
新智元编译
来源:ICML'18 Tutorial
编译:金磊
【新智元导读】目前深度学习的应用较为广泛,尤其是各种开源库的使用,导致很多从业人员只注重应用的开发,却往往忽略了对理论的深究与理解。普林斯顿大学教授Sanjeev Arora近期公开的77页PPT,言简意赅、深入浅出的介绍了深度学习的理论——用理论的力量横扫深度学习!(文末附PPT下载地址)
学习任何一门知识都应该先从其历史开始,把握了历史,也就抓住了现在与未来 。——BryanLJ
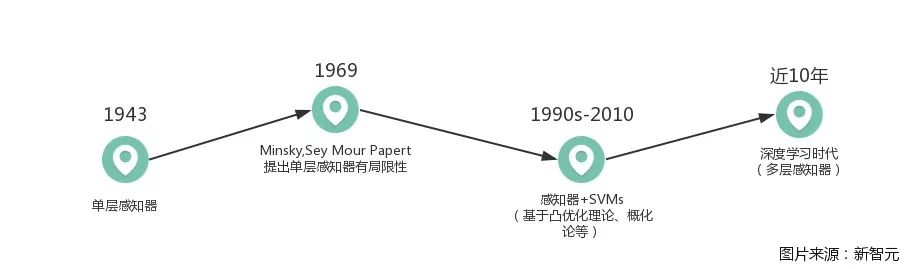
由图可以简单看出深度学习的发展历史,在经历了单调、不足与完善后,发展到了如今“动辄DL”的态势。
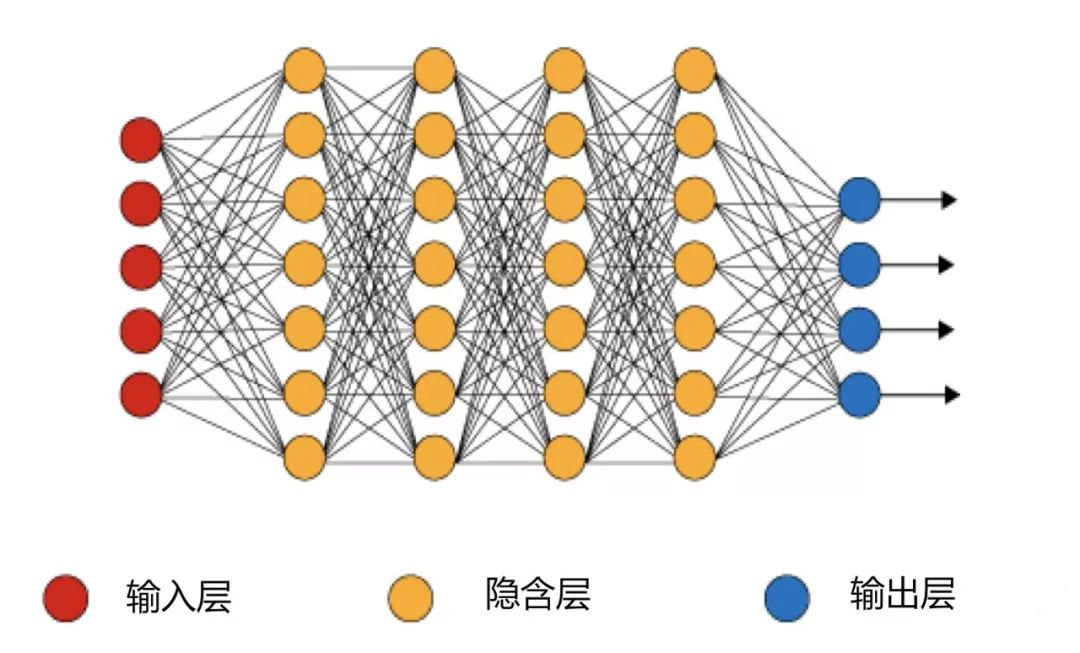
神经网络基本结构图:
定义:
θ:深度网络的参数
训练集:(x1, y1) ,(x2, y2) ,…,(xn, yn)
损失函数 ζ(θ,x,y):表示网络的输出与点x对应的y的匹配度
目标: argminθEi[ζ(θ,x1, y1)]
梯度下降: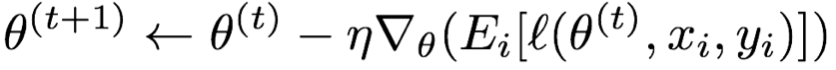
结合GPUs、大型数据集,优化概念已经塑造了深度学习:
反向传播:用线性时间算法来计算梯度;
随机梯度下降:通过训练集的小样本评估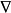 ;
;
梯度、解空间推动形成了残差网络(resnet)、WaveNet及Batch-Normalization等;
理论的目标:通过整理定理,得出新的见解和概念。
困难:深度学习中大多数优化问题是非凸(non-convex)的,最坏的情况是NP难问题(NP-hard)。
维数灾难:指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象
深度学习“黑盒”分析:
原因:
1、无法确定解空间;
2、没有明确的(xi, yi) 数学描述;
所以,求全局最优解是不可行的。

未知解空间中的控制梯度下降:
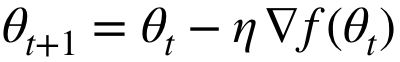
≠0→∃下降方向,但如果二阶导数比较高,允许波动很大。为了确保下降,采用由平滑程度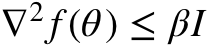 (可由高斯平滑 f来定义)决定的小步骤。
(可由高斯平滑 f来定义)决定的小步骤。
平滑: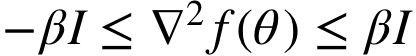
要求: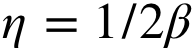 →满足
→满足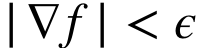 且与
且与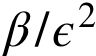 成正比。
成正比。
非“黑盒”分析:
很多机器学习问题是
深度为2的子案例,例如,输入层和输出层之间的一个隐含层。通常假设网络的结构、数据分布,等等。比起GD/SGD,可以使用不同算法,例如张量分解、最小化交替以及凸优化等等。
过度参数化(over-parametrization)和泛化(generalization)理论
教科书中说:大型模型会导致过拟合

很多人认为:SGD +正则化消除了网络的“过剩容量”(excess capacity),但是过剩容量依旧还是存在的,如下图所示:
事实上,在线性模型中也存在同样的问题。
泛化理论:
测试损失(Test Loss)-训练损失(Training Loss)≤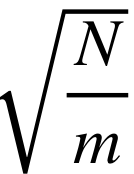
其中,N是“有效能力”。
“真实容量”(true capacity)的非空估计被证明是难以捉摸的:
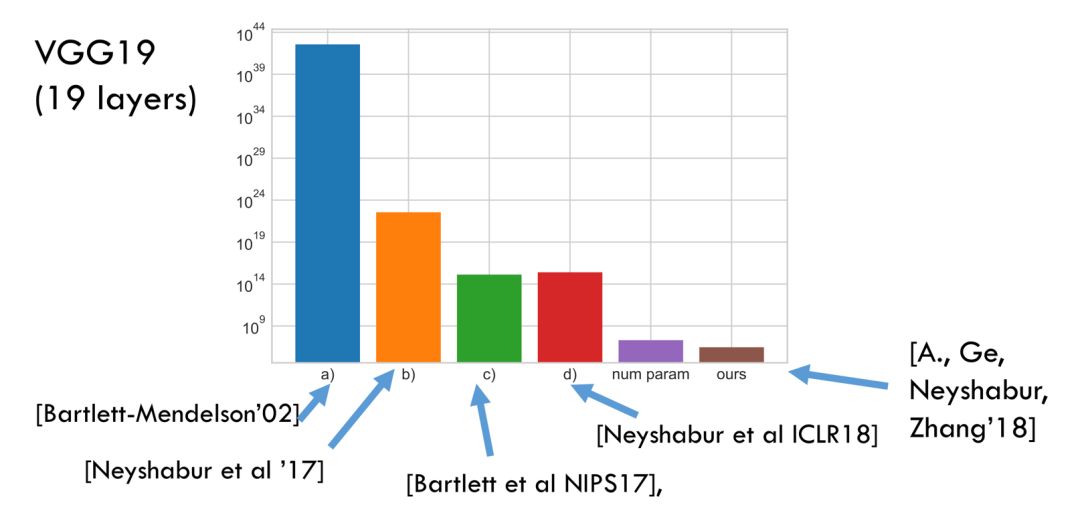
“真实参数”(true parameters)的非空边界被证明是难以捉摸的:
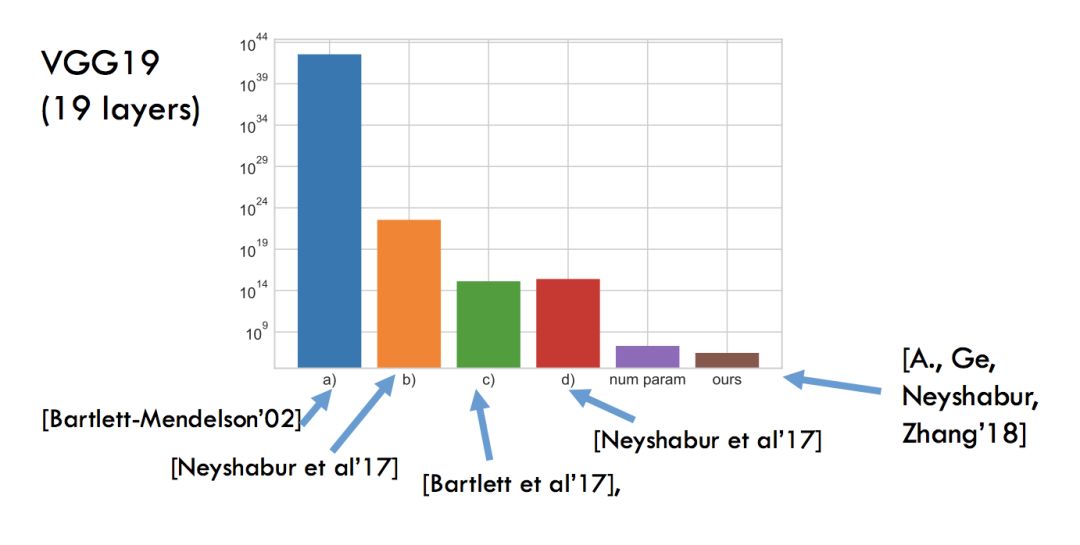
深度网络噪声稳定性(可以视作深度网络的边缘概念):
噪声注入:为一个层的输出x添加高斯η" role="presentation" style="max-width: none; font-size: 14px; float: none; direction: ltr; max-height: none; min-width: 0px; min-height: 0px; color: rgb(79, 79, 79); left: 0px; clip: rect(1px, 1px, 1px, 1px); display: inline; transition: none; vertical-align: 0px; line-height: normal; word-break: break-all; height: 1px !important; width: 1px !important; overflow: hidden !important;">η 。
测量更高层次的变化,若变化是小的,那么网络就是噪声稳定的。
VGG19的噪声稳定性:
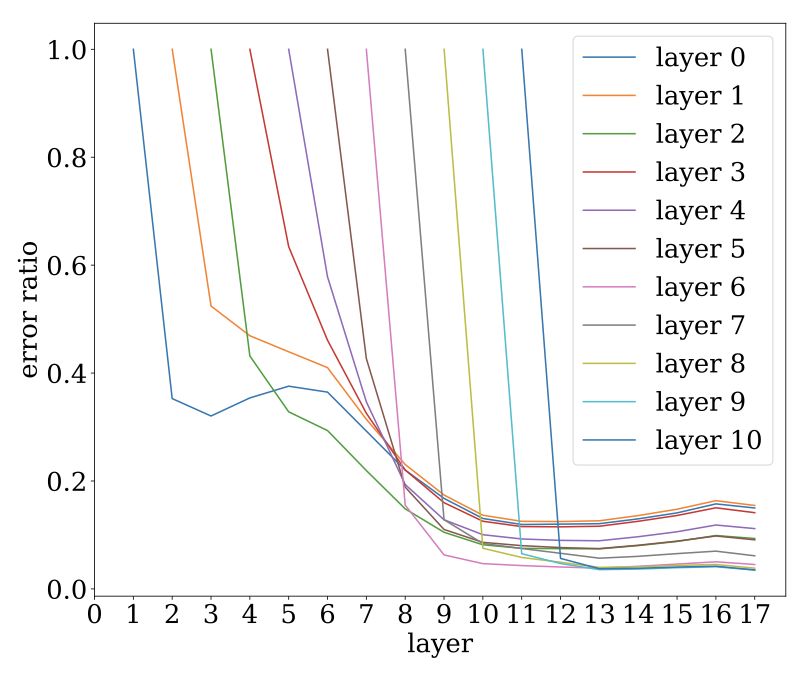
当高斯粒子经过更高层时的衰减过程
与泛化相关定性实验:
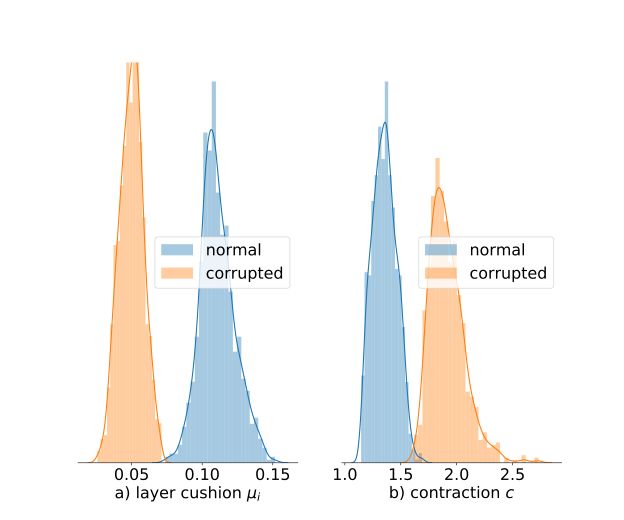
垫层(layer cushion)在正常数据上的训练要比在损坏数据上的训练高得多
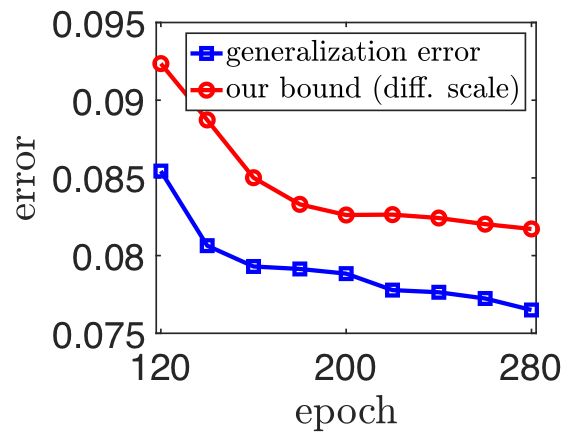
在正常数据训练过程中的进化
深度的作用是什么?
理想的结果是:当遇到自然学习问题时,不能用深度d来完成,但可以用深度d+1来完成。但是目前,由于理论依据不足,缺乏“自然”学习问题的数学形式化,还无法达到理想的结果。
深度的增加对深度学习是有益还是有害的?
支持:会出现更好的表现(正如上面实验结果所示);
反对:使优化更加困难(梯度消失(vanishing gradient)、梯度爆炸(exploding gradient),除非像残差网络这样的特殊架构)。
无监督学习:“流行假设”(Mainfold Assumption):


学习概率密度p(X|Z)的典型模型
其中,X是图像,Z是流行上的编码。目的是使用大量未标签的数据集来学习图像→编码匹配(code mapping)。
深度生成模型(deep generative model)
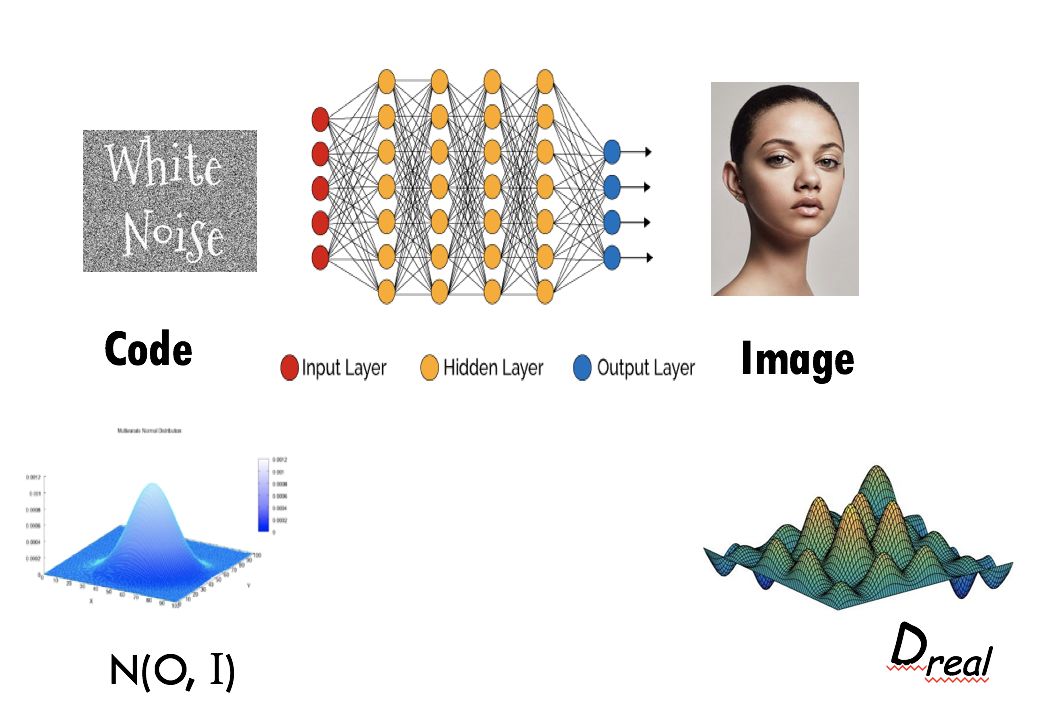
隐含假设: Dreal是由合理大小的深度网络生成的。
生成对抗网络(GANs)
动机:
(1)标准对数似然函数值(log-likelihood)目标倾向于输出模糊图像。
(2)利用深度学习的力量(即鉴别器网络,discriminator net)来改进生成模型,而不是对数似然函数。
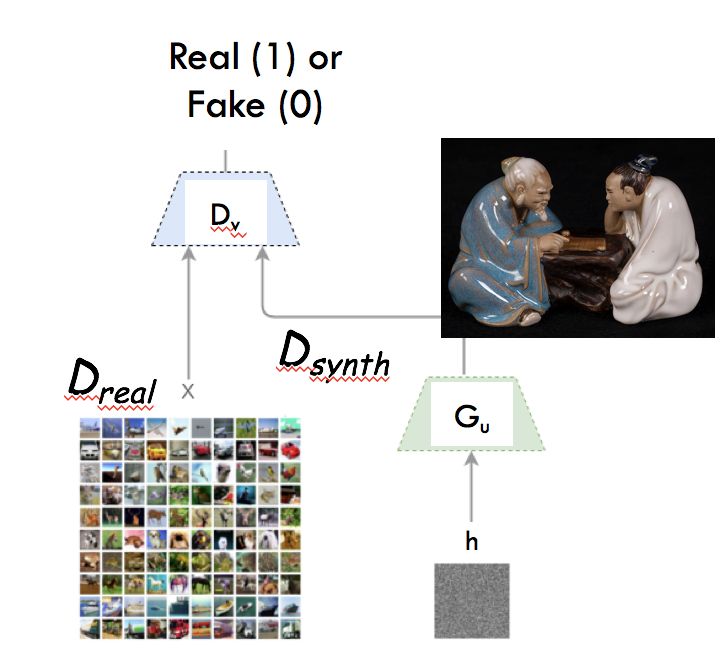
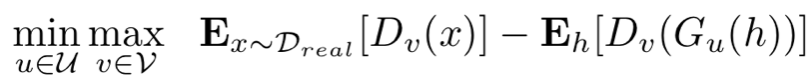
u:生成网络可训练参数
v:鉴别器网络可训练参数
鉴别器在训练后,真实输入为1,合成输入为0。
生成器训练来产生合成输出,使得鉴别器输出值较高。
GANs噩梦:模式崩溃(mode collapse)
因为鉴别器只能从少数样本中学习,所以它可能无法教会生成器产生足够大的多样性分布。
评估来自著名GANs的支持大小(support size)

CelaA:200k训练图像
DC-GAN:重复500个样本,500x500 =250K
BiGAN和所有支持大小,1000x1000 =1M
(结果与CIFAR10相似)
无监督学习文字嵌入经典流程
常用方法:复发性神经网络或LSTM等
手工业(cottage industry)的文本嵌入是线性的:
最简单的:构成词(constituent word)的词嵌入求和
加权求和:通过适应段落数据集来学习权重
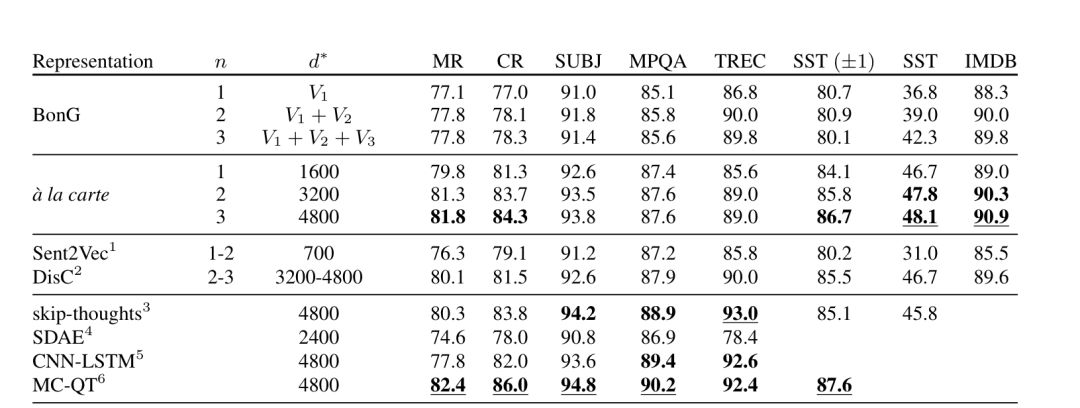
性能(相似性、蕴涵任务):

较先进的句子嵌入方法与下游分类(downstream classification)任务的比较:
附:普林斯顿大学教授:深度学习理论理解(77页PPT)下载地址:
https://www.dropbox.com/s/qonozmne0x4x2r3/deepsurveyICML18final.pptx
延展阅读:企业采用人工智能需要考虑的三大因素
当下,越来越多的公司在人工智能上进行投资。然而,要想取得成功,他们需要在推理的可解释性、低数据密度环境以及实现更丰富的知识图谱方面进行实际考量。

在企业中,人工智能的应用正在稳步上升。根据Constellation Research对众多行业C级管理人员的调查,70%的受访者表示他们的组织目前使用了某种形式的人工智能技术。此外,大部分受访者表示,2018年将在人工智能投资上花费高达500万美元。
随着越来越多的公司意识到人工智能带来的巨大机遇,他们逐渐意识到需要考虑一些实际问题,以便在整个企业中看到这项新技术将带来的重大业务影响。根据我们在众多客户环境中应用人工智能的经验,我们发现组织必须解决三个因素:缺乏可解释的人工智能、低数据密度环境以及对更丰富的知识图谱的需求。为了正确采用和实施,企业必须首先考虑这些实际问题,并在整个AI实施过程中始终将其放在首位。
1.缺乏可解释的人工智能
可解释的AI集中在回答问题的能力上,“为什么?”“为什么机器会做出某个具体的决定?事实上,许多新出现的人工智能都有一个固有的“黑匣子”概念。“将很多数据输入到盒子里,然后从盒子里拿出实际的决定或建议。然而,当人们试图打开盒子并弄清楚它的逻辑时,它就成了一个重大挑战。这在受监管的市场上可能很难被采用,因为市场会要求公司披露和解释具体决策背后的理由。此外,缺乏可解释的人工智能可能会影响整个公司所需的变更管理,以便成功实施人工智能。如果人们无法追踪到原始数据集或文档的答案,那么它可能会成为一个员工难以接受的价值主张。
实现具有可追溯性的人工智能是应对这一挑战的一种方式。例如,商业银行管理在线投资组合中的风险。银行可以向5000家中小企业贷款。它将在贷款组合的资产负债表中监测他们的健康状况。这些表可以是不同的语言或有不同的会计标准。
有了人工智能,银行实际上可以利用所有的这些资产负债表,提取信息,将非结构化数据转换为结构化数据,然后得出风险评分。该银行应该能够接受风险评分,点击并深入查看导致最终评分的子组件编号。如果发现有一个分数看起来不太对时。用户可以深入到下一个细节层次,依此类推,直到他们得出没有意义的数字,然后,例如,可以将他们引向第16页的第36个资产负债表。在那里的脚注里会有系统用来推导分数的信息。用户可以查看一个决策并解析驱动机器到达该端点的组件信息。可追溯性的实现有助于合规性的满足并推动人工智能的应用。
2.低数据密度环境
当人工智能能够利用大量数据时,它就能运行得很好。例如与Siri等虚拟助手进行会话AI,可以访问电子邮件,在线购物和多个应用程序。这就是为什么大多数AI应用程序都是在企业对消费者(B2C)环境中开始的,在B2C环境中,算法可以运行在数百万个数据点中。企业通常无法始终访问相同的数据量。例如,如果一个组织正在准备过去的合同,那么它可能要处理10万份合同——而不是100万或1000万份。因此,企业面临着双重挑战:他们需要手动处理的文件太多而无法训练算法。从这些文档中提取数据的一种方法是通过使用统计方法的传统自然语言处理算法。此外,我们还发现,基于上下文来解读含义和提取数据的计算语言学在受到少量数据的挑战时可能是有效的。
在另一个例子中,一家财富管理公司可以使用自然语言处理和机器学习等技术,以高速聚合金融机构和投资者的报表。每家公司可以有8万份文件,每份50到60页长,每页40到50笔交易,最终从中提取知识。这是一个相当大的数据量,并且手动处理非常繁琐,但只是许多主流人工智能应用程序数据量的一小部分。
因此,需要注意的是,并非所有人工智能都能获得其必须的数据量。在确定最佳人工智能解决方案时,了解数据环境非常重要。在高数据密度环境中,组织可以更有效地运行无监督学习算法。在低数据密度的环境中,监督学习是最有效的。在缺乏所有必要数据的情况下,合成数据创建等新技术可以帮助企业培训模型。例如,在零售业,公司可以使用游戏模拟来创建合成数据。
3.需要更丰富的知识图谱
正如人工智能在低数据密度环境中难以产生最优结果一样,人工智能目前还缺乏丰富的知识图谱,无法使人工智能与特定领域和行业应用相关联。
知识图谱可以捕获上下文的关系,在人工智能中训练数据模型,并在正确的上下文中对传入的信息进行分类。它们使像Alexa或Siri这样的语音助手能够回答常见的问题,比如“最近的星巴克在哪里?”Alexa和Siri可以通过连接数以百万计的参考点(包括来自亚马逊或苹果服务的搜索结果)为用户提供即时答案。虽然对于这些简单的交互很有用,但是当前的AI仍然无法复制或理解真实人类对话的复杂性并捕获消费者期望的经过深思熟虑的交互。
例如,如果一个五岁的孩子抱怨他的母亲,“Ben推了我。我摔倒了,我站了起来,把他推了回去。老师看到了我,但是没有看到Ben,所以只有我被留校了——这不公平。”每个五岁的孩子都会理解这句话的意思,但是对于人工智能系统仍然会遇到困难,因为他们不理解因果关系和公平。除了知识图谱,人工智能系统还需要对话界面来完成他们的思考。
在企业内部,许多人通过聊天机器人来使用会话式的人工智能,试图为客户提供更具互动性的体验。在这方面,银行一直站在最前沿,允许客户通过聊天机器人在他们的在线门户或移动应用程序中获取基本的账户信息。然而,更复杂的请求,如贷款申请或合同审查,对机器来说可能是一个挑战。机器人需要能够将所使用的词的本体、所问问题的上下文以及多个会话流的线程连接在一起进行综合考虑。它需要特定领域、特定语境、特定知识的有机结合,才能使整个过程更加流畅。公司正在积极地开发特定领域的AI,并将它们嵌入到正确的知识管理系统中,以便在商业环境中推动AI实现更有吸引力的体验和应用。
随着人工智能的不断投入和实施,企业必须考虑这三个实际因素:首先,打开黑匣子,跟踪机器的决定,并以一种可解释的方式呈现它。其次,知道如何在没有大量信息的环境中应用人工智能。最后,嵌入领域知识和体验式学习,以丰富它们的知识图谱并推动实现更有效的人工智能应用。


工业互联网操作系统
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业工业互联网操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)
,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com










