作者:田小幺
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
美国佛罗里达大学和田纳西大学的研究人员,通过深度学习模型 BETE-NET,成功预测了金属的电声相互作用 Eliashberg 谱函数 α²F(ω),并将搜索高 Tc 超导体的效率提高了 5 倍。
在科幻电影「阿凡达」中的潘多拉星球,那座被绿色藤蔓缠绕、悬浮于云端的哈利路亚山,无疑给观众留下了深刻的印象。其悬浮的奥秘,就在于山间蕴藏的室温超导矿石「Unobtanium」。电影中,人类为了抢夺这种地球上不存在的至宝,不惜摧毁纳美人的家园。虽然这只是一个虚构的故事,但现实中,物理学家们对超导材料的渴望与追求,却丝毫不亚于电影中的人类对「Unobtanium」的执着。因为从理论上来讲,超导材料能够提供永不枯竭的能量供应。
研究人员对超导材料的研究在 2023 年达到了一个小高潮。当时,韩国团队宣称发现了室温超导材料 LK-99,一时间引起了全球的广泛关注,甚至被一些人视为继 ChatGPT 之后的又一重大技术突破。尽管最终这一发现被证实是一场乌龙,但它却让超导材料的热度再次飙升,也让人们看到了这一领域巨大的潜力。
而随着 AI for Science 的兴起,人们开始大胆设想:能否借助 AI 技术来发现室温超导材料?从理论上讲,这是完全可行的,虽然仍存在挑战,但已经有一些研究团队在这方面迈出了重要的一步。例如,美国佛罗里达大学和田纳西大学的研究人员,通过深度学习模型 BETE-NET,成功预测了金属的电声相互作用 Eliashberg 谱函数 α²F(ω),并将搜索高 Tc 超导体的效率提高了 5 倍。这一成果不仅为超导材料的发现提供了新的思路和方法,也为 AI 技术在材料科学领域的应用树立了典范。
相关成果以「Accelerating superconductor discovery through tempered deep learning of the electron-phonon spectral function」为题,发表于学术期刊 npj Computational Materials。

论文地址:
https://www.nature.com/articles/s41524-024-01475-4关注公众号,后台回复「BETE-NET」获取完整 PDF
数据集下载地址:
https://go.hyper.ai/GjZDo
开源项目「awesome-ai4s」汇集了 200 余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
超导材料的困境:训练数据集和机器学习技术的「两难抉择」
人工智能模型对超导体的有效性,通常取决于两个关键因素:训练数据集和机器学习技术的选择。只有解决了这两个关键要素,才能更好地推动超导材料的研究和发展,为未来的科技创新奠定坚实基础。然而,这两大方向均面临着诸多困难。
首先,能够快速准确估算金属超导性质的模型,通常需要从材料信息学数据库中获取数万个数据点。然而,与其他数据库不同,要开发相应的大规模 α²F(ω) 数据集却难上加难。这不仅是因为其成本过高,还因为缺乏一套标准化的密度泛函理论参数(例如 k 点和 q 点密度、平滑值等),来准确计算 α²F(ω)。鉴于这些障碍,科学家更需要一套能够有效处理小数据集的机器学习技术,以突破当前的困境,推动超导性质估算模型的发展。
其次,在超导性研究领域,研究人员在使用此类模型时经常面临一个重大挑战:可用的数据集通常是不均匀的,并且数量有限。长期以来,超导材料的研究主要依赖于包含实验 Tc 值的知名「SuperCon」数据库来解决超导性质有限数据这一难题。然而,该数据库存在诸多问题,如充斥着重复条目、值得商榷的数值以及不明确的化学式等。这种大型、全面数据集匮乏的现象,不仅大大限制了新型超导材料的开发,还严重阻碍了超导材料在能源传输、交通领域的磁悬浮以及医学成像中强大超导磁体等方面具有的变革潜力。
尽管已经出现了一批材料结构和计算 α²F(ω) 的数据库,如格拉茨理工大学理论与计算物理研究所提出的仅包含高压氢化物的 Superhydra 数据库,德国哈雷物理研究所推出的专注于赫斯勒超导体的数据库,葡萄牙科英布拉大学物理系研究人员基于 7,000 次电子-声子计算训练的模型,以及美国国家标准与技术研究所开发的包含 626 种动态稳定材料及其相关 α²F(ω) 的数据库,但这些数据库在预测 α²F(ω) 时的表现依然欠佳。
为了更好地解决这些问题,佛罗里达大学和田纳西大学的研究人员在本研究中通过创建一个全面的 Eliashberg 谱函数数据集,并利用现代深度学习技术开发稳健模型,成功解决了这两个关键要素,为超导材料的研究和发展开辟了新的道路。这一成果不仅为超导材料的研究提供了新的方法和工具,也为未来的科技创新和应用奠定了坚实的基础。
BETE-NET:可在数据有限的情况下,显著拓展计算探索的边界
在计算电子-声子耦合时,需要确保用于计算 Kohn-Sham 波函数的 k 点网格与用于计算声子的 q 点网格相匹配。为了解决数据集的问题,该研究首先提出了一种标准化选择 k 和 q 网格的算法,可基于用户提供的 k 和 q 点密度生成网格,而不是使用固定网格来处理不同单位晶胞体积的材料。通过这种方法,研究人员不仅提高了数据的均匀性和质量,还确保了数据集的广泛适用性,最终生成了一个包含 818 种动态稳定材料的高质量电子-声子计算的全面数据库。紧接着,研究人员将 818 种动态稳定材料按照 80%-20% 的比例划分为训练集和测试集。
数据集下载地址:
https://go.hyper.ai/GjZDo
在评估了数据集的质量之后,为了应对数据库规模有限这一深度学习问题,研究人员进一步设计了 BETE-NET。如下图所示,BETE-NET 模型通过将晶体结构转换为图,并结合原子序数、原子质量、原子间距离以及位点投影的 PhDOS 信息,通过一系列卷积 (Convolution) 和门控块 (Gated-block) 操作,最终通过池化操作 (Pooling) 生成 α²F(ω) 的预测。通过引入 PhDOS 信息,模型的预测性能得到了显著提升。这种设计不仅充分利用了晶体结构的信息,还结合了材料的振动特性,使得模型在预测超导材料的 α²F(ω)时更加准确和可靠。最终,该研究训练了 3 个变体:
* CSO(仅晶体结构)变体:模型的基础网络,仅使用晶体结构信息进行预测。
* CPD(粗 PhDOS)变体:模型引入了位点投影的声子态密度 (PhDOS) 信息,进一步提高了模型的预测性能。
* FPD(细 PhDOS)变体:使用了更精细的 q 网格计算 PhDOS,进一步提高了模型对材料振动特性的捕捉能力。
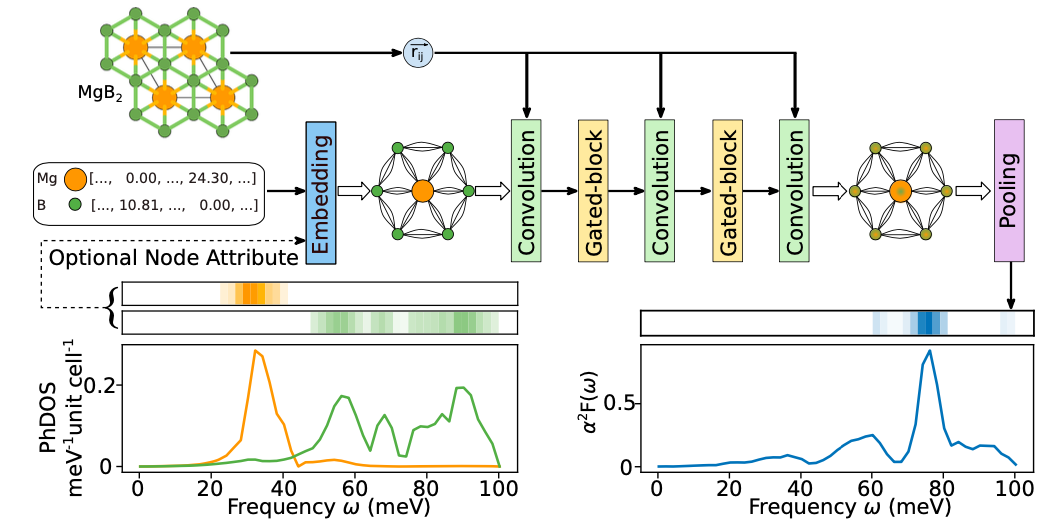
BETE-NET 架构
在有限数据的情况下,模型容易快速过拟合。尽管传统机器学习认为过拟合对模型的泛化能力有害,但许多深度学习模型在训练到近乎零损失时,仍能保持良好的泛化误差。这种现象被称为「双重下降」,可以视为一种受控的过拟合。如下图所示,双重下降现象包含 3 个阶段:经典阶段 (Classical Rigime)、临界阶段 (Critical Regime) 和现代阶段 (Modern Regime),并且每个阶段的损失景观图在插图中进行了展示。通过绘制这些损失景观图,研究人员提出了一种合理的方法来直观地解释神经网络的偏差和方差,从而为双重下降现象提供了定性解释。
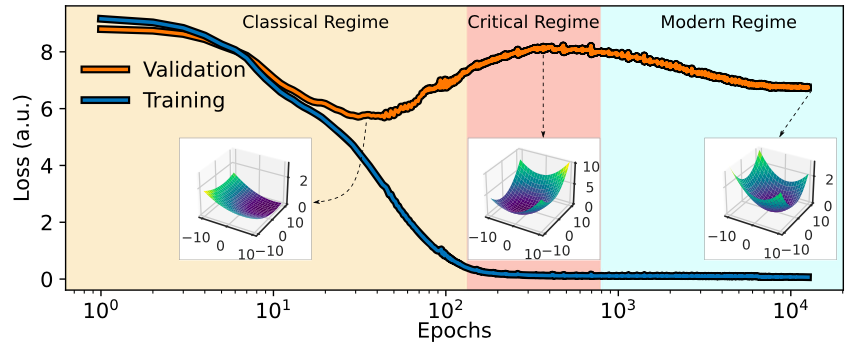
双重下降现象的 3 个阶段
该研究进一步在筛选高 Tc 材料方面得到了验证。首先,研究将所有 Tc^DFT≥5K 的材料定义为高 T 材料,最终有 33 种材料符合这一标准。接着,研究绘制了每个模型的精确召回率曲线。结果表明,CPD 和 FPD 模型获得的平均精度 (AP) 几乎是随机分类器的 5 倍。这表明,这些模型在识别高 Tc 材料方面表现出色,显著优于随机分类器,从而验证了模型在实际应用中的有效性和可靠性。
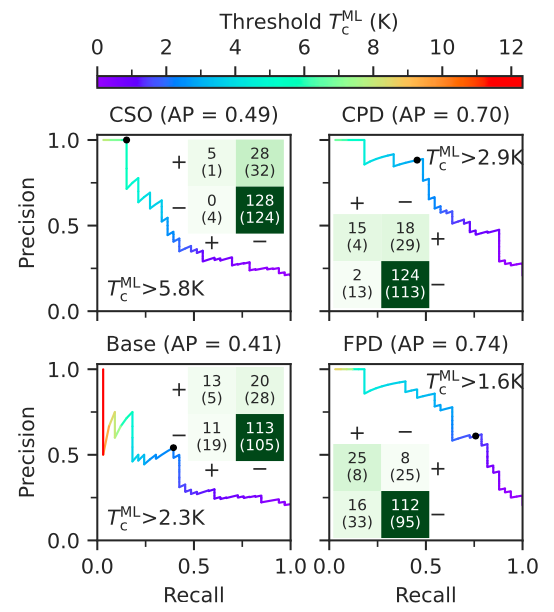
高 Tc 材料的筛选
综上所述,BETE-NET 模型堪称特定领域知识与先进深度学习技术完美融合的典范,它能够在数据有限的情况下,高效预测金属的电声相互作用 Eliashberg 谱函数 α²F(ω),不仅显著拓展了计算探索的边界,更有望通过助力新型超导体的发现,带来具有变革性的社会影响。
等变神经网络:助力材料界的 AlphaFold 诞生
有趣的是,就在本研究发布后不久,1 月 17 日,微软 CEO 纳德拉亲自站台,宣布旗下 MatterGen 模型登上 Nature 杂志。这一模型能够超越目前已知材料,利用 AI 发现针对特定需求的新材料。这标志着材料设计领域迎来了新的范式:从传统的数据库筛选,转变为根据需求提示直接生成新材料。有网友惊呼:「材料界的 AlphaFold 来了」。
值得注意的是,MatterGen 模型的关键在于其独特的扩散模型架构。在这一扩散过程中,MatterGen 模型采用的是等变分数网络,这也是本研究在学习 α²F(ω) 时所选用的模型,主要负责从扩散过程中恢复出原始的晶体结构,即去噪过程。
等变神经网络在传统神经网络的基础上,加入了等变性的约束要求。网络中的每一种操作都要求是等变的,因此整个网络是一个等变映射。事实上,等变神经网络已经成为材料领域 AI for Science 研究的主流。
去年 9 月,日本东北大学和麻省理工学院的研究人员推出了一种新型人工智能工具 GNNOpt。通过集成等变神经网络,GNNOpt 利用 944 种材料组成的小型数据集实现了高质量的预测,成功识别出 246 种太阳能转换效率超过 32% 的材料,以及 296 种具有高量子权重的量子材料,极大地加速了能源和量子材料的发现。
去年 8 月,清华大学徐勇、段文晖课题组提出了神经网络密度泛函理论 (neural-network DFT) 框架。该研究将等变神经网络以材料结构信息的嵌入作为输入条件,进而输出哈密顿量矩阵,从而统一了神经网络中损失函数的最小化与密度泛函理论中的能量泛函优化。相比传统的有监督学习方法,这一框架具有更高的准确性和效率,为发展深度学习 DFT 方法开辟了新的途径。此前,该研究团队还提出了 xDeepH(extended DeepH) 方法,通过深度等变神经网络框架来表示磁性材料的DFT哈密顿量,从而进行高效的电子结构计算。
如今,等变神经网络正引领超导材料领域迈向全新的研究范式。超导材料的研究与应用已不再局限于实验室,正逐步融入实际生活,其市场潜力也在持续释放。据预测,全球超导材料市场规模将持续扩大,到 2027 年有望增至 192 亿欧元。随着等变神经网络等 AI 技术与超导材料的深度融合,人类正触碰科技的「跃迁点」,开启一个充满无限可能的新时代。










