继续学习 Python-Core-50-Courses,配套视频链接后台回复 Python语言基础视频 可获得原作者分享链接。
几篇推文进行回溯:
Python语言基础50课
Python语言基础50课(2)
我的Python - 100天笔记 |D1-D7
我的Python - 100天笔记 |D8-D14
今天的推文内容主要涵盖:集合& 列表生成式(统计ATCG含量);函数与模块(内置函数),下面就进入正题:
集合
我们常说的Python五大标准的数据类型为:
Numbers(数字)
String(字符串)
List(列表)
Tuple(元组)
Dictionary(字典)
还有一个数据类型日常用的比较少,因此没有怎么涉及。直到最近看到的一个案例,到也是一个方法。
我将例子简化到核心,需求为 统计一条序列的中 ATCG的含量,直接上代码:
myseq = 'CTAGCGCcttagcatcctatcatgttcacNNNATCTCTAGCGCGGCAT'
print([x+'% :{:.2%}'.format(myseq.count(x)/len(myseq)) for x in set(myseq.upper())])
上面的代码主要是两个点(1)列表生成式;(2)集合
上期我们提到的表达式:
[exp for
iter_var in iterable]
也就是说,一般情况下,我们去遍历ATCG,上述的代码也会根据下面的步骤进行:
myseq = 'CTAGCGCcttagcatcctatcatgttcacNNNATCTCTAGCGCGGCAT'
for x in set(myseq.upper()):
print(x+'% :{:.2%}'.format(myseq.count(x)/len(myseq)))
还有一个是集合,用到了其中的第二条特性,对序列去重,不同手写一个存一个列表:)
无序性:一个集合中的元素的地位都是相同的,元素之间是无序的。
互异性:一个集合中每个元素只能出现一次,即去冗余。
确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。
再者,顺便考虑了N的存在,在序列计算过程中我们使用了 upper() 函数进行统一大写,便于计算。
在Python中,创建集合可以使用{}字面量语法,{}中需要至少有一个元素,因为没有元素的{}并不是空集合而是一个空字典。
注意:不能通过 set = {} 定义一个空集合。
集合的计算
和数学中的集合概念一样,我们可以进行交集、并集、差集等运算。
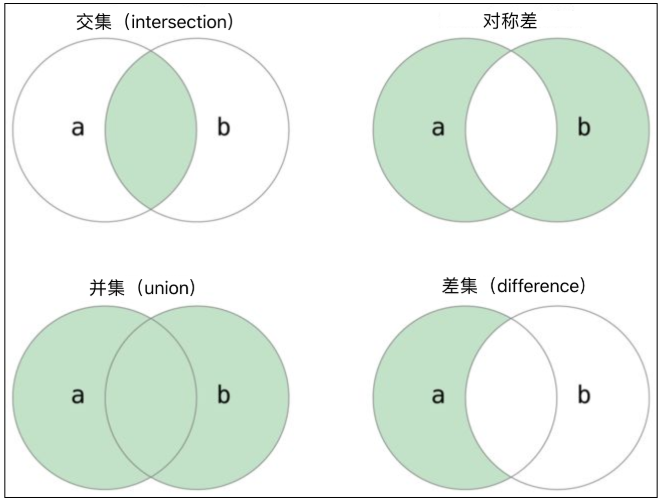
贴一个代码示例:
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
# 交集
# 方法一: 使用 & 运算符
print(set1 & set2) # {2, 4, 6}
# 方法二: 使用intersection方法
print(set1.intersection(set2)) # {2, 4, 6}
# 并集
# 方法一: 使用 | 运算符
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8, 10}
# 方法二: 使用union方法
print(set1.union(set2)) # {1, 2, 3, 4, 5, 6, 7, 8, 10}
# 差集
# 方法一: 使用 - 运算符
print(set1 - set2) # {1, 3, 5, 7}
# 方法二: 使用difference方法
print(set1.difference(set2)) # {1, 3, 5, 7}
# 对称差
# 方法一: 使用 ^ 运算符
print(set1 ^ set2) # {1, 3, 5, 7, 8, 10}
# 方法二: 使用symmetric_difference方法
print(set1.symmetric_difference(set2)) # {1, 3, 5, 7, 8, 10}
# 方法三: 对称差相当于两个集合的并集减去交集
print((set1 | set2) - (set1 & set2)) # {1, 3, 5, 7, 8, 10}
在交集的并集上,pandas中的 merge 函数也是一把好手,有兴趣可以翻阅一下 ↓↓↓
函数和模块
函数使用
我们之前聊过函数的基本写法及优势,也清楚函数名就可以认作是一个变量,因此在自定义函数时需要避免使用重复的名字去定义函数名,例如:
def foo():
print('hello, world!')
def foo():
print('goodbye, world!')
foo()
这个结果会怎么样?当然,一个项目或者简单实现功能的时候,不需要也不能够简单避免同一个变量名所带来的麻烦。但是,在多人开发的流程中会出现这个问题。因此,就要引入 模块这个概念来解决这个冲突。
模块是什么?
简单来说,每一个python文件可以看作一个模块,而不同的模块中函数名(变量名)可以重复。使用上面的例子来看,构建两个文件:
$ less module1.py
def foo():
print('hello, world!')
$ less module2.py
def foo():
print('goodbye, world!')
调用的几种方法:
import 过程中使用as关键字可以对模块进行别名;
import module1
import module2 as m2
module1.foo() # hello, world!
m2.foo() # goodbye, world!
使用from...import...语法从模块中直接导入需要使用的函数
from module1 import foo
foo() # hello, world!
from module2 import foo
foo() # goodbye, world!
内置函数说明
补充一下内置函数的说明,内置函数是指不需要import就能够直接使用:
详细内容可以点击原文查看官方文档
http://docs.python.org/3/library/functions.html
下面罗列结果不常见的进行说明:
| 函数 | 说明 |
|---|
bin | 把一个整数转换成以'0b'开头的二进制字符串,例如:bin(123)会返回'0b1111011'。 |
chr | 将Unicode编码转换成对应的字符,例如:chr(8364)会返回'€'。 |
hex |
将一个整数转换成以'0x'开头的十六进制字符串,例如:hex(123)会返回'0x7b'。 |
oct | 把一个整数转换成以'0o'开头的八进制字符串,例如:oct(123)会返回'0o173'。 |
ord | 将字符转换成对应的Unicode编码,例如:ord('€')会返回8364。 |
pow | 求幂运算,例如:pow(2, 3)会返回8;pow(2, 0.5)会返回1.4142135623730951。 |
一行代码的优雅,继续前行。
参考资料
pandas 0.25.3 documentation
jackfrued/ Python-Core-50-Courses
https://www.cnblogs.com/yyds/p/6281453.html
往期推荐
ComplexHeatmap包更新支持pheatmap转换
Python语言基础50课
Python语言基础50课(2)
生信技能树目前已经公开了三个生信知识库,记得来关注哦~
每周文献分享
https://www.yuque.com/biotrainee/weeklypaper
肿瘤外显子分析指南
https://www.yuque.com/biotrainee/wes
生物统计从理论到实践
https://www.yuque.com/biotrainee/biostat
友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
•生信爆款入门-全球听(买一得五)(第4期) ,你的生物信息学入门课。•数据挖掘第2期(两天变三周,实力加量),医学生/医生首选技能提高课。•生信技能树的2019年终总结 ,你的生物信息学成长宝藏•2020学习主旋律,B站74小时免费教学视频为你领路









