版权声明
转自kaggle竞赛宝典,版权属于原作者,仅用于学术分享https://arxiv.org/pdf/2412.00800
A Comprehensive Guide to Explainable AI: From
Classical Models to LLMs
unsetAI需要可解释性unsetunset
人工智能的崛起,尤其是深度学习的发展,在众多领域带来了令人瞩目的进步。然而,伴随这些进步而来的是一个关键问题——“黑箱”问题。许多人工智能模型,特别是复杂的模型,如神经网络和大型语言模型(LLMs),常被视为“黑箱”,因为它们的决策过程是不透明的。
这些模型可能以高精度预测结果,但其决策背后的逻辑却难以捉摸。这种缺乏可解释性的情况引发了诸多重大问题:
- 信任与责任:如果一个AI模型做出改变人生的决策,比如诊断医疗状况或批准贷款,用户需要理解背后的逻辑。没有这种理解,用户就无法信任或验证结果。
- 调试与改进模型:开发者需要深入了解决策过程,以便诊断错误或提升模型性能。如果无法解释模型,寻找错误根源就只能靠猜测。
-
监管合规:在金融和医疗等领域,监管机构要求AI决策必须可解释。例如,欧盟的《通用数据保护条例》(GDPR)中就包含了“解释权”,要求组织为自动化决策提供清晰的理由。
可解释性与模型复杂度之间的权衡
在人工智能中,可解释性与模型复杂度之间常常存在权衡。像决策树和线性回归这样的模型天生具有可解释性,但往往缺乏捕捉数据中复杂模式的灵活性。而深度学习模型和LLMs虽然具有卓越的预测能力,但解释起来却非常困难。
来看一些例子:
- 线性回归:这是一种简单且可解释的模型,其系数直接表明特征与目标变量之间的关系。然而,在复杂非线性数据集上,它的表现可能不尽如人意。
- 神经网络:这些模型能够近似复杂函数,并在图像识别和自然语言处理等任务中展现出最先进的性能。但理解每个神经元或层在决策过程中的作用却极具挑战性。
可解释性的不同层次与类型
可解释性不应与可视化混淆。可视化是一种技术手段,例如绘制特征重要性图或激活图,这些可以帮助我们理解模型,但它们本身并不是解释。
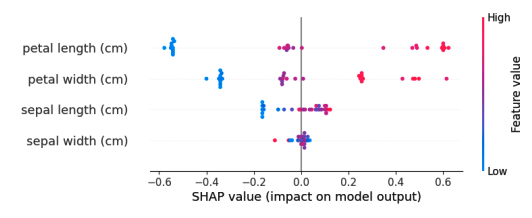
特征重要性图确实为我们提供了关于每个特征相对重要性的宝贵见解。然而,它并没有完全解释模型为何对某个特定样本做出这样的决策。
白盒模型 vs 黑盒模型
白盒模型包括以下几种:
- 线性回归:通过系数直接反映特征与目标变量之间的线性关系。
- 决策树:通过树状结构展示决策路径,易于理解和解释。
-
基于规则的系统:通过预定义的规则进行决策,规则透明且易于理解。
- K-最近邻(KNN):通过查找最近的训练样本进行预测,决策过程直观。
- 朴素贝叶斯分类器:基于贝叶斯定理和特征的独立性假设进行分类,模型简单且易于解释。
- 广义相加模型(GAMs):通过加性函数捕捉特征与目标变量之间的关系,支持对每个特征的独立解释。
黑盒模型包括以下几种:
- 神经网络(例如,深度学习模型):由于其复杂的结构和大量的参数,难以直接解释。
- 支持向量机(SVMs):虽然线性核的SVM具有一定的可解释性,但非线性核的SVM通常被视为黑盒模型。
- 集成方法(例如,随机森林、梯度提升机):虽然基于决策树,但其集成结构增加了复杂性,难以直接解释。
- Transformer模型(例如,BERT、GPT):由于其复杂的自注意力机制和大量的参数,难以直接解释。
- 图神经网络(GNNs):通过图结构处理数据,内部工作机制复杂,难以直接解释。
unsetunset传统机器学习的可解释性unsetunset
可解释模型与不可解释模型的区别
当我们讨论机器学习中的可解释性时,我们指的是能够清晰地理解和追溯模型是如何得出其预测结果的能力。可解释的模型是指人类观察者可以跟随决策过程,并直接将输入特征与输出预测联系起来的模型。相比之下,不可解释的模型,通常被称为“黑箱”模型,由于其结构复杂,很难理解其预测背后的逻辑。
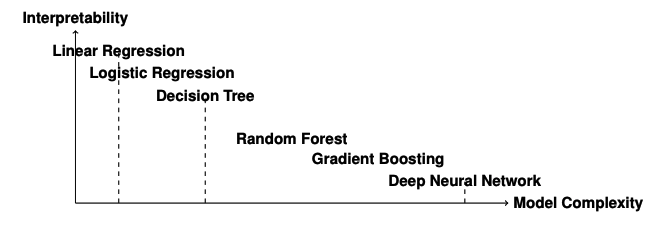
一个常见的区分方法是:
- 可解释模型:决策树和线性模型被认为是可解释的。它们的结构设计使得每一个决策或系数都可以被解释,并追溯回输入特征。
- 不可解释模型:神经网络和集成方法(例如随机森林和梯度提升)通常是不可解释的。由于它们的复杂性,包含众多的层、节点和参数,很难追溯单个预测。
决策树
决策树在机器学习中被广泛认为是最具可解释性的模型之一。它们具有简单直观的流程图结构,其中内部节点代表基于特征值的决策规则,分支表示这些决策的结果,而叶节点则包含最终预测。从根节点到叶节点的路径提供了一个清晰且易于理解的决策过程。
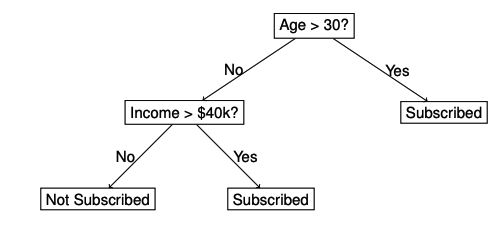
决策树通过输入特征的值将数据划分为子集,目标是减少不确定性或“不纯度”。常见的节点分裂标准包括:
这种结构突显了为什么决策树被认为是可解释的:每个决策都可以用输入特征来解释,从而便于为模型的预测提供依据。
尽管决策树本身具有可解释性,但它们很容易生长得过深,变得过于复杂,从而捕捉数据中的噪声并导致过拟合。为了应对这一问题,我们采用剪枝技术,通过移除那些对预测能力贡献微乎其微的节点来简化树。
主要的剪枝策略有两种:
- 预剪枝(Pre-pruning,早期停止):根据预定义的标准(如最大深度或每个叶节点的最小样本数)限制树的生长。这降低了过拟合的风险,同时保持了树结构的简单性。
- 后剪枝(Post-pruning):首先让树生长到最大深度,然后剪掉那些对模型性能提升不显著的节点。这种方法通常能够得到一个更平衡的模型,具有更强的泛化能力。
决策树中的特征重要性是通过评估每个特征在分裂过程中减少节点不纯度的作用来确定的。不纯度是衡量节点内无序或随机性的指标,通常使用基尼不纯度或熵来评估。当一个特征显著减少不纯度时,它会获得更高的重要性分数。
本质上,一个特征在树分裂中减少不纯度的贡献越大,它就越重要。高特征重要性表明模型在做预测时高度依赖该特征,使其成为理解模型决策过程的关键因素。
线性模型
线性模型,包括线性回归和逻辑回归,是机器学习中最具可解释性的模型之一。它们假设输入特征与输出之间存在线性关系,这使得理解每个特征对预测结果的影响变得非常直观。尽管线性模型结构简单,但在数据关系近似线性的情况下,它们依然非常强大。在对可解释性要求极高的领域,如金融和医疗保健,线性模型通常是首选。
- 线性假设:线性回归假设特征与目标之间存在线性关系。这一假设在复杂数据集中可能不成立。
- 对异常值敏感:异常值可能会严重影响拟合线,导致预测结果不佳。
- 多重共线性:当特征之间高度相关时,很难确定每个特征对输出的独立影响。
支持向量机(SVM)
支持向量机(SVM)因其鲁棒性以及能够处理线性和非线性可分数据而备受推崇。尽管通常被视为“黑箱”模型,但使用线性核的SVM可以通过其决策边界和支持向量提供一定程度的可解释性。
SVM的目标是找到一个超平面,能够最好地将数据划分为不同的类别。最优超平面会最大化边界(即超平面与每个类别最近数据点之间的距离)。这些最近的数据点被称为支持向量,它们是SVM决策过程的核心。
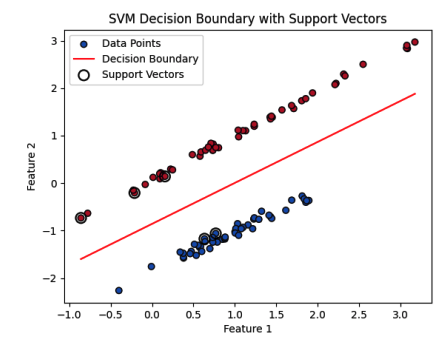
- 决策边界:红线表示将两个类别分开的超平面。这条线由权重向量 w 和偏置项 b 决定。决策边界将特征空间划分为两个区域,每个区域对应一个类别标签(蓝色和红色点)。
- 支持向量:支持向量用较大的空心圆突出显示。这些是离决策边界最近的数据点,位于边界边界上。它们在定义边界和超平面的方向上起着关键作用。如图所示,来自两个类别的几个支持向量正好位于边界上。
- 边界:边界是穿过支持向量的两条平行线之间的区域。SVM算法的目标是最大化这个边界,这提高了模型的泛化能力。较大的边界表示一个更鲁棒的分类器,对数据的小变化不那么敏感。
unsetunset
深度学习模型的可解释性unsetunset
深度学习模型,如卷积神经网络(CNNs)和循环神经网络(RNNs),包含多层神经元、非线性激活函数以及大量的参数。例如,一个简单的用于图像分类的CNN可能已经包含数百万个参数。随着网络深度和复杂性的增加,理解每个单独参数的贡献变得不可行。
在深度学习中,高维数据通过层进行处理,这些层可能会减少或增加维度,使得直接将输入特征映射到学习的表示变得困难。这种抽象阻碍了我们直接解释学习到的特征。
卷积神经网络(CNNs)的可解释性
CNNs通过一系列卷积层和池化层从输入图像中提取特征。早期层通常捕获简单的模式,如边缘和纹理,而深层则学习更抽象、高级的表示,例如物体部件。解释CNNs最直观的方法之一是通过可视化这些学习到的特征。特征可视化涉及检查卷积滤波器生成的特征图,使我们能够了解输入图像的哪些部分激活了特定的滤波器。

特征图提供了一个视觉上的窥视,让我们能够了解模型在不同网络阶段如何感知输入图像。虽然这种类型的可视化有助于理解网络的早期层,但由于学习到的特征的复杂性和抽象性,解释深层的特征图变得越来越具有挑战性。
- 缺乏直接可解释性:并非所有特征图都对应于人类可识别的模式。许多滤波器可能检测到难以视觉解释的抽象特征。
- 依赖输入数据:可视化的特征高度依赖于输入图像。不同的图像可能会激活不同的滤波器,这使得很难将解释推广到各种输入。
循环神经网络(RNNs)的可解释性
RNN的核心能力在于其隐藏状态,这些状态随每个时间步长演变。隐藏状态作为记忆单元,存储序列中以前输入的信息。然而,解释隐藏状态中编码的信息是具有挑战性的,因为它们代表了过去输入的复杂非线性组合。
为了深入了解隐藏状态,一种常见的方法是可视化它们随时间的变化。例如,绘制不同时间步长的隐藏状态激活可以揭示模式,例如对输入序列某些部分的注意力增加或敏感性增强。
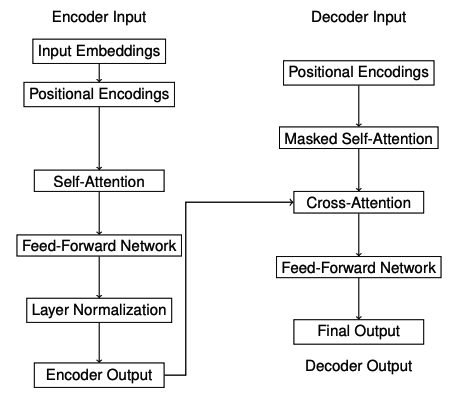
自注意力机制与Transformer模型的可解释性
自注意力机制允许模型根据每个输入标记相对于其他所有标记的重要性进行加权。该机制涉及的关键组件是查询(query)、键(key)和值(value)向量,这些向量是为每个标记计算的。
- is the dimension of the key vectors.
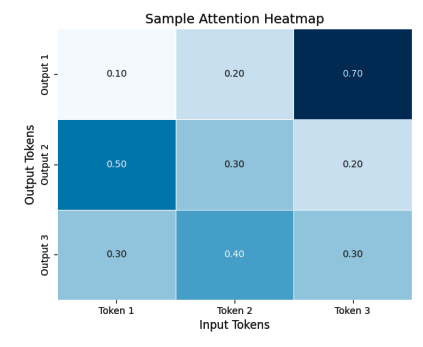
在这个例子中,热力图可视化了一个小的注意力权重矩阵,其中每个单元格代表输入标记和输出标记之间的注意力分数。每个单元格的颜色强度表示注意力分数的强度,便于识别对输出标记最有影响力的输入标记。
unset
unset大型语言模型(LLMs)的可解释性unsetunset
大型语言模型(LLMs)是一类变革性的深度学习模型,旨在理解和生成人类语言。这些模型利用大量的训练数据和Transformer架构,彻底改变了自然语言处理(NLP),在文本分类、翻译、摘要、对话系统甚至代码生成等广泛任务中达到了最先进的性能。
嵌入分析和探测
LLMs中的嵌入是高维表示,编码了关于单词、短语和句子的丰富语义信息。嵌入分析帮助我们理解模型学到了哪些语言属性以及这些属性在嵌入空间中的组织方式。
降维技术如t-SNE(t分布随机邻域嵌入)和PCA(主成分分析)常用于可视化嵌入。通过将嵌入投影到二维或三维空间,我们可以观察到揭示单词之间语义关系的聚类模式。
神经逐层可解释性
神经逐层可解释性专注于理解Transformer架构中各个层的作用。在像BERT这样的大型语言模型(LLMs)中,每一层都捕捉了不同层次的语言信息,共同构成了模型对输入文本的整体理解。
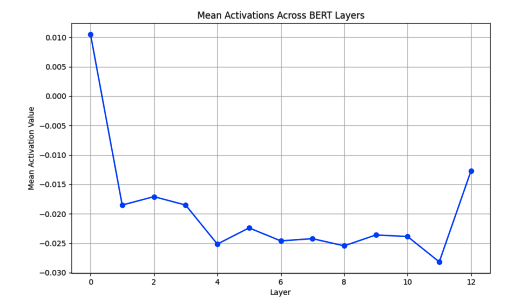
- 早期层:这些层倾向于捕捉表面级特征,如标记身份和基本的句法模式。模型在这个阶段专注于理解单个单词及其基本关系。
- 中间层:中间层负责捕捉更抽象的句法结构和依赖关系,如主谓一致和语法关系。这些层帮助模型理解句子结构。
- 晚期层:这些层编码高级语义信息和特定于任务的表示。它们直接贡献于最终预测,通常包含输入文本中最抽象和上下文感知的特征。
探测嵌入中的知识
-
句法探测:评估模型对句法属性的理解。例如,它检查嵌入是否能够区分句子中的主语和宾语,捕捉单词的句法角色。
- 语义探测:检查模型是否捕捉了语义关系,如单词相似性或蕴含关系。它旨在了解嵌入是否反映了更深层次的语义特征,如同义词或反义词。










