今年4月,在LHC(大型强子对撞机)内部的一次碰撞中,发现了个别带电粒子(橙色线)和大粒子喷射(黄色锥体)。 | ATLAS
导语
在寻找新粒子时,传统的搜索算法总是需要物理学家事先假设出粒子的表现,机器学习算法则为此提供了新的思路。
编译:集智俱乐部翻译组
来源:Quantamagazine
原题:How Artificial Intelligence Can Supercharge the Search for New Particles
在大型强子对撞机中,每秒会有十亿对质子撞击。有时,机器会干扰现实状况,在碰撞中产生一些前所未有的东西。由于这些事件本身是意外出现的,物理学家们并不清楚自己要寻找什么。
从数十亿次碰撞的数据里,筛选出方便管理的小数据量的过程中,他们担心,可能会无意间删除掉新理论的证据。纽约大学粒子物理学家,在CERN(欧洲核子研究中心)进行过ATLAS实验工作(粒子观测)的Kyle Cranmer讲道,“我们总是担心倒洗澡水的时候,把婴儿也一起倒了出去”。
面对需要减少数据量的挑战,从浩瀚无垠的寻常事件中,挖掘出新的物理现象,一些物理学家开始尝试一种称为“深度卷积神经网络”的机器学习技术。
在机器学习的原型用例中,通过学习大量的标签为“cat”和“dog”的图像,深度卷积神经网络能够掌握辨别猫和狗的能力。
但是,由于物理学家无法向机器输入他们从来没有见过的图像,对于寻找新粒子的问题,这种方法并不奏效。
因此,物理学家尝试让机器从已知的粒子开始,利用细化的信息(比如它们在总体上可能发生的频率),查找不常见的事件 ,这种技术被称为“弱监督学习”。
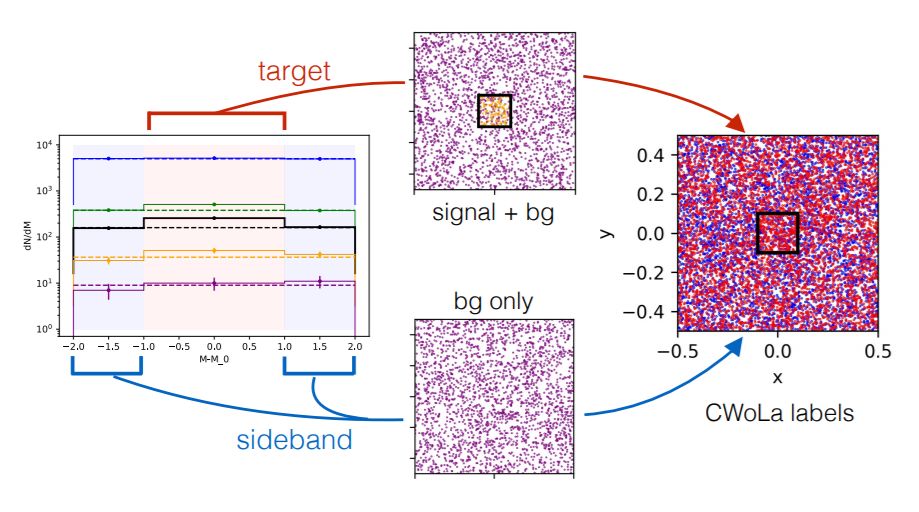
我们用一个简单的二维平面例子,来说明无监督学习的特点。左边的图,横坐标的三个区间,分别表示三个不同质量箱的粒子;纵坐标表示粒子的数量。蓝线表示粒子的总数,其余四条线表示在不同神经网络中,各自的阈值和粒子的实际数量。中间的图将每个质量箱中粒子的位置展现在二维平面中(紫色表示背景,黄色表示信号)。右边的图中,黑色正方形是本示例模型的目标信号区域。尽管该平面中的粒子没有任何标签信息,无监督学习也能够用这些数据训练出一个分类器。 | 论文①图2
今年五月,在Arxiv.org上发表的一篇论文中,三个研究员提出,应用相关策略来拓展“撞击狩猎”实验(bump hunting),该策略就是发现希格斯玻色子的经典粒子狩猎技术。Ben Nachman是劳伦斯伯克利国家实验室的一名研究员,他说道,具体的思路是训练机器,寻找数据集中罕见的变化。
论文①题目:
CWoLa Hunting: Extending the Bump Hunt with Machine Learning
论文①地址:
https://arxiv.org/abs/1805.02664
我们可以在猫狗实验原理的基础上做一个游戏——从北美森林观测数据集中找出新的动物物种。
假设任何一个新动物,都倾向于聚集在某个特定的地理区域(一个与围绕某个质量聚集的新粒子相对应的概念),算法可以通过系统地比较临近区域,挑出它们。如果不列颠哥伦比亚省刚好有113只驯鹿,华盛顿州有19只驯鹿(即使数据集中有数百万只松鼠),整个学习过程中都没有直接学习过驯鹿,该程序也可以区分出松鼠和驯鹿。
Tim Cohen是俄勒冈大学的一名理论粒子物理学家,同时,他也研究弱监督学习,他指出,“这不是魔术,但像魔术一样神奇”。
相比之下,粒子物理学中传统的搜索方法,通常要求研究员对新现象做出假设。
他们通过创建模型,描述一个新粒子会如何表现,例如,新的粒子可能会倾向于衰变成已知粒子的特定星座。只有在他们定义了他们要寻找的东西之后,他们才能设计出自定义搜索策略。这项任务通常要花费一个博士生至少一年的时间。
Nachman认为,在机器学习的帮助下,这个过程可以完成得更快,更彻底。
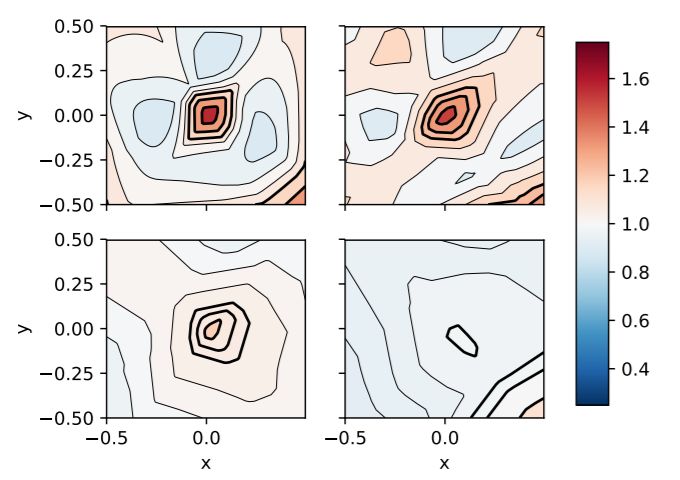
在无监督学习中,通过调整参数的值(图中测试因子分别为10%,5%,1%,和0),构建不同的分类器,可以实现网络性能的变化。以二维模型中的数据为例,训练结果如图所示。前两个例子,网络能够正确地找到信号区域,但也出现了过拟合现象。左下方例子中,网络在信号区域附近找到了正确的形状,性能没有损失,最后一个网络无法收敛到信号区域。 | 论文①图4
CWoLa算法
,表示无监督学习(Classification Without Labels),可以搜索任意未知粒子的现有数据。未知粒子会衰变成相同类型的两个较轻的未知粒子,或两个相同或不同类型的已知粒子。
利用普通的搜索方法,LHC机构至少要花费20年时间才可能找到后者存在的可能性,目前对前者的搜索也没有任何结果。
但研究ATLAS项目的Nachman提出,CWoLa可以一次完成所有的这些工作。
论文②题目:
The unexplored landscape of two-body resonances
论文②地址:
https://arxiv.org/abs/1610.09392
其他实验粒子物理学家也一致认为,这是一个有价值的项目。
Kate Pachal是一名物理学家,她在ATLAS项目中寻找新的粒子碰撞,她说道,“我们已经观察了很多可预测的区域,对我们来说,下一步的方向是,观察那些我们没看过的角落。” 去年,她和几个同事一直在试图设计灵活的软件,来处理一系列粒子,但他们中没有人对机器学习有足够的了解。她说,“我想现在是时候试一试这个技术了”。
虽然当前的数据集不利于建模工作,但卷积神经网络有希望发现数据之间微妙的相关性。其他的机器学习技术已经成功地提高了LHC某些任务的效率,比如识别由底夸克粒子制成的“喷流”。
论文③题目:
Machine Learning AIgorithms for b-Jet Tagging at the ATLAS Experiment
论文③地址:
https://arxiv.org/abs/1711.08811
这项工作表明,物理学家们确实在错过一些信号。加利福尼亚大学欧文分校的粒子物理学家丹尼尔怀特森说:“物理学家们将信息留在桌面上。不过如果你已经在机器上花了100亿美元,你并不会想把信息留在桌面上。”
然而,机器学习充满了将手臂与哑铃(甚至更糟糕的事物)相混淆的程序的警示故事。
在LHC,实验性物理学家努力地想要忽视机器自身存在的小问题,但有人担心这种捷径最终会反应出这些问题。ATLAS的物理学家Till Eifert问道,“发现异常时,它是物理学的新突破呢,还是探测器发生了什么有趣的事情呢?”
翻译:尚奇奇
审校:刘培源
编辑:王怡蔺
原文地址:
https://www.quantamagazine.org/how-artificial-intelligence-can-supercharge-the-search-for-new-particles-20180723/
图卷积神经网络(GCN)
人脸识别尺度技术
机器学习成功预测混沌
量子机器学习1.0时代
机器学习 | 傅渥成
加入集智,一起复杂!

课程地址:https://campus.swarma.org/gcou=10337

集智QQ群|292641157
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!










