这一周的学习笔记,重点在于对常用的一些操作、代码进行整理,对于高阶编程如面向对象、多线程及网络编程记录一下基本概念,有兴趣支持原作者@骆昊。
D8-D9面向对象编程基础
"一切皆对象。"
类(英语:class)在面向对象编程中是一种面向对象计算机编程语言的构造,是创建对象的蓝图,用于描述具有相同属性和方法。
对象(英语:object),是一个存储器地址,其中拥有值,这个地址可能有标识符指向此处。对象可以是一个变量,一个数据结构,或是一个函数。

官方注释:
"把一组数据结构和处理它们的方法组成对象(object),把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)和泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派。"
简单的说,类是对象的蓝图和模板,而对象是类的实例。类是抽象的概念,而对象是具体的东西。
面向对象的支柱
面向对象有三大支柱:封装、继承和多态。引用作者对封装的理解:"隐藏一切可以隐藏的实现细节,只向外界暴露(提供)简单的编程接口"。
我们在类中定义的方法其实就是把数据和对数据的操作封装起来了,在我们创建了对象之后,只需要给对象发送一个消息(调用方法)就可以执行方法中的代码,也就是说我们只需要知道方法的名字和传入的参数(方法的外部视图),而不需要知道方法内部的实现细节(方法的内部视图)。
这也是定义类以后保存为py文件以后,通过from class_name import *来使用,这样会使得代码简单、高效,使得逻辑清晰。
D10 为游戏开发基础,就不班门弄斧了。

D11 文件和异常
这一节主要是讲述了如何读取文件(字符文件还是二进制文件),并对文件进行操作(读、写还是追加)。open是内置的函数。
小例子:字典与FASTA文件序列抽提
引用@菜鸟教程 上的一张图,进行区分,常见的操作为:
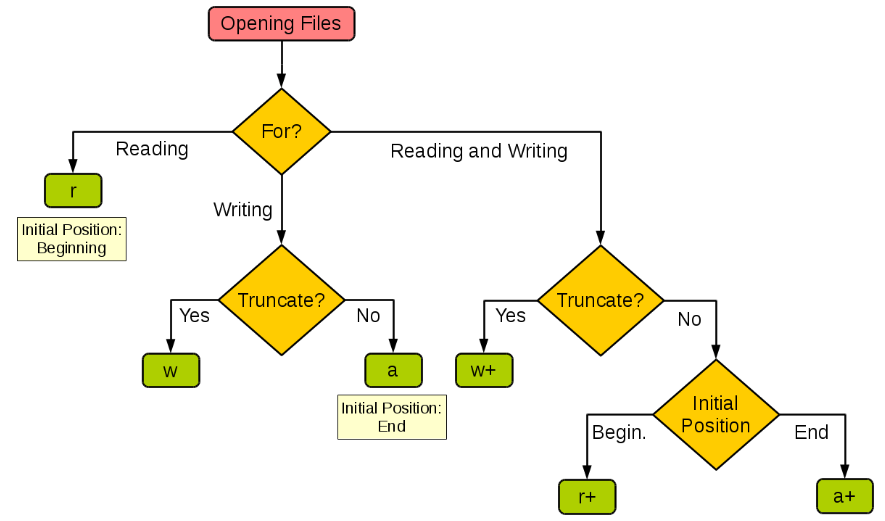
f = open('test.txt','r', encoding='utf-8')
f.close()
如果文件不存或无法打开,程序运行就会报错。这里作者给到了一个可以让代码具有一定的健壮性和容错性的函数,以处理可能发生的状况。
def main():
f = None
try:
f = open('致橡树.txt', 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if f:
f.close()
if __name__ == '__main__':
main()
这里要补充一下在之间的函数中,没有提到的try代码块和except。一般情况下,我们可以的在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。如上所示,作者在try后面跟上了三个except分别处理这三种不同的异常状况。最后的finally代码块来关闭打开的文件,为的是释放掉程序中获取的外部资源。
另一种finally代码块代替的方法:
def main():
try:
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!'
)
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
if __name__ == '__main__':
main()
读写JSON文件
JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。
在Python中,我们可以把一个列表或一个字典中的数据以JSON格式保存到文件中。例如:
{
"name": "骆昊",
"age": 38,
"qq": 957658,
"friends": ["王大锤", "白元芳"],
"cars": [
{"brand": "BYD", "max_speed": 180},
{"brand": "Audi", "max_speed": 280},
{"brand": "Benz", "max_speed": 320}
]
}
不难发现,JSON跟Python中的字典其实是一样的,因此也很容易读取数据。
| Python | JSON |
|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True / False | true / false |
| None | null |
json模块主要有四个比较重要的函数,分别是:
dump - 将Python对象按照JSON格式序列化到文件中
dumps - 将Python对象处理成JSON格式的字符串
load - 将文件中的JSON数据反序列化成对象
loads - 将字符串的内容反序列化成Python对象
D12 字符串和正则表达式
在python3入门之前,我们就不同的正则表达式及符号说明记录,本节就提一下重点:
Python提供了re模块来支持正则表达式相关操作,下面是re模块中的核心函数。
| 函数 | 说明 |
|---|
| compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
| match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
| search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
| split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
| sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
| fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
| findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
| finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
| purge() | 清除隐式编译的正则表达式的缓存 |
| re.I / re.IGNORECASE | 忽略大小写匹配标记 |
| re.M / re.MULTILINE | 多行匹配标记 |
很丰富对吧… 一般来说,我最常使用的是re.compile
和re.findall。例如:
pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')的意思是:从数字开始,1开头,可选[34578]中任意个数字,然后连接9个数字,最后一个数字结束。换句话说,该正则限定了数字匹配,且13,14,15,17,18开头,共十一位数字的匹配。
提示:上面在书写正则表达式时使用了“原始字符串”的写法(在字符串前面加上了r),所谓“原始字符串”就是字符串中的每个字符都是它原始的意义。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\,例如表示数字的\d得书写成\\d,这样不仅写起来不方便,阅读的时候也会很吃力。
在re模块的正则表达式相关函数中都有一个flags参数,即上表中最后两个,可用作标记匹配时是否忽略大小写、多行匹配等。如果需要为flags参数指定多个值,可以使用按位或运算符进行叠加,如flags=re.I | re.M
13.进程和线程
这个整篇读完还是有点懵。简单来说,进程就相当于是程序运行,可以拥有多线程,即更多的资源快速运算实现,但同时多线程的程序不太友好,会导致其他程序无法获得足够的CPU执行时间。
以下是专业的概念介绍:
进程就是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过fork或spawn的方式来创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
一个进程还可以拥有多个并发的执行线索,简单的说就是拥有多个可以获得CPU调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核CPU系统中,真正的并发是不可能的,因为在某个时刻能够获得CPU的只有唯一的一个线程,多个线程共享了CPU的执行时间。使用多线程实现并发编程为程序带来的好处是不言而喻的,最主要的体现在提升程序的性能和改善用户体验,今天我们使用的软件几乎都用到了多线程技术,这一点可以利用系统自带的进程监控工具(如macOS中的“活动监视器”、Windows中的“任务管理器”)来证实,如下图所示。
Python既支持多进程又支持多线程,因此使用Python实现并发编程主要有3种方式:多进程、多线程、多进程+多线程。
14.网络编程入门和网络应用开发
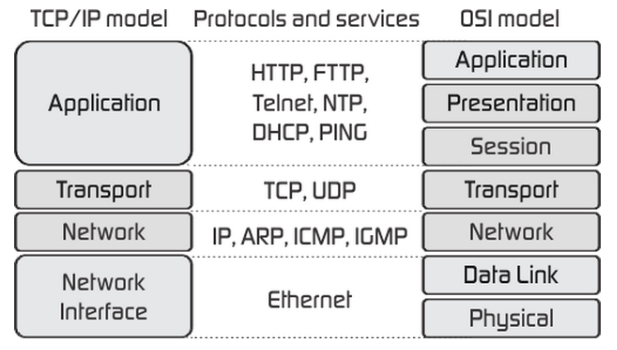
TCP/IP是一个四层模型,也就是说,该模型将我们使用的网络从逻辑上分解为四个层次,自底向上依次是:网络接口层、网络层、传输层和应用层,如下图所示。
我们经常听到的路由/路由器,主要功能就是存储转发我们发送到网络上的数据分组,让从源头发出的数据最终能够找到传送到目的地通路。也就是说网络之间有协议,我们需要通过路由派发数据传输,然后体现在终端上,实现上网。
在本节中还记录了一些有意思的实操:
发送电子邮件 & 发送短信
先mark一下。
以上是在基于Python-100天教程中挑选基础内容查漏补缺的笔记,不断迭代。如果对你也有一点点帮助,点点在看或者分享到朋友圈,你们的支持是我继续分享的动力
鸣谢作者@骆昊
Python - 100天从新手到大师
https://github.com/jackfrued/Python-100-Days








