Python是数据挖掘的核心编程语言,但一般门槛较高,你得掌握pandas、numpy、sklearn、keras等复杂的数据处理和机器学习框架,才能写一些数据挖掘算法,因此让不少人望而却步。
最近尝试用了Python中一个支持拖拉拽的数据挖掘工具Orange,通过图形化工作流的形式来处理分析数据,类似最近流行的coze工作流。
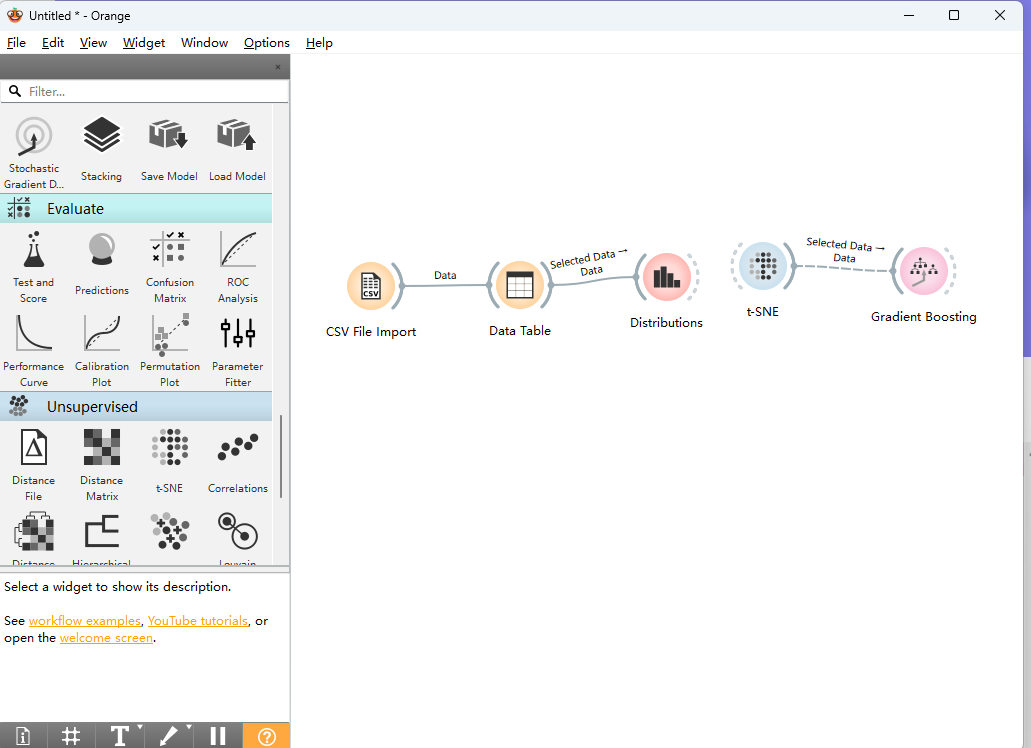
Orange是一个开源的数据挖掘和机器学习工具,能免费用。
它可以构建数据算法,还可以处理数据,生成可视化图表,而且支持运行Python脚本,且以直观的用户界面和强大的数据分析功能而名声大噪。
这个数据工具有丰富的组件可以使用,像数据IO、数据转换、数据可视化、机器学习算法、模型评估等,不需要额外写代码,拿来即用,参数也是可视化调整。
比如只需要简单的拖拽处理便可以对数据进行聚类处理,并且生成可视化图表。
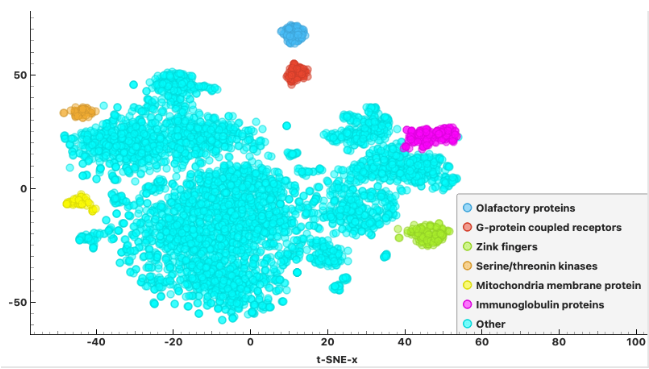
Orange因为是图形化界面,所以入门简单,不仅适合数据分析的新手,其实也适用于有经验的大佬。
Orange核心功能有以下几个:
• 数据导入导出:支持各种格式数据导入导出、连接数据库、数据预览、数据基础信息展示等。
• 数据预处理:支持数据转化、分组、拼接、过滤、排序、创建新变量、离散化等各种预处理。

• 数据可视化:支持主要的图表如散点图、折线图、箱线图、直方图等多种数据可视化图表。
• 机器学习:支持主流的的无监督和监督学习算法,如聚类、分类、回归等。

• 特征选择和评估:支持特征选择和模型评估,以优化模型性能。

在orange中运行Python脚本,有专门组件可以使用。
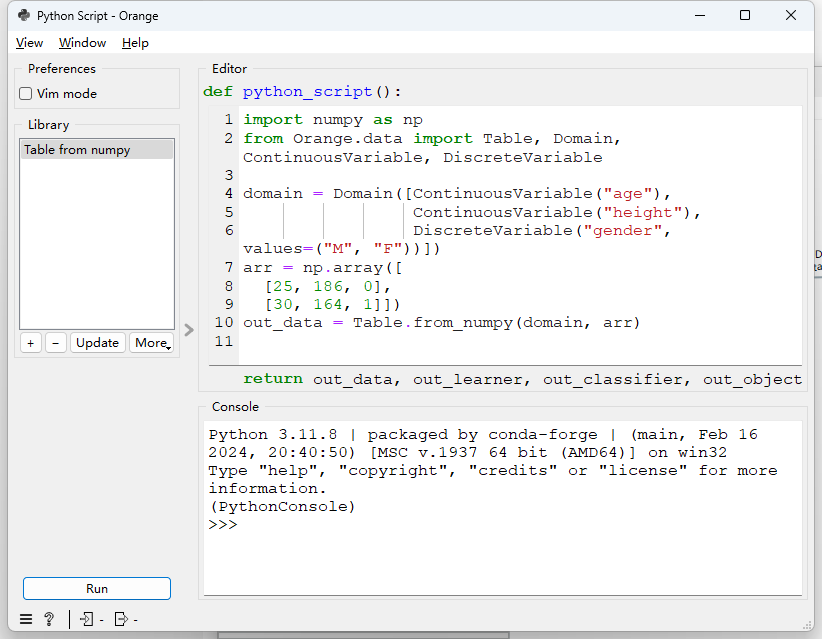
Orange安装使用方法主要有两种,一种是直接下载exe软件,安装到本地使用。
公众号后台回复:挖掘,可以直接获取安装软件。

另一种是在Python中使用pip安装,然后在命令行打开使用,下面详细讲下。
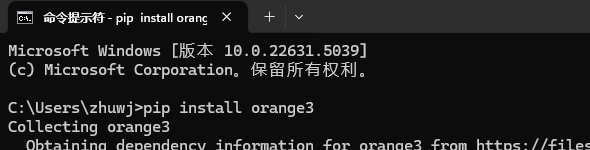
启动Orange:安装完成后,通过命令行输入orange-canvas启动Orange的图形界面。
数据加载:打开Orange后,拖拽“File”组件到工作区,加载数据集,支持多种数据格式,建议csv。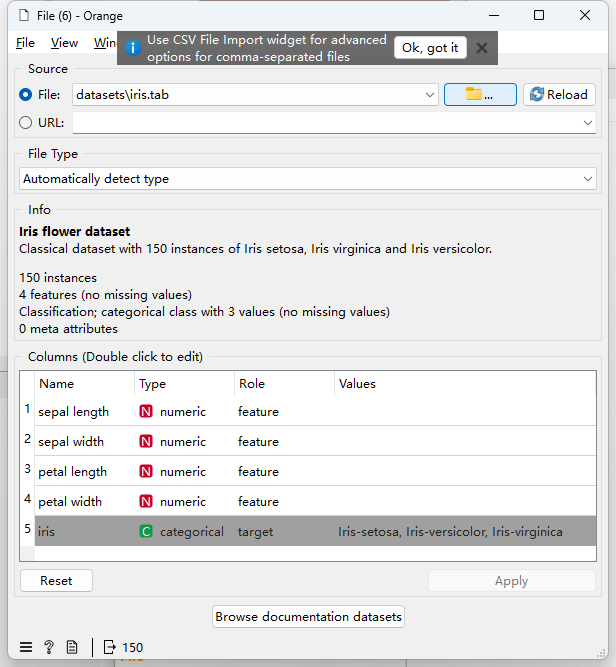
数据预处理:使用相应的预处理组件对数据进行清洗和准备,比如数据列筛选。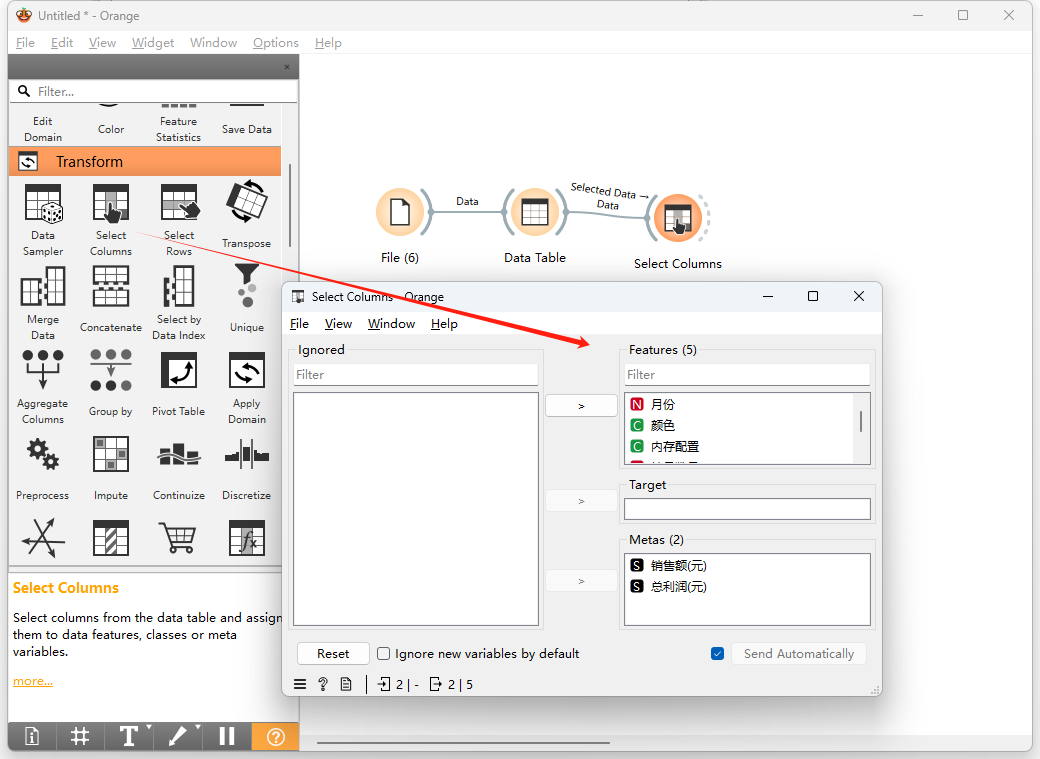
构建模型:选择合适的机器学习算法组件,如决策树、SVM等,构建模型。
模型评估:接下来评估组件,如交叉验证、混淆矩阵等,评估模型性能。
结果可视化:根据需求绘制图表,如散点图、折线图等,这样可以展示分析结果。
总的来说,Orange比较适合编程新手,或者想节省时间的分析人员,它适用于数据挖掘、数据分析、统计分析、机器学习等多个领域,如果使用熟练,一点不亚于Python编程。
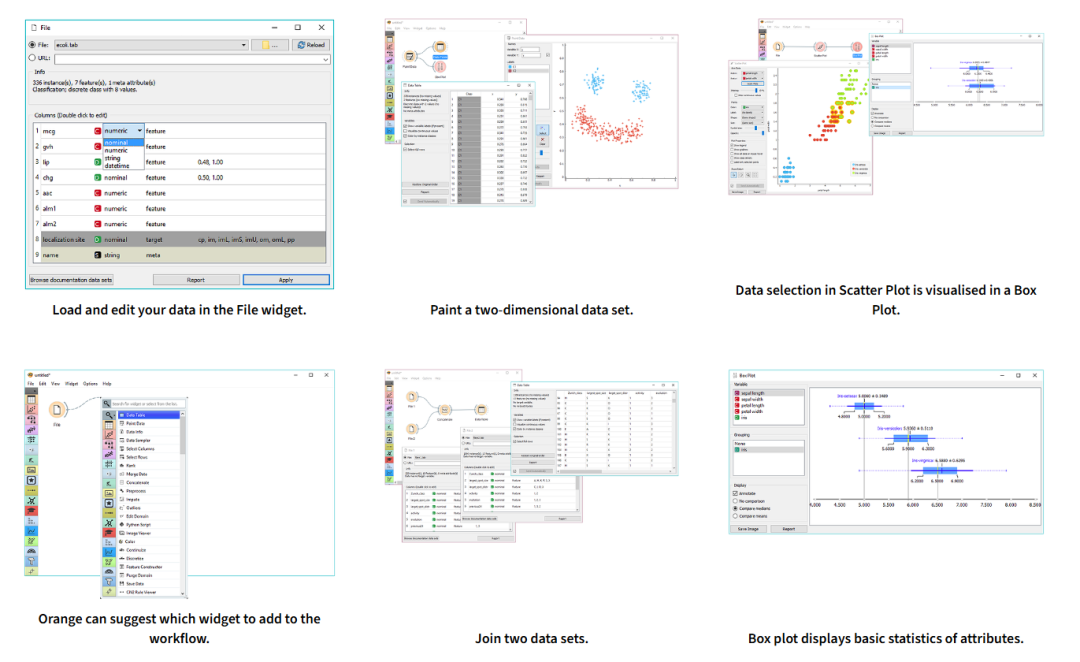
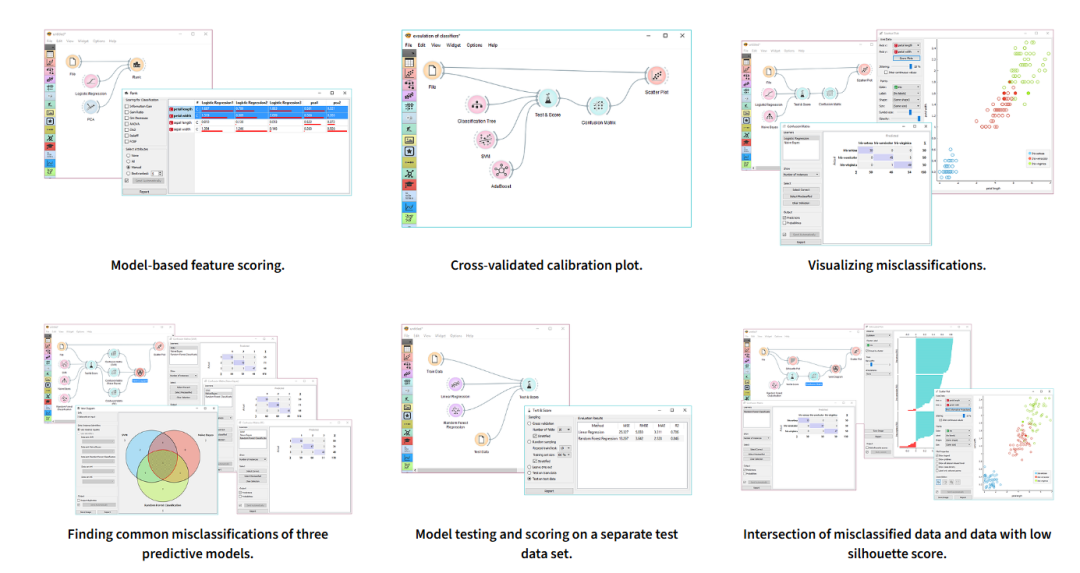
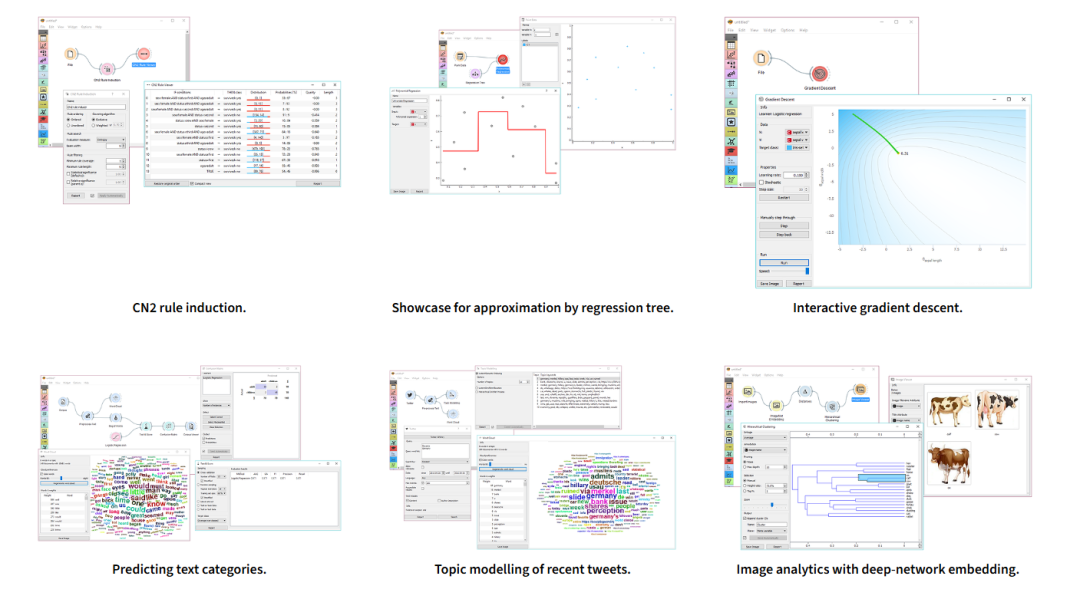
最后,公众号后台回复:挖掘,可以直接获取Orange安装软件。以下是Orange一些算法和可视化使用示例,供参考:


【我们谈论数据科学】知识星球上新啦!
长按识别下方二维码
即刻加入我们的Python知识圈子
涵盖Python、数据分析、AI大模型等十几门课程
以及专业老师VIP群指导
· 推荐阅读 ·
DeepSeek使用全教程,90%的人不知道的20个高效提示技巧
超详细!使用离线DeepSeek R1 + AnythingLLM搭建本地私有知识库
干货!VsCode接入DeepSeek实现AI编程的5种主流插件详解










