
我们在准备进行数据挖掘之前,首先需要对数据做初步的探索性分析,以及一系列数据预处理的步骤。因为原始数据存在不完整、不一致、有异常的数据,而这些“错误”的数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差。可以说数据的质量,直接决定了模型的预测和泛化能力的好坏。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
本期我们就通过一个简单的示例数据来学习如何通过 Python 中的 sklearn 包进行数据的预处理操作。
首先导入需要的库和数据集:
import numpy as np
import pandas as pd
dataset = pd.read_csv("./Data.csv")
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values
下面粗略查看一下我们的数据,通过调用以下几个方法可以大致了解我们得到的数据是什么,有什么特征,以及特征的数值类型,最大值最小值等等。
dataset.head(5)
dataset.tail(5)
dataset.columns
dataset.info()
dataset.shape
dataset.describe()
可以看到 dataset 的数据如下:
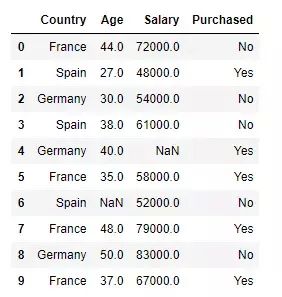
处理缺失值
一般来说,我们所使用的数据总是不完美的,常常会有一些字段存在缺失值,但又不能直接将其舍弃,因此,数据预处理中非常重要的一项就是处理缺失值。在上面的示例数据中,我们也可以看到有两个缺失值。在 sklearn 中我们可以使用 SimpleImputer 来处理缺失值。
class sklearn.impute.SimpleImputer
(missing_values=nan, strategy=’mean’, fill_value=None, verbose=0,
copy=True)

在这里我们使用均值来进行填补:
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer()
imputer = imp_mean.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
当然,其实更简单的方法就是直接用 Pandas 和 Numpy 进行填补:
dataset.loc[:,"Age"] = dataset.loc[:,"Age"].fillna(dataset.loc[:,"Age"].mean())
dataset
对分类数据进行编码
大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,但在现实中,我们有许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如,学历的取值可以是["小学",“初中”,“高中”,"大学"]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,也就是说,将文字型数据转换为数值型。为实现这个功能,需要我们从 sklearn.preprocessing 库中导入 LabelEnconder 类。
from sklearn.preprocessing import LabelEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
我们刚才已经使用 LabelEncoder 将 X 和 Y 中的文字型数据转化成了数值型数据,在Country这一列中我们使用[0,1,2]代表了三个国家,然而这种转换是正确的吗?
我们来看两种类型的离散特征:
离散特征的取值有大小的意义,比如 size:[L,XL,XXL]
,三种取值不是完全独立的,我们可以明显看出 XXL > XL > L ,这种离散特征就可以使用数值的映射{LL:1,XL:2,XXL:3}。
离散特征的取值之间没有大小的意义,比如示例数据中的国家 country:[France,Germany,Spain],这三者彼此之间完全没有联系,表达的是France ≠ Germany ≠ Spain 的概念。那么这种数据就需要使用独热编码 (One-Hot Encoding)。
所谓独热编码就是使用 N 位状态寄存器来对 N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。例如:
自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
可以这样理解,对于每一个特征,如果它有 m 个可能值,那么经过独热编码后,就变成了 m 个二元特征(如成绩这个特征有好,中,差变成one-hot就是100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
解决了分类器不好处理属性数据的问题
在一定程度上也起到了扩充特征的作用
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
切分数据集
接下来我们使用 train_test_split 将数据随机划分为训练集和测试集:
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
参数:
数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”。譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered 或者 Meansubtraction)处理和缩放处理(Scale)。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
在 sklearn 中,我们可以使用 StandardScaler 进行 z-score 标准化,公式如图所示:
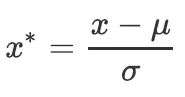
可以看到,当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布)。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
好啦,本期内容就到此为止了,欢迎大家留言或者加入我们一起学习~
参考
猜你喜欢
机器学习实战 | Adaboost
支持向量机 sklearn 参数详解
一文带你了解什么是支持向量机
机器学习实战 | 逻辑回归
机器学习实战 | 朴素贝叶斯
机器学习实战 | 决策树
机器学习实战 | k-邻近算法
一起来学习机器学习吧~







