佟达ThoughtWorks商业洞见
[摘要]
最近几年,深度学习备受关注。在2016年的每一项人工智能成就背后,几乎都能看到深度学习的影子。数据的获取、存储、计算能力的增强,以及算法的进步等因素合力推动了深度学习技术的崛起。深度学习目前的成果大多来自学术研究,然而,在不远的将来,以深度学习驱动的人工智能技术,将推动企业软件开发产生巨大的变革。

洗白“黑科技”深度学习
2016年3月,由DeepMind研发的AlphaGo以4:1的战绩完胜世界围棋冠军李世乭,拉开人工智能疯狂席卷IT圈的序幕。5月,Tesla在开启Autopilot辅助驾驶模式后出现首例致死事故,将人工智能推上了风口浪尖。霍金、比尔盖茨、埃隆马斯克等科技大咖相继发言,讨论人工智能是否会对人类未来发展不利,OpenAI应运而生。10月,HBO电视剧《西部世界》的上映,再一次引爆大众对于人工智能的关注。由于媒体的夸张宣传,人们甚至觉得《终结者》中的世界就要到来。
伴随着这一波人工智能浪潮崛起的,是一种被称为“深度学习”的技术。不论是AlphaGo、自动驾驶,抑或是其他近期的人工智能突破,我们都能在其背后看到深度学习的影子。深度学习就像是人类打开的潘多拉盒子,放出了黑科技,席卷整个科技行业。
从Gartner2016年新技术发展曲线报告中可以看出,和人工智能相关的技术,要么处于泡沫期的顶峰,要么处于正在走向泡沫期的路上。为什么人工智能会突然爆发?它会不会只是媒体吹出来的一个泡沫?作为人工智能再次兴起的核心技术突破,深度学习到底是什么“黑科技”?
从信息时代到智能时代
近20年间,互联网经历了一场“大跃进”。根据IDC做的统计:在2006年,全世界创造的数据量约为161EB,预计每18个月这个数字会翻一番,在2010年达到988EB(1024GB为1TB,1024TB为1PB,1024PB为1EB,1024EB为1ZB)。而事实上,根据IDC后来的报告,2010年达到的数字是1227EB。最近的一次IDC互联网报告是在2014年,其中提到2013年全世界产生的数据是4.4ZB,到2020年,这一数字将达到44ZB。
物联网的发展正在加速这一过程。2013年,全世界接入互联网的设备将近200亿,到2020年,这一数字将达到300亿。而全世界所有的“物体”总数,大概是2000亿。这些设备通过其内嵌的传感器监控并收集数据,并上报到云计算中心。
云计算、大数据和物联网的窘境
我们正处于“数字化一切”的时代。人们的所有行为,都将以某种数字化手段转换成数据并保存下来。每到新年,各大网站、App就会给用户推送上一年的回顾报告,比如支付宝会告诉用户在过去一年里花了多少钱、在淘宝上买了多少东西、去什么地方吃过饭、花费金额超过了百分之多少的小伙伴;航旅纵横会告诉用户去年做了多少次飞机、总飞行里程是多少、去的最多的城市是哪里;同样的,最后让用户知道他的行程超过了多少小伙伴。这些报告看起来非常酷炫,又冠以“大数据”之名,让用户以为是多么了不起的技术。然而,我们实际上在只是做一件事:数(shǔ)数(shù)。

实际上,企业对于数据的使用和分析,并不比我们每年收到的年度报告更复杂。已经有30多年历史的商业智能(Business Intelligence),看起来非常酷炫,其本质依然是数数,并把数出来的结果画成图给管理者看。只是在不同的行业、场景下,同样的数字和图表会有不同的名字。即使是最近几年炙手可热的大数据处理技术,也不过是可以数更多的数,并且数的更快一些而已。
比如我们每天都在使用的搜索引擎。在自然语言处理领域,有一种非常流行的算法模型,叫做词袋模型(Bag of Words Model),即把一段文字看成一袋水果,这个模型就是要算出这袋水果里,有几个苹果、几个香蕉和几个梨。搜索引擎会把这些数字记下来,如果你想要苹果,它就会把有苹果的这些袋子给你。
当我们在网上买东西或是看电影时,网站会推荐一些可能符合我们偏好的商品或是电影,这个推荐有时候还挺准。事实上,这背后的算法,是在数你喜欢的电影和其他人喜欢的电影有多少个是一样的,如果你们同时喜欢的电影超过一定个数,就把其他人喜欢、但你还没看过的电影推荐给你。
搜索引擎和推荐系统在实际生产环境中还要做很多额外的工作,但是从本质上来说,它们都是在数数。那么,数数有什么问题么? 有。
数字的发明,让我们的祖先可以用简便的记法记录下物体的个数。比如有一个放牛娃,家里最初只有3头牛,他可以记住每一头牛的样子,每天回到家,扫一眼牛棚,就知道家里的牛丢没丢。后来,因为家里经营的好,放牛娃的牛有100头之多,随之而来的是无法记清每头牛的烦恼。如果没有发明数字,他可能要把每一只牛照着模样刻在石壁上,每天拉着一头头的牛到石壁边去对照,看有没有丢牛。当有了数字,放牛娃只需要记下“100”这个数字,再画一头牛就够了,以后每天数一下牛群里面牛的数量,再看看石壁上的数字是否一样。

数数,让放牛娃的工作变得简单,他不用把每一头牛的样子都刻在石壁上,减轻了工作量。可是这种办法并非万无一失,有一天,附近一个游手好闲的小混混从别处找来一头病牛,混到了放牛娃的牛群之中,同时又牵走了一头壮牛。放牛娃在一天结束、清点自己的牛群时,发现还是100头牛,不多不少,就心满意足的回家睡觉了。然而他却不知道,他的一头壮牛被小混混用病牛换走了。
对于主要以数数方式来使用数据的企业,同样面临着无法关注数据细节的问题。当数据量比较小的时候,可以通过人工查阅数据。而到了大数据时代,几百TB甚至上PB的数据在分析师或者老板的报告中,就只是几个数字结论而已。在数数的过程中,数据中存在的信息也随之被丢弃,留下的那几个数字所能代表的信息价值,不抵其真实价值之万一。过去十年,许多公司花了大价钱,用上了物联网和云计算,收集了大量的数据,但是到头来却发现得到的收益并没有想象中那么多。
深度学习的困境
我们所知的深度学习,本质上应该叫做“基于深度神经网络的机器学习”。为什么用了”深度学习”这个名字,而不是深度神经网络呢?其中一个原因是,“神经网络”这个词是一个禁忌。
神经网络算法的提出可以追溯到20世纪40年代。这一算法起源于生物学中对于动物大脑神经元的研究,因此早期也被称为人工神经网络(Artificial Neural Network)。最初的神经网络是逻辑电路搭建,到了60年代,由于计算能力不足,无法构建大规模神经网络,而小规模神经网络的表现又差强人意。随着其他机器学习方法的提出,很多科研人员开始转向其他方向,人工神经网络的研究陷入了停滞。
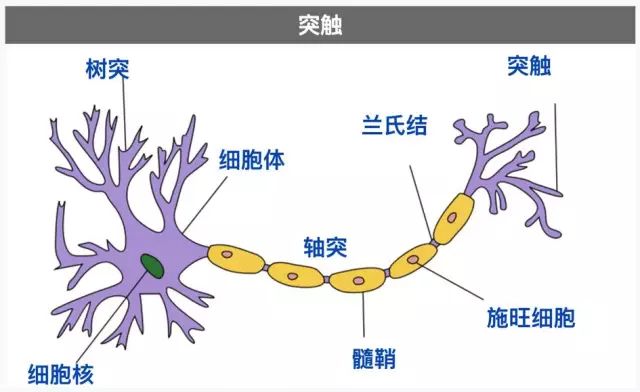
典型神经元的结构
20世纪80年代,随着通用计算机的出现,人工神经网络的研究经历了一波复苏。在这个阶段,反向传播(Back Propagation)算法逐渐成熟。直到今天,反向传播算法都是训练神经网络的最主要方法。然而,依然受限于当时的硬件条件,神经网络的规模依然不大。同时,以支持向量机为代表的基于核方法的机器学习技术,表现出了不俗的能力,因此,大量科研人员再一次放弃了神经网络。
然而并不是所有的科学家都放弃了神经网络。在那些留守的科学家中,有一位刚刚拿到人工智能学位不久的年轻人,他曾在剑桥大学国王学院拿到实验物理学的学士学位,因为对认知科学抱有浓厚的兴趣,因此选择专攻人工智能。他坚信“既然大脑能够工作,神经网络算法也一定能工作。大脑不可能是被编程出来的。”当他的研究成果并不如预期时,他总是对质疑他的人回应:“再给我6个月,到时候我会证明它是可以工作的。”当几个6个月过去,神经网络的效果依然不好,他会说:“再给我5年,一定能行。”又是好几个5年过去,神经网络真的成了。这个人就是Geoffrey Hinton,深度学习之父。
神经网络在最初的几十年内都没有表现出过人的性能,主要面临着两个困难。首先是计算性能不足。实际上,在90年代,Hinton以及他的学生就已经在试验和后来深度神经网络类似的结构,其中就有大名鼎鼎的Yann LeCunn,他所提出的神经网络结构就是现在的“LeNet”。但是,增加神经网络的深度,就会让神经网络的训练速度变慢。在那个内存不过几十MB,GPU还没有出现的年代,要训练一个小规模的深度神经网络模型,需要花上数周甚至数月。
其次是训练数据不够多。在机器学习领域流传着一个传说,叫做“维度诅咒(Curse of Dimensionality)”,随着特征维度的增加,算法的搜索空间急剧变大,要在这样的特征空间中寻找适合的模型,需要大量的训练数据。神经网络要解决的问题,通常具有成千上万维的特征,我们假设有1000维特征,每一维特征有100个候选值,那么这个特征空间就是100的1000次方,可以想象,要在如此大的特征中寻找一个模型,需要多少数据,而这个特征空间规模不过是深度学习问题中比较小的。幸好我们所在的这个世界,可以通过一个非常有用的先验假设进行简化:我们这个世界的事物都是通过更小的事物组合而成的。我们知道,所有的物体都是由分子构成,分子由原子构成,原子由质子、中子和电子构成,等等。不仅实际的物体满足这一先验假设,抽象的概念也一样如此。因此深度神经网络利用了这一假设,通过将网络层数加深,每一层神经元都是前面一层神经元输出的组合,通过这样的假设,将整个搜索空间大大减小。然而,训练深度神经网络依然需要大量的数据,才能得到一个比较好的结果。
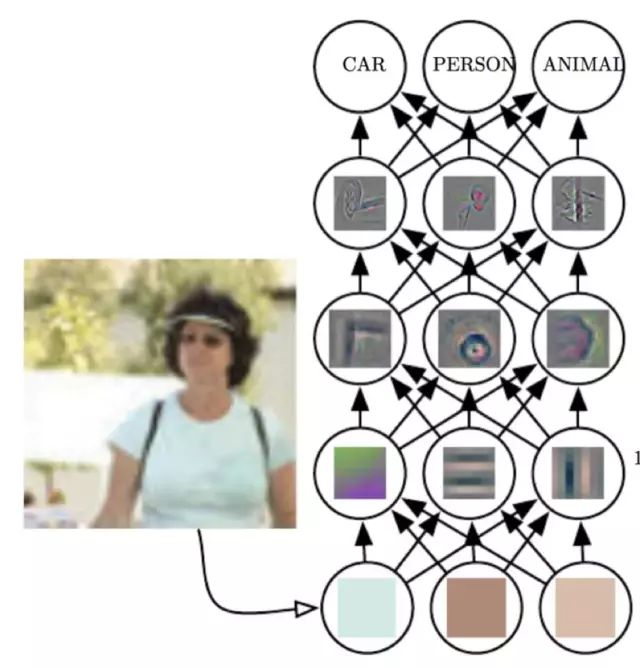
深度神经网络构建层级化特征
取深度学习之长,补传统软件之短
来到21世纪,正如我们前面所说,在21世纪的十几年间,我们的数据量和计算能力都增长了不少,这为神经网络证明其能力提供了条件。事实上,在Hinton的带领下,神经网络在2000年之后逐渐开始在一些比较小众的领域获得成功。而真正对学术界产生震动的,是2012年,Hinton实验室的学生Alex Krizhevsky用基于深度神经网络的方法,在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像识别挑战赛中一战成名,其网络结构也被人们称为AlexNet。在那之前,图像识别领域已经被基于支持向量机的算法霸占多年,而AlexNet不仅打败支持向量机,而且将错误率降低了将近一半。自此之后,图像识别算法的冠军就一直是深度学习算法。
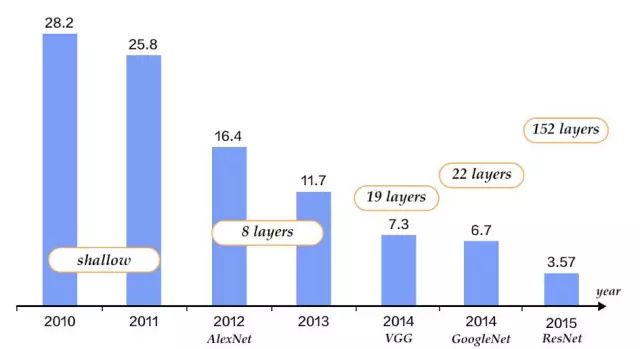
基于深度学习的算法让图像识别精度在过去几年大幅度提升
除了在图像识别领域获得巨大成功,在短短的几年之内,在各种场景下,基于深度神经网络的算法都横扫其他机器学习算法。包括语音识别、自然语言处理、搜索引擎、甚至自动控制系统。DeepMind的Alex Graves团队在2014年的一篇论文中提出的神经图灵机(Neural Turing Machine)结构,以及后来在2016年提出的DNC(Deep Neural Computer)结构,甚至可以成功学习简单的算法,这不禁让我开始遐想有一天,计算机可以自己给自己编程。
深度学习给企业带来的影响
深度学习的端到端架构,降低了企业引入深度学习的成本
相比其他经典的机器学习算法来说,深度学习需要人工干预的比例小很多。比如,在经典机器学习中,特征工程占用了科学家们开发算法的大部分精力,对于某些问题,比如图像识别、语音识别,科学家们花了几十年时间来寻找性能更好的特征。深度学习改变了这一情况。深度学习接收原始数据,在神经网络的训练过程中,寻找最适合的特征。事实证明,机器自己找到的特征,比人类科学家用几十年找到的特征性能更好。正是由于深度学习的这一特点,深度学习的一个明显趋势,是端到端的解决问题。
比如下图所示的语音识别。经典语音识别需要对原始数据提取特征(比如梅尔倒谱系数),将提取到的特征建立时间序列模型(比如隐式马尔科夫模型),得到声学模型,然后根据发声词典,将输入信号映射为一些音节,最后,根据预先定义好的语言模型,将音节转换为有意义的文字。这其中,特征提取、时间序列建模、发声词典等都需要人工预先定义好,对于不同的语种,比如中文和英文,还要使用不同的模型。
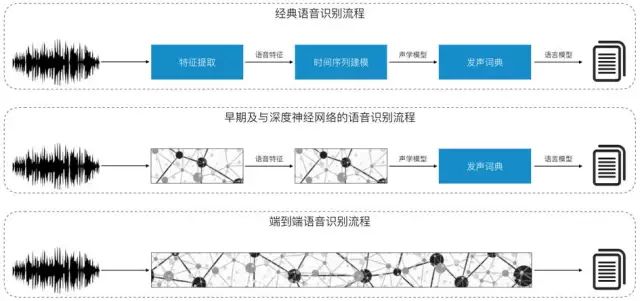
端到端的深度学习越来越流行
在深度学习流行起来的初期,语音识别流程中的特征提取以及时间序列建模等,都用深度神经网来替代了。到了最近几年,科学家发现,对于语音识别这样的问题,甚至流水线都是多余的,直接将原始数据接入到神经网络中,就能输出我们期望的文本,这样的结构要比人工设计流程得到的结果更好。
这种端到端的深度学习,在其他领域也被验证是可行的。比如自动驾驶技术,在MIT的自动驾驶项目中,就是用端到端的深度强化学习技术,输入是路况的所有信息,输出就是对汽车的指令,比如加速、刹车、方向盘角度等等。
深度学习的端到端架构,降低了企业引入深度学习的成本。过去,企业要引入机器学习,需要招聘一个科学家团队,同时还需要一个开发团队,将科学家所设计的算法模型翻译成生产环境代码。这样的开发模式不仅成本高,响应速度也非常慢。而深度学习的端到端架构,对于科学家的要求降低了很多,而且,由于不需要通过特征工程来寻找特征,开发周期也大大缩短。对于很多规模不大、但希望朝智能化演进的企业来说,先尝试引入深度学习是个不错的选择。
智能时代的产品研发将由算法驱动
在传统的软件开发中,用户的交互方式是确定的,业务流程也是确定的;当我们尝试将人工智能技术融入到产品中,需要面对大量的不确定性。
首先是和用户的交互方式将发生巨大变化。过去,我们通过按钮、表单等控件来确保用户是按照产品设计师的思路来使用软件的。随着深度学习在图像识别、语音识别、文本识别等方面的快速发展,未来,我们的软件在用户的交互过程中,将更多的使用自然语言、语音、手势、甚至是意识。具备触屏功能的智能手机的出现,掀起了一波用户体验升级的浪潮,所有应用开发者都在寻找在触屏应用中更自然的交互方式。而这一次,用户交互方式的升级将比触屏带来的影响更加深远。Amazon在这方面做出了开创性的尝试,其智能音箱Echo在设计之初就特意去掉了屏幕,让语音变成唯一的交互渠道。Facebook Messenger在发布了聊天机器人的平台之后,同样也给出了设计指导,开发者将以一种全新的方式去思考,软件应该如何与用户更好的沟通。
其次是企业的业务决策会越来越多的依赖人工智能。过去,企业要基于数据进行决策,需要搭建数据仓库,开发ETL程序,制作报表,等待分析师从各种各样的报表中找到有价值的信息,最后做出业务改进的决策。现在,我们有了深度学习这把强大的锤子,可以让我们对数据有更加深刻的洞察力;同时,实时流式大数据架构让我们可以更快速地做出反馈。企业如果可以利用好这两大利器,将释放出更大的潜力。
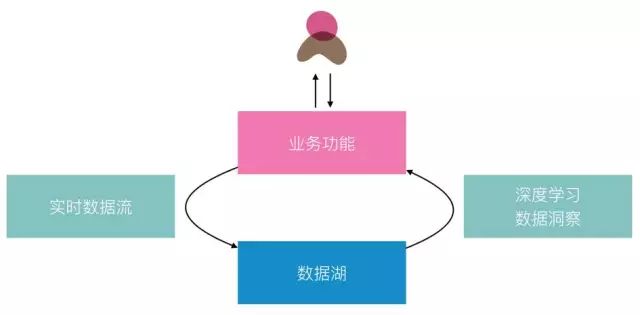
算法驱动的产品架构
IT软件的运维也将迎来新的革命。软件系统越来越复杂、规模越来越大,对于运维人员的挑战就越来越高。在IT行业的早期,运维更多是修复性工作,即发现坏了,立即进行修复。后来,为了减少系统修复带来的损失,运维工作开始强调预防性,即根据历史维护记录,找到系统故障的规律,提前进行修复。然而,据统计,有规律的故障只占所有故障中的18%。因此,我们需要更好的识别并预测故障的能力,即预测性运维。深度学习在自动学习特征方面的优势,注定其在预测性运维领域也会发挥很大的作用。
深度学习不是终结者
深度学习在这几年越来越流行,尤其是在AlphaGo击败人类棋手之后,一些媒体甚至开始营造人工智能可能会取代人类的紧张氛围。然而,就目前的研究成果来看,想要发展出科幻电影中具备独立思考能力、甚至可以和人类谈恋爱的人工智能,还有很长一段距离。且不说情感、人格这类形而上的概念,尚未有严格的科学定义,更不用提人工智能能否具备这些属性。单从目前人类的工作是否会被人工智能所替代来看,至少当前的深度学习还有很多局限性,要想打破局限,让深度学习具有更大的作用,还有很多挑战等待解决。
挑战1:多功能神经网络
尽管深度学习已经让神经网络具备了很大的灵活性,然而深度学习目前还只能做到一个神经网络解决一个问题。比如训练一个神经网络要么只能识别图片,要么只能识别语音,不能同时识别。比如,我们可以给一个神经网络看一张图片,神经网络可以识别到图片中是猫还是狗;我们也可以给另一个神经网络听一段声音,这个神经网络可以识别出是声音中是猫还是狗的叫声;但是,现在还没有一个神经网络,既能通过视觉识别物体,还能通过听觉识别物体。尽管借助多任务学习(Multi-task learning)技术,神经网络可以在识别图片类别的同时,识别轮廓、姿态、阴影、文字等等相关的内容,相比我们人类多才多艺的大脑,现在的深度神经网络可以说是非常低能。
目前如果需要一个应用支持不同的能力,必须组合使用多个神经网络,这不仅对于计算资源是巨大的消耗,不同神经网络之间也难以形成有效的互动,比如图片中的狗、声音中的狗和一段文字中出现的狗,在各自的神经网络中都有不同的表示方式。而对于人类来说,这些其实都是同一个概念。
如何让神经网络能够同时实现多个目标,目前科学家们也都还没有答案,不过从人类大脑得到的启示是,通过某种方式,将负责不同功能的神经网络连接起来,组成更大的神经网络,也许可以解决这个问题。Google在ICLR 2017上的一篇论文,通过一个系数门矩阵将多个子网络连接起来,是在这个方向上的一个有趣尝试。
挑战2:终极算法
Pedro Domingos教授在《The Master Algorithm》一书中回顾了机器学习的5大流派:符号主义、连接主义、进化主义、贝叶斯主义、分析主义。这5类机器学习算法并没有绝对的优劣,不同的算法适用于不同的场景和问题。比如以神经网络为主的连接主义算法,对于视觉、听觉这类感知问题,具有更好的效果,但是却不擅长逻辑推理。而逻辑推理刚好是符号主义算法所擅长的。书中提出了一种终极算法,能够结合这五种主流机器学习,可以适用于更大范围的问题域。
深度学习正是连接主义发展而来,不过深度学习提供了可扩展性非常强的框架,以深度学习为基础,很有希望将其他几类机器学习算法融入进来。OpenAI在进行深度强化学习的实验过程中发现,使用进化主义的遗传算法替代经典的反向传播(BP)算法,模型可以更快的收敛,性能也更好;Google基于TensorFlow框架开发的概率编程工具库Edward,证明了概率图和神经网络可以无缝的结合在一起。
从目前的趋势看来,终极算法非常有希望。不过,事情不会总是这么顺利。当年物理学家们希望寻找大统一理论来结合自然界四种基本力,电磁力、强核力、弱核力很快就结合到一个模型中,然而最后引力却怎么都找不到结合的办法。当我们找到终极算法的时候,通用人工智能(Artificial General Intelligence)就离我们不远了。
挑战3:更少的人工干预
深度学习让机器学习不再依赖于科学家寻找特征,但调试深度神经网络依然需要很多人工的工作,其中最主要的就是调参。这里所说的调参,不是调节神经网络的每个神经元的参数,而是指调试超参数。超参数是用来控制神经网络的描述性参数,比如,神经网络的层数、每一层的神经元个数、学习率(Learning Rate)的大小、训练时间的长短等等。这些参数的微小差异,会给最终模型带来巨大的性能差异,而这部分工作大多需要靠经验完成,很难总结出有效的最佳实践。
然而这一状况在未来将会有所改善。既然神经网络可以用于学习参数,就应该可以学习超参数。DeepMind提出的Learning to Learn算法,使用神经网络来学习和调整学习率,可以让神经网络更快的收敛到理想的精度。正所谓,授人以鱼不如授人以渔。
结语
深度学习的火爆,吸引了越来越多的计算机科学家投身到这一领域。如果以目前学术成果的发展速度来预测,也许不超过10年,上述深度学习的挑战就会被解决。与其杞人忧天的担心人工智能会毁灭人类,不如提前布局,做好准备,迎接智能时代的到来。智能时代的IT系统,将是“具备自主性的IT系统,能够根据人类制定的目标,针对复杂业务变化,做出认为的最优选择。”如果深度学习的几大挑战能够在几年之内被解决,将大大加快未来IT系统实现的脚步。
本文收录于《ThoughtWorks商业洞见——智能时代》

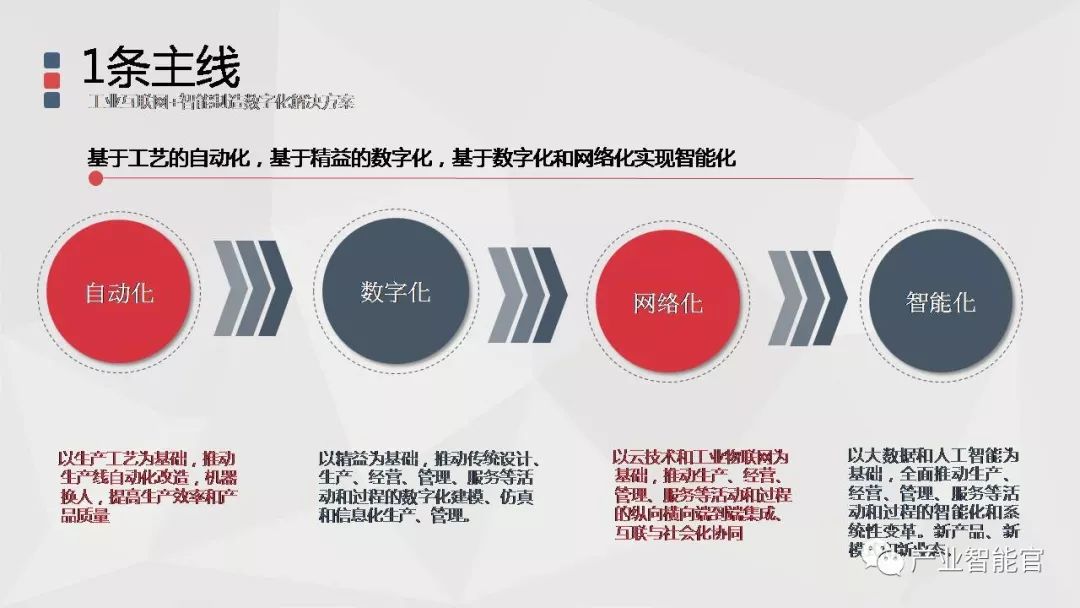
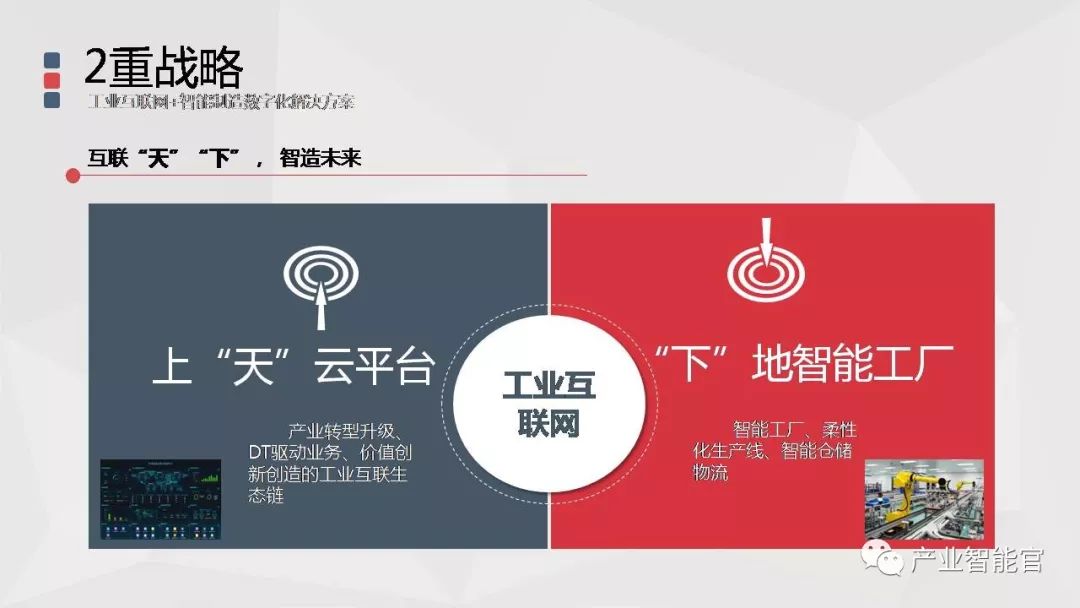
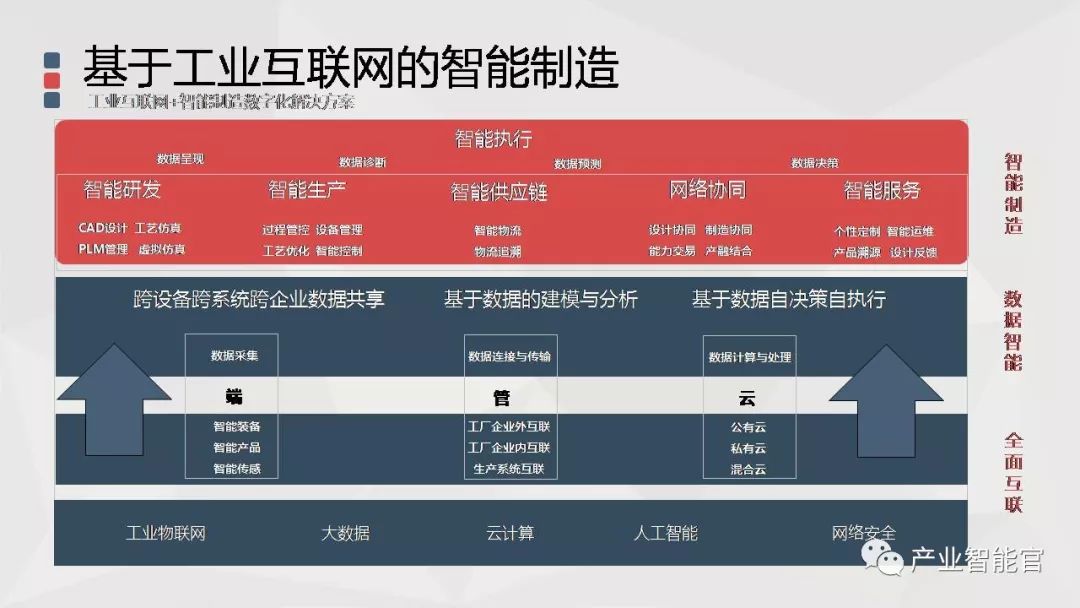
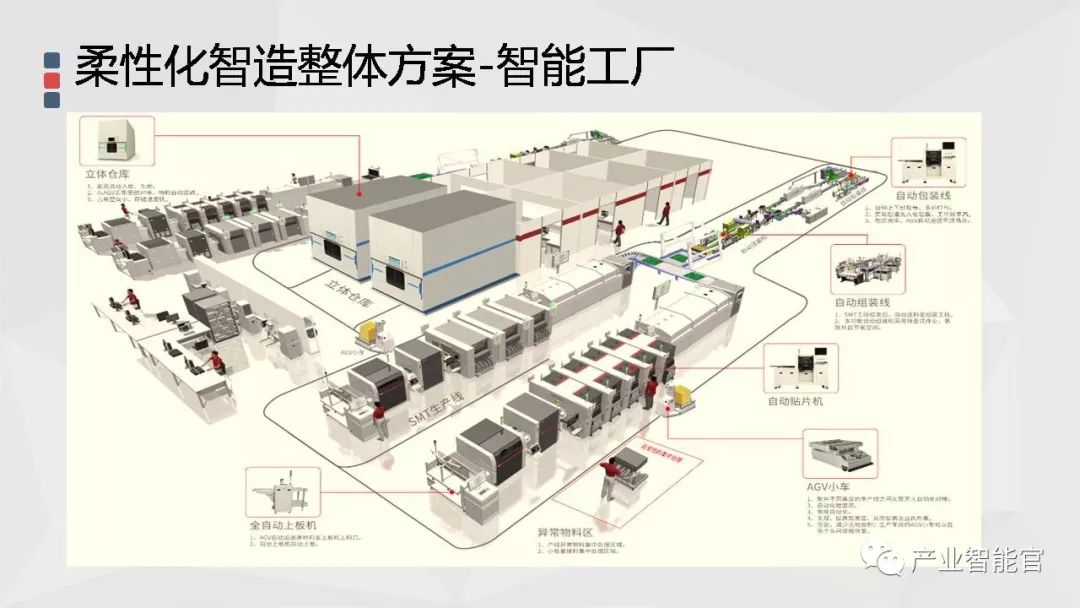
工业互联网+智能制造
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:
产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。










