简介
大量经济学研究涉及到文本处理,比如根据一条帖子的内容判断作者是否支持这位总统;又比如通过分析一段演讲,判断演讲者对这一问题是否乐观等……随着自然语言处理的发展,我们可以利用计算机对文本的感情倾向进行相对客观的判断,从而使得研究更加可靠。本次推送中,我们介绍如何使用Python的snowNLP库进行文本情绪判断。
推送中用到的文件可以点击“阅读原文”获取,密码为0aq6。
安装
本文使用到的snowNLP是一个中文文本处理模块,我们可以用它来对句子进行分词、断句、词性判断和情感分析等。和往期推送相同,首次使用之前我们需要先安装该库。在cmd下输入
pip3 install snowNLP
完成安装。该库较大,可能下载速度较慢,请耐心等待。
进行情感判断
from snownlp import SnowNLP #从库中导入SnowNLP
text1 = '我爱学习,学习使我快乐。' #输入需要进行分析的文本
nlp1 = SnowNLP(text1) #利用SnowNLP函数进行分析
nlp1.words #查看分词结果
nlp1.sentiments #查看情感倾向

输出结果如下:
['我', '爱', '学习', ',', '学习', '使', '我', '快乐', '。']
0.9994997439951893
从中看到,该函数不仅准确地将词语区分开来,还对这句话打出了0.999的高分,这意味着这句话含义非常积极——SnowNLP.sentiment返回的值介于[0,1]之间,越接近1代表这句话越积极,而接近0则代表否定消极的情绪。
下面我们展示一个文本有否定含义的例子:

>>> text2 = '谁说的?我没说过。告辞。'
>>> nlp2 = SnowNLP(text2)
>>> nlp2.sentiments
0.14084892354986367
结果仅为0.14,snowNLP做出了准确的判断,认为这段文本有否定含义。
实例
下面,我们选择莫泊桑的著名小说《我的叔叔于勒》进行分析。这篇小说有非常明显的情绪变化,主人公一家起先对叔叔于勒持有积极态度,但后来转变为厌恶。因此,我们利用snowNLP对小说进行逐段分析,观察sentiments值是否会像我们预期一样,先高后低。
# 读入小说全文
with open('text.txt', 'r') as f: #读者可以自己选择不同的文本,这一示例中的文本可以点击原文链接获得,密码为0aq6
text = f.readlines()
para = [i.rstrip('\n') for i in text]
# 对para中的每一段进行情感倾向分析
senti = [SnowNLP(i).sentiments for i
in para]
# 取横坐标为段落编号,纵坐标为分值,画成散点图
import matplotlib.pyplot as plt #如果报错,请先安装matplotlib和numpy库,方法同安装snowNLP一样
import numpy as np
x = np.array(range(len(senti)))
y = np.array(senti)
plt.scatter(x,y)
plt.show()
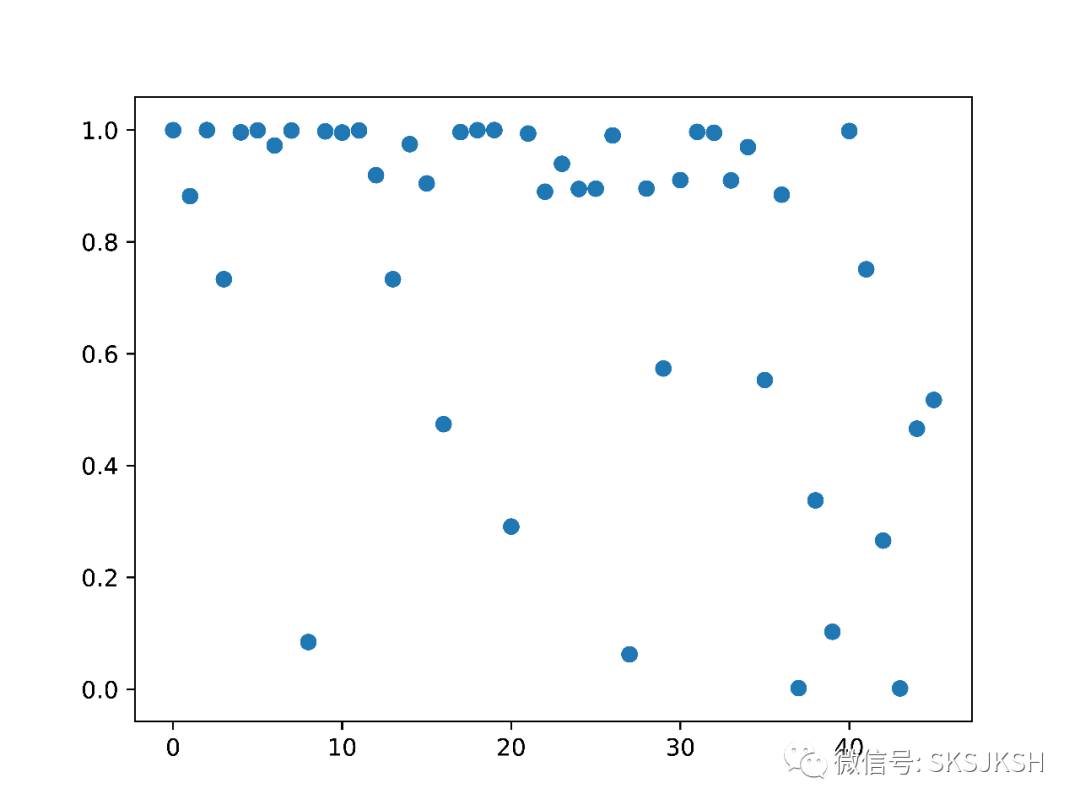
不难看出,随着小说的推进,文章的情绪从积极转向消极,符合我们的预期。
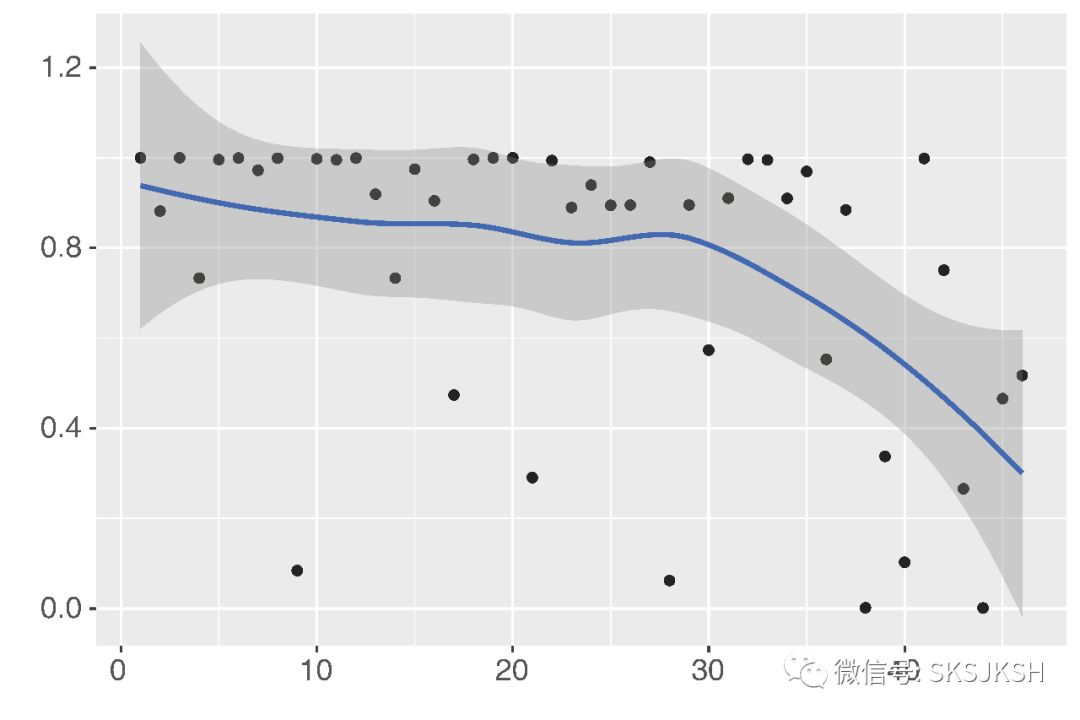
我们也可以对这些散点做平滑处理,从而更直观地看出文章情绪的变化趋势。
注:操作平台为PyCharm 2017. 3. 2 (Python 3. 6. 3)
广受欢迎的微信公共账号“社会科学中的数据可视化”每周推送ArcGIS、Python、R、Stata等软件在社会科学各领域中的运用实例及教程。本帐号由复旦大学经济学院陈硕教授及其团队负责。欢迎媒体及学界与我们展开内容合作,联系邮箱sksjksh@163.com。查看以前推送:点“社会科学中的数据可视化”并选择“查看历史消息”。搜寻帐号: SKSJKSH或扫描二维码如下:











