今天咱们聊聊 MySQL 的主从复制。作为一个 Java 开发工程师,相信你一定知道 MySQL 是最常见的数据库之一,而主从复制作为一种常见的数据库架构设计方式,对于提升数据库的可用性和性能有着举足轻重的作用。
今天我就从技术层面给大家深入分析一下 MySQL 的主从复制,带你彻底了解它是怎么工作的。
首先, MySQL 主从复制的核心技术之一就是 binlog(二进制日志)。这个东西用来记录 MySQL 上的所有变更操作,并以二进制形式保存在磁盘上,目的是方便将数据库中的变动记录下来并同步到其他数据库中。
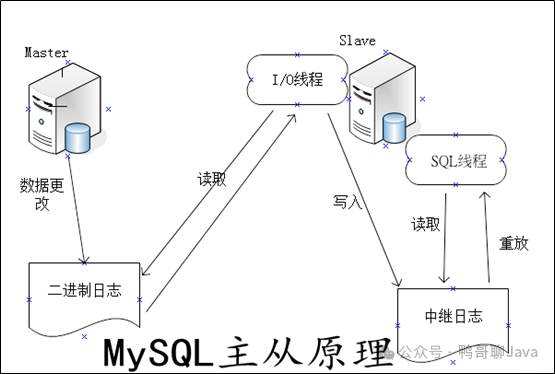
MySQL 的主从复制过程可以分为以下三个阶段:
写入 Binlog:当你在主库上执行了一个数据操作(比如插入、删除或者更新数据),主库会先将这些变动记录到 binlog 中,然后提交事务,并更新本地存储数据。实际上,主库在完成事务后,并不会立刻等待从库同步完这些数据,而是会直接返回客户端操作成功的响应,这就是异步复制的特点。
同步 Binlog:从库有一个专门的 I/O 线程,它会连接到主库上的 log dump 线程,拉取主库的 binlog 日志。当从库收到主库的 binlog 日志后,会把这些日志写到本地的 relay log(中继日志)中。此时,从库并不会直接执行这些变动,它只是在等待一个机会来回放这些日志。
回放 Binlog:从库会创建一个回放 binlog 的线程,这个线程会读取 relay log 中的内容并执行其中的 SQL 语句,从而更新自己的数据存储。这样,从库的数据就会与主库的数据保持一致。
通过以上的阶段,我们可以总结出 MySQL 主从复制的大致工作流程:
-
主库:客户端提交事务请求 → 主库写 binlog → 主库提交事务 → 更新存储引擎数据 → 返回响应。
- 从库:从库创建 I/O 线程,连接主库的 log dump 线程 → 接收 binlog 并写入 relay log → 返回复制成功的响应。
- 从库:从库创建回放线程,读取 relay log → 回放 binlog 并更新存储引擎中的数据。
通过这个过程,主库的数据变动就会异步地同步到从库。值得注意的是,虽然复制是异步的,但如果配置得当,主从库的差异应该非常小,基本上能够实现数据的一致性。
为了更好地理解这个过程,我给大家举个简单的例子。假设我们有一个名为 users 的表,在主库上执行如下 SQL:
INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25);
这时,主库会执行插入操作,并将这条变动写入 binlog。假设 binlog 中保存的内容如下:
BINLOG: INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25);
接着,从库的 I/O 线程会拉取这个 binlog,并将其保存到 relay log 中:
RELAY LOG: INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25);
从库的回放线程会读取 relay log 中的内容,并执行对应的 SQL 语句:
INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25);
回放完毕后,从库的 users 表也会有一条记录,数据同步完成。
有了主从复制,我们就可以将数据库的读写操作分开,主库只负责写操作,从库只负责读操作。这样可以大大提高数据库的性能,特别是对于高并发的应用系统。
比如,如果你有一个需要频繁读取数据的系统,使用主从复制可以把大部分读操作分担到从库,减轻主库的压力,从而提高系统的整体性能。同时,主库可以专注于写操作,不会因为大量的读请求而产生负担。
在面试过程中,关于 MySQL 主从复制的问题是很常见的。以下是一些常见的面试问题和回答。
问题 1:什么是 MySQL 主从复制?它是如何工作的?
回答:
MySQL 主从复制是通过 binlog(数据变动的二进制日志)实现的异步数据同步。主库在执行数据变动时,会将这些变动记录到 binlog 中。从库的 I/O 线程会拉取主库的 binlog 并保存到 relay log 中。然后,从库的回放线程会读取 relay log 并执行其中的 SQL 语句,从而实现数据的同步。
问题 2:MySQL 主从复制是同步的吗?
回答:
MySQL 的主从复制默认是异步的,即主库执行事务后,事务提交并返回客户端响应时,并不会等待从库同步完数据。虽然从库的数据最终会与主库一致,但主库在提交事务后并不会等待从库确认,这就是主从复制的异步特性。
问题 3:如何确保主从复制的数据一致性?
回答:
为了确保主从复制的数据一致性,我们需要关注几个方面:
- 确保主库和从库的时间同步,可以使用 NTP 等工具。
- 使用 GTID(全局事务标识符)来保证主从复制的顺序一致性。
- 配置合理的复制延迟监控,及时发现和修复可能的数据不一致问题。
通过这些措施,主从复制的数据一致性能够得到较好的保证。
问题 4:MySQL 主从复制延迟的原因是什么?如何解决?
回答:
主从复制的延迟可能由多种原因引起,例如:
- 主库的写操作频繁,导致 binlog 写入过快,从库无法及时消费。
- 从库的 I/O 或回放线程性能不足,导致数据处理慢。
- 网络延迟或网络带宽不足,影响 binlog 的同步速度。
为了解决这些问题,可以:
- 提高从库的硬件性能,确保 I/O 和回放线程的速度。
总之,MySQL 主从复制是一个非常重要且实用的技术,能够有效提升数据库的性能和可靠性。通过合理配置和优化,可以让你的系统在高并发场景下依然保持高效稳定。









