转自:环境工程与科学

12月26日,美国凯斯西储大学张慧春教授在Environmental Science & Technology发表了题为“Combining Group Contribution Method and Semisupervised Learning to Build Machine Learning Models for Predicting Hydroxyl Radical Rate Constants of Water Contaminants”的研究论文,提出了通过基团贡献法 (GCM) 和半监督学习 (SSL) 策略来构建机器学习模型预测水污染物的羟基自由基速率常数。
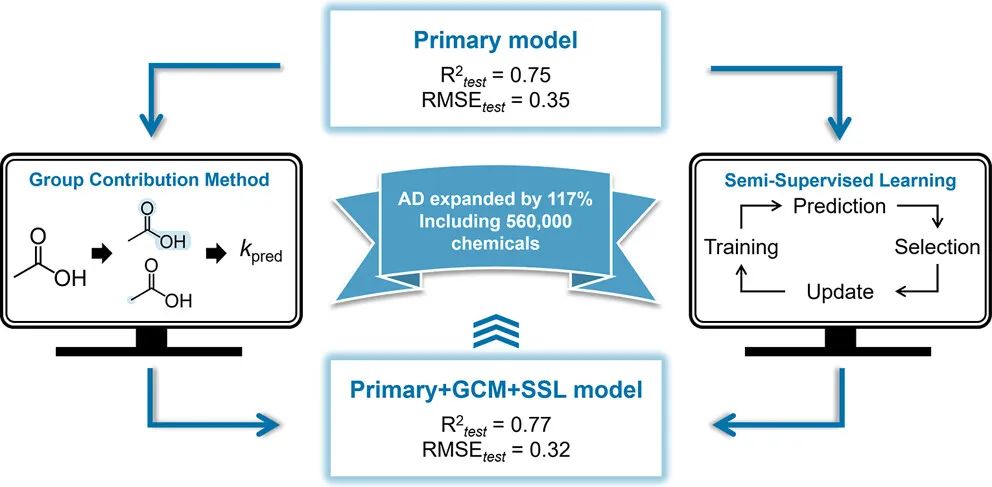
机器学习 (ML) 是解决许多实际问题的强大工具。然而,它在包括环境领域在内的各个领域的应用往往受到缺乏足够数据的制约。具体来说,用于模拟环境化学反应性的样本量通常在几十到几千之间。例如,一个旨在预测有机污染物从土壤到植物根部的生物积累的 ML 模型依赖于 72 种化学品的 341 个数据点。最近用于预测Fe(II)相关还原剂的非生物还原,1978 吸附用化学品,978 记录 206 种厌氧生物降解化学品,12,750 条记录,涵盖 6032 种好氧生物降解化学品,以及 195、191、759 和 557 条记录,分别记录了 HClO、二氧化氯、臭氧和硫酸根的氧化。即使在羟基自由基 (HO•),预测反应速率常数 (k) 的最新模型仅使用了 1374 个数据点。这种数据稀缺性本质上限制了数据集中化学结构的多样性,因此相应的 ML 模型至少面临三个主要限制。首先,模型应用域 (AD) 受到训练数据集中存在的化学结构的限制。因此,将这些模型扩展到许多环境相关的化合物具有挑战性。其次,数据集越小,过拟合的风险就越大,在这种情况下,模型可能会捕获噪声而不是基本原理。这限制了模型推广到新化合物的能力,从而降低了它们的预测准确性和稳健性。最后,小样本量限制了机理洞察的深度,并阻碍了从模型中发现新知识。因此,获得的 ML 模型仅捕获数据集中的部分趋势,这些趋势有时甚至可能存在偏差。
机器学习是预测许多有机化合物的反应速率常数的有效工具,其中羟基自由基 (HO•).以前报道的模型取得了相对较好的性能,但由于数据稀缺(<140本研究策划了一个更大的实验数据集(Primary Data Set),其中包含 2358 条动力学记录。然后,采用基团贡献法 (GCM) 和半监督学习 (SSL) 策略来添加新的数据点,旨在有效扩展模型的 AD,同时提高模型性能。结果表明,GCM 提高了模型对 AD 之外化学品的性能,而 SSL 扩展了模型的 AD。最终模型在整合了 147,168 个新数据点后,实现了R2= 0.77,均方根误差=0.32,均值绝对误差=0.24。重要的是,与仅基于主要数据集开发的模型相比,AD 扩展了 117%,最终模型可以可靠地应用于 DSSTox 数据库中的 560,000 多种化学品。进一步的模型解释结果表明,该模型基于对关键取代基和反应位点对HO•影响的正确“理解”做出预测。这项研究提供了一种增强数据集的有效方法,这对于提高 ML 模型性能和扩展 AD 非常重要。最终模型已通过免费的在线预测器广泛访问。
声明:本公众号仅用于分享前沿学术成果,无商业用途。如涉及侵权,请联系公众号后台删除!
投稿、转载、合作、申请入群可在后台留言(备注:姓名+微信号)或发邮件至sthjkx1@163.com











