激活函数和损失函数在深度学习中扮演着至关重要的角色。通过选择合适的激活函数和损失函数,可以显著提高神经网络的表达能力和优化效果。
其中激活函数是神经网络中的非线性函数,用于在神经元之间引入非线性关系,从而使模型能够学习和表示复杂的数据模式,常见的激活函数有 Sigmoid、Tanh、ReLU 和 Leaky ReLU;损失函数则是评估模型预测值与真实值之间的差异,通过最小化损失函数来优化模型参数,常见的损失函数有 MSE和交叉熵损失(Cross-Entropy Loss)。
激活函数(Activation Function)是什么?在深度学习中,
激活函数是神经网络中的非线性函数,用于在神经元之间引入非线性关系,从而使模型能够学习和表示复杂的数据模式。如果神经网络没有像Relu这样的激活函数(也叫非线性激活函数),神经网络每层就只包含两个线性运算,即点积与加法:output = dot(input, W) + b。神经网络中的每一层若仅进行线性变换(仿射变换),则其假设空间受限,无法充分利用多层表示的优势。因为多个线性层堆叠后,其整体运算仍然是线性的,增加层数并不能扩展假设空间。为了获得更丰富的假设空间,需要引入非线性因素,即激活函数。Sigmoid和Tanh是较早使用的激活函数,但存在梯度消失问题。ReLU及其变体(如Leaky ReLU、PReLU、ELU等)通过改进梯度消失问题,成为了当前隐藏层常用的激活函数。而softmax函数则专门用于多分类问题的输出层,将输出转换为概率分布。Sigmoid:将输入值压缩到(0, 1)之间,常用于二分类问题的输出层。但存在梯度消失问题,且输出不以零为中心。
Tanh:将输入值压缩到(-1, 1)之间,输出均值为0,更适合隐藏层。但同样存在梯度消失问题。
ReLU:当输入大于0时,输出等于输入;当输入小于0时,输出为0。具有计算简单、梯度消失问题较轻的优点,是隐藏层常用的激活函数。但存在神经元死亡问题。
Leaky ReLU:解决了ReLU在输入小于0时梯度为0的问题,允许小的梯度流过。
Softmax:将输入向量中的每个元素映射到(0, 1)区间内,并且所有输出元素的和为1。用于多分类问题的输出层,将神经网络的输出转换为概率分布。
“激活函数是神经网络中的非线性组件,用于在神经元间引入非线性关系,使模型能捕捉复杂数据模式,其中ReLU及其变体常用于隐藏层,而Softmax则专用于多分类输出层。”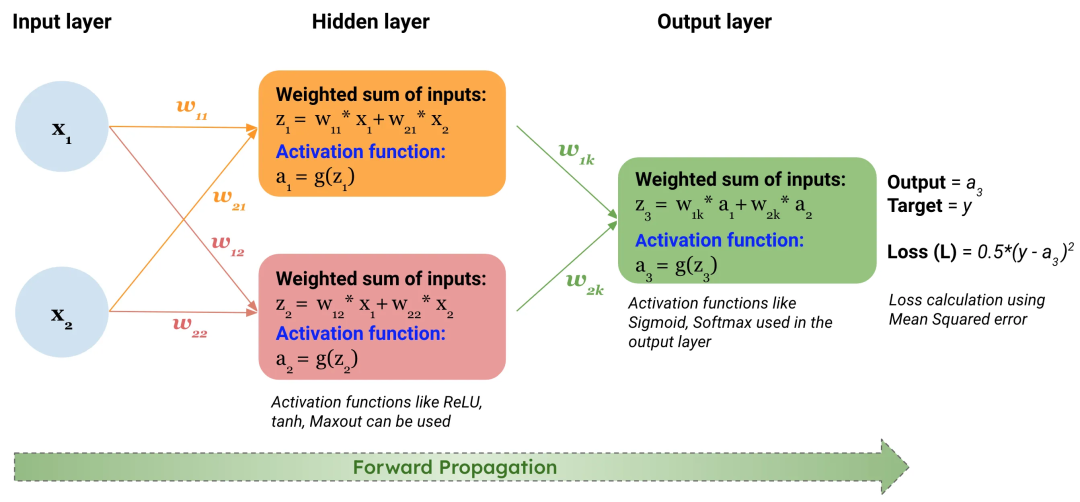
损失函数(Loss Function)是什么?在深度学习中,损失函数则是评估模型预测值与真实值之间的差异,通过最小化损失函数来优化模型参数。
在深度学习中,通过计算损失值,可以直观地了解模型的预测性能,从而指导模型的优化方向。神经网络通常使用梯度下降等优化算法来调整模型参数。
损失函数为这些优化算法提供了明确的目标和方向。通过不断减小损失值,可以逐步优化模型参数,提高模型的预测性能。常见类型包括均方误差、交叉熵损失等,选择时需根据任务类型、数据分布和特定需求进行考虑。
“一图 + 一句话”彻底搞懂损失函数。
“损失函数是衡量模型预测值与真实值差异的函数,通过最小化损失函数优化模型参数,常见类型有均方误差(回归)和交叉熵损失(分类),选择时需根据任务需求。”









