自 2006 年深度学习概念被提出以来,近 20 年的时光悄然流逝。深度学习作为人工智能领域的一场重大革命,已然催生出众多极具影响力的算法。
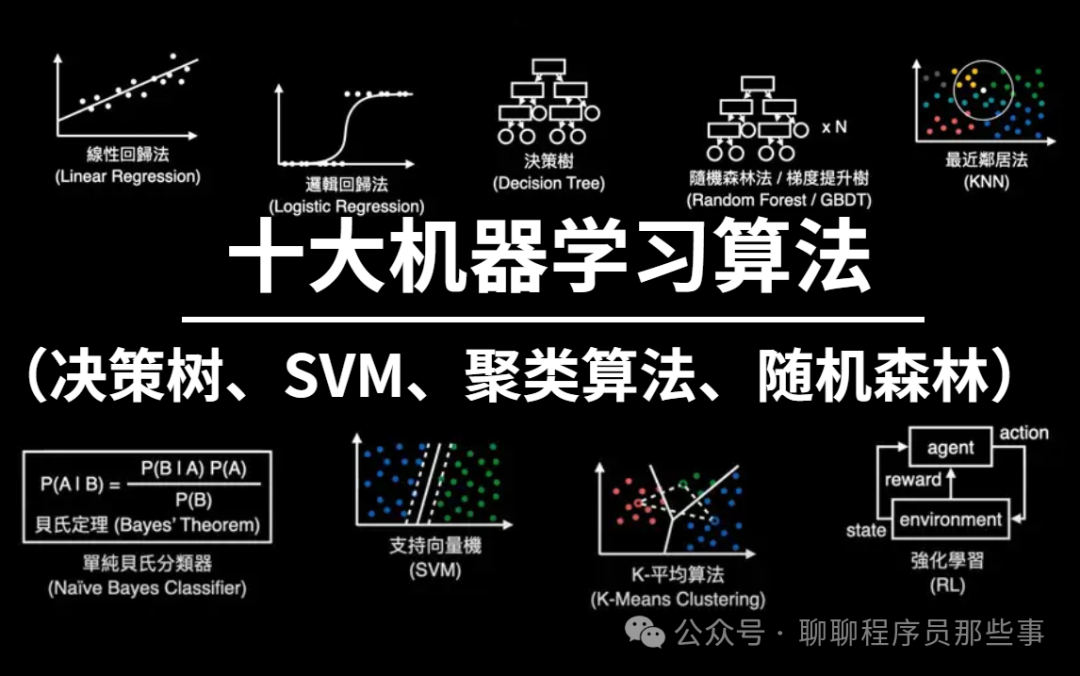
那么,在你心中深度学习的 top10 算法有哪些呢?以下是我心目中的深度学习 top10 算法,这些算法在创新性、应用价值以及影响力等方面都占据着重要的地位。
1、深度神经网络(DNN)
深度神经网络(DNN),又称为多层感知机,是最为普遍的深度学习算法。在发明之初,由于算力瓶颈的限制,它曾饱受质疑。
然而,直到近些年,随着算力的飞速提升以及数据的爆发式增长,深度神经网络才迎来了重大突破。
如今,它在图像识别、自然语言处理等众多领域都展现出了强大的实力。
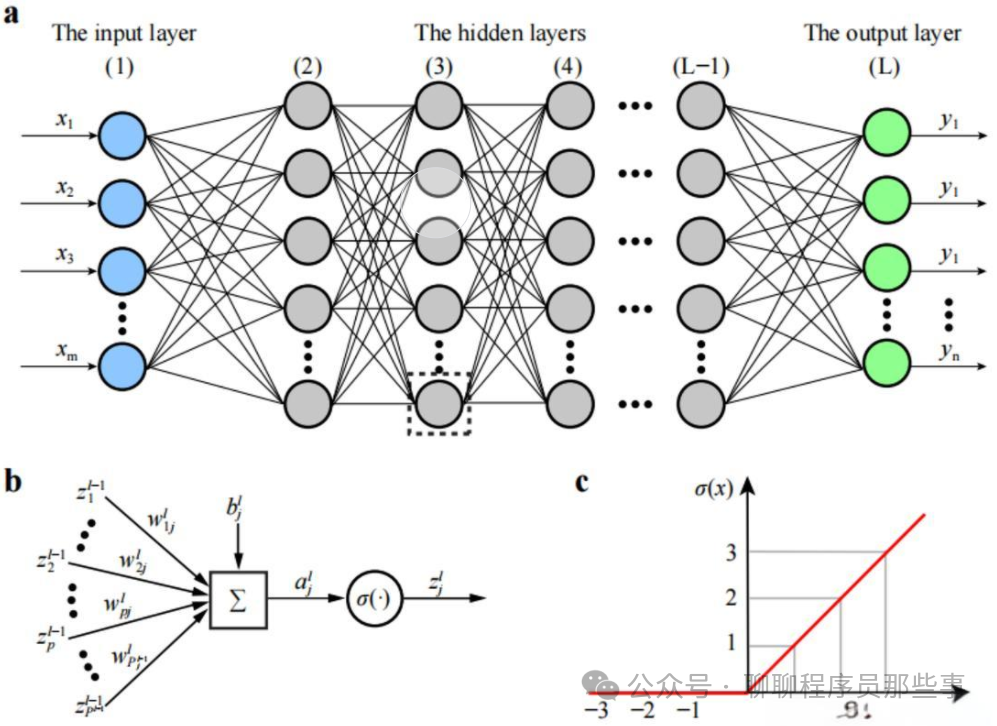
一、模型原理
深度神经网络是一种具有多个隐藏层的人工神经网络。它通过多个神经元组成的层来对输入数据进行逐步抽象和特征提取。每一层的神经元接收上一层的输出作为输入,并通过激活函数进行非线性变换后输出给下一层。通过不断调整神经元之间的连接权重,使得网络能够学习到输入数据与输出目标之间的复杂映射关系。
二、模型训练
通常使用反向传播算法进行训练。首先,给定一组输入数据和对应的目标输出,网络进行前向传播计算出实际输出。然后,根据实际输出与目标输出之间的误差,通过反向传播算法计算出各层连接权重的梯度。接着,使用优化算法(如随机梯度下降)根据梯度更新权重,以减小误差。重复这个过程,直到误差达到一个可接受的水平或者达到预设的训练次数。
三、优点
强大的学习能力:能够学习到非常复杂的函数关系,对大规模数据具有很好的拟合能力。
自动特征提取:可以自动从原始数据中提取有用的特征,减少了人工特征工程的工作量。
通用性:适用于多种任务,如图像识别、语音识别、自然语言处理等。
四、缺点
计算量大:由于具有大量的参数和复杂的结构,训练和推理过程需要大量的计算资源和时间。
过拟合风险:容易对训练数据过度拟合,导致在新数据上的泛化能力不足。
黑箱性:难以解释网络的决策过程,对于一些对可解释性要求高的任务可能不适用。
五、使用场景
图像识别:可以识别图像中的物体、场景等。
语音识别:将语音信号转换为文本。
自然语言处理:如文本分类、机器翻译等任务。
推荐系统:根据用户的行为和偏好进行个性化推荐。
六、Python 示例代码
以下是使用 Keras 库构建一个简单的深度神经网络进行手写数字识别的示例代码:
from keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers import Densefrom keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))train_images = train_images.astype('float32') / 255test_images = test_images.reshape((10000, 28 * 28))test_images = test_images.astype('float32') / 255train_labels = to_categorical(train_labels)test_labels = to_categorical(test_labels)
model = Sequential()model.add(Dense(512, activation='relu', input_shape=(28 * 28,)))model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=128)
test_loss, test_acc = model.evaluate(test_images, test_labels)print('Test accuracy:', test_acc)
这段代码首先加载了 MNIST 手写数字数据集,然后对数据进行预处理,将图像展平并归一化,将标签转换为 one-hot 编码。接着构建了一个包含两个隐藏层的深度神经网络,使用 ReLU 激活函数和 softmax 激活函数分别在隐藏层和输出层。最后编译模型,使用随机梯度下降优化器和交叉熵损失函数进行训练,并在测试集上评估模型的性能。
2、卷积神经网络(CNN)
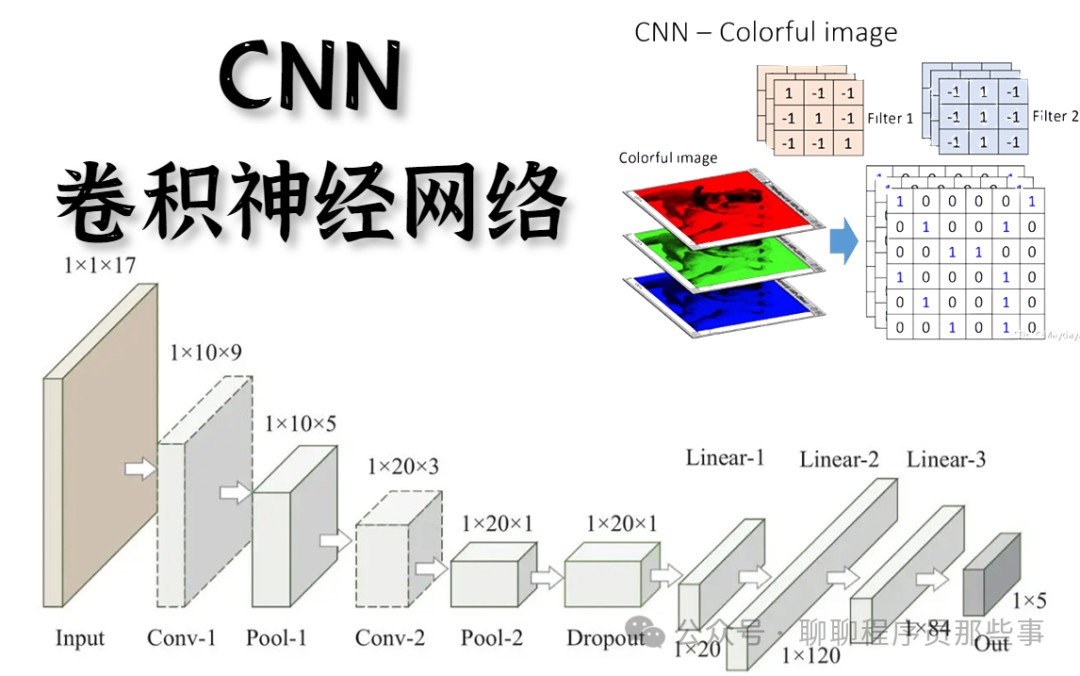
一、模型原理
卷积神经网络主要由卷积层、池化层和全连接层组成。
卷积层通过卷积核与输入数据进行局部连接和权值共享,提取输入的局部特征。卷积核在输入数据上滑动,对每个局部区域进行卷积操作,得到特征图。
池化层通常在卷积层之后,用于降低特征图的空间尺寸,减少参数数量和计算量,同时保留主要特征。常见的池化方法有最大池化和平均池化。
全连接层在网络的最后,将提取到的特征进行整合,输出最终的分类或回归结果。
二、模型训练
准备数据集:收集并整理适合任务的数据集,进行数据预处理,如归一化、数据增强等。
定义网络结构:确定卷积神经网络的层数、卷积核大小、池化方式等参数。
选择损失函数和优化算法:常见的损失函数有交叉熵损失、均方误差等,优化算法如随机梯度下降、Adam 等。
前向传播:将输入数据送入网络,经过卷积、池化和全连接层的计算,得到输出结果。
计算损失:根据输出结果和真实标签计算损失值。
反向传播:根据损失值,通过反向传播算法计算各层参数的梯度。
更新参数:使用优化算法根据梯度更新网络参数。
重复以上步骤,直到达到预设的训练次数或损失收敛。
三、优点
局部连接和权值共享:减少了参数数量,提高了模型的泛化能力。
自动特征提取:能够自动学习到图像、文本等数据的特征,无需手动设计特征。
对平移、旋转和缩放具有一定的不变性:适合处理图像等具有空间结构的数据。
并行计算:卷积和池化操作可以并行计算,提高训练和推理速度。
四、缺点
对数据量要求较高:需要大量的标注数据才能训练出较好的模型。
计算量大:尤其是在训练深度较大的网络时,需要大量的计算资源和时间。
黑箱性:难以解释模型的决策过程。
五、使用场景
图像识别:如物体识别、人脸识别、图像分类等。
视频分析:动作识别、视频分类等。
自然语言处理:文本分类、情感分析等(结合一维卷积)。
六、Python 示例代码
以下是使用 Keras 构建一个简单卷积神经网络进行图像分类的示例:
from keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 加载数据(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 数据预处理train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype('float32') / 255test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype('float32') / 255
# 构建模型model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(Flatten())model.add(Dense(64, activation='relu'))model.add(Dense(10, activation='softmax'))
# 编译模型model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型model.fit(train_images, train_labels, epochs=5, batch_size=64)
# 评估模型test_loss, test_acc = model.evaluate(test_images, test_labels)print('Test accuracy:', test_acc)
这段代码使用 MNIST 数据集训练一个卷积神经网络进行数字分类。首先对数据进行预处理,将图像形状调整为适合卷积神经网络的输入格式,并进行归一化。然后构建了一个包含卷积层、池化层和全连接层的网络结构。最后编译模型并进行训练和评估。
3、残差网络(ResNet)
随着深度学习的迅猛发展,深度神经网络在诸多领域都取得了极为显著的成就。然而,深度神经网络在训练过程中面临着诸如梯度消失以及模型退化等问题,这在很大程度上限制了网络的深度与性能。为有效解决这些难题,残差网络(ResNet)应运而生。
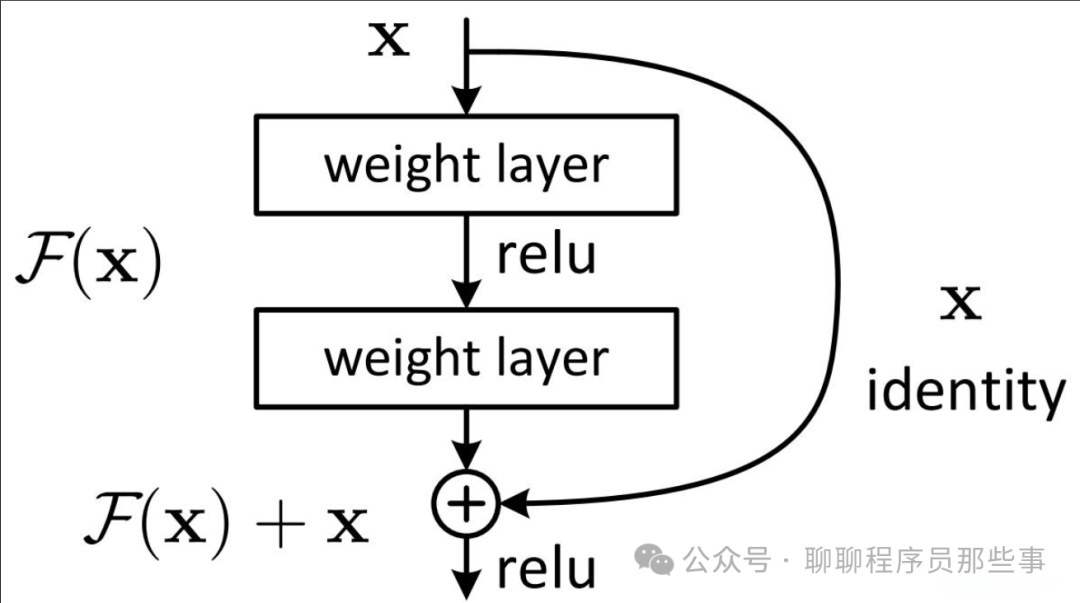
一、模型原理
传统的深度神经网络在层数不断增加时会出现梯度消失或梯度爆炸问题,以及性能退化现象。ResNet 通过引入残差块(residual block)来解决这些问题。
残差块由两部分组成:直接映射和残差映射。直接映射就是输入直接连接到后面的层,残差映射则是通过一些卷积层等操作对输入进行处理得到的结果。最终的输出是直接映射和残差映射的和。这种结构使得网络可以更容易地学习恒等映射,即使网络层数很深也能有效地训练。
二、模型训练
数据准备:同其他网络一样,准备合适的训练数据集并进行预处理。
定义网络结构:构建由多个残差块组成的 ResNet 网络,确定层数、卷积核大小等参数。
选择损失函数和优化算法:例如交叉熵损失和随机梯度下降优化器等。
前向传播:输入数据经过 ResNet 网络的各个层进行计算。
计算损失:根据输出结果与真实标签计算损失值。
反向传播:利用反向传播算法计算各层参数的梯度。
更新参数:使用优化算法更新网络参数。
重复训练过程直到满足停止条件。
三、优点
可以训练非常深的网络:解决了深度网络的性能退化问题,使得能够构建上百层甚至上千层的网络。
高效的训练:残差结构使得梯度更容易在网络中传播,加快了训练速度。
良好的泛化能力:在各种图像分类等任务中表现出优秀的性能。
四、缺点
计算复杂度较高:由于网络较深,计算量相对较大,需要较多的计算资源和时间。
内存占用较大:在训练和推理过程中可能需要较大的内存空间。
五、使用场景
图像分类:在大规模图像分类任务中取得了显著的成果。
目标检测:作为骨干网络用于目标检测算法中。
图像分割:可用于图像分割任务,提取有效的特征。
六、Python 示例代码
以下是使用 Keras 构建一个简单 ResNet 网络进行图像分类的示例:
from keras.layers import Input, Conv2D, BatchNormalization, Activation, Addfrom keras.models import Model
def residual_block(input_tensor, filters, stride=1): x = Conv2D(filters, (3, 3), strides=stride, padding='same')(input_tensor) x = BatchNormalization()(x) x = Activation('relu')(x) x = Conv2D(filters, (3, 3), padding='same')(x) x = BatchNormalization()(x)
shortcut = input_tensor if stride!= 1 or input_tensor.shape[-1]!= filters: shortcut = Conv2D(filters, (1, 1), strides=stride)(shortcut) shortcut = BatchNormalization()(shortcut)
return Activation('relu')(Add()([x, shortcut]))
input_tensor = Input(shape=(28, 28, 1))x = Conv2D(64, (7, 7), strides=2, padding='same')(input_tensor)x = BatchNormalization()(x)x = Activation('relu')(x)x = MaxPooling2D((3, 3), strides=2, padding='same')(x)
x = residual_block(x, 64)x = residual_block(x, 64)x = residual_block(x, 128, stride=2)x = residual_block(x, 128)x = residual_block(x, 256, stride=2)x = residual_block(x, 256)x = residual_block(x, 512, stride=2)x = residual_block(x, 512)
x = AveragePooling2D((7, 7))(x)x = Flatten()(x)output = Dense(10, activation='softmax')(x)
model = Model(input_tensor, output)
这段代码定义了一个残差块函数,并构建了一个简单的 ResNet 网络用于图像分类。可以根据实际需求调整网络结构和参数。
4、LSTM(长短时记忆网络)
在处理序列数据时,传统的循环神经网络(RNN)面临着梯度消失和模型退化等问题,这限制了网络的深度和性能。为了解决这些问题,LSTM被提出。
一、模型原理
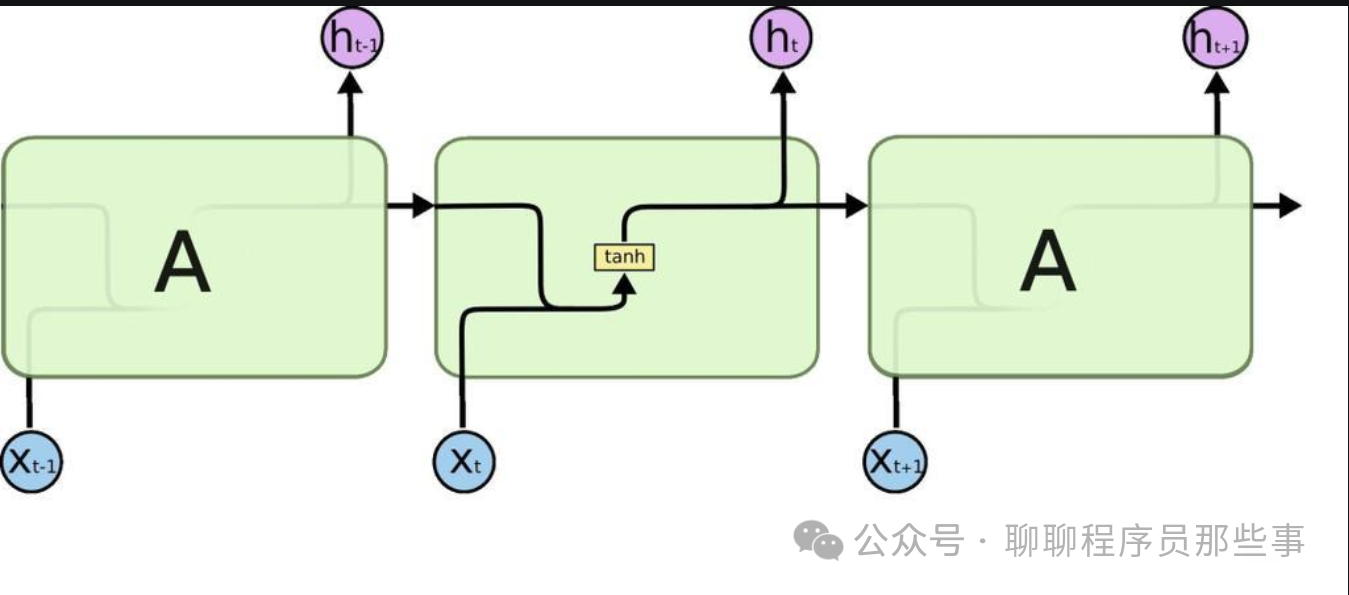
LSTM 是一种特殊的循环神经网络(RNN)结构,主要用于处理序列数据。它通过引入门控机制来控制信息的流动和遗忘,从而有效地解决了传统 RNN 中存在的长期依赖问题。
LSTM 单元主要由三个门和一个记忆单元组成:
输入门(Input Gate):决定当前输入信息有多少被存储到记忆单元中。
遗忘门(Forget Gate):控制记忆单元中信息的遗忘程度。
输出门(Output Gate):决定记忆单元中的信息有多少被输出到当前隐藏状态。
记忆单元(Cell State):用于存储长期信息。
二、模型训练
数据准备:收集和整理序列数据,进行适当的预处理,如归一化等。
定义网络结构:确定 LSTM 的层数、隐藏单元数量等参数。
选择损失函数和优化算法:常见的有交叉熵损失和 Adam 优化器等。
前向传播:将序列数据依次输入 LSTM 网络,计算每个时间步的输出。
计算损失:根据输出结果与真实标签计算损失值。
反向传播:通过反向传播算法计算各参数的梯度。
更新参数:使用优化算法更新网络参数。
重复训练过程直到满足停止条件。
三、优点
能够处理长期依赖:有效地记忆和利用长序列中的信息。
门控机制灵活:可以根据不同的任务和数据自适应地控制信息的流动。
广泛应用:在自然语言处理、时间序列预测等领域表现出色。
四、缺点
计算复杂度较高:由于门控机制和复杂的结构,计算量相对较大。
训练时间较长:尤其是对于大规模数据集和深层网络。
五、使用场景
自然语言处理:如语言建模、机器翻译、文本分类等。
时间序列预测:股票价格预测、气象预测等。
音频处理:语音识别、音乐生成等。
六、Python 示例代码
以下是使用 Keras 构建一个简单 LSTM 网络进行文本分类的示例:
from keras.models import Sequentialfrom keras.layers import Embedding, LSTM, Dense
# 假设已经有了预处理后的文本数据和对应的标签max_features = 20000maxlen = 100
model = Sequential()model.add(Embedding(max_features, 128, input_length=maxlen))model.add(LSTM(128))model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型model.fit(x_train, y_train, epochs=10, batch_size=32)
# 评估模型score = model.evaluate(x_test, y_test)print('Test accuracy:', score[1])
这段代码构建了一个简单的 LSTM 网络用于文本分类。首先使用嵌入层将文本转换为向量表示,然后接入 LSTM 层和全连接层。可以根据实际任务调整网络结构和参数。
5、Word2Vec
Word2Vec模型是表征学习的开山之作。由Google的科学家们开发的一种用于自然语言处理的(浅层)神经网络模型。Word2Vec模型的目标是将每个词向量化为一个固定大小的向量,这样相似的词就可以被映射到相近的向量空间中。
一、模型原理
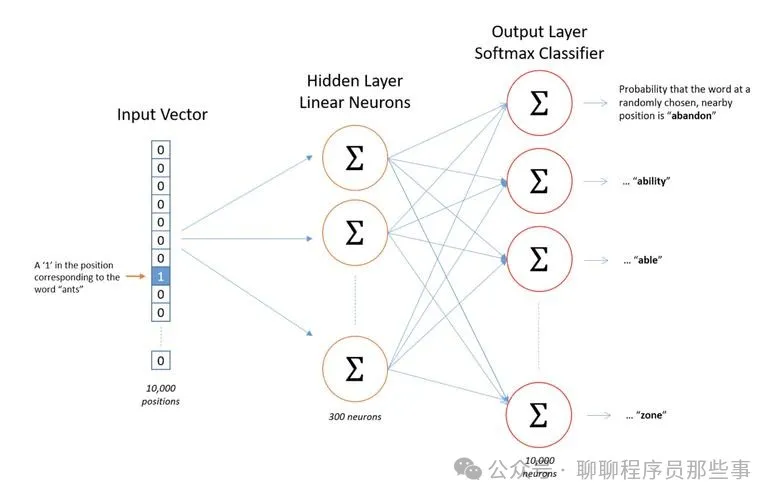
Word2Vec 是一种用于将单词转换为向量表示的技术。它主要有两种模型架构:连续词袋模型(CBOW)和 Skip-gram 模型。
连续词袋模型(CBOW):通过给定周围的上下文单词来预测中心单词。它将上下文单词的向量进行平均或求和等操作,然后通过一个神经网络来预测中心单词。
Skip-gram 模型:与 CBOW 相反,它是通过中心单词来预测周围的上下文单词。
Word2Vec 通过在大规模文本上进行训练,使得具有相似语义的单词在向量空间中距离较近,从而捕捉到单词之间的语义关系。
二、模型训练
数据准备:收集大量的文本数据作为训练语料。
选择模型架构:决定使用 CBOW 还是 Skip-gram 模型。
定义模型参数:如向量维度、窗口大小、训练算法等。
初始化单词向量:随机初始化每个单词的向量表示。
进行训练:根据选择的模型架构和训练算法,通过不断调整单词向量,使得模型能够更好地预测目标单词。
优化模型:使用优化算法如随机梯度下降来最小化损失函数。
重复训练过程直到满足停止条件。
三、优点
高效的词向量表示:能够将单词表示为低维稠密向量,捕捉单词的语义信息。
可扩展性:可以在大规模语料上进行高效训练。
通用性:适用于多种自然语言处理任务,如文本分类、情感分析等。
四、缺点
依赖大规模语料:需要大量的文本数据才能训练出较好的词向量。
静态表示:训练得到的词向量是静态的,不能根据特定的上下文进行动态调整。
五、使用场景
文本分类:将单词向量作为特征输入到分类模型中。
情感分析:利用词向量捕捉文本的情感倾向。
机器翻译:作为源语言和目标语言的单词表示,辅助翻译过程。
信息检索:提高检索的准确性和相关性。
六、Python 示例代
以下是使用 gensim 库训练 Word2Vec 模型的示例:
from gensim.models import Word2Vecfrom nltk.tokenize import word_tokenize
sentences = [word_tokenize(sentence) for sentence in text_data]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
model.save("word2vec.model")
loaded_model = Word2Vec.load("word2vec.model")
vector = loaded_model.wv["word"]
这段代码首先对文本数据进行分词处理,然后使用 Word2Vec 进行训练。可以根据实际需求调整模型参数和训练数据。
6、Transformer
在深度学习的早期发展阶段,卷积神经网络(CNN)于图像识别和自然语言处理等领域斩获了显著的成功。然而,伴随任务复杂度的不断增加,序列到序列(Seq2Seq)模型以及循环神经网络(RNN)逐渐成为处理序列数据的常用手段。尽管 RNN 及其变体在某些特定任务上有着良好的表现,但在处理长序列数据时,它们却容易遭遇梯度消失以及模型退化等问题。为了有效解决这些难题,Transformer 模型应运而生。此后,诸如 GPT、Bert 等大模型皆是基于 Transformer 实现了卓越的性能表现。
一、模型原理
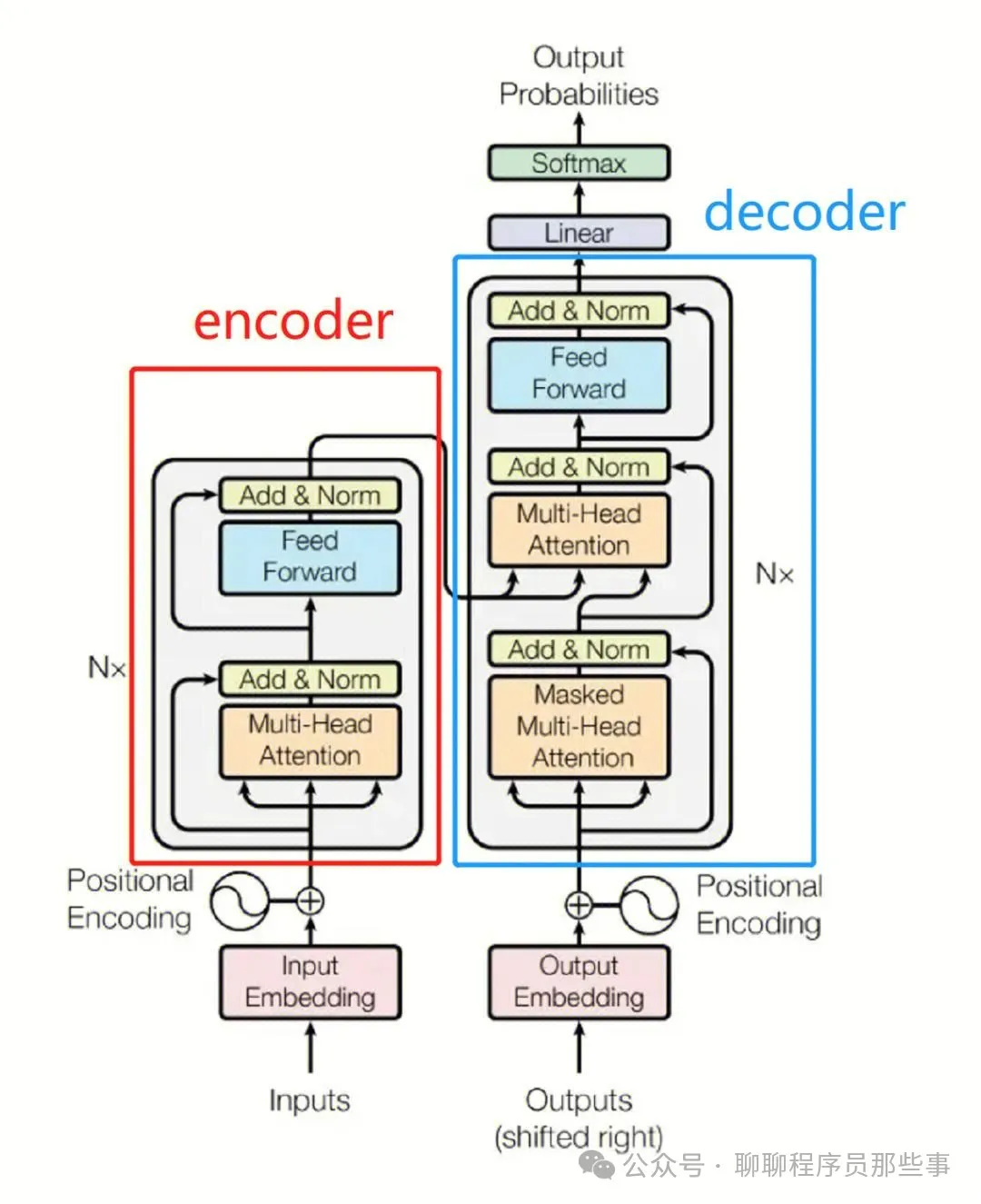
Transformer 是一种基于自注意力机制(self-attention)的深度学习模型,主要用于自然语言处理任务。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)架构,完全依靠注意力机制来对输入序列进行建模。
Transformer 主要由编码器(Encoder)和解码器(Decoder)组成。
编码器:由多个相同的层堆叠而成,每个层包含两个子层,即多头自注意力层和前馈神经网络层。多头自注意力机制允许模型同时关注不同位置的信息,从而更好地捕捉序列中的长距离依赖关系。
解码器:也由多个相同的层堆叠而成,每个层包含三个子层,即多头自注意力层、编码器 - 解码器注意力层和前馈神经网络层。解码器在生成输出序列时,会同时考虑输入序列的信息和已经生成的部分输出序列。
二、模型训练
数据准备:收集和整理适合任务的文本数据,进行预处理,如分词、编码等。
定义模型结构:确定 Transformer 的层数、隐藏单元数量、注意力头数量等参数。
选择损失函数和优化算法:常见的有交叉熵损失和 Adam 优化器等。
前向传播:将输入序列送入编码器,经过多个层的处理后得到编码表示。然后,将编码表示和解码器的初始输入一起送入解码器,逐步生成输出序列。
计算损失:根据输出序列与真实标签计算损失值。
反向传播:通过反向传播算法计算各参数的梯度。
更新参数:使用优化算法更新网络参数。
重复训练过程直到满足停止条件。
三、优点
并行计算:由于不依赖于序列的顺序处理,Transformer 可以充分利用并行计算,大大提高训练和推理速度。
长距离依赖捕捉:通过自注意力机制,能够有效地捕捉长距离的依赖关系。
可扩展性强:可以很容易地扩展到大规模数据和深层网络结构。
四、缺点
对数据量要求高:需要大量的标注数据才能训练出较好的模型。
计算资源消耗大:由于模型结构复杂,训练和推理过程需要大量的计算资源。
五、使用场景
机器翻译:在机器翻译任务中取得了非常好的效果。
文本生成:如文章生成、对话生成等。
语言理解:如文本分类、情感分析等。
六、Python 示例代码
以下是使用 PyTorch 构建一个简单 Transformer 模型进行机器翻译的示例:
import torchimport torch.nn as nnimport torch.optim as optim
# 定义多头注意力机制class MultiHeadAttention(nn.Module): def __init__(self, embed_dim, num_heads): super(MultiHeadAttention, self).__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim
self.q_linear = nn.Linear(embed_dim, embed_dim) self.k_linear = nn.Linear(embed_dim, embed_dim) self
.v_linear = nn.Linear(embed_dim, embed_dim) self.out_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value, mask=None): batch_size = query.size(0)
# 线性变换 q = self.q_linear(query).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_linear(key).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_linear(value).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力权重 scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) attn_weights = torch.softmax(scores, dim=-1)
# 计算注意力输出 attn_output = torch.matmul(attn_weights, v) attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.embed_dim) return self.out_linear(attn_output)
# 定义前馈神经网络class FeedForward(nn.Module): def __init__(self, embed_dim, hidden_dim): super(FeedForward, self).__init__() self.linear1 = nn.Linear(embed_dim, hidden_dim) self.linear2 = nn.Linear(hidden_dim, embed_dim) self.activation = nn.ReLU()
def forward(self, x): return self.linear2(self.activation(self.linear1(x)))
# 定义编码器层class EncoderLayer(nn.Module): def __init__(self, embed_dim, num_heads, hidden_dim): super(EncoderLayer, self).__init__() self.self_attn = MultiHeadAttention(embed_dim, num_heads) self.feed_forward = FeedForward(embed_dim, hidden_dim) self.layernorm1 = nn.LayerNorm(embed_dim) self.layernorm2 = nn.LayerNorm(embed_dim)
def forward(self, x, mask=None): attn_output = self.self_attn(x, x, x, mask) x = self.layernorm1(x + attn_output) ff_output = self.feed_forward(x) return self.layernorm2(x + ff_output)
# 定义编码器class Encoder(nn.Module): def __init__(self, vocab_size, embed_dim, num_layers, num_heads, hidden_dim): super(Encoder, self).__init__() self.embed = nn.Embedding(vocab_size, embed_dim) self.layers = nn.ModuleList([EncoderLayer(embed_dim, num_heads, hidden_dim) for _ in range(num_layers)])
def forward(self, x, mask=None): x = self.embed(x) for layer in self.layers: x = layer(x, mask) return x
# 定义解码器层class DecoderLayer(nn.Module): def __init__(self, embed_dim, num_heads, hidden_dim): super(DecoderLayer, self).__init__() self.self_attn = MultiHeadAttention(embed_dim, num_heads) self.enc_dec_attn = MultiHeadAttention(embed_dim, num_heads) self
.feed_forward = FeedForward(embed_dim, hidden_dim) self.layernorm1 = nn.LayerNorm(embed_dim) self.layernorm2 = nn.LayerNorm(embed_dim) self.layernorm3 = nn.LayerNorm(embed_dim)
def forward(self, x, enc_output, self_mask=None, enc_mask=None): attn_output = self.self_attn(x, x, x, self_mask) x = self.layernorm1(x + attn_output) attn_output = self.enc_dec_attn(x, enc_output, enc_output, enc_mask) x = self.layernorm2(x + attn_output) ff_output = self.feed_forward(x) return self.layernorm3(x + ff_output)
# 定义解码器class Decoder(nn.Module): def __init__(self, vocab_size, embed_dim, num_layers, num_heads, hidden_dim): super(Decoder, self).__init__() self.embed = nn.Embedding(vocab_size, embed_dim) self.layers = nn.ModuleList([DecoderLayer(embed_dim, num_heads, hidden_dim) for _ in range(num_layers)]) self.linear = nn.Linear(embed_dim, vocab_size)
def forward(self, x, enc_output, self_mask=None, enc_mask=None): x = self.embed(x) for layer in self.layers: x = layer(x, enc_output, self_mask, enc_mask) return self.linear(x)
# 定义 Transformer 模型class Transformer(nn.Module): def __init__(self, src_vocab_size, tgt_vocab_size, embed_dim, num_layers, num_heads, hidden_dim): super(Transformer, self).__init__() self.encoder = Encoder(src_vocab_size, embed_dim, num_layers, num_heads, hidden_dim) self.decoder = Decoder(tgt_vocab_size, embed_dim, num_layers, num_heads, hidden_dim)
def forward(self, src, tgt, src_mask=None, tgt_mask=None): enc_output = self.encoder(src, src_mask) dec_output = self.decoder(tgt, enc_output, tgt_mask, src_mask) return dec_output
# 训练模型def train(model, optimizer, criterion, src_data, tgt_data, batch_size, num_epochs): model.train() for epoch in range(num_epochs): total_loss = 0 num_batches = len(src_data) for i in range(0, len(src_data), batch_size): src = src_data[i:i + batch_size] tgt = tgt_data[i:i + batch_size] optimizer.zero_grad() src_mask = (src!= 0).unsqueeze(1).unsqueeze(2) tgt_mask = (tgt!= 0).unsqueeze(1).unsqueeze(2) output = model(src, tgt, src_mask, tgt_mask) loss = criterion(output.view(-1, output.size(-1)), tgt.view(-1)) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch + 1}, Loss: {total_loss / num_batches}")
# 示例用法src_vocab_size = 1000tgt_vocab_size = 1000embed_dim = 512num_layers = 6num_heads = 8hidden_dim = 2048batch_size = 64num_epochs = 10
model = Transformer(src_vocab_size, tgt_vocab_size, embed_dim, num_layers, num_heads, hidden_dim)optimizer = optim.Adam(model.parameters(), lr=0.0001)criterion = nn.CrossEntropyLoss(ignore_index=0)
# 假设已经有了源语言和目标语言的数据集src_data = torch.randint(1, src_vocab_size, (1000, 20))tgt_data = torch.randint(1
, tgt_vocab_size, (1000, 20))
train(model, optimizer, criterion, src_data, tgt_data, batch_size, num_epochs)
这段代码构建了一个简单的 Transformer 模型用于机器翻译任务。可以根据实际需求调整模型参数和数据集。
7、生成对抗网络(GAN)
GAN(生成对抗网络)的思想源自博弈论中的零和游戏。在这个游戏中,一个玩家致力于生成最为逼真的假数据,而另一个玩家则尝试区分真实数据与假数据。GAN是由蒙提霍尔问题演变而来,不过与蒙提霍尔问题有所不同,GAN并不着重于逼近某些概率分布或者生成某种特定样本,而是直接采用生成模型与判别模型进行对抗。
一、模型原理
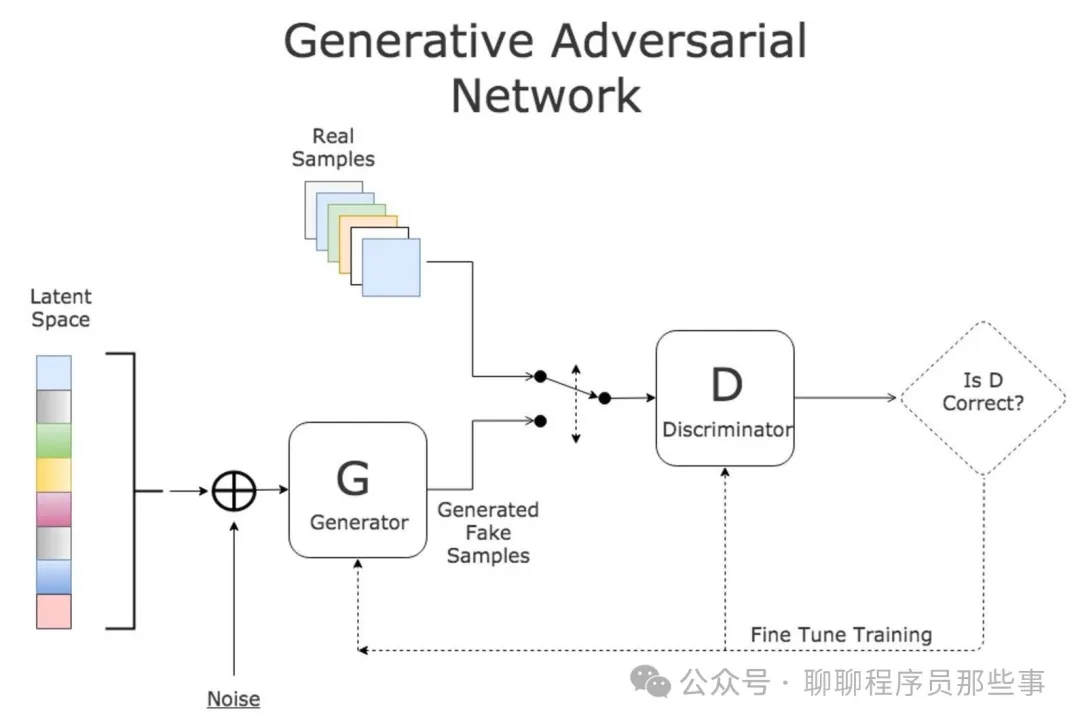
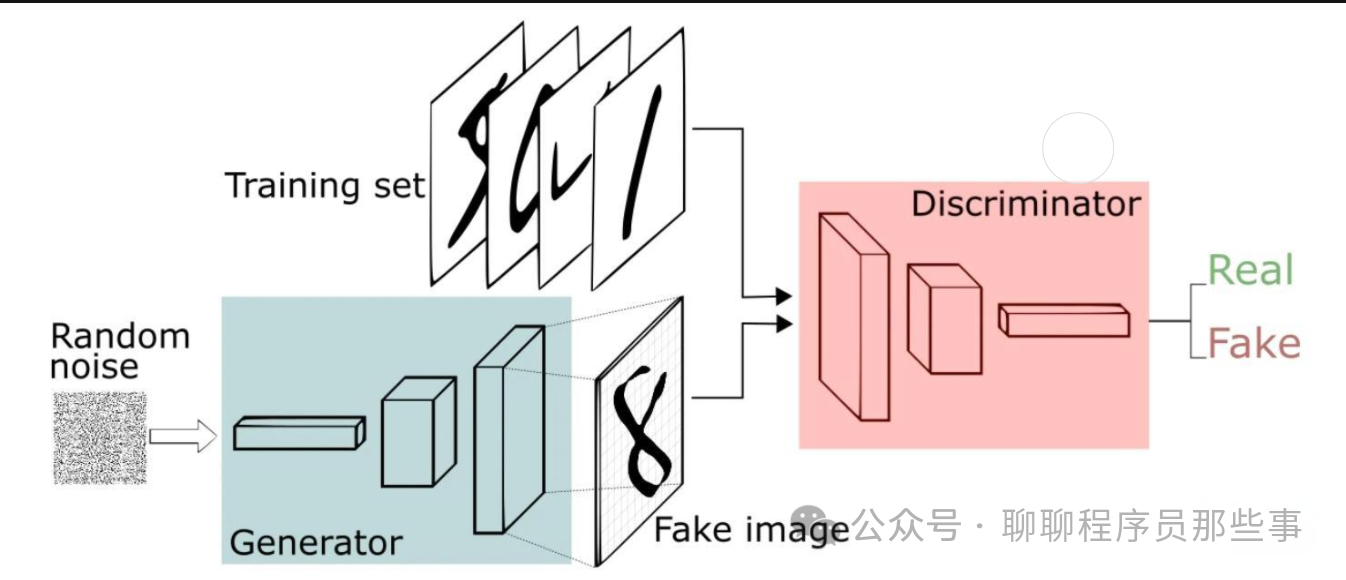
生成对抗网络由生成器(Generator)和判别器(Discriminator)组成。
生成器的任务是生成尽可能逼真的假样本,试图欺骗判别器。它接收一个随机噪声向量作为输入,通过一系列的神经网络层将其映射为一个看似真实的样本,例如生成逼真的图像、音频等。
判别器则负责区分输入的样本是来自真实数据还是由生成器生成的假数据。它接收一个样本作为输入,经过一系列的神经网络层后输出一个概率值,表示该样本为真实样本的可能性。
在训练过程中,生成器和判别器进行对抗性的博弈。生成器努力提高生成样本的质量,使得判别器难以区分真假;判别器则不断提升自己的鉴别能力,以更好地识别真实样本和假样本。通过这种对抗训练,双方的性能不断提升,最终达到一种平衡状态。
二、模型训练
数据准备:收集真实数据作为训练的基础。
初始化生成器和判别器:随机初始化它们的参数。
交替训练:
从真实数据集中抽取一批真实样本,输入判别器,计算其对真实样本的输出概率。
生成一批假样本,由生成器根据随机噪声生成,输入判别器,计算其对假样本的输出概率。
根据真实样本的标签(通常为 1,表示真实)和假样本的标签(通常为 0,表示假),计算判别器的损失函数。
使用优化算法(如随机梯度下降)更新判别器的参数,以提高其鉴别能力。
重复上述步骤,直到达到预定的训练次数或满足其他停止条件。
三、优点
能够生成高质量的样本:经过充分训练后,生成器可以生成非常逼真的样本,在图像、音频等领域有广泛的应用。
无需大量标注数据:与监督学习相比,GAN 可以在没有明确标注的情况下进行训练,只需要真实数据即可。
具有创造性:可以生成具有新颖性和创造性的样本,为艺术创作、数据增强等提供了新的思路。
四、缺点
训练不稳定:GAN 的训练过程可能不稳定,容易出现模式崩溃(生成器只生成少数几种模式的样本)或梯度消失等问题。
难以评估:很难确定生成器生成的样本的质量,缺乏明确的评估指标。
计算资源需求大:训练 GAN 通常需要大量的计算资源,尤其是对于复杂的任务和大规模的数据集。
五、使用场景
图像生成:生成逼真的图像,如艺术创作、数据增强等。
音频生成:合成新的音频片段。
视频生成:生成视频序列。
数据增强:为机器学习任务提供更多的训练数据。
六、Python 示例代码
以下是使用 PyTorch 构建一个简单 GAN 进行图像生成的示例:
import torchimport torch.nn as nnimport torch.optim as optimimport torchvisionimport torchvision.transforms as transformsimport numpy as npimport matplotlib.pyplot as plt
class Generator(nn.Module): def __init__(self, latent_dim, img_shape): super(Generator, self).__init__() self.img_shape = img_shape self.model = nn.Sequential( nn.Linear(latent_dim, 128), nn.LeakyReLU(0.2), nn.Linear(128, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2), nn.Linear(256, 512), nn.BatchNorm1d(512), nn.LeakyReLU(0.2),
nn.Linear(512, np.prod(img_shape)), nn.Tanh() )
def forward(self, z): img = self.model(z) img = img.view(img.size(0), *self.img_shape) return img
class Discriminator(nn.Module): def __init__(self, img_shape): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(np.prod(img_shape), 512), nn.LeakyReLU(0.2), nn.Linear(512, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1), nn.Sigmoid() )
def forward(self, img): img_flat = img.view(img.size(0), -1) validity = self.model(img_flat) return validity
latent_dim = 100batch_size = 64num_epochs = 200lr = 0.0002
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
img_shape = (1, 28, 28)generator = Generator(latent_dim, img_shape)discriminator = Discriminator(img_shape)
adversarial_loss = nn.BCELoss()optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
for epoch in range(num_epochs): for i, (imgs, _) in enumerate(dataloader): batch_size = imgs.size(0)
real_imgs = imgs.cuda() valid = torch.ones(batch_size, 1).cuda() fake = torch.zeros(batch_size, 1).cuda()
real_loss = adversarial_loss(discriminator(real_imgs), valid)
z = torch.randn(batch_size, latent_dim).cuda() fake_imgs = generator(z)
fake_loss = adversarial_loss(discriminator(fake_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
discriminator.zero_grad() d_loss.backward() optimizer_D.step()
z = torch.randn(batch_size, latent_dim).cuda() fake_imgs = generator(z) valid = torch.ones(batch_size, 1).cuda()
g_loss = adversarial_loss(discriminator(fake_imgs), valid)
generator.zero_grad() g_loss.backward() optimizer_G.step()
if
epoch % 10 == 0: print(f"Epoch [{epoch}/{num_epochs}], D_loss: {d_loss.item()}, G_loss: {g_loss.item()}")
z = torch.randn(64, latent_dim).cuda()fake_imgs = generator(z).detach().cpu()fig, axs = plt.subplots(8, 8, figsize=(8, 8))for i in range(8): for j in range(8): axs[i, j].imshow(fake_imgs[i * 8 + j].reshape(28, 28), cmap='gray') axs[i, j].axis('off')plt.show()
这段代码使用 MNIST 数据集训练一个简单的 GAN 来生成手写数字图像。可以根据实际需求调整模型结构和参数
8、Diffusion扩散模型
Diffusion 模型是一种基于深度学习的生成模型。它主要被用于生成连续数据,例如图像、音频等。Diffusion 模型的核心思想在于,通过逐步添加噪声的方式,将复杂的数据分布转化为简单的高斯分布。而后,再通过逐步去除噪声,从这一简单分布中生成所需的数据。
一、模型原理
Diffusion 扩散模型是一种生成模型,其基本思想是通过逐步添加噪声来破坏原始数据,然后学习从噪声分布中恢复原始数据的逆过程。
具体来说,扩散模型包含两个过程:前向扩散过程和反向扩散过程。
前向扩散过程:
反向扩散过程:
二、模型训练
数据准备:准备用于训练的数据集。
定义模型结构:构建用于反向扩散过程的神经网络,通常是一个深度神经网络,如 U-Net 结构。
前向扩散:对训练数据进行前向扩散,得到不同时间步的噪声版本的数据。
训练反向扩散网络:
对于每个时间步,输入当前的噪声数据,让网络预测如何去除一部分噪声以接近上一个时间步的数据。
使用损失函数(通常是均方误差或其他适当的损失)来衡量网络预测与真实的前向扩散过程之间的差异。
通过优化算法(如 Adam 等)更新网络参数,以最小化损失。
重复训练过程直到模型收敛。
三、优点
高质量生成:能够生成非常高质量的样本,在图像生成等任务中表现出色。
理论基础扎实:有较为严格的数学理论基础,有助于理解和分析模型的行为。
灵活性:可以适用于不同类型的数据和任务。
四、缺点
训练时间较长:由于需要进行多个时间步的扩散和逆扩散过程,训练通常比较耗时。
计算资源需求大:特别是对于高分辨率图像等大规模数据,需要大量的计算资源。
五、使用场景
图像生成:生成逼真的图像,包括艺术创作、数据增强等。
音频生成:合成高质量的音频片段。
视频生成:生成连续的视频序列。
六、Python 示例代码
以下是一个简单的 Diffusion 模型用于图像生成的示例代码(使用 PyTorch 实现,仅为示意,实际应用中需要更多的优化和调整):
import torchimport torch.nn as nnimport torch.optim as optimimport torchvisionimport torchvision.transforms as transforms
class UNet(nn.Module): def __init__(self): super(UNet, self).__init__() self.conv1 = nn.Conv2d(3, 64
, kernel_size=3, padding=1)
def forward(self, x, t): return x
batch_size = 64num_epochs = 100lr = 0.001
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = UNet()
criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs): for images, _ in dataloader: noisy_images = images + torch.randn_like(images)
t = torch.randint(0, num_steps, (batch_size,)).long()
predicted_images = model(noisy_images, t)
loss = criterion(predicted_images, images)
optimizer.zero_grad() loss.backward() optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
with torch.no_grad(): noise = torch.randn(1, 3, 32, 32) generated_image = model(noise, torch.tensor(num_steps - 1).long()) generated_image = (generated_image + 1) / 2 import matplotlib.pyplot as plt plt.imshow(generated_image[0].permute(1, 2, 0)) plt.show()
这段代码展示了一个简单的 Diffusion 模型的训练和生成过程。在实际应用中,需要更复杂的网络结构和更精细的训练策略。
9、图神经网络(GNN)
图神经网络(Graph Neural Networks,简称 GNN)是一类专门用于处理图结构数据的深度学习模型。在现实世界里,众多复杂系统都能够用图来进行表示,诸如社交网络、分子结构、交通网络等等。传统的机器学习模型在处理这些图结构数据时会面临诸多挑战,而图神经网络则为解决这些问题提供了全新的思路。
一、模型原理
图神经网络是一类专门用于处理图结构数据的神经网络。它的核心思想是通过在图的节点和边上传播和聚合信息,从而学习到图的特征表示。
在图中,每个节点都有其自身的特征向量,边也可以有相应的特征。GNN 通过多个传播步骤来更新节点的特征表示,使得节点能够融合来自其邻居节点的信息。
常见的 GNN 架构包括图卷积网络(GCN)、图注意力网络(GAT)等。以 GCN 为例,它通过对节点的邻居进行卷积操作来更新节点的特征。在每一层中,节点的特征会与邻居节点的特征进行加权求和,权重通常由图的结构和节点之间的关系决定。
二、模型训练
数据准备:收集具有图结构的数据集,包括节点特征和图的连接关系(边)。
定义模型结构:选择合适的 GNN 架构,如 GCN、GAT 等,并确定网络的层数、隐藏单元数量等参数。
定义损失函数:根据具体任务选择合适的损失函数,例如在节点分类任务中可以使用交叉熵损失。
前向传播:将图数据输入到 GNN 中,通过多个传播步骤更新节点的特征表示。
计算损失:根据输出结果和真实标签计算损失值。
反向传播:通过反向传播算法计算各参数的梯度。
更新参数:使用优化算法(如随机梯度下降)更新网络参数。
重复训练过程直到满足停止条件。
三、优点
强大的图数据处理能力:能够有效地处理各种类型的图结构数据,包括社交网络、分子结构等。
利用图的结构信息:可以充分利用图的连接关系来学习节点和边的特征表示。
可扩展性:可以处理大规模的图数据,并且可以很容易地与其他深度学习模型结合。
四、缺点
计算复杂度较高:由于需要在图上进行传播和聚合操作,计算量相对较大,特别是对于大规模图。
对图的结构敏感:图的结构变化可能会对模型的性能产生较大影响。
五、使用场景
社交网络分析:节点分类、链接预测等任务。
生物信息学:蛋白质结构预测、药物发现等。
推荐系统:利用用户和物品之间的关系图进行推荐。
交通网络分析:预测交通流量、路径规划等。
六、Python 示例代码
以下是使用 PyTorch Geometric 库构建一个简单的图卷积网络(GCN)进行节点分类的示例:
import torchimport torch.nn.functional as Ffrom torch_geometric.nn import GCNConvfrom torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data', name='Cora')data = dataset[0]
class GCN(torch.nn.Module): def __init__(self): super(GCN, self).__init__() self.conv1 = GCNConv(dataset.num_node_features, 16) self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, x, edge_index): x = self.conv1(x, edge_index) x = F.relu(x) x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = GCN().to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()for epoch in range(200): optimizer.zero_grad() out = model(data.x.to(device), data.edge_index.to(device)) loss = F.nll_loss(out[data.train_mask].to(device), data.y[data.train_mask].to(device)) loss.backward() optimizer.step()
model.eval()_, pred = model(data.x.to(device), data.edge_index.to(device)).max(dim=1)correct = float(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())acc = correct / data.test_mask.sum().item()print(f'Test Accuracy: {acc:.4f}')
这段代码使用 PyTorch Geometric 库构建了一个简单的 GCN 模型,并在 Cora 数据集上进行节点分类任务。可以根据实际需求调整模型结构和参数。
10、深度Q网络(DQN)
在传统的强化学习算法中,智能体通过一个 Q 表来存储状态 - 动作值函数的估计。但是,这种方法在应对高维度的状态和动作空间时会遭遇限制。为了解决这个问题,DQN(深度 Q 网络)作为一种深度强化学习算法被提出,它引入了深度学习技术来学习状态 - 动作值函数的逼近,进而能够处理更为复杂的问题。
一、模型原理
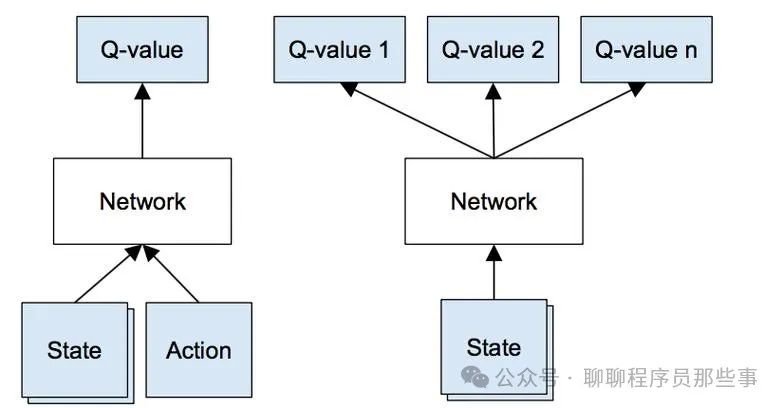
深度 Q 网络是一种结合了深度学习和强化学习的算法,主要用于解决强化学习中的决策问题。其核心思想是使用深度神经网络来近似表示动作价值函数(Q 函数)。
传统的 Q 学习算法使用表格来存储每个状态 - 动作对的 Q 值,但在状态空间和动作空间较大时,这种方法变得不可行。DQN 利用深度神经网络的强大表示能力,将状态作为输入,输出每个可能动作的 Q 值估计。
DQN 通过与环境进行交互,收集经验数据(状态、动作、奖励、下一个状态),并使用这些数据来训练神经网络,以最小化预测的 Q 值与目标 Q 值之间的误差。
二、模型训练
初始化网络和经验回放缓冲区:
创建深度神经网络作为 Q 函数的近似器。
初始化一个经验回放缓冲区,用于存储与环境交互的经验数据。
与环境交互:
智能体根据当前策略选择一个动作,并在环境中执行该动作。
观察环境的反馈,包括奖励和下一个状态。
将(当前状态、动作、奖励、下一个状态)存储到经验回放缓冲区中。
从经验回放缓冲区中采样数据:
随机从经验回放缓冲区中抽取一批经验数据。
计算目标 Q 值:
对于每个采样的经验数据,根据下一个状态计算目标 Q 值。通常使用贝尔曼方程来计算目标 Q 值。
训练网络:
使用均方误差损失函数,计算预测 Q 值与目标 Q 值之间的误差。
通过反向传播算法更新神经网络的参数,以最小化损失。
定期更新目标网络:
为了提高训练的稳定性,定期将当前网络的参数复制到一个目标网络中。
重复以上步骤,直到达到停止条件。
三、优点
能够处理高维状态空间:利用深度神经网络可以有效地处理大规模的状态空间,适用于复杂的环境。
学习能力强:通过与环境的交互和经验回放,可以不断学习和改进策略。
通用性:可以应用于各种强化学习任务,如游戏、机器人控制等。
四、缺点
训练不稳定:在训练过程中可能会出现不稳定的情况,例如 Q 值的波动较大。
对超参数敏感:训练结果对超参数的选择比较敏感,需要进行仔细的调参。
计算资源需求大:训练深度神经网络需要大量的计算资源。
五、使用场景
游戏:如 Atari 游戏等,智能体通过学习来掌握游戏策略。
机器人控制:训练机器人在复杂环境中执行任务。
自动驾驶:优化自动驾驶车辆的决策策略。
六、Python 示例代码
以下是一个使用 PyTorch 实现的简单 DQN 算法示例,用于解决一个简单的强化学习问题:
import torchimport torch.nn as nnimport torch.optim as optimimport numpy as np
class QNetwork(nn.Module): def __init__(self, state_size, action_size): super(QNetwork, self).__init__() self.fc1 = nn.Linear(state_size, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, action_size)
def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) return self.fc3(x)
class DQN: def __init__(self, state_size, action_size, gamma=0.99, learning_rate=0.001): self.q_network = QNetwork(state_size, action_size).to('cuda' if torch.cuda.is_available() else 'cpu') self.target_network = QNetwork(state_size, action_size).to('cuda' if torch.cuda.is_available() else 'cpu') self.target_network.load_state_dict(self.q_network.state_dict()) self.optimizer = optim.Adam(self.q_network.parameters(), lr=learning_rate) self.gamma = gamma self.memory = [] self.action_size = action_size
def act(self, state, epsilon): if np.random.rand() < epsilon: return np.random.choice(self.action_size) state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to('cuda' if torch.cuda.is_available() else 'cpu') return torch.argmax(self.q_network(state)).item()
def remember(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done))
def replay(self, batch_size): if len(self.memory) < batch_size: return minibatch = np.random.choice(len(self.memory), batch_size, replace=False) states, actions, rewards, next_states, dones = zip(*[self.memory[i] for i in minibatch]) states = torch.tensor(states, dtype=torch.float32).to('cuda' if torch.cuda.is_available() else 'cpu') actions = torch.tensor(actions, dtype=torch.long).unsqueeze(1).to('cuda' if torch.cuda.is_available() else 'cpu') rewards = torch.tensor(rewards, dtype=torch.float32).unsqueeze(1).to('cuda' if torch.cuda.is_available() else 'cpu') next_states = torch.tensor(next_states, dtype=torch.float32).to('cuda' if torch.cuda.is_available() else 'cpu') dones = torch.tensor(dones, dtype=torch.float32).unsqueeze(1).to('cuda' if
torch.cuda.is_available() else 'cpu')
q_targets_next = self.target_network(next_states).detach().max(1)[0].unsqueeze(1) q_targets = rewards + self.gamma * q_targets_next * (1 - dones) q_expected = self.q_network(states).gather(1, actions)
loss = nn.MSELoss()(q_expected, q_targets) self.optimizer.zero_grad() loss.backward() self.optimizer.step()
def update_target_network(self): self.target_network.load_state_dict(self.q_network.state_dict())
state_size = 4action_size = 2dqn = DQN(state_size, action_size)epsilon = 1.0epsilon_decay = 0.995epsilon_min = 0.01for episode in range(1000): state = np.random.randn(state_size) done = False while not done: action = dqn.act(state, epsilon) next_state = np.random.randn(state_size) reward = np.random.randn() done = np.random.choice([True, False]) dqn.remember(state, action, reward, next_state, done) state = next_state if len(dqn.memory) > 32: dqn.replay(32) epsilon = max(epsilon_min, epsilon * epsilon_decay) if episode % 10 == 0: dqn.update_target_network()
这段代码实现了一个简单的 DQN 算法,用于解决一个具有连续状态空间和离散动作空间的强化学习问题。可以根据实际任务调整网络结构和超参数。
转自“聊聊程序员那些事”公众号
转载此文章仅以传播知识为目的,如有任何版权问题请及时联系我们!





