
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
无论是在机器学习领域还是深度学习领域里面,通过模型的集成来提升整体模型的性能是一件非常有效的事情,当前我们所接触到的比较成熟的四大集成框架主要包括:Bagging、Boosting、Stacking和Blending。对于初学者来说前两种思想或者是框架可能是会比较耳熟能详的,而后两种如果没有接触到的话可能会觉得比较陌生,我也是读了研究生以后才接触到Stacking和Blending的,思想还是比较好理解的,效果也是蛮不错的,这里简单温习一下这三种集成学习策略:
1、Bagging
Bagging的个体弱学习器的训练集是通过随机采样得到的。通过T次有放回的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来得到最终的强学习器。随机森林是Bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在Bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离Bagging的范畴。Bagging原理示意图如下所示:
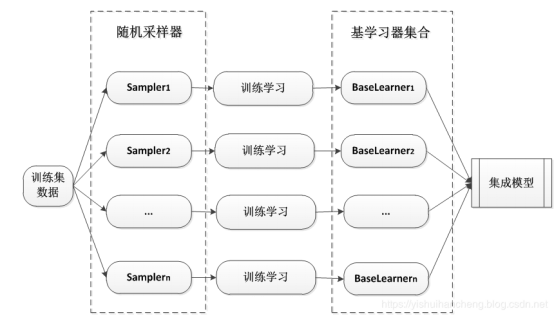
2、Boosting
Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的样本在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。Boosting系列算法里最著名算法主要有AdaBoost算法和GBDT提升树(boosting tree)系列算法。原理示意图如下所示:
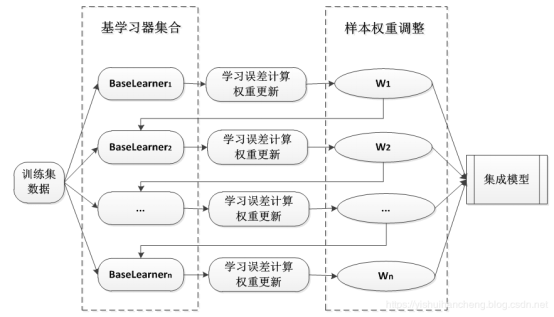
3、Stacking
Stacking也是一种模型融合的方法。首先,直接用所有的训练数据对第一层多个模型进行k折交叉验证,这样每个模型在训练集上都有一个预测值,然后将这些预测值做为新特征对第二层的模型进行训练,stacking两层模型都使用了全部的训练数据。Stacking模型是指将多种分类器组合在一起来取得更好表现的一种集成学习模型。一般情况下,Stacking模型分为两层。第一层中我们训练多个不同的基础模型,然后再以第一层训练的各个模型的输出作为输入来训练第二层的模型,以得到一个最终的输出。
Stacking原理示意图如下图所示:
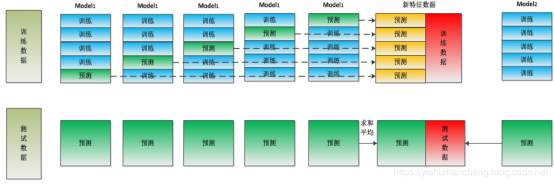
4、Blending
Blending设计思想与Stacking类似,对于一般的Blending,主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。第一层我们在这70%的数据上训练多个模型,然后去预测那30%数据的label。在第二层里,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练即可。从这里我们可以看到Stacking和Blending模型在构建过程中最明显的差别就是Stacking的两层训练都是用的全部数据,而Blending是使用的部分数据。
学习了基础的理论知识后,下面进入到实践环节。首先是数据集的创建,具体实现如下:
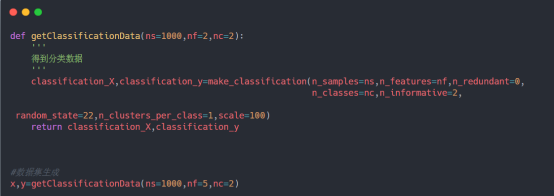
基于投票的思想来构建集成分类器是很常见的一种方法,常用的投票分类模型主要分为:硬投票模型、软投票模型和软投票加权模型。具体的代码实现如下:
首先是数据集分割与基分类器模型的初始化定义实现:

接下来是集成投票分类器的具体实现:
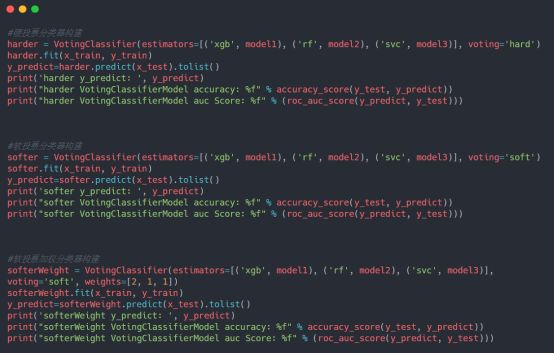
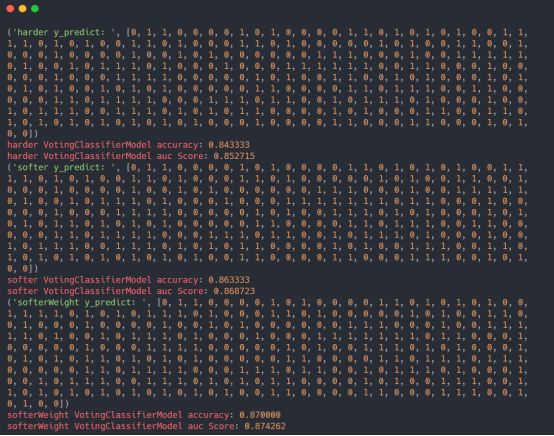
模型测试结果输出如下:
除了sklearn之外后,mlxtend也提供了原生态的集成投票分类器模型,这里也做一个简单的实践说明,如下:
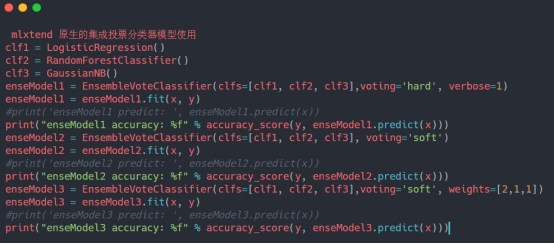
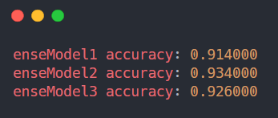
模型测试输出如下:
接下来,我们分别实践使用Stacking和Blending两种集成框架,其中,由于mlxtend中对Stacking有了完整的实现,我们这里直接使用就好了,Blending的搭建由我们自己完成,具体的实现如下:
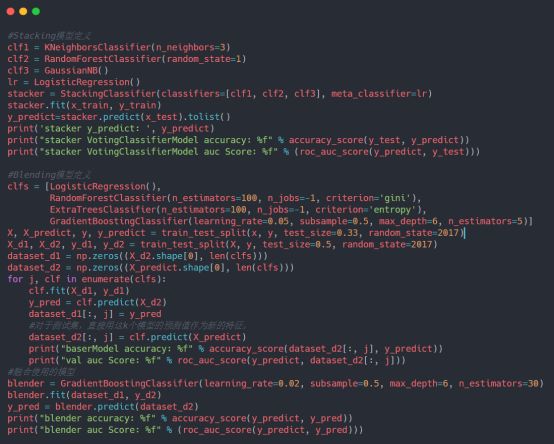
模型测试结果输出如下:
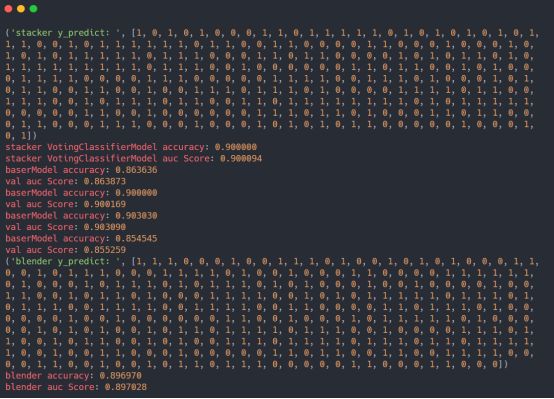
这里没有贴出来单个基分类器模型的auc值或者是准确度值,感兴趣的话可以自己亲身实践一下,通过有效的集成学习思想集成的模型在一定程度上对于模型性能的提升还是非常有效的。
到这里集成模型的实践使用和讲解就差不多结束了,最后给出来一点模型调参的实践内容,这部分网上有很多的学习内容,在我之前的文章里面也有一篇关于超参数调参优化的详细实践讲解,感兴趣可以去看看,下面是网格调参的简单实践:
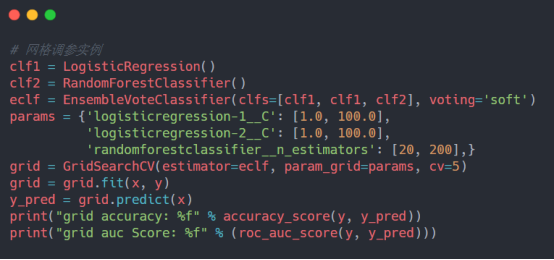
测试结果输出如下:
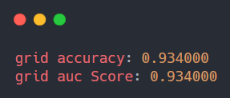
很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持。
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY









