类型:超精简版
选文: 大壮
编辑: 大壮
生活中总有苦难和波折,但要保持一个积极、阳光的心态,传递正能量。同时也要自信一些、开朗一些。
言归正传:
论文2025.1.3刚发表。这个使用机器学习模型评估肿瘤实验试验结果,研究思路上还是很创新的,值得学习。

随机对照试验(RCTs)在评估抗癌药物时,其结果的普适性有限,导致现实世界中的生存率通常低于试验报告的水平。限制性入选标准和选择性招募是主要原因之一,但可能还有其他因素。为了更好地将3期试验结果应用于现实世界患者,需要改进的方法来考虑患者的多种特征。结合电子健康记录(EHR)数据和机器学习(ML)可以帮助识别与RCT结果一致的患者群体,并揭示更微妙的预后差异。尽管已有框架用于试验模拟,但基于ML的患者预后调整尚未广泛应用。TrialTranslator是一个新框架,旨在通过ML识别的预后表型系统地模拟3期肿瘤学试验,以揭示现实世界患者中的治疗效果异质性。
1.研究简介
RCTs的局限性:许多抗癌药物的RCTs由于严格的入选标准,导致其结果在现实世界中的普适性有限。现实世界中的患者预后异质性较大,而RCTs的参与者通常预后较好。
预后风险的不确定性:除了入选标准外,预后风险的选择偏差也是导致普适性不足的一个因素。
1.1研究目的:
论文的主要目的是评估随机对照试验(RCTs)在肿瘤治疗中的结果在现实世界患者中的普适性,特别是针对抗癌药物的RCTs。研究者开发了一个名为TrialTranslator的框架,通过机器学习模型来模拟RCTs,以评估其在不同预后表型的现实世界患者中的普适性。
1.2研究方法:
TrialTranslator框架:该框架分为两个步骤:
1. 预后模型开发:使用机器学习模型对现实世界中的肿瘤患者进行风险分层,预测从转移诊断到死亡的风险。
2. 试验模拟:在每个试验中,将符合入选标准的患者根据预后风险评分分为低风险、中风险和高风险表型,然后进行生存分析,比较不同表型的治疗效果。
入选标准匹配:选择符合关键入选标准的现实世界患者,包括正确的癌症类型、适当的治疗线和相关的生物标志物状态。
预后表型分型:使用GBM模型计算每个患者的死亡风险评分,并将患者分为低风险、中风险和高风险表型。
生存分析:通过逆概率治疗加权(IPTW)调整的Kaplan-Meier生存曲线,评估每个表型的治疗效果,并与相应的RCT结果进行比较。
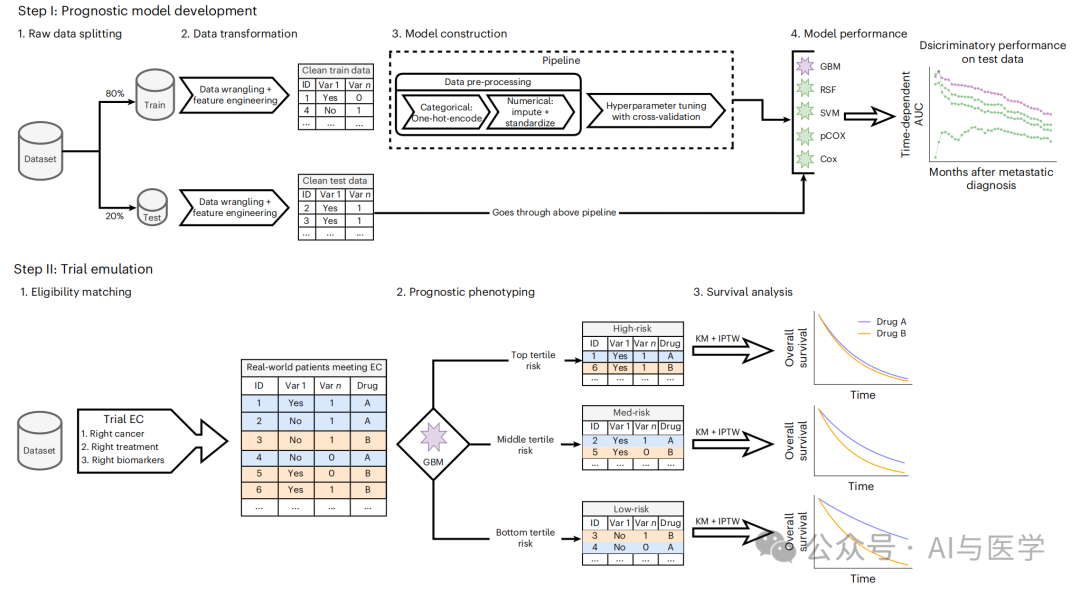
数据来源:使用Flatiron Health的电子健康记录数据库,涵盖约280个美国癌症诊所的数据。
模型选择:选择了梯度提升生存模型(GBM)作为表现最佳的模型,用于预后风险评分的计算。
1.3实验结果
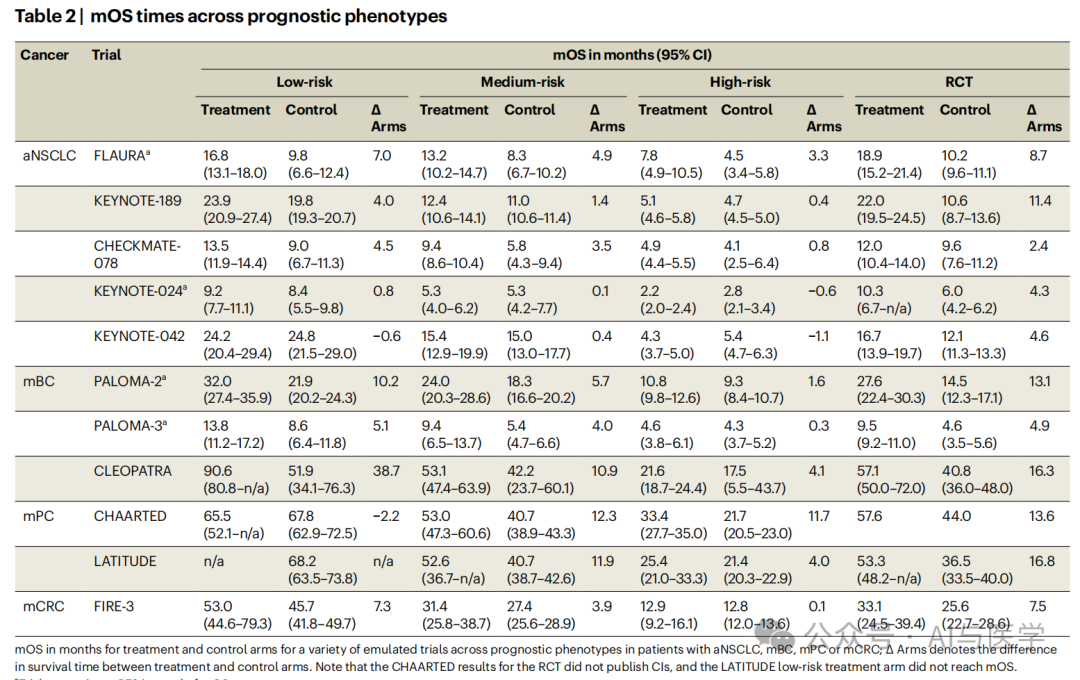
低风险和中风险表型:这些表型的患者在模拟试验中的生存时间和治疗相关的生存获益与RCTs的结果相似。
高风险表型:与RCTs相比,高风险表型的患者生存时间和治疗相关的生存获益显著降低。
稳健性评估:通过特定患者亚组的检查、留出验证和半合成数据模拟等方法,验证了结果的稳健性。
1.4结论和意义
预后异质性的作用:现实世界肿瘤患者的预后异质性在RCT结果的普适性有限中起着重要作用。
机器学习框架的应用:机器学习框架可以促进个体患者层面的决策支持,并估计现实世界中的治疗获益,以指导试验设计。
这项研究通过机器学习方法对RCTs的结果进行模拟和评估,为将RCTs的结果更好地应用于现实世界中的患者提供了新的思路和工具。这对于临床决策和未来试验的设计具有重要的指导意义。
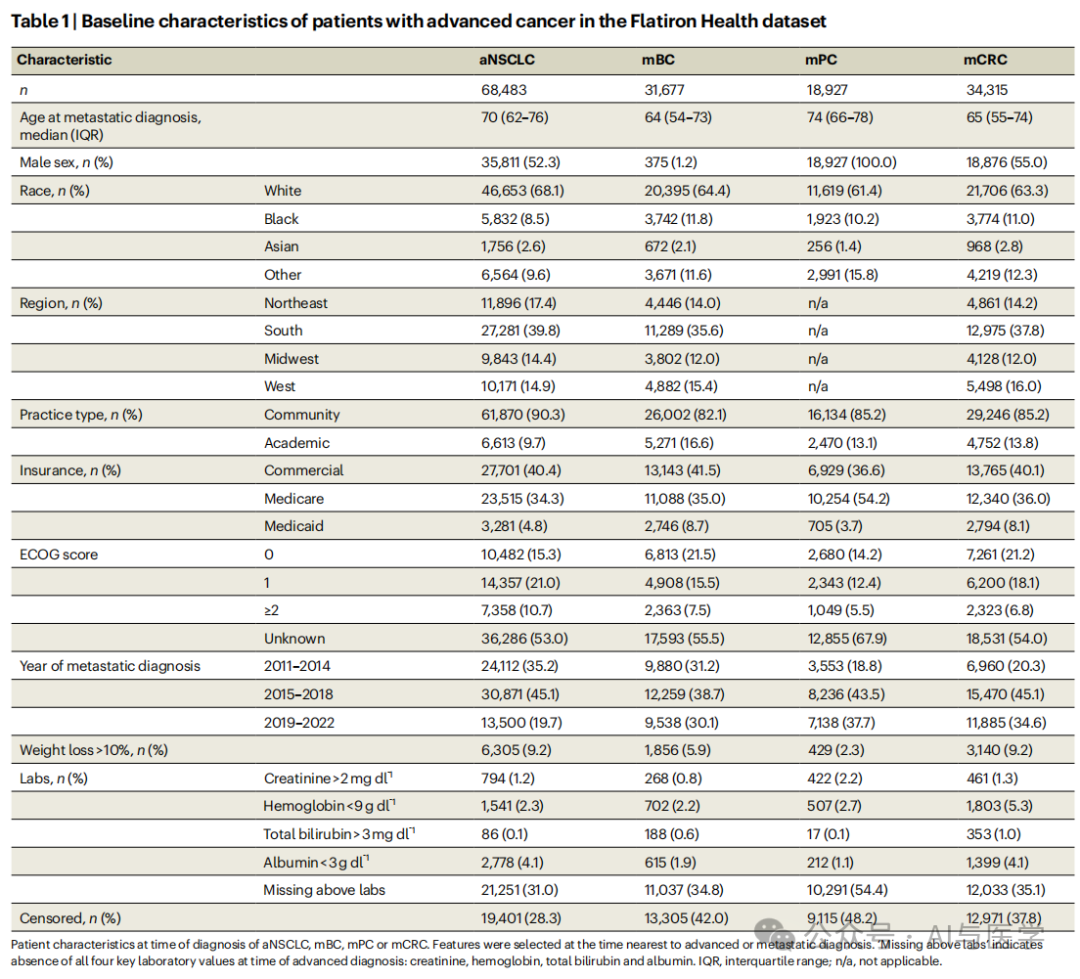
2.数据介绍
使用了Flatiron Health的电子健康记录(EHR)数据库作为数据来源。该数据库收集了来自美国约280个癌症诊所的去识别化的患者数据。这些数据包括结构化数据和非结构化数据。
结构化数据:包括实验室结果、诊断代码等,这些数据经过标准化处理,以确保数据的一致性和可比性。
非结构化数据:如临床笔记和病理报告等,通过肿瘤注册员和肿瘤护士使用技术辅助的抽象平台进行处理,提取关键变量,如生物标志物或疾病进展日期。
数据库中包括68,483名非小细胞肺癌(aNSCLC)患者、31,677名转移性乳腺癌(mBC)患者、18,927名转移性前列腺癌(mPC)患者和34,315名转移性结直肠癌(mCRC)患者。
3.预后模型开发
主要目标是预测从转移诊断开始的死亡率。为此,开发了针对每种癌症类型的监督生存模型。这些模型在特定的时间点进行了优化:非小细胞肺癌(aNSCLC)为转移诊断后1年,而转移性乳腺癌(mBC)、转移性结直肠癌(mCRC)和转移性前列腺癌(mPC)为转移诊断后2年。这些时间点的选择是为了与Flatiron Health数据库中每种癌症类型的中位总生存期(mOS)相匹配。
使用的机器学习模型包括梯度提升生存模型(GBM)、随机生存森林、生存线性支持向量机以及三种惩罚性Cox(pCox)比例风险模型的变体。此外,还构建了一个Cox比例风险模型,灵感来源于每种癌症类型的回顾性研究,作为与机器学习模型的比较基准。

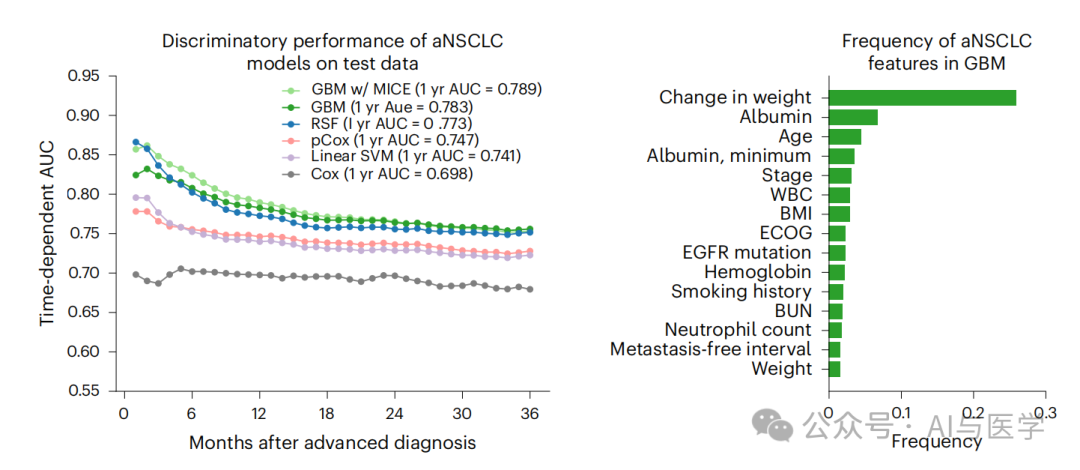
在所有四种癌症类型中,GBM在测试集上始终表现出优越的性能,特别是在转移或晚期诊断后1年和2年的总体生存率方面。
在aNSCLC中,GBM的1年生存AUC为0.783,
而基于前瞻性数据得出的肺癌预后指数的Cox模型为0.689。
对于mBC、mPC和mCRC,2年AUC分别为0.814、0.754和0.768,
GBM的表现优于相应的Cox模型。
对GBM预测价值贡献最大的关键特征包括年龄、体重减轻、东部合作肿瘤学组(ECOG)表现状态、癌症生物标志物以及血清虚弱标志物,如白蛋白和血红蛋白。
4.表型分层模拟实验
模拟试验的入选资格取决于患者是否满足三个关键入选标准:
(1)具有正确的癌症类型,
(2)在适当的治疗线接受感兴趣的治疗,
(3)在治疗时具有相关的生物标志物状态。
模拟试验的队列规模从1,200到30,000名患者不等,平均每个试验约有4,000名患者。
满足试验入选标准的患者随后使用步骤一中确定的癌症特异性GBM进行预后表型分型。该模型为每位患者计算死亡风险评分,代表其在时间t之前死亡的可能性,评分越高表示风险越大。
在研究中,通过模拟试验来评估不同预后表型患者的治疗效果。
1.入选标准:首先,选择符合特定条件的患者,包括正确的癌症类型、适当的治疗方案和相关的生物标志物状态。
2. 表型分层:使用机器学习模型对这些患者进行风险评估,将他们分为低风险、中风险和高风险三组。
3. 加权平衡:为了确保治疗组和对照组在基线特征上相似,我们使用逆概率治疗加权(IPTW)方法来调整数据。这样可以减少其他因素对结果的影响。
4. 生存分析
:通过分析调整后的数据,我们比较了不同表型患者的生存时间和治疗效果。结果显示,低风险和中风险患者的治疗效果与临床试验结果较为一致,而高风险患者的治疗效果则较差。
5.总结
研究发现,临床试验中报告的抗癌药物的生存时间和治疗效果在现实世界中的普适性有限,特别是在高风险患者中。低风险或中风险患者的治疗效果与临床试验结果较为一致,而高风险患者的治疗效果则显著降低。TrialTranslator框架通过整合电子健康记录数据、机器学习表型分型和试验模拟,能够将临床试验结果更好地应用于个体患者,支持临床决策和未来试验的设计。
未来的试验应考虑在患者入组时采用更复杂的方法来评估患者的预后,而不是仅仅依赖于严格的入选标准。此外,应努力提高高风险亚组在临床试验中的代表性,以更好地理解这些患者的治疗效果。
研究也存在一些局限性,如模型缺乏外部数据集的验证,可能导致对某些患者群体的预测准确性不足。此外,由于缺乏死因数据,无法考虑竞争风险的影响。未来的研究可以进一步改进模型和方法,以提高结果的可靠性和普适性。
6.学习心得
(1)这个论文读起来,相对难理解,但是选题很好
(2)Flatiron Health这个数据大家可以试试。
(3)细节部分大家可以去详细品品这个论文的。由于时间比较干,对于细节部分大壮也是没读透。
感谢您的阅读,如果您对这项研究感兴趣或想了解更多关于AI在医学中的应用,请继续关注我们,我们会定期分享最新的科研成果和健康资讯。别忘了点赞和转发哦!👍🔄










