
主题
“网络、几何与机器学习”研读营是由集智俱乐部主办、凯风基金会资助的“复杂系统的信息物理研讨会”系列活动的第三期。我们于2018年6月22日至6月27日在中国云南省大理市喜林苑举行为期5天的前沿文献研读和讨论活动,主题范围涵盖:复杂网络、统计物理、量子物理与机器学习。
其目的是为了从这些前沿科学领域获得新的研究灵感以及促进集智科学家成员之间的彼此互动、交流,从而孕育全新的科研思想。
背景
网络、几何与机器学习研讨会旨在把握当前前沿物理学与人工智能的发展趋势与本质。一方面,复杂网络模型可以用于理解时空的本源,也可以构建复杂的神经网络,模拟大脑的思维。
另一方面,网络是几何学的进一步延伸与拓展,我们利用几何化的思路来抓住网络背后的简单原理,机器学习则是一种必要的技术。 传统的社会科学研究的一个主要目标是模仿自然科学把社会活动及其背后的原理运用数学进行定量化。
近年来在科学界掀起的注重关系而非实体的思潮可能给这种社会科学-自然科学的交融的产生很大的影响,从而产生新的研究范式。
这种范式注重数据分析和社会活动所依托的复杂网络,运用近年来在人工智能领域很有可能在不远的将来颠覆以往的社会科学的研究方式。因此,本研讨会的研讨结果将有可能对社会科学研究产生重要的作用。
本届研读营是对2016年和2017年两届研读营的延伸讨论,主题涉及:张量网络、深度学习、消息传播算法等。
李熙,中南大学哲学系讲师
肖达,北京邮电大学讲师,彩云科技首席科学家
张江,北京师范大学教授,集智俱乐部创始人、集智AI学园创始人
张潘,中国科学院理论物理研究所副研究员
尤亦庄,加州大学圣地亚哥分校助理教授
吴令飞,芝加哥大学计算中心知识实验室博士后
王成军,南京大学新闻传播学院副教授
傅渥成(唐乾元),东京大学大学院综合文化研究科特任研究员
苑明理,彩云科技软件工程师
李林倬,芝加哥大学在读博士生
章彦博,本科毕业于中科大物理系,即将赴亚利桑那州立大学攻读博士学位
罗秀哲,中国科学院物理研究所科研助理
程嵩,中国科学院物理研究所在读博士
刘晶,北京师范大学系统科学学院在读直博生
张章,北京师范大学系统科学学院科研助理
二零一八年六月,云南大理,玉洱银苍,云奔山横。二十三日,集智俱乐部第三次研读营,在大理喜林苑举行。
第一日下午,我们正式开始进行交流、讨论。来自加州大学圣地亚哥分校的尤亦庄与东京大学的傅渥成与大家分享了他们的想法与工作。
尤亦庄首先分享了他近期的思想,主要是关于重整化与生成模型。在一般的话语中,我们常常说「重整化群」,但由于重整化中包含pooling的过程,所以实际上重整化的过程是不构成群的,因为其中有信息的丢失。那么,如何在有信息丢失的情况下,构造一个真正的重整化群呢?我们可以放弃对于个例的精确追求,而从系综的层面构造重整化群。就以卷积神经网络里「卷积+pooling」的过程为例。

每一次pooling之后,总会损失信息,从而使得这个过程不可逆。然而,在系综的层面上来看,我们是可以构造一个生成模型,将这个过程逆向,但目标是使得生成的信息,符合原始信息的分布。这就要求在pooling的过程中,保留的信息之间,互信息要尽量的多;而省略的信息之间,互信息要尽量的少。这样,在一轮轮的重整化中,我们就保留了原始信息中最独特的部分。
尤亦庄还提到,这种思想还可以与AdS/CFT联系起来。而通过进一步的思考,我们可以发现,在逆向的生成过程中,数据就像在一个庞加莱圆盘上行走——从中心到边缘。
自达尔文提出进化论以来,大家逐渐开始相信「适者生存」的论断。然而,傅渥成在他的分享中,对「适者生存」作出了一点挑战。

傅渥成
我们思考一个模型:如果一个生物进化到了非常适应自然的情况,那么,对于这个个体,他确实会生活的非常舒服:天敌、食物、繁殖,都不是问题。但是,如果这个「完美的DNA」稍有变化,性状就发生巨大的变化,而且是很坏的变化,那这个基因能遗传下去吗?不能,因为变异总是普遍发生的。这就要求生物不仅仅要适应环境,而且要对外界的改变不那么敏感。
这种思想,就给适者生存添加了时间的维度,使得生物进化不能只在当前最优中选择。这就像两个小球,一个在锅底,一个在很深试管中。相比较而言,试管底部的能量更低。但是,只要有一个外部的扰动,「试管底部」这个位置可能就会变成试管口的高度,同时锅底的高度却没有明显的变化。
如果我们把能量低的位置看作「更合适的位置」,那么在不断的扰动下,「试管底」这个全局最优位置,就不会流传给后代;反而是锅底这个局部最优点,可以代代相传。从这个角度看,进化,不只是适者生存。
上午,中科院理论物理所的张潘分享了张量网络在机器学习上的一个具体应用——生成模型。对张量网络的讨论贯穿了前两届研读营。张潘首先简单回顾了张量网络的基本概念,并重点介绍了矩阵乘积态(MPS, matrix product states)这一特殊的张量网络。

张潘
借助量子力学中概率诠释的思想,张潘介绍了名为Born Machine的生成模型,以及模型的具体细节和训练方法。最后,张潘在Jupyter Notebook上为大家演示了MPS Born Machine的代码实现。
下午,来自中科院物理所的程嵩分享了张量网络和机器学习的历史渊源。早在2013年,便有研究者发现了重整化群和深度学习之间的映射关系。虽然这一结论并不严格,但依旧吸引了物理学家的关注。

程嵩
之后,物理学家发现了张量网络和机器学习的诸多相似性,在此基础上论述了深度学习之所以有效的原因。最后,程嵩介绍了几个张量网络与机器学习相结合的代表性工作,并总结了张量网络方法的优缺点。
下午,来自中国科学技术大学的罗秀哲分享的主题是量子计算和他开发的量子计算工具——“幺”。

罗秀哲
“幺”基于Julia语言,是为量子算法设计而开发的架构,具有拓展性强、效率高等特点。罗秀哲为大家介绍了量子计算的前景,并利用“幺”为大家演示了量子计算中的基本操作和算法实现。
在人们的直觉中,普遍认为更复杂的东西更难研究。但如何从定量的角度回答呢?章彦博分享了一个从算法信息论(AIT)出发的实证研究。首先用 Kolmogorov 复杂度来定义复杂,以及统计复杂度。

章彦博
由于图灵停机问题不可计算,Kolmogorov 复杂度无法通过明确的程序求得,但我们可以计算 Kolmogorov 复杂度的上界。对于小系统,可以用穷举图灵机来估计 Kolmogrov 复杂度,对于更大的系统,可以用 BDM 方法来估计。
更复杂的系统更难研究吗?章彦博把“研究一个系统的难度”定义为“从演化数据中获得动力学机制所需要的时间”。
用元胞自动机作为模型,对于一个元宝自动机的演化时空图,我们可以通过对它的观测,从简单模型出发,到更复杂的模型,来从可能的动力学中找到其真正的演化机制。最后得到了数值验证——更复杂的系统确实更难研究。
肖达分享的主要内容有神经编程与self-attention两部分算法。

在神经编程讲座环节,肖达先分享了这个领域在近几年的发展现状,然后展示了彩云在神经编程领域的工作。彩云的最新论文中,提出了一种新的神经编程解释器,他们提出“组合子”和“应用子”的概念,通过强化学习的方式让AI自己尝试生成可以完成如排序等任务的算法程序。
在self-attention讲座环节,肖达分享了self-attention方法的原理,传统的RNN(循环神经网络)模型难以关注长程链接,而self-attention正是在这一点上取得了突破。因而能在序列生成、翻译等任务重都能有更好的表现。
李熙是通用人工智能领域的研究者。通用人工智能领域的理论研究希望通过一个数学模型来概括智能的本质。

李熙
那么,什么是智能的本质?李熙认为,智能的系统应该拥有通用归纳的能力,能够逼近任意可逼近的模式,并利用归纳的结果,通过一些行动与环境进行互动,取得最好的收益。
即“智能”是一个个体能够在复杂多变的环境中选择行动,达成目标的能力。在本次讲座中,李熙不但给大家展示了怎样从纯数学 的角度来定义人工智能中的基础概念,例如从如何从逻辑学的角度定义“复杂性”与“随机性”,也为我们展示了前沿的理论突破,比如著名的“AIXI模型”和“哥德尔机”。
张江分享了图网络领域近年来的发展现状和一些在图网络数据处理中非常重要的算法,如节点的嵌入、聚类,节点上的信息整合,网络上的动力学的学习,注意力机制在图网络数据上的应用等。

张江
张江着重介绍了在图网络数据中非常有用的GCN算法,GCN(Graph Convolutional Network)算法类似于图像处理领域的CNN,它可以整合节点和邻居节点的信息,使我们可以更方便的提取网络的信息,进行网络的状态预测等研究。
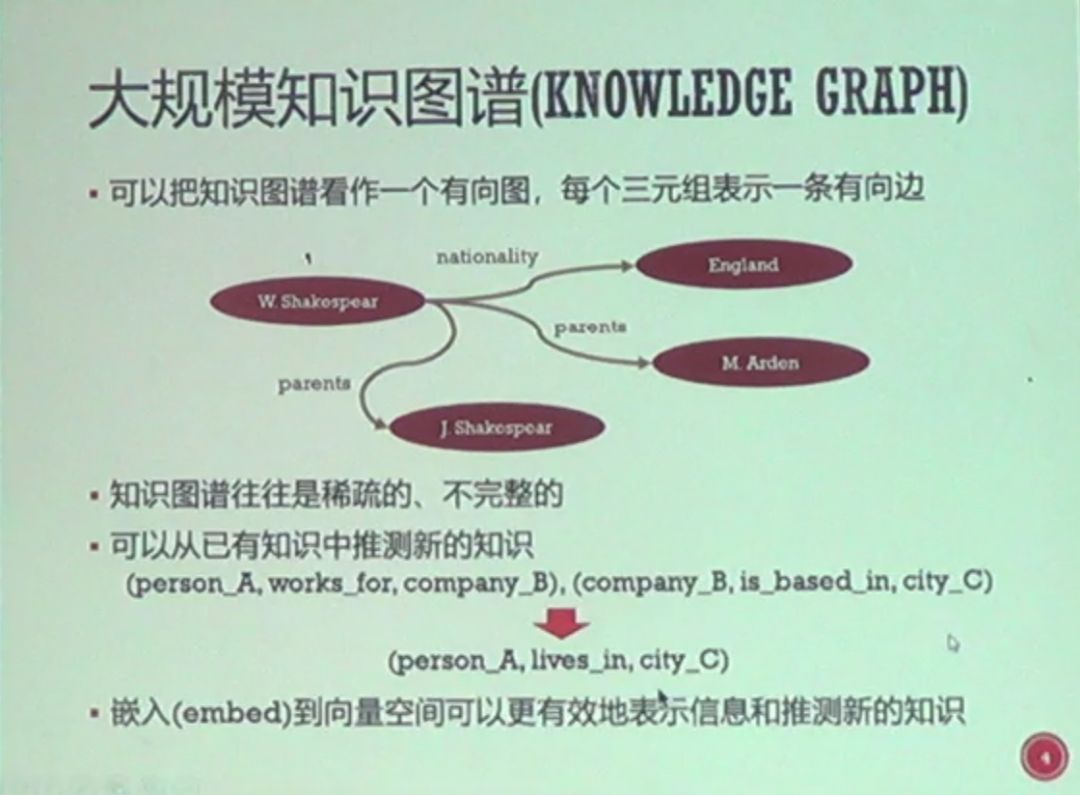
张力文:知识图谱的表示及在自然语言问答系统中的应用
在研读营的第四天上午,现场的学者与来自北美芝加哥大学计算机系的张力文博士进行了跨海视频通话。张力文博士详细讲解了“知识图谱的表示及在自然语言问答系统中的应用”。
张力文等远程参会者
内容包括“什么是知识图谱?”,“为什么要在向量空间里表示?”,“如何表示知识图谱里的实体和关系?”,“如何表示复杂关系的表示”等等。
接下来是由来自南京大学的王成军副教授围绕最近开展的“故事生成模型”进行的研究。

王成军
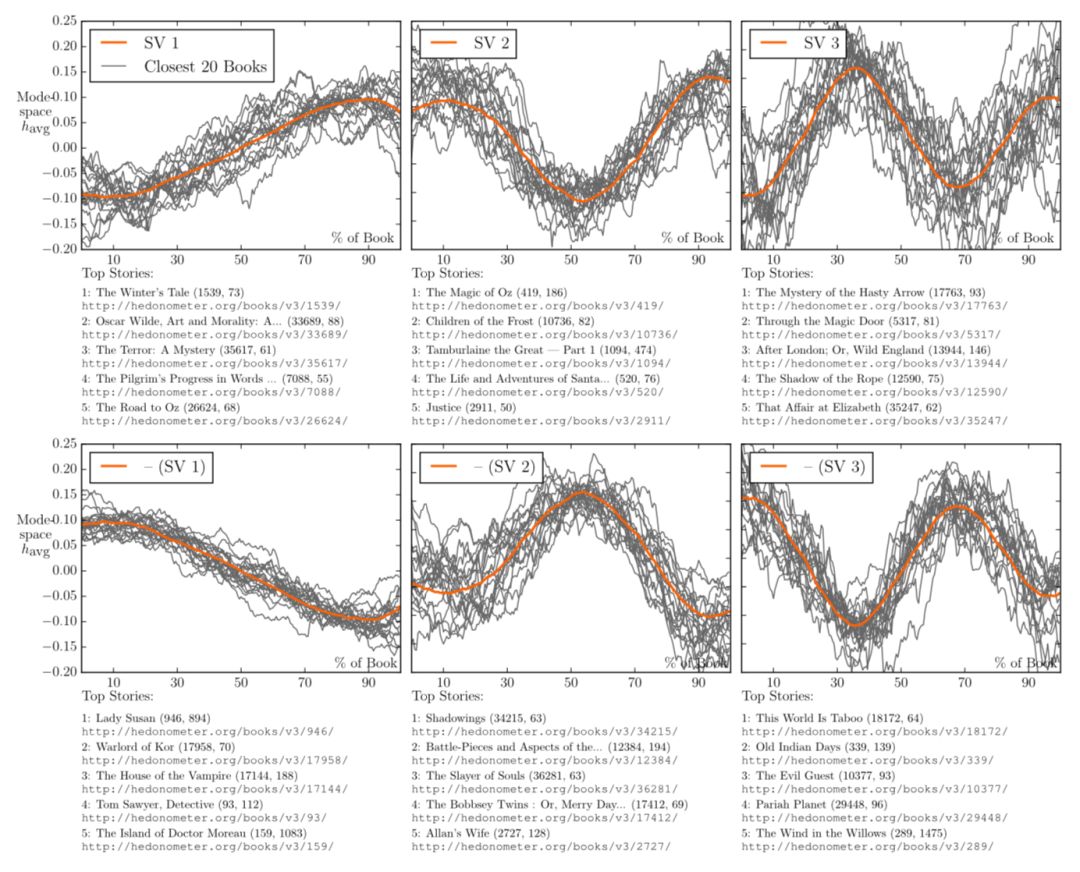
王成军介绍了关于“Shape of Story”的研究,这个研究是尝试去寻找故事中叙事线条的形状 。实际上人们喜闻乐见的故事都是有一定的“叙事波动”可以追寻的,而探究这种情感波动的一种方法是通过词嵌入来分析故事中的情感语义。
王成军还介绍了关于单词意义随着时代而变化的研究“HistWords”,在不同的时代,一个词意义的变化,可以通过这个词的邻居词来理解。比如“gay”这个词,在1900年比较靠近高兴的意义,而在1950年就掺杂了一些“智慧、机智”的意义,而到了1990年就基本上是我们现在的意思了。
吴令飞:AI & Future Employment
第四天下午,来自芝加哥大学 Knowledge lab 的吴令飞博士,介绍了围绕人类工作与相关技能组合的一系列的研究。

吴令飞
关于“AI未来会代替多少人类的工作”这一热门话题,吴令飞介绍了关于这个问题的研究情况。首先介绍了关于“Bottleneck Theory”的研究,这个工作研究了未来人工智能将会取代多少人类的工作,以及这个取代速度会有多快。作者认为,难以被AI替代的工作应该具有以下三种特征,即“需要较强的创造性(Creativity)”、“需要较强的沟通(Social Intelligence)”、“需要高精度的感知与控制(Perception and Manipulation)”。
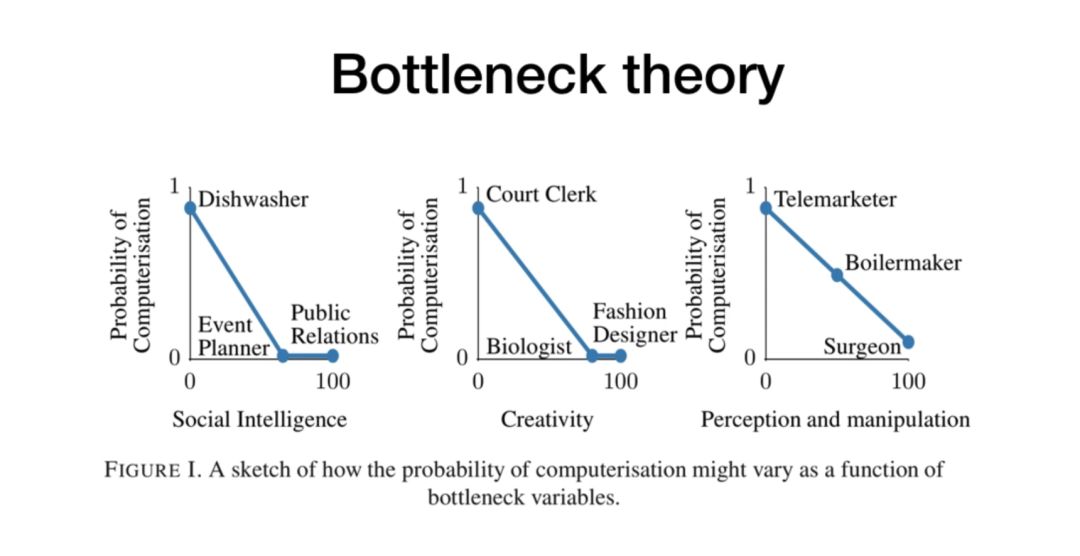
最后吴令飞介绍了他们研究组的相关工作。首先是技能的嵌入与表示,通过对36个技能在966个工作中的应用情况可以得到36个966维的向量,那再使用类似Word2Vec词向量的降维表示方法,可以得到明显的聚类。
第四天最后是由李林倬讲解的通过词嵌入(词向量)的语义分析来研究文化的抽象几何表示的研究。通过对一些特定词的词向量进行几何表示,我们可以从中分析出包括性别、贫富差距等语义特征在几何图形中的表示。

李林倬
比如当我们将多种球类运动的词向量同时放在一个三维的几何空间中进行表示时,我们能清楚的看到人们对这些球类运动的认知语义,包括哪些运动是更倾向于哪种性别进行的,以及哪些运动在人们看来是“更加富有”的运动等等。
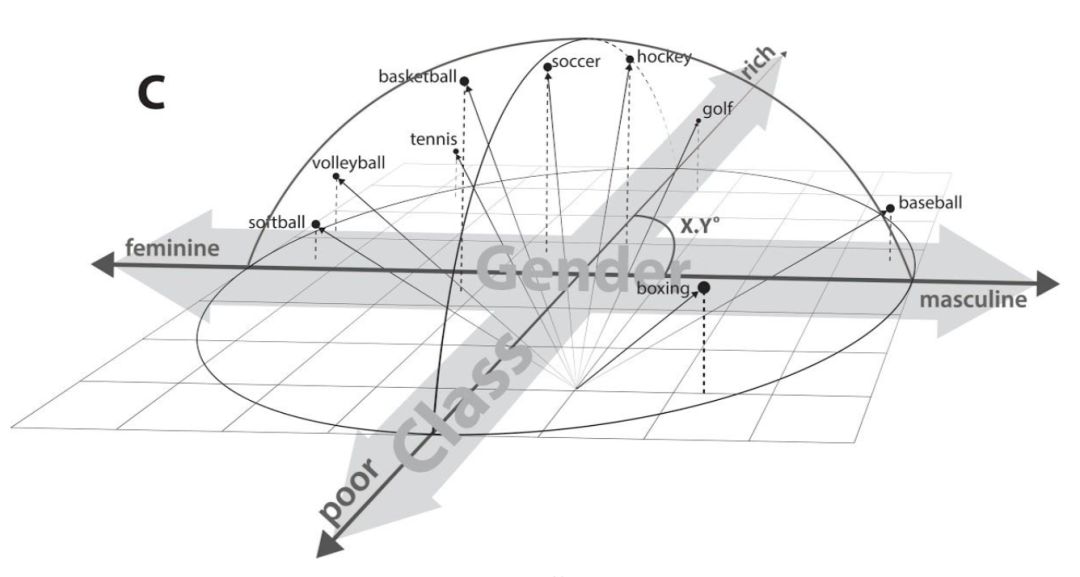
张潘:
tutorial
http://lib.itp.ac.cn/html/panzhang/mps/tutorial/
文章:
https://arxiv.org/pdf/1806.05964.pdf
notebook:
http://lib.itp.ac.cn/html/panzhang/mps/tutorial/mps_tutorial.zip
罗秀哲:
slides:
http://104.224.129.42/slides/yao/#/
Julia官网地址:
julialang.org
关于Julia语言可以看我另外一个Slide:
http://104.224.129.42/slides/the-julia-language/
如果想试用我们的package可以查看文档:
https://quantumbfs.github.io/Yao.jl/latest
JuliaPro 0.6.3.1 C MKL (for Mac)
https://shop.juliacomputing.com/Products/index.php?eddfile=297339%3A295304%3A123%3A0&ttl=1530013556&file=123&token=15ba69a82b56534b8abbe74a34271d50
肖达:
展示链接:
http://www-personal.umich.edu/~reedscot/iclr_project.html
百度网盘资料:
https://pan.baidu.com/s/17RD6hIMkVi3o4wNrwcf9Rg

内容:章彦博,张章,刘晶,朱瑞鹤
编辑:孟婕

课程地址:http://campus.swarma.org/gpac=380
2017集智-凯风研读营记录
2017集智-凯风研读营记录
2017集智-凯风研读营记录
2017集智-凯风研读营记录
2016集智-凯风研读营记录
2016集智-凯风研读营记录
2016集智-凯风研读营记录
加入集智,一起复杂!

集智QQ群|292641157
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!










