

多年来,以 Elasticsearch 为代表的基于全文检索的搜索方案,一直是搜索和推荐引擎等信息检索系统的默认选择。但传统的全文搜索只能提供基于关键字匹配的精确结果,例如找到包含特殊名词“Python3.9”的文档,或是找到带“花”字,“雨”字,“雪”字的古诗词。
但在实际需求中,我们有时候需要的,不只是古诗词中带“雪”字,还要找到表示雪很大这样意向的古诗词。比如,初高中语文课里学到的“忽如一夜春风来,千树万树梨花开”这句诗,虽然没有雪字,却精准表达了雪很大这样的意向。
再以照片检索为例,我们不仅需要 1:1 精准搜索出图像对应的原图,往往也需要对图像的特征、关键信息提取后,去检索具备类似特征的图像,完成以图搜图或者内容推荐等任务。
如何通过检索得到以上结果?
基于稠密向量打造的语义搜索就发挥了作用。通常来说,语义检索,通过将我们输入的词汇、图片、语音等原始数据转化为向量,进而捕捉不同数据之间的语义关系(例如知道“老师”和“教师”其实是一个意思),可以更精准的理解用户的搜索意图,从而提供更准确、更相关的搜索结果。
但如何实现语义检索?Embedding 模型和向量数据库在其中的作用至关重要。前者主要完成原始信息的向量化,后者则提供对向量化信息的存储、检索等服务。目前,检索增强生成(RAG)与多模态搜索,是语义检索的核心应用场景之一。
但通常来说,在实践中,全文检索与语义检索不是非此即彼的关系。我们需要同时兼顾语义理解和精确的关键字匹配。比如学术论文的写作中,用户不仅希望在搜索结果看到与搜索查询相关的概念,同时也希望保留查询中使用的原始信息返回搜索结果,比如基于一些特殊术语和名称。
因此,许多搜索应用正在采用混合搜索方法,结合两种方法的优势,以平衡灵活的语义相关性和可预测的精确关键字匹配。
实现混合搜索的常见方法如下:
先使用像开源 Milvus 这样的专用向量数据库,进行高效和可扩展的语义搜索;
然后使用像 Elasticsearch 或 OpenSearch 这样的传统搜索引擎进行全文搜索。
两两搭配虽然效果不错,但也引入了新的复杂性:首先,搭配两套不同的搜索系统,也就意味着我们要同时管理不同的基础设施、配置和维护任务。这会造成更重的运营负担并增加潜在的集成问题。
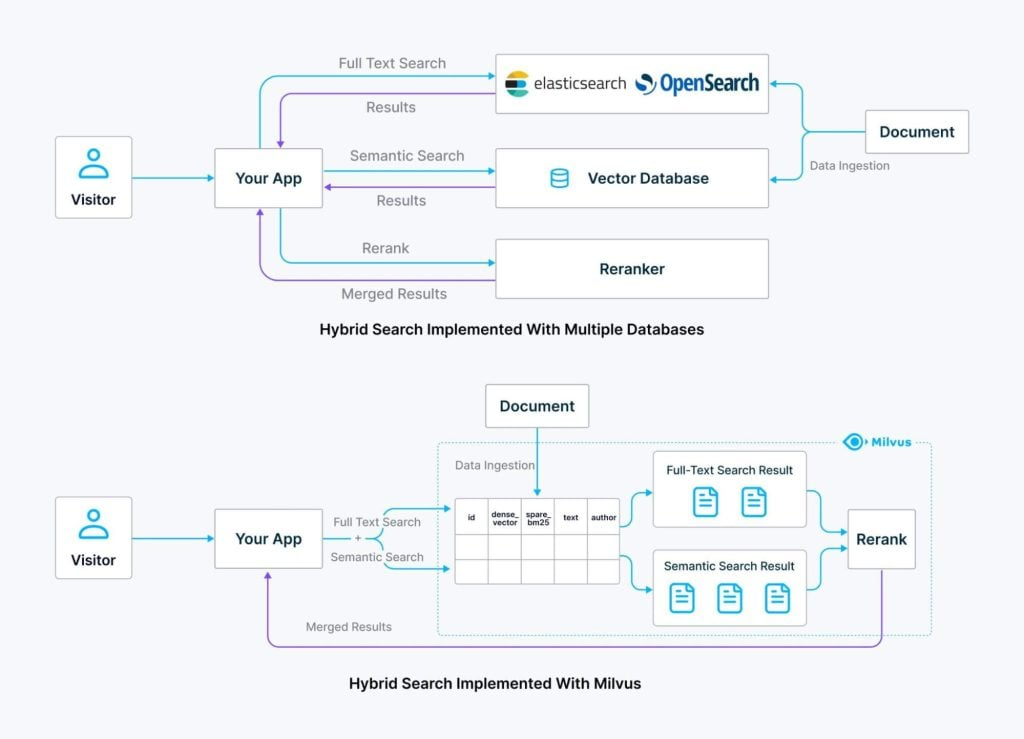
在此基础上,混合检索统一解决方案横空出世。
混合搜索的统一解决方案将提供许多好处:
减少基础设施维护: 管理一个系统而不是两个系统大大降低了操作复杂性,节省了时间和资源。这也意味着更少的上下文切换和掌握两组不同 API 的算力开销。
合并数据管理: 统一的表结构允许用户将密集(基于向量)和稀疏(基于关键字)数据与共享元数据标签一起存储。使用两个单独的系统,则需要将元数据标签存储两次,以便双方能够进行元数据过滤。
简化查询:单个请求可以执行语义和全文搜索任务,无需对单独的系统进行两次 API 调用。
增强的安全性和权限改造:统一的方法可以实现更直接和更强大的安全管理,因为所有访问控制都可以在向量数据库中集中管理,从而提高安全性合规性和一致性。
在语义搜索中,机器学习模型会根据文本的含义将文本“嵌入”为高维空间中的点(称为密集向量) 。具有相似语义的文本在此空间中,彼此的距离会更接近。例如,“苹果”和“水果”就比“苹果”和“汽车”更接近。这使得我们能够通过使用近似最近邻 (ANN) 算法计算每个点之间的距离来快速找到语义相关的文本。
这种方法也可以通过将文档和查询编码为稀疏向量,进而应用于全文搜索。
在稀疏向量中,每个维度代表一个术语,值表示每个术语在文档中的重要性。
文档中不存在的术语的值为零。由于任何给定的文档通常只使用词汇表中所有可能术语的一小部分,因此,大多数术语不会出现在文档中。这也就意味着生成的向量是稀疏的——因为它们的大多数值为零。例如,在通常用于评估信息检索任务的 MS-MARCO 数据集中,虽然大约有 900 万个文档,100 万个词,但大多数文档只覆盖不足几百个词,生成的向量中绝大多数维度值为零。
这种极端稀疏性对于我们高效存储和处理这些向量具有重要意义。比如,我们可以将其用于优化搜索性能,同时保持准确性。
最初为密集向量设计的向量数据库,其实也可以高效处理这些稀疏向量。例如,开源向量数据库 Milvus 刚刚发布了使用 Sparse-BM25 的原生全文搜索功能。
Sparse-BM25 由 Milvus 提出,其原理类似 Elasticsearch 和其他全文搜索系统中常用的 BM25 算法,但针对稀疏向量设计,可以实现相同效果的全文搜索功能:
除了这些优化之外,Sparse-BM25 还继承了高性能向量数据库 Milvus 的几个系统级优势:
高效的底层实现和内存管理:
Milvus 的核心向量索引引擎采用 C++ 实现,可以提供比基于 Java 的系统(如 Elasticsearch)更高效的内存管理。与基于 JVM 的方法相比,仅此一项就节省了数 GB 的内存占用。
对 MMap 的支持: 与 Elasticsearch 在内存和磁盘中使用 page-cache 进行索引存储类似,Milvus 支持内存映射(MMap)以在索引超过可用内存时扩展内存容量。
Elasticsearch 是为传统的倒排索引构建的,在不根本改变架构的情况下,支持向量索引具有非常大的挑战。这导致其相比于专用向量数据库有非常大的性能差异:即使只有 100 万个向量,Elasticsearch 也需要 200 毫秒(在全托管的 Elastic Cloud 上测试)才能返回搜索结果,而在 Milvus 上(在全托管的 Zilliz Cloud 上测试)需要 6 毫秒——性能差异超过 30 倍。
每秒查询率(QPS)测量的吞吐量也有 3 倍的差异,Zilliz Cloud 上性能最高的实例运行在 6,000QPS,而 Elastic Cloud 最多为 1,900QPS。此外,Zilliz Cloud 在加载向量数据和构建索引方面比 Elastic Cloud 快 15 倍。
此外,Elasticsearch 的 Java/JVM 实现导致其性能的可扩展性也弱于基于 C++/Go 实现的向量数据库。而且,Elasticsearch 缺乏高级的向量搜索功能,如基于磁盘的索引(DiskANN、MMap)、优化的元数据过滤和 range search。

Milvus 作为性能领先的向量数据库,通过无缝结合语义搜索和全文搜索,将稠密向量搜索与优化的稀疏向量技术相结合,提供了卓越的性能、可扩展性和效率,并简化了基础设施的部署难度,降低成本的同时还增强了搜索能力。
展望未来,我们相信基于向量数据库的新型基础设施,将有望超越 Elasticsearch 成为混合搜索的标准解决方案。
陈将,Zilliz 生态和 AI 平台负责人
GitHub谎报了Copilot的统计数据!两年了,我们还是没办法证明AI编程助手能提高代码质量
在架构方面,没有谁比亚马逊的 CTO 更能预见未来
“卷王”一次上架百余款大模型,改写游戏规则
6 款大模型官宣后,生成式 AI 淘汰赛的号角正式吹响了
12 月 13 日至 14 日(周五至周六),AICon 全球人工智能开发与应用大会将在北京盛大开幕!本次大会汇聚 70+ 位 AI 及技术领域的顶尖专家,深入探讨大模型与推理、AI Agent、多模态、具身智能等前沿话题。此外还有丰富的圆桌论坛、以及展区活动,带你深入探索大模型的最新实践与未来趋势。年度最后一次 AI 盛宴,让我们一起见证 AI 未来。










