TLDR:主要讨论了从追求模型 SoTA 到揭示新现象的转变。通过几个例子,包括ACNet到RepVGG的发展,RIFE插帧、Film插帧,以及OpenAI的近期工作,阐述了这种转变的重要性。
知乎:黄哲威 hzwer
链接:https://zhuanlan.zhihu.com/p/14170281797
最近大家对于前沿工作的讨论,常常出现两极分化
比如 DiT,看到很多人说是灌水,研究生实验报告,Sora 以后有人又说“打脸”
比如说 OpenAI-o3,有答主说 “这是真正的智能爆炸,断崖式提升”,然后评论区说 “下次换个话术”
身边的故事,近期审了不少论文,发现大家对于宣称 SoTA 的工作越来越严苛了。往年那种先 SoTA 再故事的论文,眼看着被连环拒。作者喊着性能无敌,审稿人 borderline reject
想了一些东西,也对 论文写作指南 做了点补充
ACNet 到 RepVGG 的现象上升
聊个大佬朋友的例子, @丁霄汉 说 RepVGG 其实可以叫 ACNetv2
简单来说 ACNet 就是训练的时候三个卷积核,推理的时候合成一个
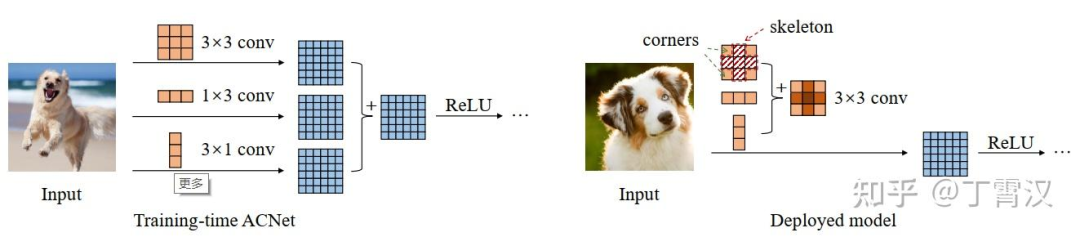
ACNet 在 ICCV19 投稿得分还是有正有负被捞起来,目前 800+ 引用说明后续影响力很不错
我个人觉得并不是当年的审稿人水平太差没有看出它的创新性,而是 ACNet 的创新性在丁博的后续工作中有广泛提升
因为 RepVGG 抽象了一个新概念“结构重参数化”,把 ACNet 中不好说清楚动机的设计方式变成 “构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构”
然后同时又报告了一个现象,即 VGG 式的网络,只要有并行的恒等和 1x1 卷积分支,就能训出 ResNet 相当的性能,推理时还跟原来的 VGG 结构一样
重参数化自此成为手工设计 CNN 的一类重要操作
论文刷点是一部分,更高的性能同时揭露新的现象,才是学术的本质
王婆卖瓜 - RIFE 插帧
卖个自己论文的例子 - RIFE 实时视频插帧模型
我近一两年才逐渐意识到自己阴差阳错做了一篇还不错的论文,目前还不知道怎么达到更高水平,希望以此为例传达一些经验教训
研究初衷是当时业界流行的插帧算法 DAIN 速度比较慢,就想设计个规整的 CNN 网络来做一个实时插帧模型
一开始投稿也是主要突出 SoTA 性能,但是审稿人买账的不多,特别是轻量化模型并不是一个讨喜的研究话题,被拒好几次
虽然我们认为某个指标提高就是模型核心竞争力的体现,但是全世界大概只有几个小同行共识,而且提高一点性能,本身不为领域带来什么新的知识
于是我们重写了文章,更多的加入了新的发现,于是审稿人和读者可以各自寻找心中的哈姆雷特
- 把先前一些模型的误差解释为光流逆转时忽略了物体空间移动,所以我们有更强的动机在轻量化网络中端到端估计中间帧光流
- 对于为什么要做光流蒸馏,先指出输入中间帧信息为“特权”的模型会有高得多的性能
- 多倍插帧,我们发现把目标时间 T 输入进网络是可以实现控制任意时刻插帧的,而且训练之后还可以放入梯度式的时间编码实现场景融合或果冻效应模拟
- 将光流和融合权重先一起预测,可以用来做其它模态的插帧
- 性能上我们也改成强调整体设计带来的多倍插帧场景的效果提升等等
这样自己都不用强调,审稿人每个人都会说这篇论文提出的方法性能很好
我们希望读者觉得论文更有读的价值,现在看引用也真的来自很多不同的方向,比如有 20+ 篇做果冻效应的引用
为什么说 “阴差阳错” 呢,因为很多 idea 其实是多次 rebuttal 以后想的。比如说有两次审稿人批评不能做任意时刻插帧,我就回复说这个简单,把目标时间 T 输入就行了嘛。审稿人说,没做实验你说个锤子,一做才发现效果比预期还好
水平所限,当年其实还是没有把这篇论文写的很好,写这篇总结是希望下次能做的更优美
不用刷 SoTA 的 Film 插帧
带着这样的视角,看看为什么有的论文在很卷的赛道也能中得顺利,发在 ECCV22 的插帧论文 Film: Frame interpolation for large motion,Fitsum Reda 大佬作品

看宣称的论文贡献:
我们将帧插值的范围扩展到一个新颖的近重复照片插值应用,为社区开辟了一个新的探索空间。
– 我们调整了一个共享权重的多尺度特征提取器,并提出了一个尺度无关的双向运动估计器,使用常规训练帧来很好地处理小范围和大范围的运动
– 我们采用基于Gram矩阵的损失函数来修复由大场景运动引起的大范围遮挡,从而生成清晰且令人满意的帧
– 我们提出了一个统一、单阶段的架构,以简化训练过程,并消除对额外光流或深度网络的依赖
很明显地有一些新东西,首先是开辟新的研究范围,找到一些以往算法都会挂掉的例子
然后围绕这个问题构建整个论文,提出了一系列设计,包括结构和损失函数
和别人的对比是次要的,在以往 benchmark 上和 SoTA 差不多可比就可以了,突出一些关注场景的性能
近期热门的 OpenAI 工作
OpenAI 发的一系列东西,如果我们从做新现象的角度去审视,就能知道为什么它们是好东西
比如说 Sora 现在不如可灵,那它是不是价值显著下降?
我觉得可灵以及很多国产视频生成大模型的广泛成功,其实说明了 Sora 的含金量,即它展示的现象是别人可以复现的,通过 DiT 来高质量长时长的可控视频生成,甚至于它的失败例子其实都是很有意思的实验现象
GPT4 / o1 / o3,每一个都展示了前代模型没有的新现象,这是它们足以吸引诸多研究者的原因
如果我第一次看到 ChatGPT,我会很疑惑怎么会有这样交互水平的对话模型,它是不是在时不时联网 + 人工干预 + 复杂的 pipeline 设计来产出内容
然后当我们在小模型复现了一些流程以后,会惊讶于一个 7B 左右大小的模型真的能日常对话
GPT4 一开始最吸引我的,就是它解决我出的算法题的水平。虽然它在这方面不如很多经过训练的初中生,但是比起其它胡说八道的模型真的强了很多
o1 / o3 是思维链了更扩展版本,探索了用更多的推理开销换取智能的可能性
具体就不赘述了,总之我希望社区看这些工作的时候,不要过多讨论 xxx 是不是通往 AGI(通用人工智能)的路子,以及 xxx 的本质是不是就是 xxx,而是分享我们能从新方法看到什么新现象
新的现象才孕育着新的可能










