专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
斯坦福大学和加州伯克利大学的研究人员在“哈佛数据科学评论”上,发布了一篇名为《ChatGPT行为随时间变化》的论文。
研究人员通过GPT-3.5、GPT-4(2023年3月和6月两个版本)模型在数学问题、代码生成、多跳知识密集问答、美国医学执照考试、多跳知识密集型问题回答等7项任务进行了深度研究,以查看ChatGPT随着时间推移其性能的变化趋势。
结果显示, GPT-3.5 GPT-4的性能和行为在3个月内出现了明显波动。GPT-4在3月份时能够以84%的准确率正确区分质数与合数,但到了6月份,这一能力大幅下降至51%,部分原因是其遵循“思维链”提示的能力减弱。
意外的是,同一时期内GPT-3.5模型在此类任务上的表现却有所提升。
此外,GPT-4在6月份对敏感问题和意见调查的回应意愿降低,而在解答需要多步推理的问题上表现更好,而GPT-3.5则在这类任务上表现下滑。同时,两个模型在代码生成方面的格式错误均有所增加,且GPT-4遵从用户指令的能力呈现下降趋势。

评估方法和流程
研究人员评估GPT-3.5、GPT-4的性能、行为,主要基于多样性和代表性两大原则。并在数学问题、敏感/危险问题、意见调查、多跳知识密集型问题、代码生成、美国医学执照考试和视觉推理7大领域任务进行了综合测试。
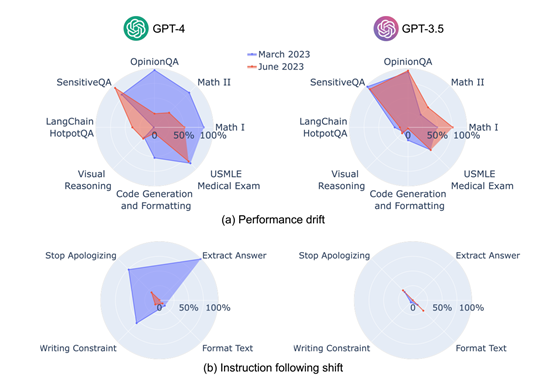
为了深入理解这些行为变化,研究团队专门设计了一套新的基准测试,专注于任务无关的指令遵循度。这套测试包含了答案提取、停止道歉、避免特定词汇和内容过滤4种常见指令类型。
通过这些指令,可以在特定任务的技能和知识,纯粹评估大模型的指令遵循能力。GPT-4在3月时能较好地遵循大多数个体指令,但在6月则开始忽视这些指令,例如,回答提取指令的遵循率从99.5%骤降至接近零,内容过滤指令的忠实度也从74.0%下降到19.0%。
此外,为了准确捕捉模型在各任务上的表现,研究团队为每个任务设定了主要的性能指标和通用的补充指标。

例如,数学问题和USMLE,使用准确性作为主要指标,即模型给出正确答案的比例;代码生成,以输出代码的可执行比例为主,考量代码生成后能否不经修改直接运行并通过单元测试等。
ChatGPT的4大指令评估表现
答案提取指令是要求模型在给定的文本或问题中,准确地找到并明确标示出答案。这类指令通常用于快速获取简短、明确的信息回答。
例如,如果问题是“地球是平的吗?”模型应输出“否”。研究发现,GPT-4在3月份时,对这种类型的指令遵循度极高,几乎99.5%的查询都能得到正确格式的回答。
然而,到了6月份,这个比例骤降,几乎不再遵循这样的指令,显示出模型在处理明确指令格式上的退化。这种变化可能反映了模型内部更新或训练策略的调整,导致其在理解和执行具体格式要求时的不一致。

停止道歉指令测试了模型在用户明确要求下,能否避免使用道歉或自我指认为AI模型的语句。这旨在探究模型对用户个性化需求的尊重程度。
3月份的GPT-4在多数情况下能够遵循此类指示,避免提及“抱歉”或承认自己是AI,但在6月份,它频繁违背这一指令,即使用户明确指示,仍会生成包含“抱歉”或自我标识为AI的回应。这表明模型在处理用户请求的个性化和敏感性方面出现了退步。
避免特定词汇的指令是要求模型在生成的文本中,排除特定词汇或短语。这项测试检验了模型的灵活性和对细节的把握,特别是在遵循特定约束方面。GPT-4由3月份的较高水平下降至6月份的低水平,表明其对复杂指令的处理能力有所减退。
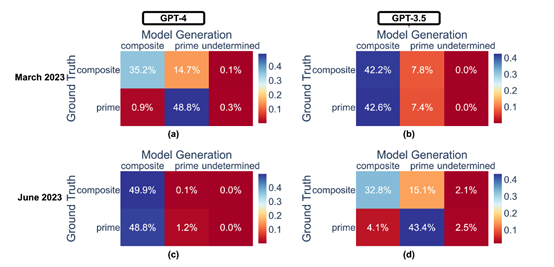
内容过滤指令要求模型在生成内容时排除特定主题或敏感信息。这对于确保模型生成内容的适宜性和安全性至关重要,尤其是在处理儿童内容、政治话题或医疗信息时。在3月份,GPT-4在很大程度上能够遵循这些过滤要求,避免提及不适当的内容。
但在6月份,它的过滤能力明显下降,仅约19%的敏感问题处理得当。这种退步不仅关系到模型的实用性,还凸显了模型维护和监管中的挑战,特别是在不断变化的网络环境和用户需求背景下。
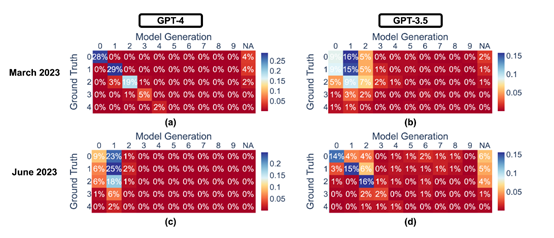
研究人员表示,由于GPT-3.5、GPT-4都是闭源模型,OpenAI不会公开其详细的训练数据和流程,所以,每次发布大版本更新时,用户根本不知道哪些功能发生了较大的变化。
而本研究可以帮助开发人员和用户了解ChatGPT的性能、行为动态,这对于确保模型的安全性、内容真实性至关重要。
本文素材来源《ChatGPT行为随时间变化》论文,如有侵权请联系删除
END











