三、特征构建要分析视频文件,第一步是构建相关的音频和视觉特征。在本节中,我们将描述用于特征提取和构建的方法。虽然我们按此顺序讨论视觉和音频特征,但它们可以单独提取。同一点适用于每个小节中描述的不同视觉和音频特征。3.1.视觉特征
3.1.1视频摘要。视频数据由音频和视觉部分组成。音频数据以数字信号的形式出现,如第2.2节所述,而视觉数据则以图像序列的形式出现,称为帧。我们的YouTube数据集中的大多数视频都是以每秒24或30帧的帧速率生成的,分辨率为1,280*720像素。由于标准的竞选广告持续30或60秒,因此每个视频包含720-1,800帧,相当于几千兆字节的视觉信息。处理和分析如此大量的数据可能非常繁琐,计算成本也非常高,尤其是在将分析范围扩大到政治竞选活动时,因为政治竞选活动每轮选举都会产生数以万计的广告。虽然现有算法可能能够处理如此大量的数据,但我们的研究重点是自动化不依赖于视频中的运动信息的任务,即候选人和图像文本识别。对于这些任务,连续帧包含与这些变量有关的大致相同的视觉信息,因此帧数据中存在大量冗余。为了提高分析广告视觉内容的效率,我们使用视频摘要程序来获取一组较小的帧,这些帧可以捕获视频中包含的大部分相关视觉信息。我们注意到,这种方法虽然适用于本研究中考虑的变量,但会导致信息丢失。具体来说,摘要不会捕获视频的时间和运动质量,而这些质量仍然包含有关广告内容的重要信息,可能在其他任务中有用。我们使用Chakraborty、Tickoo和Iyer(2015)的算法,因为它简单、易于调整,并且可以灵活地控制摘要中的帧数。该算法允许我们牺牲摘要的唯一性,以减少丢失包含关键信息的帧的机会,从而有助于减轻自动编码任务中的错误分类错误源。该算法的另一个好处是它专为处理低分辨率视频而设计,这大大减少了生成摘要所需的计算量。在我们自己的研究中,摘要导致帧数减少了大约97%-99%,并且每个视频的计算时间大约为20-40秒。这些结果表明,与分析视频中所有帧的方法相比,摘要可能会产生显着的效率提升。图1.自动生成的摘要和手动生成的摘要
为了评估视频摘要程序的性能,我们将自动生成的视频摘要结果与手动摘要结果进行了比较,这些结果来自我们从验证数据集中随机抽取的40个视频文件。我们承认这项研究规模太小,无法对我们的方法得出任何有力的结论,但它仍然有助于了解视频摘要是否会导致重要视觉信息的大量丢失。我们仔细观看每个采样视频,并选择我们认为代表视觉内容的帧。我们的选择标准基于这样的想法:由于视频由一系列镜头组成,每个镜头都代表在两次编辑或剪切之间运行的具有固定摄像机角度的不间断帧片段,因此可以通过单个帧有效地进行摘要。因此,我们通过为每个镜头选择单个帧来构建手动摘要。图1展示了一个示例,它对应于我们40个样本视频中自动视频摘要的最差表现。原始视频文件取自2014年西弗吉尼亚州参议员选举中 Natalie Tennant 的竞选广告。我们发现在这种情况下,自动生成的摘要在广告结尾处缺少三幅图像,一张显示烟囱,一张显示标志,最后一张显示电线。在原始广告中,这些图像快速连续显示,观看时很难发现。此外,他们的遗漏并不重要,因为摘要中前面还有其他几幅图像显示了类似的内容。对于其他39个比较,自动视频摘要的性能甚至更好,可以捕获每个视频文件中包含的大部分视觉信息。3.1.2图像文本识别。许多竞选广告使用图像文本或屏幕文本来提供附加信息、强调广告的某些内容以及显示认可信息和认可。由于我们的目标是分析广告内容,因此提取图像文本并将其用作补充音频文本的特征对于我们的分类任务非常重要。图2展示了一些包含图像文本的帧示例,范围从报纸的使用到政策立场和认可的显示。我们使用Google Cloud Platform(GCP)Vision API对给定视频摘要中的每一帧执行图像文本检测并获取原始文本数据。GCP是一个云计算服务,提供各种数据处理任务,收费很低。由于GCP是一项专有服务,因此关于其使用的算法的信息很少甚至没有。然而,许多人认为Vision API算法基于卷积神经网络(CNN),这是当前图像文本检测和识别文献中的标准方法(Ye and Doermann 2015;Zhu、Yao and Bai 2016)。我们使用图2中的示例来说明API的性能。虽然算法的性能并不完美,但它捕获了大多数图像文本。具体来说,API能够恢复图2 a、c、e帧中的所有文本,而图2b、d、f帧中仅缺少几个单词。在某些情况下,API更加准确。该算法检测到图2a帧中显示的报纸中的所有小文档文本,而人类编码员无法在短时间内处理这些文本。为了缓解这个问题,我们忽略了高度小于总图像高度3.5%的检测到的文本,并且只保留前25个检测到的边界框。该算法还往往会漏掉与背景混合的文本。例如,API无法检测到图2b框架中的“Approve d by Alex Mooney. Paid for by Mooney for Congress”,该文本使用窄字体并与不同的背景混合。该算法还漏掉了图2d框架中的日期“3/21/10”,而正确检测到了所有其他单词。此外,API漏掉了图2f框架中的短语“Donnelly voted to cut”,这可能是因为在“Donnelly”周围使用了方框,并且字体模糊。幸运的是,在这个案例和许多其他案例中,漏掉的短语也是视频中的人说的。最后,我们注意到,糟糕的视频摘要会影响图像文本检测的性能。如果所选帧的图像质量较差,或者摘要中缺少包含文本的帧,则任何算法都很难检测到正确的图像文本。3.1.3 人脸识别。我们还进行人脸识别,以确定广告中候选人和对手的出现情况。这可以自动编码WMP变量,这些变量表明广告中是否提到或描绘了特定的政治家。检测反对候选人的存在尤其令人感兴趣,因为这通常是攻击性广告的指标。我们的人脸识别程序由几个步骤组成,如图3所示。首先,我们使用CNN检测每个摘要帧中的人脸,生成一组裁剪图像。其次,我们使用估计的标志性特征位置将人脸图像转换为标准尺寸和姿势,这些特征位置对应于人脸的不同特征,例如嘴角和眼睛、鼻尖或眉毛。第三,我们使用另一个CNN为每个检测到的人脸计算特征表示。最后,我们将这些特征用作预训练分类器的输入,以确定检测到的人脸的身份。我们现在描述检测人脸和计算特征表示的过程,将分类及其结果的讨论留到第4.3节。人脸检测和识别是使用Python包 face_recognition,执行的,该包提供了C++库dlib(King 2009)中人脸检测和识别算法的简单实现。该库使用CNN进行人脸检测,使用梯度提升回归树集合进行人脸对齐(Kazemi and Sullivan 2014),使用FaceNet算法进行特征计算(Schroff et al. 2015)。我们注意到,该算法与Xi等人(2020)中使用的算法相同。按照FaceNet论文中的建议,使用广告中检测到的面部特征与对应于候选人参考图像的预计算特征之间的欧几里得距离阈值进行分类。我们选择一对多方法进行分类,因为它实施起来简单。Schroff等人(2015年)和本文的验证结果都显示错误检测率较低,这表明该算法在分类设置中也能很好地区分面部。虽然还有许多其他人脸检测(参见Jin和Tan 2017)和人脸识别(参见Wang and Deng 2018)算法,但我们选择使用上述方法,因为它有高质量的开源实现和预训练模型。使用这些算法的face_recognition实现,对于每个视频摘要,我们会计算摘要中检测到的所有面部的面部嵌入,从而生成用于面部识别的面部特征集。我们注意到,与图像文本检测一样,面部检测和识别也会受到质量较差的摘要的负面影响。图3.人脸识别系统图。示例取自共和党候选人Ron DeSantis参加2012年佛罗里达州第六区众议院选举的竞选视频。首先,在源图像中检测人脸,生成一组裁剪图像。其次,将人脸居中、缩放和对齐,使眼睛处于同一水平。第三,将对齐的人脸输入卷积神经网络,该网络在特征变换步骤中计算检测到的人脸j的向量表示fj。最后,使用预训练分类器确定人脸身份。
3.2.音频特征
音频数据包含有关竞选广告内容的关键信息。典型的广告以叙述者(通常是候选人)为特色,讨论他们的政策立场并强调对手的问题。另一个突出的组成部分是音乐。几乎所有的竞选广告都使用音乐来设定广告的基调。例如,不祥和紧张的音乐通常被用作攻击对手的背景。下面,我们讨论从音频中提取转录本的方法以及计算捕捉音频整体基调的特征的方法。我们还讨论了如何从转录本计算文本特征。3.2.1语音转录。我们使用GCP视频智能API为数据集中的每个视频生成转录文本。虽然YouTube现在可以为所有上传的视频提供高质量的转录文本,但该系统还处于早期阶段,当时2012年和2014年的竞选广告在YouTube上发布。我们发现,与GCP视频智能API相比,YouTube的转录服务在此期间的表现令人失望。该语音转录算法将视频作为输入,并返回其对视频转录文本的估计。
GCP Video Intelligence API具有一项功能,允许用户提供预计会出现在视频中的短语,以帮助提高转录的准确性。这在我们的应用中非常有用,因为我们的目标之一是检测广告中提到的候选人或对手。由于姓名不是常用词,而且一些候选人姓名来自其他语言,因此ASR 系统很难准确识别它们。对于每个视频,我们都会提供主要政党候选人和领先的独立候选人的姓名。该姓名列表是从相应选举的维基百科页面上收集的,其中包含候选人在竞选周期中使用的姓名,而不是他们的出生名(例如,伯尼·桑德斯(Bernie Sanders)与伯纳德·桑德斯(Bernard Sa nders))。文献表明,这些ASR系统可以实现非常低的错误率(Prabhavalkar等人,2017年)。Pro ksch等人(2019年)分析了欧盟国情咨文辩论中的政治演讲,并表明使用GCP的自动生成的转录本进行词袋文本模型与使用人工注释的效果相当。我们还发现GCP的算法准确且适合我们的任务。最常见的错误是混淆发音相似的单词,但这些错误通常不会降低文本的实质含义。图4展示了使用视频智能API及其基本事实获得的转录本示例,说明了GCP转录的准确性。3.2.2文本特征。我们使用Google ASR算法生成的转录本执行几个视频分类任务,即问题提及(第4.1节)、对手提及(第4.2节)和广告否定性(第4.5节)。对于前两个任务,我们仅使用原始转录本采用基于关键字的方法,但对于广告否定性,我们构建文本特征并训练分类器。在本节中,我们描述了用于广告否定性分类的这些文本特征的计算过程。
我们使用词袋作为输入特征。我们之所以选择此功能而不是更高级的替代方案(例如句子嵌入),是因为计算机生成的文本不包含标点符号,这会严重降低任何基于语法的方法的性能。相反,我们专注于使用自然语言处理技术对文本进行预处理和过滤,生成一个简洁的词汇表来计算单词计数向量。我们使用Python包spacy来实现这一点。”具体来说,我们首先使用词性标注和命名实体识别对原始文本进行注释,将命名实体与文本的其余部分分开。这样,我们就可以对句子进行标记,而无需拆分应该放在一起的n-gram ,例如《社会保障》或《平价医疗法案》。在对文本进行注释后,我们会过滤掉那些与广告情绪无关的标记。具体来说,我们会删除与人物相对应的命名实体,但巴拉克·奥巴马、罗纳德·里根和南希·佩洛西除外,因为它们经常被用来强调支持或反对的候选人的意识形态。最后,过滤掉的与实体不对应的标记会通过词形还原器来恢复字典形式(即字典中找到的基本形式),以便将相似的单词压缩为单个标记。3.2.3音乐特征。除了文本之外,视频中使用的音乐类型也提供了有关给定广告的基调或目的的有用信息。因此,我们应用Ren的算法,Ming-Ju和Jang(2015)计算可用于对音乐类型进行分类的特征。我们根据该算法在音乐信息检索评估交换(MIREX)中的表现选择了该算法。MIREX是一个社区驱动的框架,用于对音频和音乐信息检索机器学习领域中各种问题的系统和算法进行科学评估(Downie 2008)。与2.2节中描述的频谱指纹识别方法一样,音乐特征基于音频信号的频谱图。我们首先从视频中获取音频信号。在计算频谱图的FFT步骤之前,每个帧都会经过预加重滤波器,该滤波器会增强高频分量。此操作有助于区分信号的高频分量与频谱中的噪声,后者的幅度往往比低频分量弱。预加重后,我们对帧进行加权,然后计算绝对值以生成频谱图。音乐特征由几种频谱图表征组成,目的是捕捉音频的不同感知品质,如音高、音色、速度或韵律。我们可以将这些特征分为短期特征或长期特征。短期特征用于测量音频信号的音色质量,并以频谱形状为特征。相反,长期特征表征比音色更长的时间尺度上出现的感知音频品质,如节奏和速度。结合短期和长期特征,我们得到一个452维特征向量,并将其用于音乐情绪分类和情绪分析。
四、结果验证
在本节中,我们展示了验证结果,评估了自动编码与人工编码的性能。
4.1 问题提及
WMP数据集中的一组关键变量指示电视广告是否提及或描绘了某些政治问题和相关人物。这些变量大致可分为三类。第一组变量指示是否逐字提及和/或描绘了10位著名人物,包括巴拉克·奥巴马、南希·佩洛西、米奇·麦康奈尔、民主党和共和党。第二组变量表示是否逐字提及12个政治色彩浓厚的单词或短语,例如茶党、变革、保守派、华尔街和大政府。最后一组变量指示是否讨论了
61个问题,包括税收、工作/就业、枪支管制、毒品和移民,即使它们没有逐字提及。
以枪支管制为例,仅仅寻找两个词短语“枪支管制”的确切提及可能不足以捕捉到所提及问题的情况,因为候选人经常通过不同的措辞或短语表达他们对此事的看法。例如,如果候选人谈到保护持有和携带武器的权利,或者批评国会与美国全国步枪协会(NRA)关系过于密切,他们在枪支管制问题上采取了两种相反的立场。这些情况应该反映在我们对相应变量的编码中。
与Proksch等人(2019)进行的分析类似,本节的目标是评估用于基本文本分析任务的自动转录本的质量,因此对于问题提及,我们选择使用一种简单的方法。具体来说,我们通过简单地检查每个视频中是否至少提到一个关键词来自动编码这些变量。虽然WMP代码本提供了问题标签(即问题、政治参与者的名称和短语),但它们并不总是构成有用的关键词。因此,我们选择一组相关的单词和短语作为关键词,并在某些情况下排除这些关键词在无关上下文中的使用(例如,华尔街日报不算作对华尔街的提及)。我们注意到,对于问题检测,我们不会对文本进行词干或词形还原,因为这样做会导致对相同关键词和短语的使用产生细微的区分。例如,词干化将使我们无法区分“他作为我们的州长做得不好”和“我们必须停止将我们的工作转移到海外”在使用“工作”一词时的情况。
给定关键词集,如果音频记录中至少提到一个关键词,或者从每个视频文件中提取的图像文本中出现该关键词,我们将问题提及变量编码为1(否则编码为0)。请注意,在分类中,我们排除了国会和华尔街的图像文本提及,以减少由于频繁出现脱离上下文的引用而导致的误报。我们还结合了面部识别算法来补充文本,以对巴拉克·奥巴马进行分类。
我们首先使用音频数据,检查了204,844(=2,468x83)个视频-问题对中WMP问题提及变量与我们对这些变量的自动编码之间的总体一致性水平。表2显示,在所有考虑的视频-问题对中,它们在98%以上是一致的。使用图像文本和人脸识别来补充音频记录,结果又得到了661个(总体为0.32%)个积极的发现。在这些样本中,WMP
将其中254个(38%)编码为是,其余407个(62%)编码为否。虽然总体一致率很高,但这在一定程度上是由于许多问题提及变量的值都为零:每个视频只提到了少数问题。
表2.华尔街日报与自动编码中问题提及变量的比较。每个单元格中的值对应于华尔街日报和自动编码方案的四种不同结果组合的比例。前两列显示我们仅使用音频记录自动检测关键词时的结果,后两列显示使用音频记录、图像文本和人脸识别时的结果。整体准确率为98.43%(左)和98.37%(右)。共有83期204,844个视频问题对。
更具参考价值的指标可能是假阳性率(FPR)和假阴性率(FNR)。如果我们假设WMP编码确实正确,那么FPR(即WMP编码为否的案例中自动编码为是的比例)小于1%,FNR(即WMP编码为是的案例中自动编码为否的比例)为24%。使用音频和视觉数据,FNR下降到
21%,FPR略有增加,但仍低于1%。FNR值相对较高,表明我们的方法在检测人类编码员可以检测到的问题提及方面存在困难。此错误可能是由于我们简单的基于关键字的方法,当问题提及出现在更微妙的上下文中时,该方法可能会遇到困难。我们发现误解的上下文是导致假阴性的主要原因,而WMP编码中的人为错误是导致假阳性的主要原因。我们还发现,在大多数不一致的情况下,机器编码是正确的。
但是,人和机器都可能对某些变量进行错误编码。我们使用Amazon Mechanical Turk 进一步验证自动和手动编码。为此,我们随机抽样500个视频-问题对,其中210对代表同意的情况,而其余290对代表不同意的情况,其中有176个假阳性(即自动编码给出“是”,而人工编码给出“否”)和114个假阴性(即自动编码给出“否”,而人工编码给出“是”)。每个问题-视频对都由五位不同的获得MTurk大师资格的个人审查。包含MTurkers看到的说明的示例脚本可以在补充材料附录S10中的图S10.5中找到。
图5显示了在四种不同一致条件下认可自动编码的MTurkers数量的条形图。当WMP和自动编码彼此一致时(两个对角线图),许多
MTurkers会做出相同的判断,从集中在4或5附近的数字可以看出。当WMP和自动编码彼此不一致时(非对角线图),我们发现MTurkers经常彼此不认可,并且更有可能认可自动编码。结果表明,在两种编码方案不一致的情况下,自动编码比WMP编码更准确。
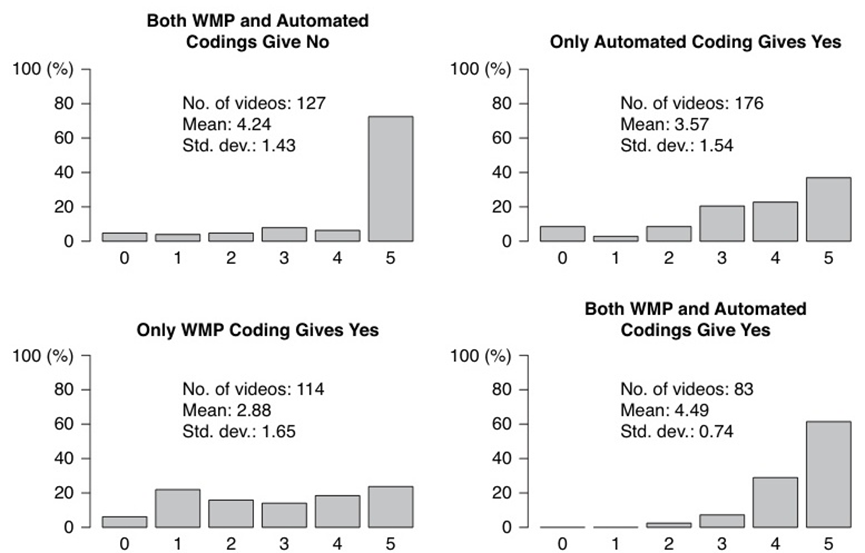
图5.同意自动编码提及问题的MTurkers数量。这四个案例基于WMP和自动编码之间的一致性和不一致性。每个任务的MTurkers总数(因此同意自动编码的MTurkers的最大数量)为5。每个图中的文本显示了每个样本中包含的问题-视频对的数量以及同意自动编码的MTurkers数量的平均值和标准差。
4.2 对手提及
WMP数据集还包含一个单独的变量,用于确定广告是否在广告主体部分(不包括口头批准部分)中提及对手。我们的自动编码算法与问题提及完全相同,只是使用的关键词是对手姓氏的三种不同形式:姓氏本身、所有格和不带撇号的所有格。例如,如果对手的名字是Jane Roe,那么我们使用“Roe”、“Roe's”和“
Roes”。我们包含不带撇号的所有格形式,是为了解释音频转录或图像文本检测算法将所有格误解为复数并因此错误地抑制撇号的情况。
表3显示,当音频记录和屏幕文本检测相结合时,自动编码与原始WMP编码的一致性超过96%。与问题提及变量的情况相比,我们发现正负情况之间的平衡更好。总共记录了88个(总体为4%)不一致的情况,其中四分之三属于假阳性情况。我们还发现,使用图像文本检测来补充音频记录可以提高编码算法的性能,导致真阳性情况增加了75个(总体为3%),假阳性情况增加了8个(总体为0.4%)。
最后,我们发现,WMP标记中的人为错误是导致假阳性的最常见原因,而自动转录中的错误是导致假阴性的主要原因。无论如何,我们的方法在大多数不一致的情况下都是正确的,这表明对手提及变量的自动编码性能超过了WMP人工编码。
表3.WMP和自动编码中对手提及变量的比较。每个单元格中的值对应于两种编码方案的四种不同结果组合的比例。前两列显示我们仅使用音频记录来检测关键词时的结果,其余两列显示同时使用音频记录和屏幕文本时的结果。总体准确率为93.67%(左)和96.41%(右)。在丢弃19个缺少WMP变量的视频后,总共考虑了2,449个视频。
4.3 人脸识别
我们进行人脸识别的目的是检测所青睐的候选人和对手是否出现在竞选广告中。不幸的是,WMP不会将这些变量编码到其数据集中,而是仅跟踪所青睐的候选人或对手何时出现在广告的主要部分,不包括与口头批准相对应的部分。对于对手的提及,WMP定义中的细微差别无关紧要,因为口头批准中很少出现提及和描述。然而,对于所青睐的候选人的提及,这给我们评估人脸识别算法的能力带来了问题,因为所青睐的候选人通常只出现在口头批准期间。为了解决这个问题,我们将所青睐的候选人变量与另一个WMP指示变量相结合,该变量编码所青睐的候选人是否在口头批准部分直接与观众交谈。请注意,即使候选人在批准消息中出现,如果他们没有直接向观众讲话,这个组合变量仍然被编码为否,因此它不能完全替代所青睐的候选人的出现。尽管如此,我们还是通过将人脸识别算法与支持候选人描述的组合变量和反对候选人描述的原始变量进行比较,来评估人脸识别算法正确检测支持候选人和反对候选人面孔的能力,无论他们出现在广告的哪个部分。
我们会自动检测2012年和2014年参议院选举中播出的广告中的候选人和对手的出场情况,其中至少有一个YouTube视频与WMP视频文件相匹配。我们首先通过抓取专门用于相应选举的维基百科页面收集了113位参议院候选人的图像。如果图片缺失、过期或由于质量低下,这些都由互联网上的手动搜索取代。图6展示了这些候选人的所有图像的蒙太奇。最后,我们应用了第3.1.3节中描述的人脸识别算法,当检测到的人脸编码与参考图之间的欧几里得距离低于某个阈值t时,即宣布匹配。我们通过监督学习选择了t。首先,我们构建训练数据,使用所有检测到的人脸编码与对方候选人的参考编码之间的最小距离作为特征,使用相应的WMP变量作为类标签。然后,我们对数据拟合线性支持向量机(SVM)并得到t=0.5139的值。

图6.2012年和2014年选举周期中113名参议院候选人的收集图像的蒙太奇图。候选人按字母顺序排列,从左上角的Todd Akin到右下角的Mark Zaccaria。
表4显示了WMP和自动编码对候选人外观变量的一致和不一致模式。对于支持的候选人,两种编码模式在约81%的情况下一致。在不一致的情况下,自动人脸识别在大多数样本中返回“是”。对于反对候选人,总体一致率更高,两者在约91%的情况下一致。大多数不一致对应于人脸识别算法返回“否”的情况。
表4.WMP与自动人脸识别中候选人外貌变量的比较。每个单元格中的值对应于WMP和自动编码方案的四种不同结果组合的比例。前两列为有利候选人的外貌,后两列为不利候选人的外貌。总体准确率为80.83%(左)和90.87%(右)。总样本量为767。
考虑到摘要过程中丢弃了许多帧,人脸识别算法的出色表现似乎令人惊讶。然而,候选人和对手在竞选广告中,人们通常会以中性姿势突出显示,以帮助观众识别,这使得人脸识别在此应用中成为一项相对容易的任务。图7中显示了导致假阴性的最常见问题的两个说明性示例。这些示例突显了人脸识别算法的缺点,当候选人的外观呈非标准姿势(左图)或图像中存在视觉噪声(右图)时,该算法会遇到困难。右图被错误分类的另一个假设是人脸识别系统存在偏见,事实证明,该系统在识别少数群体方面存在困难(例如,Grother等人,2019
年)。然而,在许多这些情况下,检测到的人脸编码和参考编码之间的最小距离接近阈值。

图7.说明候选外观变量自动编码错误的示例。
4.4 音乐情绪分类
许多政治竞选广告都有背景音乐。WMP数据集包含三个二进制变量,分别描述其情绪“不祥/紧张”、“振奋人心”和“悲伤/悲痛”。WMP对这三类音乐的编码并不相互排斥:在2,250个视频中,至少有一种类型的音乐,其中358个(16%)被编码人员选择了多个类别。这三个类别也相对不平衡:“振奋人心”的音乐编码最频繁,有1,586个视频(70%),其次是“不祥/紧张”音乐,有712个视频(32%),以及“悲伤/悲痛”音乐,有312个视频(14%)。
我们采用监督学习方法,通过平衡类权重和径向基函数训练SVM分类器。我们通过五重交叉验证网格搜索调整超参数,其中损失函数针对“不祥/紧张”和“振奋人心”分类器的准确性进行了优化,并平衡了“悲伤/悲痛”分类器的准确性。用于分类的音乐特征在第3.2.3节中进行了描述,并且每个类别的音乐编码都是独立完成的。
表5显示了原始WMP和自动编码之间的一致和不一致比例。总体而言,三种音乐的平均一致率相似:“不祥/紧张”音乐为74%,“振奋”音乐为76%,“悲伤/悲痛”音乐为74%。如上所述,每种音乐情绪的频率不同,在大多数采样视频中,两种编码方案都能检测到振奋的音乐,而“不祥/紧张”和“悲伤/悲痛”音乐的相应数字较低。在不一致的情况下,与WMP编码相比,分类器对“不祥/紧张”音乐返回“否”的可能性更大,而对“振奋”和“悲伤/悲痛”音乐返回“是”的可能性更大。
表5.WMP和自动编码的音乐情绪变量比较。每个单元格中的值对应于WMP和自动编码方案的四种不同结果组合的比例。三个二乘二矩阵对应于WMP数据中使用的三种不同音乐情绪。整体准确率分别为73.56%(左)、76.44%(中)和74.22%(右)。此处显示的结果来自大小为450的测试数据集。

与其他分类任务相比,此音乐情绪分类任务与原始WMP编码的一致率较低。这是因为音乐情绪分类是一项艰巨的任务,目前最先进的机器学习方法在基准MIREX数据集(Ren等人,2015年)中实现了约70%的分类准确率。另一个性能较低的可能原因是所使用的特征不适合情绪分类,这在Mehr
等人(2019)中有所观察到。然而,即使是通常分类准确率更高的人类编码员,也无法完全确定给定广告包含的音乐类型。WMP报告称,基于2012年选举周期的903个双编码样本,编码员对“不祥/紧张”、“令人振奋”和“悲伤/悲痛”类别的一致率分别为83.9%、88.8%和89.5%。2014年选举周期样本的相应数字分别为89.0%、89.8%和91.5%。
鉴于确定该变量的基本事实本身就很困难,我们使用Amazon Mechanical Turk作为另一个编码来源。我们为验证数据集中包含的450个视频中的每一个视频分配了五位具有硕士资格的不同MTurk编码员,并要求他们编码广告是否包含这三种类型的音乐中的任何一种。示例脚本以及MTurkers看到的说明可以在补充材料附录S10中的图S10.6中找到。图8显示了在“不祥/紧张”类别的四种一致模式下与自动编码一致的MTurkers数量分布。该图表明,当WMP和自动编码都返回相同结果时,MTurkers
更有可能同意,尽管在两种编码都给出“是”的情况下,响应分布更均匀。在两种编码彼此不一致的情况下,MTurkers更倾向于同意WMP编码,尤其是当只有WMP编码返回“否”时。这表明自动情绪分类器的性能可能达不到人类对音乐情绪分类的标准。
鉴于这项任务的难度,自动编码的表现不佳是意料之中的。当我们根据每种情况下的多数意见将MTurk编码员的响应汇总为二进制变量时,所有三个类别中与WMP编码的一致率约为86%,略低于WMP报告的编码员间一致率。这表明即使是人类编码员也可能无法完成这项任务。
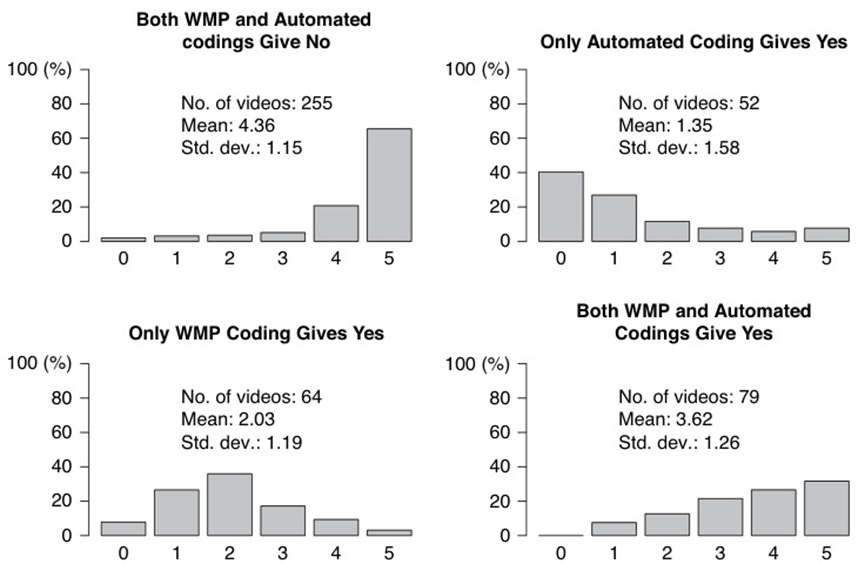
图8.同意不祥/紧张音乐自动编码的MTurkers数量。四种情况基于WMP和自动编码之间的一致性。每个任务的MTurkers总数为5。每个图中的文本显示每个样本中包含的视频数量以及同意自动编码的MTurkers数量的平均值和标准差。
4.5 广告消极性
作为最后的验证练习,我们使用预训练的分类器对竞选广告的负面性进行分类。或者,可以使用基于字典的方法对负面性进行分类,例如Lexicoder情感词典(Young and Soroka 2012),这种方法往往具有更好的泛化性能,可能更适合对本文研究范围之外的选举周期中的负面性进行分类。然而,我们使用Lexicoder情感词典(LSD
)的结果显示其性能明显低于监督学习,这表明我们的数据可能不太适合这种方法。
WMP数据包含两个与消极性相关的变量。一个变量将广告的语气分为“积极”、“消极”或“对比”。此变量由CMAG提供,因此并非由WMP直接编码。另一个变量由WMP 研究团队编码,将广告的目的分为“对比”、“推广”或“攻击”。在本文中,我们自动化了前一个变量,它更符合情绪分析的经典定义。为简单起见,我们删除了所有标记为“对比”的广告,因为它们将同时包含积极和消极内容。其余视频的标签为1(如果是积极的话),0(如果是消极的话)。
我们研究了五种不同的模型:朴素贝叶斯分类器、线性SVM、带径向基函数的非线性SV M、k近邻分类器(KNN)和随机森林。对于这些分类器的输入,我们使用三组特征:第3.2.2节中所述的文本特征、第3.2.3节中所述的音乐特征向量以及由文本和音乐特征连接而成的组合特征。在构建文本特征时,我们同时考虑了字数和tf-idf特征。
我们通过基于互信息标准的特征选择来控制过度拟合,并排除所有在数据中仅出现一次的术语。我们在一个由80%的WMP数据条目组成的随机样本上训练了五个模型,并将剩余的20%作为测试集。每个分类器的调整参数都通过五重交叉验证进行优化,方法是在密集的值网格上最大化准确率得分。对于依赖样本之间的距离度量进行分类的分类器(SVM和
KNN),我们在训练过程之前对特征进行了标准化。
表6显示了原始WMP与非线性SVM自动编码之间的一致性比例,在所使用的三个模型中,非线性SVM具有最高的整体一致性。线性SVM、KNN、随机森林和朴素贝叶斯分类器的结果见补充材料附录S14中的表S14.6。结果表明,文本特征对于将广告分为正面和负面广告是有效的,一致性率达到84%,在所有三个特征下,假阳性率都高于假阴性率。正如预期的那样,音乐特征的效果较差,只有75%的一致率。将文本特征与音乐特征相结合并不能显著提高单独使用文本特征的性能。我们推测这是因为我们使用的音乐特征不是专门为检测经常用于负面广告的暗黑音乐而设计的。未来的研究可能会考虑针对此任务的新功能。尽管如此,自动编码和人工编码之间相对较高的一致率表明机器编码可用于有效地对正面和负面广告进行分类。
表6.使用非线性SVM对WMP和自动编码之间的广告负面性变量进行比较。每个单元格中的值对应于WMP和自动编码方案的四种不同结果组合的比例。三个二乘二矩阵对应于用于训练模型的三种输入数据。总体准确率分别为84.12%(左)、74.88%(中)和84.12%(右)。此处显示的结果来自大小为422的测试数据集。











