4月3日,哈尔滨工业大学(深圳)路璐教授/在ACS ES&T Engineering发表了题为“Prediction of Waste Sludge Production in Municipal Wastewater Treatment Plants by Deep-Learning Algorithms with Antioverfitting Strategies”的研究论文,开发了多种深度学习算法(DLAs)用于污泥产量的时间序列预测。
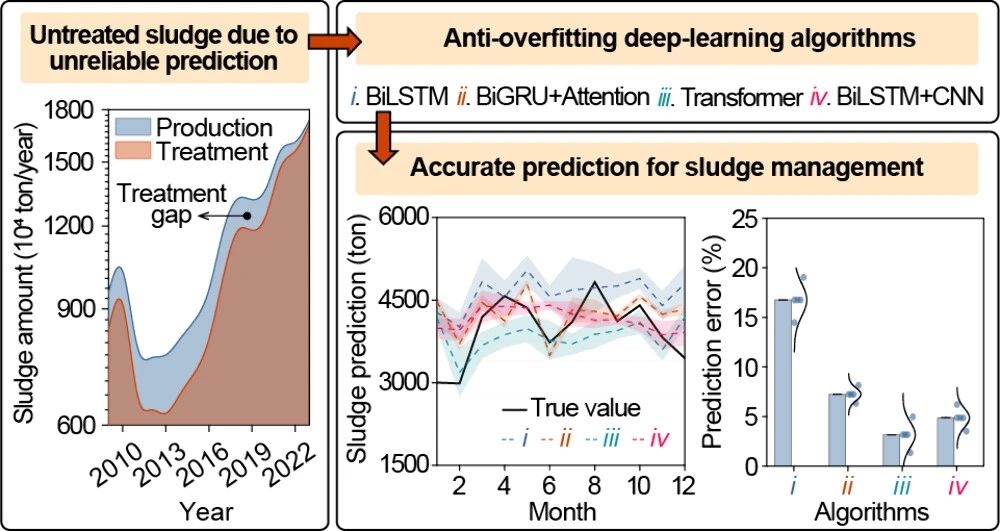
截至2023年,中国城市污水排放量达到约781亿立方米,每年产生约1740万吨城市污泥(含水率低于50%)。尽管处理能力有所提升,但仍有大量污泥未得到充分处理。部分原因在于对实际污泥产量的预测不准确,导致污水处理部门未能规划和优化设施能力、资源配置以及污泥完全处置的管理策略。此外,随着城市人口和工业密度的持续增长,污泥产量预计将进一步增加,这可能会扩大处理缺口。传统的统计方法(如回归分析)依赖历史数据建立污泥产量与污水处理参数(如流量、污染物浓度、温度、微生物活性)之间的关系。然而,这些模型往往无法捕捉污水处理过程中固有的复杂非线性动态。例如,无机杂质的引入和污水参数的意外波动会给生物处理过程带来显著的不确定性,导致污泥产量并不总是遵循活性污泥模型。这些挑战凸显了传统方法在处理污泥产量复杂性方面的局限性,强调了开发新型预测策略的必要性。
准确预测城市污水处理厂(WWTPs)的污泥产量对于匹配处理能力至关重要。然而,传统统计方法通常无法捕捉污水处理中固有的复杂关系,从而导致预测结果存在显著偏差。机器学习方法(MLMs)提高了预测精度,但面临大量手动数据标注、适应性有限和可解释性低的挑战。本研究开发了多种深度学习算法(DLAs),包括双向长短期记忆(BiLSTM)、带注意力的双向门控循环单元(BiGRU)、Transformer以及BiLSTM与卷积神经网络(CNN)的组合,用于通过自动标注北京某污水处理厂的数据集来预测污泥产量。这些具有更好可解释性的模型通过逐层神经元丢弃、批量归一化和岭正则化等抗过拟合技术进行优化,以增强对不同数据集的泛化能力。Transformer和BiLSTM + CNN模型表现出较高的预测精度,验证结果与实际数据之间的均方误差(MSE)为0.014–0.027,相关系数为0.53–0.72。当在广州两家污水处理厂(具有不同水质和处理规模)的数据集上进行测试时,这些DLAs的预测误差低至3.15 ± 1.81%至3.78 ± 1.75%,证实了其高适应性。相比之下,即使采用抗过拟合策略,包括随机森林、极限梯度提升和支持向量回归在内的MLMs预测误差高达30–65%,MSE为0.026–0.14,相关系数仅为0.25–0.48。Shapley加性解释分析表明,温度变化是影响污泥产量的关键因素。本研究凸显了DLAs在准确预测污泥产量方面的巨大潜力。
声明:本公众号仅用于分享前沿学术成果,无商业用途。如涉及侵权,请联系公众号后台删除!











