可以对软件的运行方式抱有一定的预期。如果一个开发者为某个标准化平台构建了某个东西,他可以评估出该软件的目标市场总规模。
如果你用JavaScript写了一个程序,你会知道它将会在所有人的浏览器中运行。如果你给iOS创作了一个游戏,你会知道每个有iPhone的人都可以下载它。如果你构建了一个工具来分析.NET中的垃圾收集,你会知道大量的Windows开发者会遇到内存问题,所以他们会购买你的软件。
标准化的专有平台可以给平台提供者创造大量的利润。1995年,Windows这个很好的平台让微软能够以100美元的价格售出一个只是纸盒子装着的光盘。2018年,iPhone这个很好的平台让苹果能够从平台所有的应用销售额中拿走30%。
但是专有的标准会导致分裂。
比如,你的iPhone应用无法在Kindle Fire上运行。我不能在Facebook Messenger(脸书信使)上使用你的Snapchat增强现实贴纸。我最喜欢的数字音频工作站[1]只能在Windows上使用,所以我不得不使用Windows电脑来制作音乐。
当开发者们见到这种分裂时,他们会抱怨。他们会联想到贪婪的资本家,这些资本家为了赚钱,不惜牺牲软件的质量。开发者们会想:“为什么人们不能和谐共处?”为什么我们不能让所有东西开放和免费?
开发者们还会想:“我们不需要专有标准。我们可以拥有开放标准。
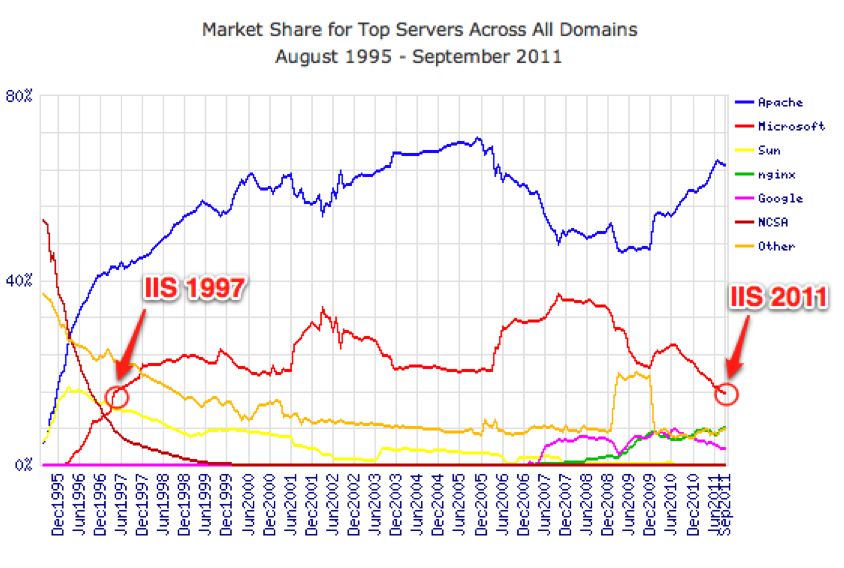
Apache的增长,Apache是LAMP (Linux、 Apache、MySQL和PHP)堆栈的一部分
Linux就曾发生过这样的事。现在,大多数新的服务侧应用都在使用Linux。但曾经有一段时间,人们对此有争议。见上图的左侧远端部分。
最近,我们还看到了一个更新的开放标准:Docker。Docker给了我们一个开放、标准化的打包、部署和分布单个节点的方法。这极其有价值!但在Docker解决的所有大问题之中,有个新的问题非常突出,那就是我们应该如何将这些节点编排到一起?
毕竟,你的应用肯定不只是单个节点。你知道自己希望部署一个Docker容器,但是容器应该如何相互通信呢?你如何向上扩展容器实例呢?你如何在容器实例之间路由流量呢?
在Docker流行之后,一大批开源项目和专有平台纷纷出现,以解决容器编排的问题。
Mesos、Docker Swarm和Kubernetes均提供了不同的抽象来管理容器。Amazon ECS提供了一个专有的受管的服务,它可以为AWS用户提供Docker容器的安装和扩展服务。
有些开发者并未采用任何编排平台,而是使用BASH、Puppet、Chef和其它工具来为他们的部署编写脚本。
无论一个开发者是否使用编排平台或者脚本来部署容器,Docker都可以加快开发,并且让开发者和运营之间更加和谐。

随着愈来愈多的开发者使用Docker来部署容器,编排平台的重要性日益突出。容器对于分布式系统的重要性就如同对象对于面向对象程序的重要性那样[2]。所有人都希望使用容器平台,但是众多平台之间存在着竞争,很难看出哪个平台会最终胜出,所以这可能会是持续十多年的竞争,就如iOS和安卓的竞争那样。
这样的竞争正在制造分裂。这并不是因为流行的编排框架是专有的(Swarm、Kubernetes和Mesos都是开源的),而是因为每个容器编排社区都已经在自己的系统上投入了太多资金。
所以,从2013到2016年,Docker用户一直有种隐忧。选择容器编排框架就像一次豪赌,如果你选择了错误的编排系统,这就好像你开了一家影像店,却选择了高清DVD,而不是蓝光光碟[3]。

集装箱(container)船倾覆的图片从不过时。图片来源:Huffington的帖子
容器编排的战争给人感觉就像是一场赢家赢得一切的战争。
正如在所有战争中那样,总是有一层雾,让我们很难看透彼此。在我报道容器编排之战时,我曾用一条条播客记录我和容器编排专家的谈话,其中,我会问到这样的问题,”那么,哪一个容器编排系统会赢?“
我一直这么做,直到某个我十分景仰之人告诉我问这样的问题一点也没有意思,还不如评估一下不同编排商之间的技术权衡。
回首过去,我后悔自己被不同容器编排商之间的战争的故事所吸引。
当有关容器编排商的辩论如火如荼时,甚至是我这样的记者也被这样的情绪激发,并且认为这将是一场与派系斗争有关的故事时,那些最聪明的人大多数却正在进行着平静和科学的谈论。
容器编排之战并非是一场派系斗争,而更多的是观点和开发者工程学之间的差异。

好吧,或许容器编排之战并不只是观点之间的差异。因为这个领域将会创造大量财富。我们现在谈论的是与数十亿市值的老组织如银行、电信公司和保险公司之间的合同,这些组织正在逐步向云迁移。
如果你正在帮助电信公司迁移到正确的平台,那么你的业务会很好。但如果你拥护了错误的平台,最终你只会得到一仓库的高清DVD。
冲突最严重的时间大约是2016年底,那时有关于Docker可能出现分歧的传言,原因是因为Docker公司想改变Docker标准,以更好地适配其容器编排系统Docker Swarm[4]。但即使在那时,做一个乐观者仍然是明智的。
具有毁灭性的创新会带来痛苦,但它是一个进步的标志。在争取容器编排统治地位的斗争中,出现了许许多多的毁灭性创新。
但在2016底迷雾消散之后,Kubernetes成了明显的获胜者。
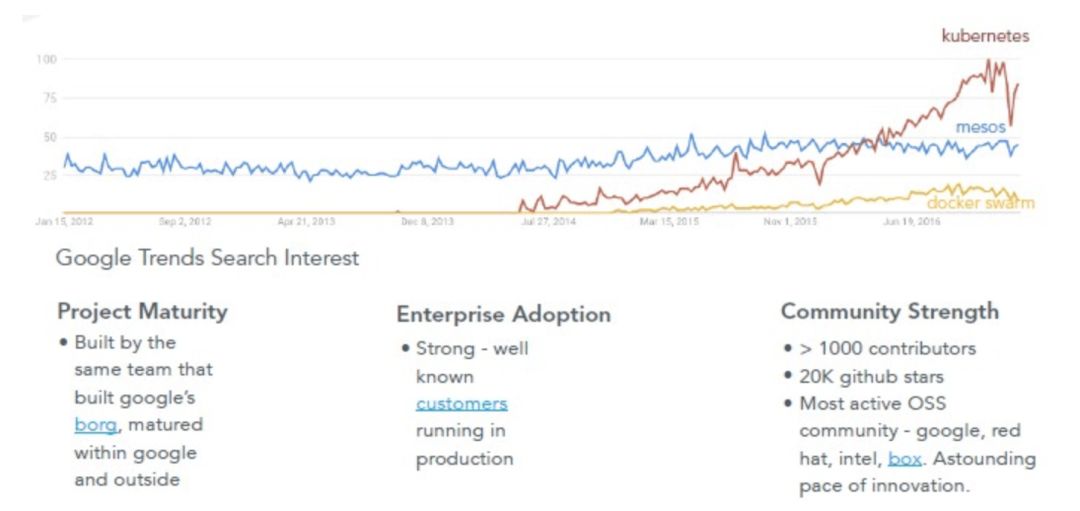
今天,随着Kubernetes成为保险的选择,CIO们对在企业中采用容器编排感到更安全了,这也让厂商更愿意投入到Kubernetes专用的工具中,并且把这些工具销售给这些CIO。
让我们来看看现状:
开源开发者正在朝同样的方向前进,并且为他们能构建的东西感到兴奋。
大公司(无论是新还是老)都在逐渐采用Kubernetes。
大型云提供商也准备好迎接低成本的Kubernetes即服务。
监控、日志记录、安全和合规软件厂商也极为激动,因为他们能更加容易地预测自己要集成的底层软件堆栈了。
今天,盈利最多的专有后端开发者基础设施提供商就是亚马逊AWS云服务。开发者并不憎恨AWS,因为AWS是创新和具备使能性的,并且便宜。如果你在AWS花了很多钱,那说明你的生意很好。
通过AWS,开发者不会感到90年代时的主导专有平台所给人的那种被锁定的感觉。但仍然有一些锁定感。一旦你深深地扎根于AWS的生态系统中,并使用如DynamoDB、Amazon Elastic Container Service(弹性容器服务)、或Amazon Kinesis服务时,你会发现你很难再脱离亚马逊。
然而,由于Kubernetes为基础设施创造的是一个开放、共有的层,所以理论上,将你的Kubernetes集群从一个云提供商处”迁移到“另一个提供商那里是可行的。
如果你决定迁移你的应用,你需要重写应用的部分组件来停止使用亚马逊特定的服务(如亚马逊S3)。例如,如果你想要一个可以在任何云上运行的S3替代品,你可以配置一个带Rook[5]的Kubernetes集群,并使用与你在S3上使用的相同API 来存储对象到Rook上。
这是一个很好的选项,但是我还从未听说过谁真正地将他们的应用从云中迁走,除了Dropbox[6]之外,但他们的迁移是如此宏大,以至于耗费了2年半的时间[7]。
当然,除了Dropbox之外,肯定还有其他人也在亚马逊S3上投入了很多钱,虽然他们也想创造自己的对象存储,但是迁移会非常费力。
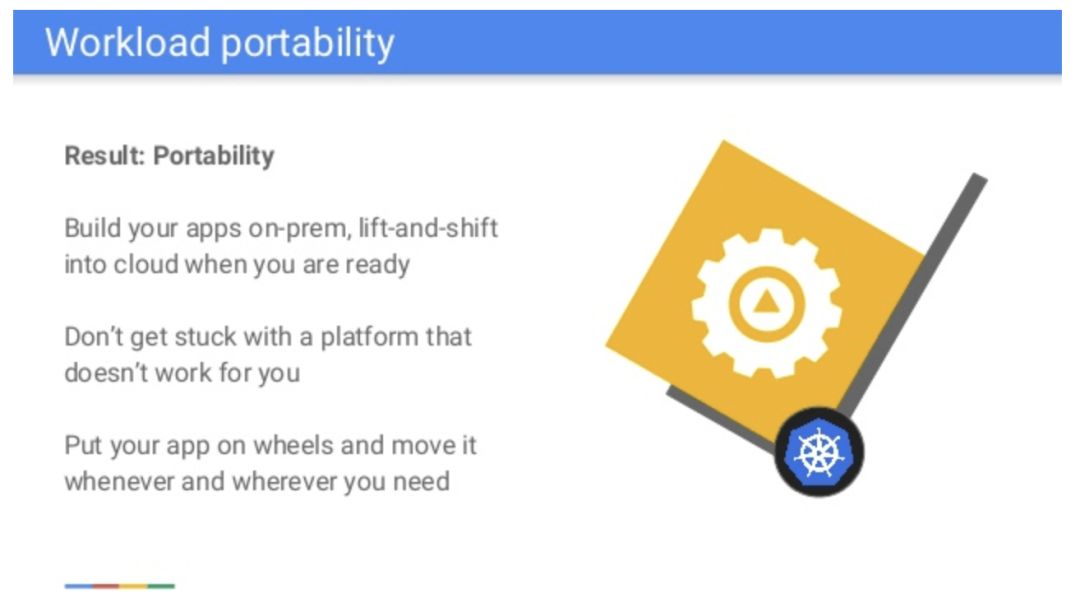
(Kubernetes可以被用于迁移应用,但更可能会用于在不同的云之中提供相似的操作层)
在不远的将来,Kubernetes或许不会成为一个广泛用于应用迁移的工具。更可能的情况是Kubernetes将会成为一个无所不在的控制平面,企业可以在多个云上使用它。
NodeJS便是一个有用的类比。为什么人们喜欢NodeJS的服务器侧应用?这并不一定是因为NodeJS是最快的web服务器,而是因为人们喜欢在客户端和服务器上使用相同的语言。NodeJS可以让你在客户端和服务器节点切换,而无需切换语言,同样,Kubernetes也能让你在不同的云之间切换,而无需改变运营方式。
在每个云上,你都会有一些定制的应用代码,它们由Kubernetes运行,并且与那个云提供的受管服务进行交互。
企业希望多云化,部分是因为容灾的考虑,但还因为访问不同云上的受管服务有实际的好处。
一个新出现的模式是将基础设施分布于AWS(用于用户流量)和Google Cloud(用于数据工程)上。Thumbtack[8]公司正在使用此模式。
在Thumbtack,位于AWS的生产基础设施负责处理用户请求。事务日志将从AWS推送到Google Cloud,并在那里进行数据工程。在Google Cloud上,事务记录在Cloud PubSub中排队。Cloud PubSub是一个信息队列服务。这些事务会从队列里被抽出,并存储在BigQuery中,BigQuery是一个存储和查询大量数据的系统。
BigQuery充当编排机器学习任务时的数据池,以便人们从中抽取数据。这些机器学习任务是在Cloud Dataproc中运行的,Cloud Dataproc是一个运行Apache Spark的服务。在Google Cloud上训练好一个模型之后,这个模型会被部署到AWS侧,然后处理用户流量。在Google Cloud侧,这些不同的受管服务的编排是由Apache Airflow完成的。Apache Airflow是一个开源工具。Thumbtack在Google Cloud上管理自己时,需要Apache Airflow。
今天,Thumbtack用AWS来处理用户请求,并用Google Cloud来进行PubSub中的数据工程和排队。Thumbtack在谷歌中训练其机器学习模型,并将它们部署到AWS中。
这就是今天我们常见的现象。Thumbtack最终或许还会将Google Cloud用于面向用户的服务。
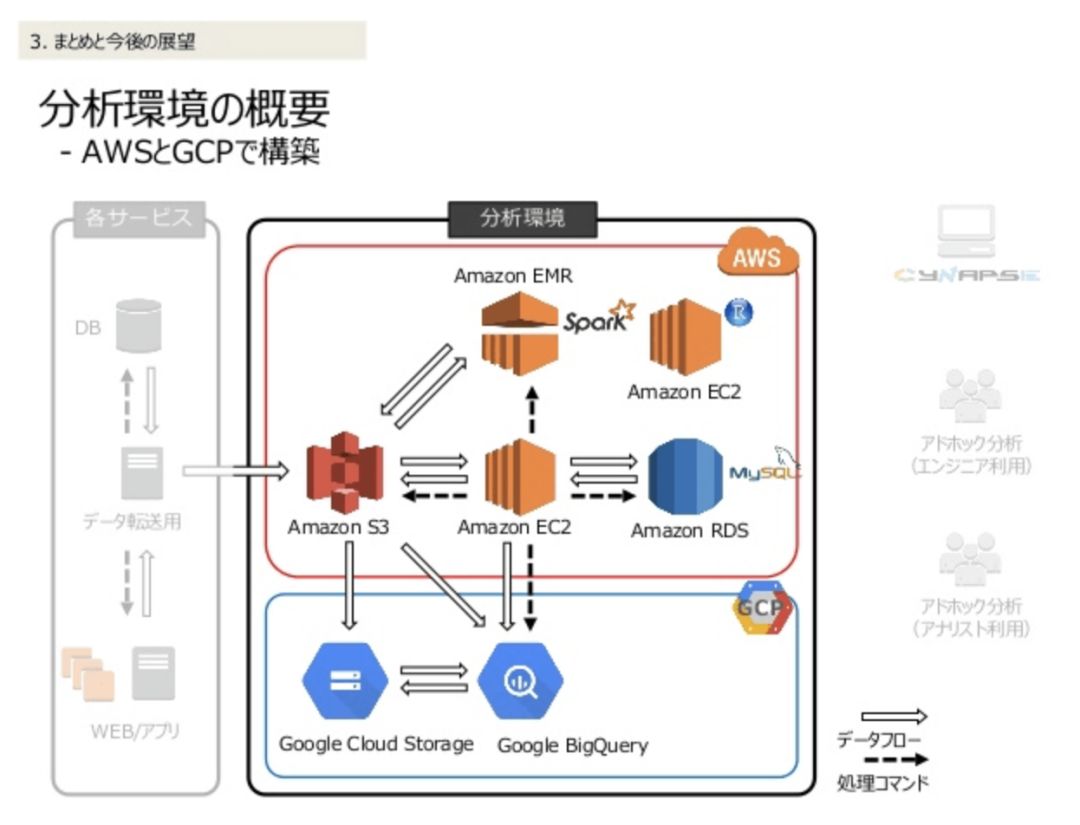
(某家日本公司采用的多云化的数据工程流水线)
越来越多的公司将逐渐迁移至多个云,而且它们当中的某些公司会在每个云上管理独立的Kubernetes集群。
你可能在谷歌上有一个GKE Kubernetes集群来编排BigQuery、Cloud PubSub和Google Cloud ML之间的负载,而且你可能会有一个Amazon EKS集群来编排DynamoDB、 Amazon Aurora和你的生产NodeJS应用之间的负载。
云提供商并非可替换的商品。不同的云提供的服务会变得越来越独特和不同。如果可以访问不同的云提供商提供的不同服务,那么企业将因此受益。
Google BigQuery 等 AWS Redshift服务十分流行,因为它们给了你强大、可扩展和多节点的工具,而且API还简单。开发者经常选择这些受管服务,因为它们是如此好用。
针对单个节点的付费工具并不常见。我不需要给NodeJS、React或Ruby on Rails付费。
针对单个节点的工具比针对分布式系统的工具用起来更容易。相比于在我的笔记本上运行Ruby on Rails应用来说,在许多服务器上部署Hadoop难多了。然而,有了Kubernetes后,这一切都将改变。
如果你正在使用Kubernetes,你可以使用一个名叫Helm的分布式系统包管理器。它就好比是用于Kubernetes应用的npm。如果你正在使用Kubernetes,无论你使用的是哪个云提供商,你都可以用Helm来轻松安装一个复杂的多节点应用。
下面是对Helm的描述:
Helm帮助你管理Kubernetes应用。Helm Charts帮助你定义、安装和升级Kubernetes应用,无论它们有多复杂。Charts很容易创建、进行版本控制、共享和发布,所以请开始使用Helm吧,停止复制-粘贴的疯狂举动。
一个用于分布式系统的包管理器。不可思议!让我们看看我们能安装的东西。
未列出的还有WordPress、Jenkins和Kafka
分布式系统配置很难,不信就去问问配置过Kafka集群的人。Helm将使安装Kafka 像在你的MacBook上安装新版Photoshop那样简单。 而且你可以在任何云上这么做。
在Helm之前,最接近分布式系统软件包管理器(就我所知道的)的东西是AWS[9]或Azure[10]或Google Cloud Launcher[11]上的应用市场。在这里,我们再次看到了专有软件如何导致分裂。在Helm之前,没有任何一个标准的、与平台无关的一键安装Kafka的方法。
你可以在AWS、Google或Azure上找到一键安装Kafka的方法。 但是,这些安装中的每个都必须独立编写,以供每个特定的云提供商使用。 而要在Digital Ocean上安装Kafka,则需要遵循这个10步教程[12]。
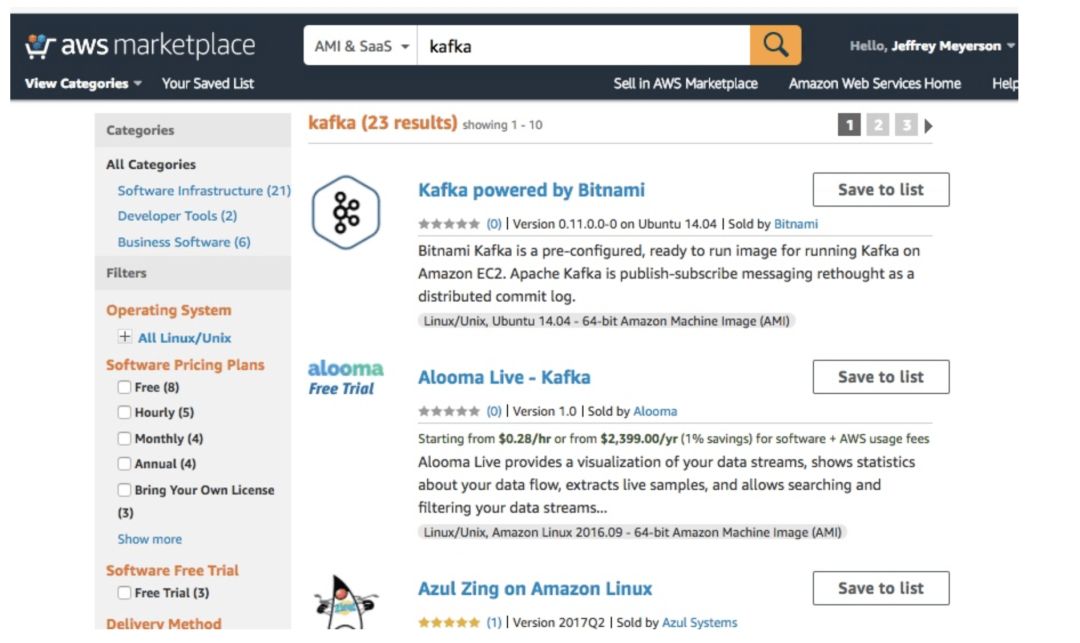
Helm是一个在任何Kubernetes实例上分布多节点软件的跨平台系统。 你可以在任何云提供商那里或你自己的硬件上使用已安装有Helm的应用。 你可以轻松安装Apache Spark或Cassandra系统。众所周知,它们都是难以设置和操作的。
Helm是Kubernetes的包管理器,但它看起来也像是Kubernetes应用商店的雏形。 有了应用商店,你就可以出售用于Kubernetes的软件。
你可以卖什么样的软件?
你可以销售Cloudera Hadoop,Databricks Spark和Confluent Kafka等分布式系统平台的企业版。 或者难以安装的Prometheus等新型监控系统和Cassandra等多节点数据库。
也许你甚至可以销售像Zendesk这样的更高级的消费级软件。
自主托管Zendesk的想法听起来很疯狂,但是有人的确可以构建它,并以专有二进制文件的形式出售,以固定费用而不是订阅进行收费。 如果我向你出售价值99美元的Zendesk-for-Kubernetes,并且你可以在AWS上的Kubernetes集群上轻松运行它,那么你将在工单软件上节省大量支持费用。
企业经常运行自己的WordPress来管理公司的博客。 Zendesk的软件比WordPress更复杂吗? 我不这么认为,但比起管理自己的博客软件,企业更害怕管理自己的Help Desk软件。
我经营了一家非常小的公司,但我订阅了很多不同的软件即服务工具。 包括一个昂贵的WordPress主机,一个用于广告销售的昂贵的CRM软件,和用于通讯简报的MailChimp。 我支付这些服务是因为它们超级可靠和安全,而且它们也是复杂的多节点应用。 我不想在自己的机房里运行它们。我也不想自己管理它们。 当我的简报发送失败时,我不想自己排除技术故障。 我不想运行太多的软件[13]。
相比之下,我并不担心我的单机软件出错。
我在单机软件上的开销往往要便宜得多,因为我不需要把它们作为服务购买。 我用来写音乐的软件有一次性的固定成本。 Photoshop有一次性固定成本。 我支付电费来运行我的电脑,但除此之外,我不需要持续的资本支出才能运行Photoshop。
当多节点应用与单节点应用一样可靠时,我们将看到定价模型的变化。
也许有一天我可以购买Zendesk-for-Kubernetes。 Zendesk-for-Kubernetes将会给我提供我需要的所有东西 - 它将启动一个电子邮件服务器,它会给我一个网络前端来管理工单。 如果出现任何问题,我可以在需要支持时支付费用。
Zendesk是一个非常棒的服务,但如果它有一个固定的定价模式,那将会更好。
借助Kubernetes,部署和管理分布式应用程序变得更加容易。 借助Helm,将这些应用程序分发给其他用户变得更加容易。 但是开发分布式系统还是相当困难的。
这是Brendan Burns最近所作的一篇CloudNative Con / KubeCon主题演讲的焦点,那个演讲的题目为“构建新工具、模式和范例来让分布式系统开发更加大众化的工作实在太难了[14]”。
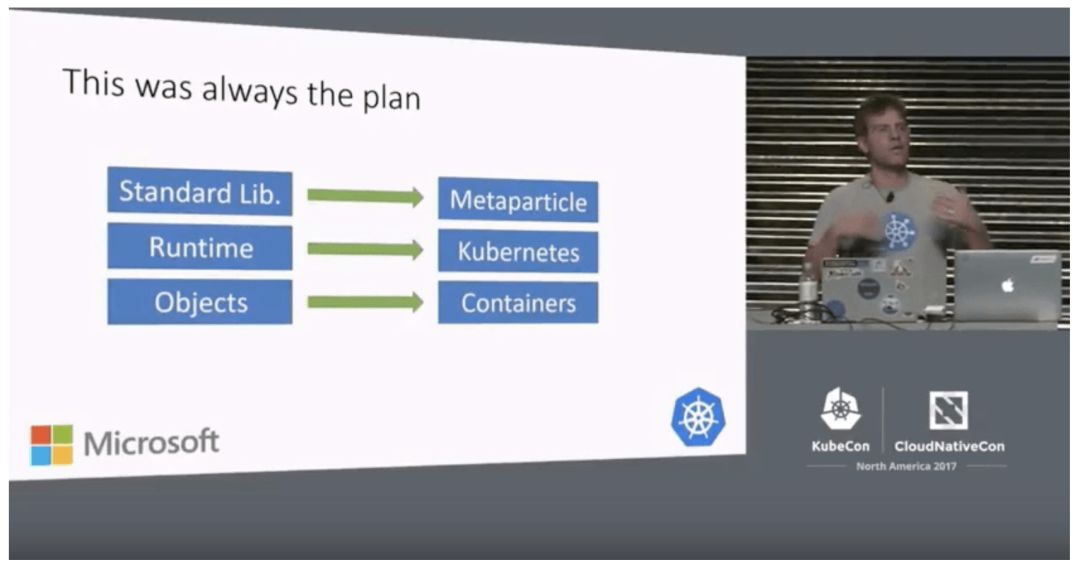
Brendan在发言中提出了一个名为Metaparticle的项目。 Metaparticle是云原生开发的标准库,其目标是实现分布式系统的大众化。 Brendan在对Metaparticle的介绍[15]中写道:
云原生开发是定制且复杂的,而且仅限于少数专家开发人员。 Metaparticle通过在熟悉的编程语言中引入一系列实用程序来改变这种状况,这些实用程序符合开发人员当前的处境,并使他们能够使用熟悉的语言开始开发云原生系统。
Metaparticle建立在Kubernetes原语的基础上,而且它使分布式协调更容易。 Metaparticle提供独立于语言的模块,用于锁定和主选举,并把这些模块作为熟悉的编程语言中易于使用的抽象。
经过几十年的分布式系统研究和应用,我们如何构建这些系统的模式已经显现。 我们需要一种方法来锁定一个变量,这样两个节点便不能以非确定性的方式写入该变量。 我们需要一种方法来做主选举,以便在主节点死亡时,其他节点可以选择一个新节点来编排系统。
今天,我们使用etcd和Zookeeper这样的工具来帮助我们进行主选举和锁定,而这些工具都有接入成本。
Brendan用Zookeeper的例子来说明这一点。Hadoop和Kafka都使用Zookeeper来做主选举。 你需要花费大量的时间和精力来学习如何操作Zookeeper。 在构建Hadoop和Kafka的过程中,这些项目的创始工程师设计的系统可以与Zookeeper协作,共同来维护一个主节点。
如果我正在编写一个系统来执行分布式MapReduce,我希望不考虑节点故障和竞争条件。 Brendan的想法是将这些问题推到一个标准的库中,从而让下一个开发人员为多节点应用程序提出新想法更加容易。
重要的元点:使用Metaparticle的前提是使用Kubernetes。 Metaparticle是一个语言层级的抽象,它是建立在对底层(分布式)操作系统的假设之上的。这再一次使我们回到了标准这一话题。 如果每个人都在同一个分布式操作系统上,我们可以对我们项目的下游用户做出更大的假设。
这就是为什么我会被Kubernetes洗脑的原因。 它是跨越异构系统的一个标准层。
功能即服务(通常称为“无服务器”功能)是一种功能强大且价格低廉的抽象,开发人员可以与Kubernetes一同使用它,在Kubernetes之上使用它,或者在某些情况下,单独使用它。
让我们快速回顾无服务器应用程序的现状,然后考虑无服务器和Kubernetes之间的关系。
功能即服务的快速回顾[16]:
功能即服务是无需依赖特定服务器运行的可部署功能。
功能即服务旨在部署、执行和扩展开发人员的单个调用。 在你调用无服务器功能之前,你的功能并没有在任何地方运行 - 所以你并未使用任何资源,除了存储原始代码的数据库以外。 当你把一个功能作为服务调用时,你的集群将负责调度和运行该功能。
你不必考虑启动一台新机器并监控该机器,或者在机器闲置时停机。 你只需告诉集群你想要运行一个功能,然后集群将执行它并返回结果。
在部署无服务器功能时,功能代码实际上并未被部署。 你的代码将以纯文本形式保存于数据库中。 当你调用这个功能时,你的代码将从数据库入口中取出,加载到一个Docker容器中并执行。
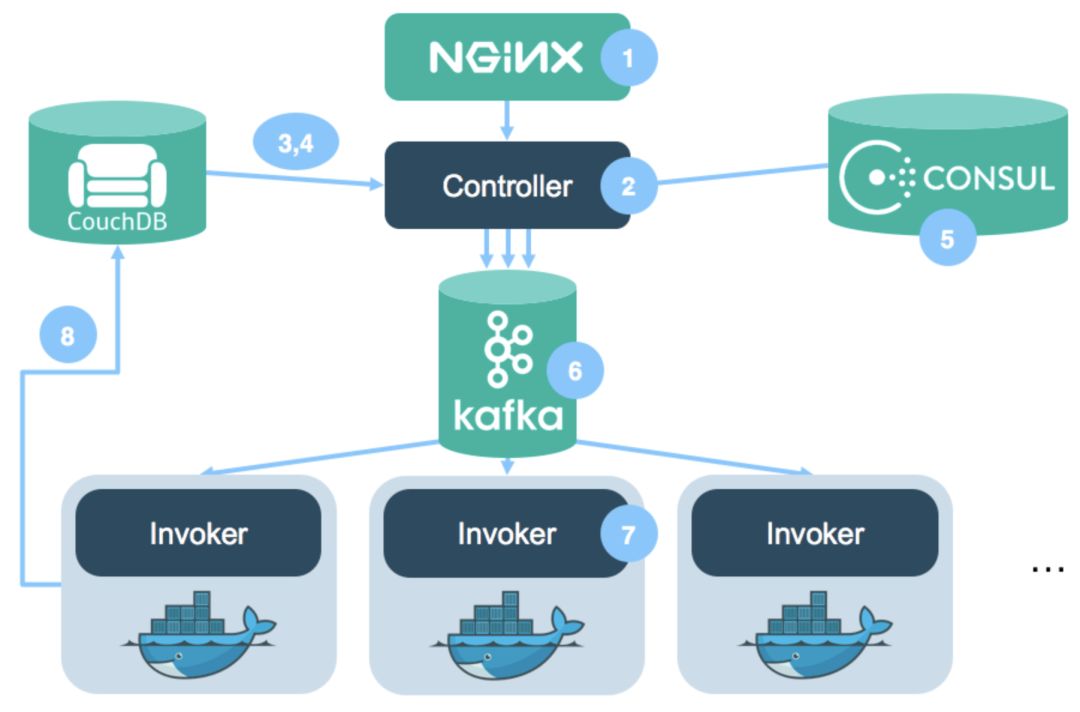
(来自https://medium.com/openwhisk/uncovering-themagic-how-serverless-platforms-really-work-3cb127b05f71的图表)
AWS Lambda在2014年开创了“功能即服务[17]”的理念。 从那以后,开发人员一直在思考各种用例。 有关开发人员如何使用无服务器的完整列表,请参见CNCF无服务器工作组创建的共享Google文档(本文发布时文档为34页)[18]。
从我在《软件工程日报》上的交谈中来看,这些作为服务的功能至少有两个明显的应用例子:
为了创建一个功能即服务(FaaS)平台,云提供商提供了一个名为调用者(invokers)的Docker容器集群。 这些调用者等待得到调配给他们的大块代码。 当你要求你的代码执行的时候,你必须等待一段时间用于将代码加载到调用者并执行。 这个等待便是“冷启动”的问题。
冷启动问题是你决定在FaaS上运行部分应用时必须做的折衷之一。 你不需为没有进行任何工作的服务器的运行时间付费 - 但是当你想调用功能时,你必须等待代码被调配给一个调用者。
在AWS上,会为AWS Lambda的请求指定调用者。 在Microsoft Azure上,会为Azure Functions请求指定调用者。 在Google Cloud上,会为Google Cloud Functions保留调用者。
对于大多数开发人员来说,使用AWS、Microsoft、Google或IBM的“功能即服务”平台都可以。 因为成本低,冷启动问题对于大多数应用来说不成问题。 但是一些开发者会想要更低的成本。 或者他们可能希望编写自己的调度器,该调度器会定义如何将代码调度到调用者容器上。 这些开发人员可以推出自己的无服务器平台。
像Kubeless这样的开源FaaS项目可以让你在Kubernetes之上配置你自己的无服务器集群。 你可以定义自己的调用者池。 你可以确定如何按照计划调度容器。 你可以决定如何解决你的集群的冷启动问题。
Kubernetes的开源FaaS只是一种资源调度器。 它们只是Kubernetes之上的其他自定义调度器的预览。 开发人员总是在构建新的调度器,以便在这些调度器之上构建更高效的服务。
那么,在Kubernetes之上还有哪些其他类型的调度器? 那么,正如他们所说,未来已经到来,但这些调度器只能作为一个AWS受管服务被提供。
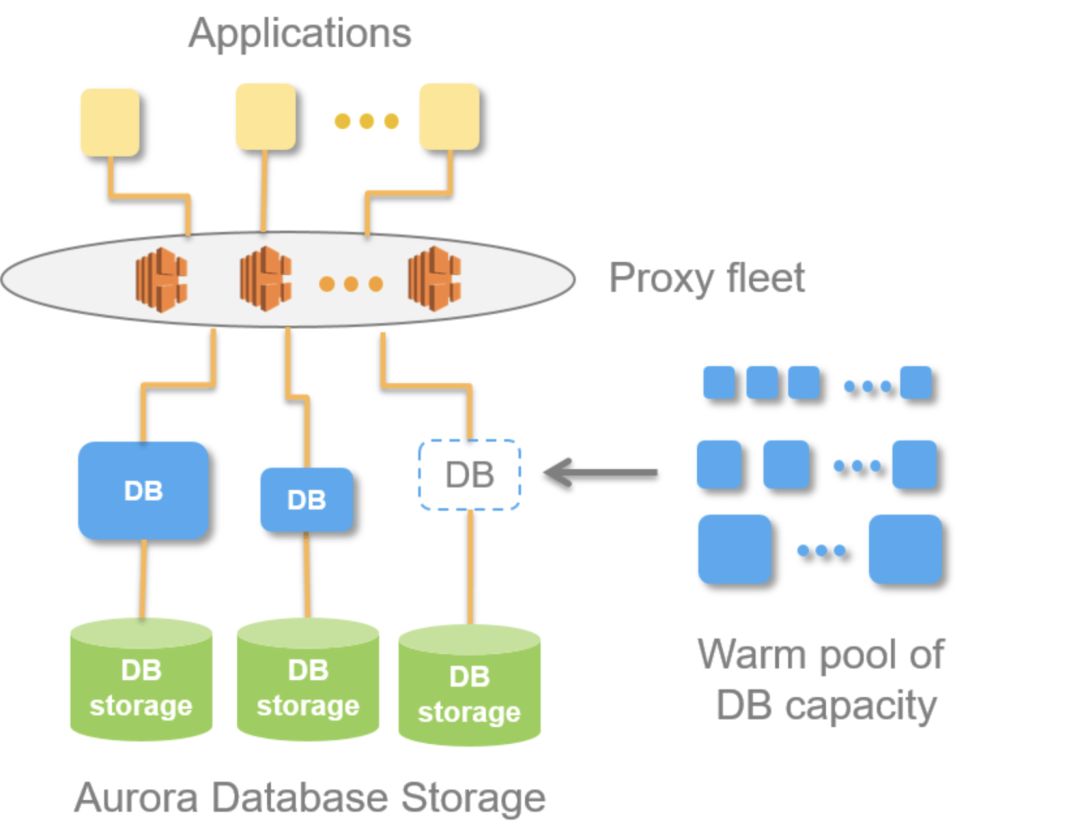
AWS有一项名为Amazon Aurora Serverless的新服务,它是一种自动扩展存储和计算的数据库。 来自Jeff Barr关于AWS Serverless Aurora的帖子[20]:
当创建Aurora数据库实例时,你可以选择所需的实例大小,并可以选择使用读副本提高读取吞吐量。 如果你的处理需求或查询速率发生变化,你可以选择修改实例大小或根据需要更改读副本的数量。 这个模型在工作负载可预测、并且请求速率和处理需求在一定范围内的环境下运行得非常好。
在某些情况下,工作负载可能是间歇性的和/或不可预知的,并且可能每天或每周只能出现持续几分钟或几小时的突发请求。 闪电销售、不频繁的或一次性的事件、在线游戏、报告工作负载(小时或每天),开发/测试和全新的应用都符合该条件。 做出适当的容量规划可能需要做很多工作; 稳定地付费可能是不明智的。
由于存储和处理是分开的,因此可以将规模一直缩小到零并仅支付存储费用。 我觉得这真的很好,而且我期望它可以带来新型的瞬时应用程序的出现。 扩展只需要几秒钟,并基于一池子“热”资源之上进行构建,这些资源急切地渴望满足你的要求。
AWS可以构建这样的东西,我们并不感到惊讶,但是很难想象它会成为一个开源项目 - 直到Kubernetes出现。任何开发人员都可以在Kubernetes之上构建的这类系统。
如果你想在Kubernetes之上构建自己的无服务器数据库,则需要解决一些调度问题。 网络、存储、日志记录、缓冲和缓存需要不同的资源层级。 对于每个不同的资源层,你需要定义资源如何按照需求进行扩展和缩减。
就像Kubeless为功能代码的一小部分提供调度器一样,我们可能会看到其他自定义调度器被人们用作更大应用的构建块。
一旦你真正建立你的无服务器数据库,也许你可以把它卖到Helm 应用程序商店,一次性购买它只需要99美元。
我希望,通过一些Kubernetes的历史和对未来的猜测,你能享受这次旅程。
2018年已经开始,这些将是我们今年想要探索的一些领域:
人们如何管理在Kubernetes上机器学习模型的部署? 我们和Matt Zeiler一起做了一个展示[21],他讨论了这个问题,听起来很复杂。
Kubernetes是否用于无人驾驶汽车? 如果是这样,你是否部署了一个集群来管理整个汽车?
Kubernetes 物联网部署是什么样的? 在具有间歇性网络连接的一组设备上运行Kubernetes是否有意义?
用Kubernetes构建的新的基础设施产品和开发工具有哪些? 什么是新的商业机会?
Kubernetes是构建现代应用后端的绝佳工具 - 但它仍然只是一个工具。
如果Kubernetes完成其使命,它最终会消失,成为背景。 将来,我们会像讨论编译器和操作系统内核一样讨论Kubernetes。Kubernetes将会是低层级的管路系统,而不在普通应用开发人员的视野之内。
对但在那成为现实之前,我们仍会对Kubernetes继续报道。
原文链接:
https://softwareengineeringdaily.com/2018/01/13/the-gravity-of-kubernetes/
参考地址:
[1] https://www.image-line.com/flstudio/
[2] https://youtu.be/gCQfFXSHSxw?t=611
[3] https://en.wikipedia.org/wiki/High-definition_optical_disc_format_war
[4] https://softwareengineeringdaily.com/2016/10/03/docker-fork-with-alex-williams-and-joab-jackson/
[5] https://rook.io
[6] https://softwareengineeringdaily.com/2016/05/17/dropboxs-magic-pocket-james-cowling/
[7] https://www.wired.com/2016/03/epic-story-dropboxs-exodus-amazon-cloud-empire/
[8] https://softwareengineeringdaily.com/2017/11/28/thumbtack-infrastructure-with-nate-kupp/
[9] https://aws.amazon.com/marketplace
[10] https://aws.amazon.com/marketplace
[11] https://cloud.google.com/launcher/
[12] https://www.digitalocean.com/community/tutorials/how-to-install-apache-kafka-on-ubuntu-14-04
[13] https://softwareengineeringdaily.com/2017/11/20/run-less-software-with-rich-archbold/
[14] https://www.youtube.com/watch?v=gCQfFXSHSxw
[15] https://metaparticle.io/posts/welcome-to-metaparticle/
[16] https://www.softwaredaily.com/#/post/5a251d5f0cbcbe0004c932e1
[17] https://aws.amazon.com/cn/blogs/aws/run-code-cloud/
[18] https://docs.google.com/document/d/1UjW8bt5O8QBgQRILJVKZJej_IuNnxl20AJu9wA8wcdI/edit#heading=h.yiaul8is1ki
[19] https://softwareengineeringdaily.com/2017/08/04/serverless-startup-with-yan-cui/
[20] https://aws.amazon.com/cn/blogs/aws/in-the-works-amazon-aurora-serverless/
[21] https://softwareengineeringdaily.com/2017/05/10/convolutional-neural-networks-with-matt-zeiler/
《Linux云计算及运维架构师高薪实战班》2018年05月14日即将开课中,120天冲击Linux运维年薪30万,改变速约~~~~
*声明:推送内容及图片来源于网络,部分内容会有所改动,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
- END -

更多Linux好文请点击【阅读原文】哦
↓↓↓









