
凡是搞计量经济的,都关注这个号了
邮箱:econometrics666@126.com
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
本书旨在为现代统计推断(即机器学习(ML)或人工智能(AI))与因果推断方法的融合提供一个实用的入门指南。目标读者包括高年级本科生、硕士生以及专注于应用实证研究的博士生。学习本书核心内容的基础是修完一学期的初级计量经济学和一学期的机器学习课程。同时,也希望本书能为那些希望在工作中应用现代方法的实证研究者提供有价值的参考。
本书系统梳理了预测推断与因果推断的核心思想,并深入探讨了预测工具在解决因果问题中的关键作用。书中提到的“预测推断”,特指以预测或描述为主要目标的研究场景,这类场景中的模型和估计无需具备因果解释能力。ML/AI工具主要用于解决预测推断问题,因此对Lasso、随机森林、深度神经网络等主流ML/AI方法进行了概括性介绍,以便为不熟悉这些方法的读者提供必要的背景知识。
在因果推断方面,本书重点介绍了为统计估计赋予因果解释的基础理论。采用潜在结果、有向无环图(DAGs)和结构因果模型(SCMs)的语言来阐述这些理论。本书认为,潜在结果、DAGs和SCMs这三种表达方式是相辅相成的。尽管不同背景的读者可能对其中某一种更为熟悉或偏好,但任何对因果推断感兴趣的研究者都应掌握这三种框架。它们各自提供了独特的视角,而熟练掌握这些框架的表达方式,能够帮助研究者与来自不同领域、对因果关系感兴趣的读者进行有效沟通。
本书分为两大部分:核心内容与高级主题。核心内容是本书的主体部分,学习完这一部分后,读者应能掌握预测推断与因果推断的核心思想,并了解如何将二者结合以解决因果推断中的典型问题。核心内容的章节在预测推断与因果推断之间交替展开,通常先介绍用于预测推断的工具,再展示如何利用这些工具解决因果推断问题。高级主题则是对核心内容的延伸,涵盖了更复杂的因果结构场景,例如工具变量模型、因果效应异质性分析,以及双重差分法等实证研究中常见的特定场景。
书中标有★的章节需要读者具备更扎实的数理统计基础。对于希望将机器学习方法应用于实际工作的读者,我们建议初次阅读时可以略过这些部分,待后续有需要时再深入学习。
每章末尾附有简短的参考文献和习题,旨在帮助读者拓展阅读范围并巩固所学知识。
抢先预览:借助机器学习与人工智能推动因果推断
本书的核心问题是:某个行为对结果产生的因果效应是什么?例如,研究者可能希望了解产品价格的设定对其销量有何影响。为了探讨这一问题,本书从亚马逊网站上抓取了9,212款玩具车的数据。图1展示了每款玩具车的30天平均价格与其销售排名的倒数(作为销量的替代指标)之间的对数-对数尺度散点图。其中,𝐷表示价格的对数,𝑌表示销售排名的负对数,这些数据是从亚马逊销售的玩具车中随机抽取的。通过这个例子,本书将逐步展开各章节的内容,展示如何将这些内容结合起来,帮助读者利用ML和AI在现代数据集上进行有效的因果推断。
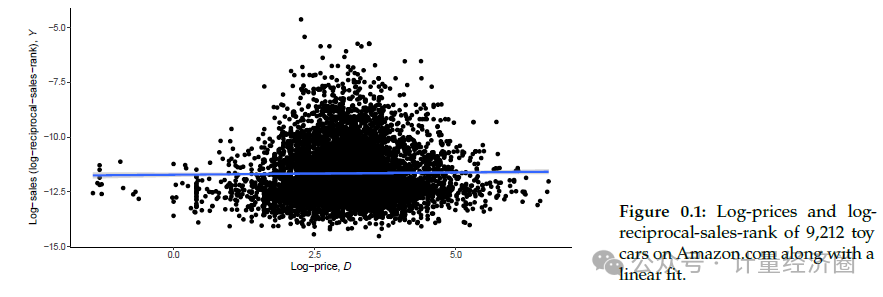
在第1章
中,介绍了普通最小二乘法(OLS)线性回归,这种方法有助于理解两个变量之间的关系。在本例中,OLS表明,𝐷每增加一个单位,𝑌平均变化范围在−0.008到0.050之间;即(−0.008, 0.050)是最佳线性预测斜率95%的置信区间。换句话说,不能排除价格与销量之间存在轻微负相关甚至略微正相关的可能性。然而,如果推断任意提高某款玩具车的价格对其销量几乎没有影响甚至可能增加销量,这是不正确的。
经济学理论认为,任何一款玩具车的潜在对数销量𝑌(𝑑)应随着设定价格的对数𝑑的增加而下降。在第2章中,引入了潜在结果的概念,并研究了在行为随机化(或外生性)条件下对其平均值的推断。例如,研究者可能对价格设定为某一水平时的平均销量感兴趣。与第2章讨论的随机对照试验(RCT)不同,本例中的价格并非随机设定,即价格是内生的。因此,观察到的无关联或略微正相关可能是由于混杂因素的影响,这些因素同时影响了某一定价下的潜在销量和实际设定的价格。例如,某款玩具车是否由知名品牌生产或是否包含热门电视剧角色,可能会提高其在任何价格下的销量,同时也可能导致卖家选择更高的价格,无论是因为预期需求增加还是因为生产成本或授权费用更高。
在第5章中,混杂的概念被形式化,并探讨了在观察到所有混杂变量𝑊的情况下,对潜在结果平均值的因果推断。第6章进一步引入了一个线性结构方程:该方程假设,在排除每款玩具车的个体差异𝑈后,任何对数价格下的对数销量是对数价格的线性函数。在此方程中,𝛼被解释为𝑑对𝑌的因果效应,即通过干预系统改变𝑑而保持其他销量决定因素不变时,𝑑的变化对𝑌的影响。这种因果效应通常无法通过将观测到的𝑌对观测价格𝐷进行回归来恢复,因为观测价格是在市场中设定的,可能与不可观测因素𝑈相关。
在简单线性结构方程中,假设𝑊能够解释所有混杂因素,可以得出:其中𝑔(𝑊)是某个函数。因此,在完成因果建模和假设后,剩下的任务是对𝑌关于𝐷和𝑊的复杂回归模型中的系数进行推断。也就是说,在因果建模和假设下,从(𝑌, 𝐷,𝑊)数据中对式(0.0.2)中的𝛼进行统计推断(如构建估计值和置信区间)即为因果推断。(0.0.1)是最简单的结构方程——为了理解更复杂的结构,第7章考虑了方程组,甚至是非线性结构方程。
为了说明如何利用ML和AI增强因果推断,回到𝑊究竟是什么的问题。在亚马逊网站上,除了价格和销量外,还可以观察到每款玩具车的许多特征:产品页面上的所有文本(如名称和描述)、产品子类别(不仅仅是玩具)、品牌、颜色、物品及其包装的尺寸和重量。可以利用哪些特征?如何利用?
经典方法如OLS(第1章)允许在式(0.0.2)为线性回归且维度适中时对𝛼进行推断,即当𝑊是𝑝维随机向量,𝑔(𝑊) = 𝛽1 + 𝛽′2𝑊,且𝑝远小于观测数量(本例中为9,212)时。在式(0.0.2)中令𝑔(𝑊) = 𝛽1+𝛽′2𝑊,得到一个线性模型。玩具车有243个产品子类别。假设将每个子类别编号为1到243,并令𝑊为一个243维向量,其中产品子类别对应的索引为1,其余为0。对𝑌关于𝐷和这一特定𝑊的OLS回归解释了𝑌方差的7.5%(以调整后的𝑅2衡量),并给出了𝛼的95%置信区间为(−0.026, 0.036)。这些结果与未调整任何混杂效应时推断的𝑌与𝐷之间的关联关系差异不大,但至少上限更小——正效应被认为是不现实的。
也许需要控制比子类别更多的混杂效应。然而,即使不偏离线性,如果在𝑊中包含过多特征,OLS也无法提供可靠的推断。在式(0.0.2)中令𝑔(𝑊) = 𝛽1 + 𝛽′2𝑊且𝑊为高维(即维度𝑑与观测数量相当或更大),得到一个具有高维控制的线性模型。第3章介绍了比OLS更高级的ML方法:使用正则化线性回归进行高维预测推断。正则化线性回归可能比OLS提高预测性能,但会引入偏差,危及对系数的推断。第4章展示了如何在对任何单一系数进行推断时纠正这种偏差。在因果推断的背景下,这种设置能够处理大量混杂因素,并希望更可靠地证明已考虑了所有混杂因素。
简而言之,在式(0.0.2)的设定中,如果取𝑌˜和𝐷˜分别为𝑌关于(1,𝑊)和𝐷关于(1,𝑊)的现代高维线性回归的残差,那么对𝑌˜关于𝐷˜的OLS回归即使在𝑊为高维时也能对𝛼进行有效推断。假设𝑊是一个11546维向量,不仅包括子类别的指示变量,还包括物品的物理尺寸(经过对数变换并扩展至对数的三次方)、缺失值指示变量、这些尺寸特征与子类别的交互项,以及品牌指示变量(共1827个品牌)。在这种情况下,𝑝大于观测数量𝑛。利用第4章介绍的方法,在这种特定设置中利用高维𝑊,得到𝛼的95%置信区间为(−0.10, −0.029)。置信区间仅包含负值,这与提高价格会减少需求的直觉一致。同时,可能仍担心线性模型过于严格,本质上只允许线性控制预先指定的混杂因素。
在第 9 章里,介绍了非线性 ML 回归方法,涵盖树模型、集成学习以及神经网络。相较于运用 LASSO 预测对数价格和对数销量,采用这些方法(利用 2083 维特征向量,省去线性模型所需的扩展和交互项),通过 5 折交叉验证的 𝑅2 评估,将 𝑅2 分别提升了 25 - 53% 和 89 - 189%。显而易见,这些方法针对本数据集带来了显著的预测改进。不过,这些非线性方法不存在可明确提取的参数,也无系数可供检查。尽管它们能够做出出色的预测,但对于如何借助它们对有限维参数(比如平均效应)开展有效的统计推断,尚不明确。这一问题在第 10 章得到了解决。
在式 (0.0.2) 中,令 𝑔(𝑊) 为任意非线性函数,由此形成所谓的部分线性模型,该模型在结构性与灵活性之间达成良好平衡:模型的因果效应部分简单且易于理解 —— 行为每增加一个单位,结果相应增加 𝛼;而人们无意去解释的混杂部分则可以近乎任意复杂。在式 (0.0.2) 所设定的情境下,能够保留残差对残差的 OLS 推断方法,只是所用残差来自高级非线性回归,只要在数据的某部分拟合这些回归,并排除用于预测以及生成残差的部分。这便是部分线性模型的双重机器学习(DML)或去偏机器学习。在此例中,运用 DML 配合梯度提升树回归对价格弹性 𝛼 进行推断,得出的置信区间为 (−0.139, −0.074),表明效应的方向与直觉更为契合,这主要归因于这些更为强大的预测方法能够更好地解释并纠正那些将表面关系推高的混杂效应。
然而,目前尚不清楚所观察到的数值特征能否可靠地捕捉所有混杂效应 —— 若不能,那么无论回归模型多么灵活,都无济于事。这个问题 —— 获取正确的数据以支持因果推断 —— 是处理观察数据时常见的挑战。正是在充分利用所有可用数据的过程中,现代 AI 与本书开发的工具相结合,独特地支持了利用现代观察数据集开展强大的因果推断。现代数据集内容丰富,远不止数值特征。例如,本数据集包含每款产品的文本 —— 描述中蕴含了许多关于每款产品的重要特征,这些特征并未明确列出,但必须通过阅读文本来推断。幸运的是,现代 AI 近年来在文本、图像、视频等丰富数据的机器认知方面取得了巨大进展。
第 11 章探讨了如何将强大工具与 DML 结合使用。BERT 是一种基于深度学习架构(即 Transformer)的大型语言模型,在自然语言处理基准测试中表现卓越。通过基于 BERT 构建的神经网络预测模型对数价格和对数销量,相较于仅使用数值特征的非线性模型,交叉验证的 𝑅2 分别提高了 12 - 37% 和 4 - 59%。这表明,数据中的非数值特征在预测价格和销量时,似乎比产品的基线数值因素更为重要。运用 DML 结合这些利用非数值特征的模型,能够对每款玩具车产品页面上的丰富文本所反映的混杂因素进行因果推断。通过这种方式,第 11 章详细阐述了,得到 𝛼 的置信区间为 (−0.21, −0.13)。此处得出的更负的估计再次表明,存在残余的混杂效应,致使价格与销量之间出现虚假的正相关关系,而唯有通过 AI 利用丰富文本数据才能控制并抵消这些效应。
虽然通过保留测试集和交叉验证来验证预测模型的性能相对容易,但要明确验证因果效应则极为困难,甚至可以说是不可能的,因为它终究依赖于根本无法检验的假设。不过,对于正确且充分利用可用数据、不依赖不必要参数假设的估计,可以更有信心。基于 DML 和 AI 的估计能够做到这一点。能够利用丰富的数据而不强加严格的函数形式限制,并且重要的是,这样做不会危及有效统计推断的保证。核心内容概述了运用 DML 与 AI 学习器来估计和推断低维因果效应的基本思路及基础成果。
高级主题部分涵盖了对核心章节基本内容的拓展。在核心内容中,探讨了比本预览介绍的部分线性模型更复杂的结构,但仅在所有相关变量都被观察到的情况下进行推断。第 12 章介绍了在未观察到所有混杂因素时识别因果效应的替代方法,诸如敏感性分析、工具变量以及代理控制等技术,而第 13 章则提供了在此类情境下开展因果推断的具体方法。这些工具使得人们能够对借助特殊结构(比如工具变量或代理)的因果估计充满信心,无需额外做出不必要的参数假设,并且能够利用强大的 AI 处理丰富数据。在许多实例中,人们或许希望了解因果效应的异质性,例如因果效应如何随着观测预测变量而变化。第 14 章涵盖了用于表征这种异质性的 DML 推断,第 15 章则超越了对低维因果参数的推断,讨论了从丰富的个体层面数据中学习异质性因果效应,甚至基于此类数据个性化治疗方案。最后,第 16 章和第 17 章分别探讨了 DML 与两种流行的因果效应识别方法 —— 双重差分法和断点回归设计 —— 的结合应用。
在学习完本书之后,读者还应在许多未明确涵盖的应用场景中理解和运用 DML。以玩具车例子为例,关注点在于销量,然而当库存达到极限时,销量或许无法准确反映需求,这种情况被称为右截尾。截尾是数据粗化的一种形式,从数学角度而言,与未采取行动的潜在结果的缺失并无太大差异。同样地,人们可能希望研究超出平均值的分布效应,比如对销量分位数的影响。DML 通常可以应用于这些问题,并且有活跃的研究将其应用于更为复杂的问题。
此外,还有一些主题超出了本书的范围。一开始便提及,关注的是行为对结果的因果效应 —— 一个更为宽泛但更具挑战性的问题在于,在多个变量中,发现哪些变量对哪些变量存在因果效应。尽管在第 7 章和第 8 章中讨论了有向无环图的使用,但仅用其表示假设的结构,并简要提及如何直接从数据中学习因果结构,这是因果发现的课题。本书的目标相对集中:呈现预测推断和因果推断的构建模块,并展示它们在实践中的有效且正确使用,助力读者在真实、实际的场景中应用它们。书中将两种推断相互交织,提供了大量带有代码笔记本的真实数据示例。期望最终读者能够借助 ML 和 AI 进行因果推断,并且在实践中利用丰富的现代数据得出有效、可靠的推断。
目录






书籍下载链接:https://causalml-book.org/assets
*群友可直接在社群下载正本书籍的PDF。
关于因果推断书籍,参看:1.一本最新因果推断书籍, 包括了机器学习因果推断方法, 学习主流和前沿方法,2.社会经济政策的评估计量经济学, 提供书籍和数据和程序文件,3.诺奖得主Angrist的因果推断课程文献读物单子再次更新了, 还提供了其他三门课程,4.全面且前沿的因果推断课程, 提供视频, 课件, 书籍和经典文献,5.从网页上直接复制代码的因果推断书籍出现了, 学会主流方法成效极快,6.推荐书籍"用R软件做应用因果分析", 有需要的学者可以自行下载!7.哪本因果推断书籍最好?我们给你整理好了这个书单!8.“不一样”的因果推断书籍, 很多观点让我们能恍然大悟, 涵盖了不少其他书里没有的因果推断方法!9.搞懂因果推断中内生性问题解决方法必读的书籍和文献已搜集好!10.一位“诗人”教授写了本因果推断书籍, 现在可以直接下载PDF参看!11.使用R软件学习计量经济学方法三本书籍推荐,12.机器学习与Econometrics的书籍推荐, 值得拥有的经典,13.史上最全的因果识别经典前沿书籍, 仅此一份,14.用R语言做Econometrics的书籍推荐, 值得拥有的经典,15.Stata学习的书籍和材料大放送, 以火力全开的势头,16.USA经管商博士最狂热崇拜的计量书籍震撼出炉,17.推荐使用Python语言做因果推断前沿方法的书籍
,18.哈佛教授因果推断经典之作推荐!通过数据,代码和示例手把手教你!19.世界银行刚出版了“政策评估”经典书籍, 包括当前主流政策评估计量方法,20.欧盟EU出版了“数据驱动的政策评估”经典书籍, 关键还免费!
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
7年,计量经济圈近2000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多
、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。










