代码前期获取数据,可能较卡,后面都很顺利。
如嫌文章内容太长,或者翻译不准确,可直接到文末,点击原文或者链接,自行去学习哈。
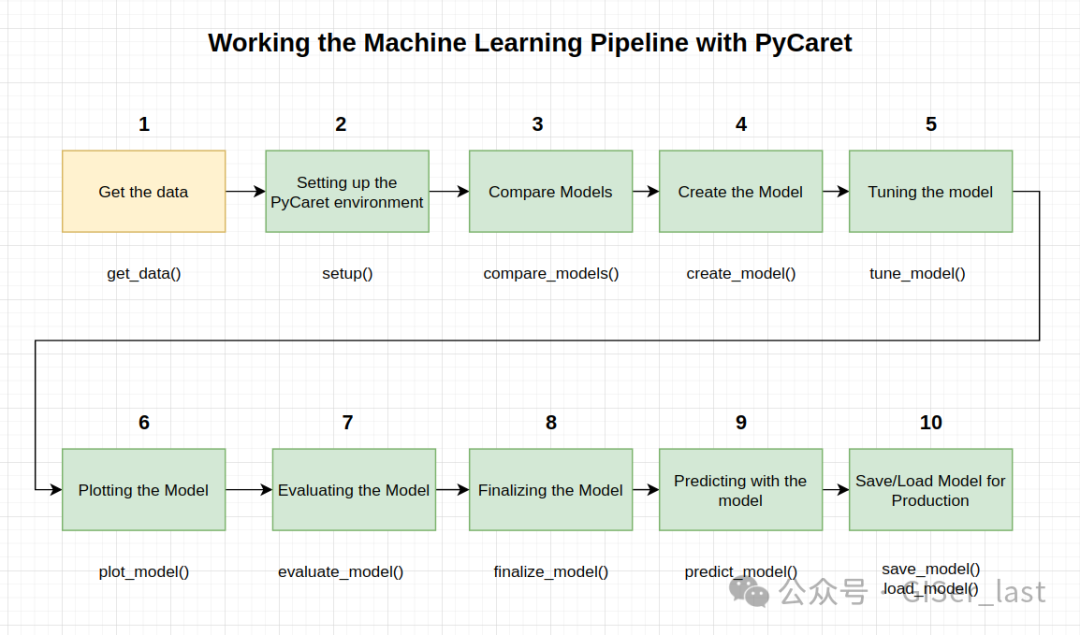
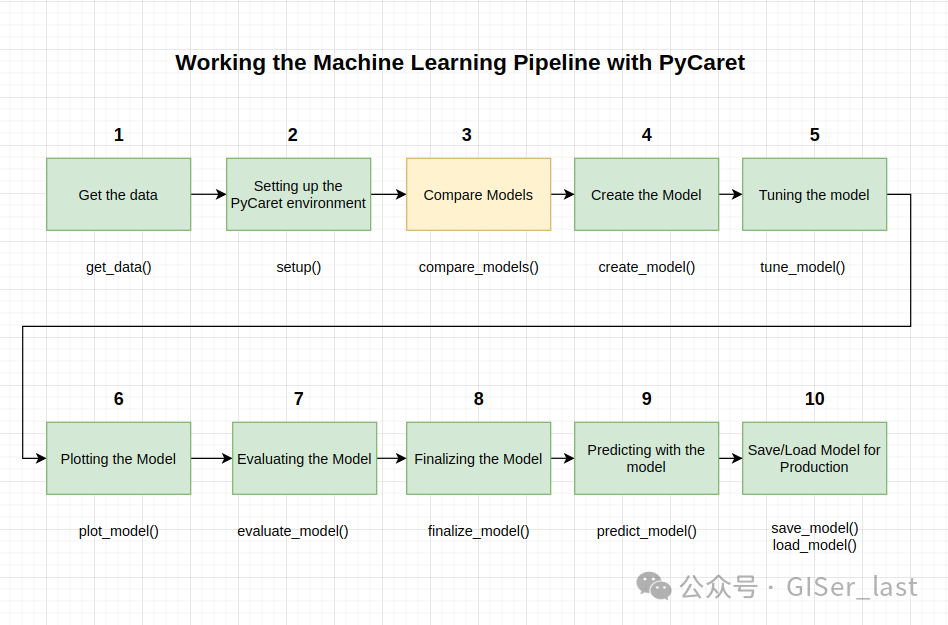
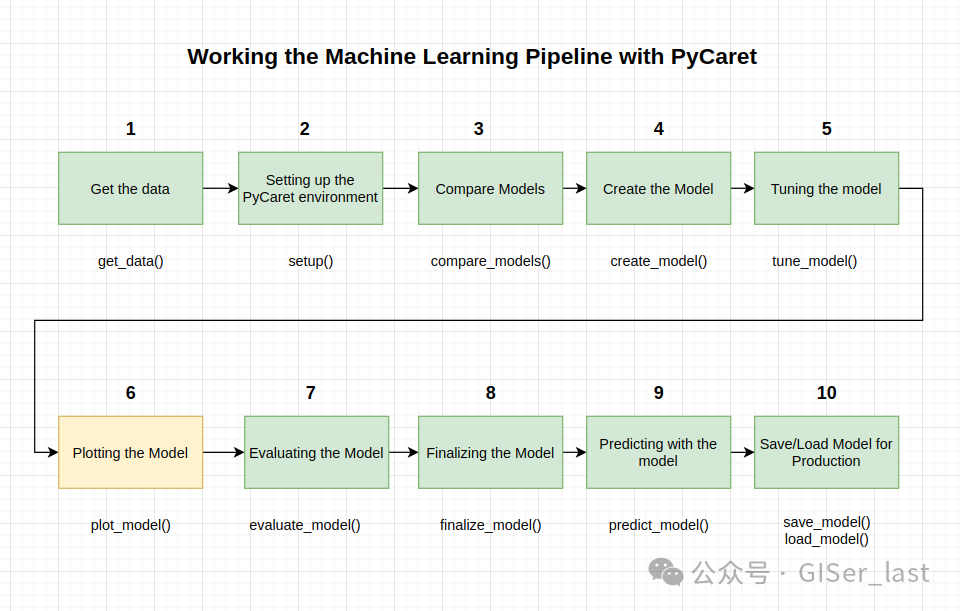
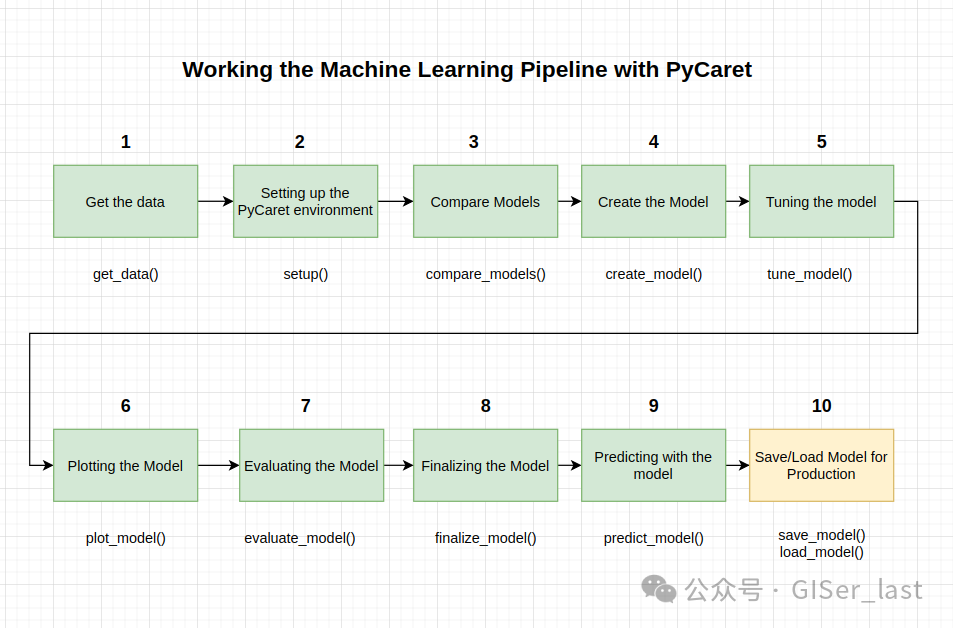
本教程涵盖了整个 ML 流程,从数据摄取、预处理、模型训练、超参数拟合、预测和存储模型以备后用。
我们将在不到 10 个命令中完成所有这些步骤,这些命令是自然构建的并且非常直观易记,例如
create_model(),
tune_model(),
compare_models()
plot_model()
evaluate_model()
predict_model()
让我们看看全貌

在大多数库中,在没有 PyCaret 的情况下重新创建整个实验需要 100 多行代码。该库还允许您执行更高级的操作,例如高级预处理、集成、通用堆栈和其他技术,这些技术允许您完全自定义 ML 管道,并且是任何数据科学家的必备工具。
PyCaret 是一个开源的低级 ML 和 Python 库,可让您在几分钟内完成从准备数据到部署模型的操作。允许科学家和数据分析师高效地从头到尾执行迭代数据科学实验,并允许他们更快地得出结论,因为花在编程上的时间要少得多。此库与 Caret de R 非常相似,但使用 python 实现
在从事数据科学项目时,通常需要很长时间来理解数据(EDA 和特征工程)。那么,如果我们可以将花在项目建模部分的时间减少一半呢?
让我们看看如何操作
首先,我们需要这个先决条件
Python 3.6 或更高版本
PyCaret 2.0 或更高版本
在这里,您可以找到库文档和其他文档。
首先,请运行以下命令:!pip3 install pycaret
对于 Google Colab 用户:如果您在 Google Colab 中运行此笔记本,请在笔记本顶部运行以下代码以显示交互式图像
from pycaret.utils import enable_colab
enable_colab()
Pycaret 模块
Pycaret 根据我们想要执行的任务进行划分,并且具有不同的模块,分别代表每种类型的学习(监督式或无监督式)。在本教程中,我们将使用二元分类算法开发监督学习模块。
分类模块
PyCaret 分类模块 () 是一个监督式机器学习模块,用于根据各种技术和算法将元素分类为二进制组。分类问题的一些常见用途包括预测客户违约(是或否)、客户放弃(客户将离开或留下)、遇到的疾病(阳性或阴性)等。pycaret.classification
PyCaret 分类模块可用于二进制或多类分类问题。它有超过 18 种算法和 14 个用于分析模型性能的绘图。无论是超参数调整、集成还是堆叠等高级技术,PyCaret 的分类模块都能满足您的需求。
分类模型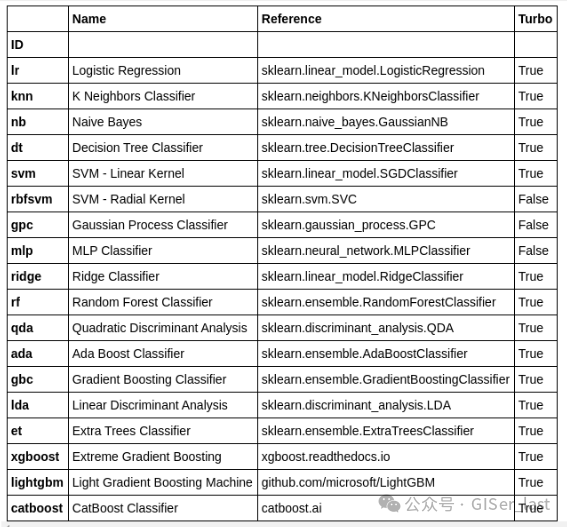
在本教程中,我们将使用一个名为 Default of Credit Card Clients Dataset 的 UCI 数据集。该数据集包含 2005 年 4 月至 2005 年 9 月期间台湾信用卡客户的违约付款、人口统计、信用数据、付款历史和账单等信息。有 24,000 个样本和 25 个特征。
数据集可以在这里找到。或者在这里,您可以找到直接下载链接。
因此,将数据集下载到您的环境中,然后我们将像这样加载它
在 [2] 中:
import pandas as pd
在 [3] 中:
df = pd.read_csv('datasets/default of credit card clients.csv')
在 [4] 中:
df.head()
输出[4]:
| 未命名:0 | X1 | X2 | X3 | X4 | X5 系列 | X6 | X7 系列 | X8 系列 | X9 系列 | ... | X15 系列 | X16 | X17 | X18 系列 | X19 系列 | X20 系列 | X21 系列 | X22 系列 | X23 系列 | Y |
|---|
| 0 | 身份证 | LIMIT_BAL | 性 | 教育 | 婚 | 年龄 | PAY_0 | PAY_2 |
PAY_3 | PAY_4 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 下个月违约金 |
|---|
| 1 | 1 | 20000 | 2 | 2 | 1 | 24 | 2 | 2 | -1 | -1 | ... | 0 | 0 | 0 | 0 | 689 | 0 | 0 | 0 |
0 | 1 |
|---|
| 2 | 2 | 120000 | 2 | 2 | 2 | 26 | -1 | 2 | 0 | 0 | ... | 3272 | 3455 | 3261 | 0 | 1000 | 1000 | 1000 | 0 | 2000 | 1 |
|---|
| 3 | 3 | 90000 | 2 | 2 | 2 | 34 | 0 | 0 |
0 | 0 | ... | 14331 | 14948 | 15549 | 1518 | 1500 | 1000 | 1000 | 1000 | 5000 | 0 |
|---|
| 4 | 4 | 50000 | 2 | 2 | 1 | 37 | 0 | 0 | 0 | 0 | ... | 28314 | 28959 | 29547 | 2000 | 2019 | 1200 | 1100 | 1069 | 1000 |
0 |
|---|
5 行 × 25 列
1- 获取数据
我们还有另一种加载方法。事实上,这将是我们在本教程中将使用的默认方式。它直接来自 PyCaret 数据集,是我们 Pipeline 的第一种方法
在 [5] 中:
from pycaret.datasets import get_data
dataset = get_data('credit')
| LIMIT_BAL | 性 | 教育 | 婚 | 年龄 | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 违约 |
|---|
| 0 | 20000 | 2 | 2 | 1 | 24 | 2 | 2 | -1 | -1 | -2 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 689.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 1 | 90000 | 2 | 2 | 2 | 34 | 0 | 0 | 0 | 0 | 0 | ... |
14331.0 | 14948.0 | 15549.0 | 1518.0 | 1500.0 | 1000.0 | 1000.0 | 1000.0 | 5000.0 | 0 |
|---|
| 2 | 50000 | 2 | 2 | 1 | 37 | 0 | 0 | 0 | 0 | 0 | ... | 28314.0 | 28959.0 | 29547.0 | 2000.0 | 2019.0 | 1200.0 | 1100.0 | 1069.0 | 1000.0 | 0 |
|---|
|
3 | 50000 | 1 | 2 | 1 | 57 | -1 | 0 | -1 | 0 | 0 | ... | 20940.0 | 19146.0 | 19131.0 | 2000.0 | 36681.0 | 10000.0 | 9000.0 | 689.0 | 679.0 | 0 |
|---|
| 4 | 50000 | 1 | 1 | 2 | 37 | 0 | 0 | 0 | 0 | 0 | ... |
19394.0 | 19619.0 | 20024.0 | 2500.0 | 1815.0 | 657.0 | 1000.0 | 1000.0 | 800.0 | 0 |
|---|
5 行 × 24 列
在 [6] 中:
#check the shape of data
dataset.shape
出局[6]:
(24000, 24)
为了在看不见的数据上演示该功能,我们保留了原始数据集中的 1200 条记录样本,用于预测。这不应与训练/测试拆分混淆,因为此特定拆分是为了模拟真实场景。另一种思考方式是,在执行 ML 实验时,这 1200 条记录不可用。predict_model()
在 [7] 中:
## sample returns a random sample from an axis of the object. That would be 22,800 samples, not 24,000
data = dataset.sample(frac=0.95, random_state=786)
在 [8] 中:
data
出局[8]:
| LIMIT_BAL | 性 | 教育 | 婚 | 年龄 | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 |
... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 违约 |
|---|
| 20534 | 270000 | 2 | 1 | 2 | 34 | 0 | 0 | 2 | 0 | 0 | ... | 44908.0 | 19508.0 | 15860.0 | 4025.0 | 5.0 | 34000.0 | 0.0 | 0.0 | 0.0 |
0 |
|---|
| 6885 | 160000 | 2 | 1 | 2 | 42 | -2 | -2 | -2 | -2 | -2 | ... | 0.0 | 741.0 | 0.0 | 0.0 | 0.0 | 0.0 | 741.0 | 0.0 | 0.0 | 0 |
|---|
| 1553 | 360000 | 2 | 1 | 2 | 30 | 0 | 0 | 0 | 0 |
0 | ... | 146117.0 | 145884.0 | 147645.0 | 6000.0 | 6000.0 | 4818.0 | 5000.0 | 5000.0 | 4500.0 | 0 |
|---|
| 1952 | 20000 | 2 | 1 | 2 | 25 | 0 | 0 | 0 | 0 | 0 | ... | 18964.0 | 19676.0 | 20116.0 | 1700.0 | 1300.0 | 662.0 | 1000.0 | 747.0 | 602.0 |
0 |
|---|
| 21422 | 70000 | 1 | 2 | 2 | 29 | 0 | 0 | 0 | 0 | 0 | ... | 48538.0 | 49034.0 | 49689.0 | 2200.0 | 8808.0 | 2200.0 | 2000.0 | 2000.0 | 2300.0 | 0 |
|---|
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 4516 | 130000 | 1 | 3 | 2 | 45 | 0 | 0 | -1 | 0 | -1 | ... | 1261.0 | 390.0 | 390.0 | 1000.0 | 2522.0 | 0.0 | 390.0 | 390.0 | 390.0 |
0 |
|---|
| 8641 | 290000 | 2 | 1 | 2 | 29 | 0 | 0 | 0 | 0 | -1 | ... | -77.0 | 8123.0 | 210989.0 | 1690.0 | 3000.0 | 0.0 | 8200.0 | 205000.0 | 6000.0 | 0 |
|---|
| 6206 | 210000 | 1 | 2 | 1 | 41 | 1 | 2 | 0 | 0 |
0 | ... | 69670.0 | 59502.0 | 119494.0 | 0.0 | 5000.0 | 3600.0 | 2000.0 | 2000.0 | 5000.0 | 0 |
|---|
| 2110 | 550000 | 1 | 2 | 1 | 47 | 0 | 0 | 0 | 0 | 0 | ... | 30000.0 | 0.0 | 0.0 | 10000.0 | 20000.0 | 5000.0 | 0.0 | 0.0 | 0.0 |
0 |
|---|
| 4042 | 200000 | 1 | 1 | 2 | 28 | 0 | 0 | 0 | 0 | 0 | ... | 161221.0 | 162438.0 | 157415.0 | 7000.0 | 8016.0 | 5000.0 | 12000.0 | 6000.0 | 7000.0 | 0 |
|---|
22800 行 × 24 列
在 [9] 中:
# we remove from the original dataset this random data
data_unseen = dataset.drop(data.index)
在 [10] 中:
data_unseen
输出[10]:
| LIMIT_BAL | 性 | 教育 |
婚 | 年龄 | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 违约 |
|---|
| 5 | 100000 | 2 | 2 | 2 | 23 | 0 | -1 | -1 | 0 | 0 | ... | 221.0 | -159.0 |
567.0 | 380.0 | 601.0 | 0.0 | 581.0 | 1687.0 | 1542.0 | 0 |
|---|
| 39 | 380000 | 1 | 2 | 2 | 32 | -1 | -1 | -1 | -1 | -1 | ... | 32018.0 | 11849.0 | 11873.0 | 21540.0 | 15138.0 | 24677.0 | 11851.0 | 11875.0 | 8251.0 | 0 |
|---|
| 57 | 200000 | 2 |
2 | 1 | 32 | -1 | -1 | -1 | -1 | 2 | ... | 5247.0 | 3848.0 | 3151.0 | 5818.0 | 15.0 | 9102.0 | 17.0 | 3165.0 | 1395.0 | 0 |
|---|
| 72 | 200000 | 1 | 1 | 1 | 53 | 2 | 2 | 2 | 2 | 2 | ... | 144098.0 | 147124.0 | 149531.0
| 6300.0 | 5500.0 | 5500.0 | 5500.0 | 5000.0 | 5000.0 | 1 |
|---|
| 103 | 240000 | 1 | 1 | 2 | 41 | 1 | -1 | -1 | 0 | 0 | ... | 3164.0 | 360.0 | 1737.0 | 2622.0 | 3301.0 | 0.0 | 360.0 | 1737.0 | 924.0 | 0 |
|---|
| ... | ... | ... |
... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 23978 | 50000 | 1 | 2 | 1 | 37 | 1 | 2 | 2 | 2 | 0 | ... | 2846.0 | 1585.0 | 1324.0 |
0.0 | 3000.0 | 0.0 | 0.0 | 1000.0 | 1000.0 | 1 |
|---|
| 23979 | 220000 | 1 | 2 | 1 | 41 | 0 | 0 | -1 | -1 | -2 | ... | 5924.0 | 1759.0 | 1824.0 | 8840.0 | 6643.0 | 5924.0 | 1759.0 | 1824.0 | 7022.0 | 0 |
|---|
| 23981 | 420000 | 1 |
1 | 2 | 34 | 0 | 0 | 0 | 0 | 0 | ... | 141695.0 | 144839.0 | 147954.0 | 7000.0 | 7000.0 | 5500.0 | 5500.0 | 5600.0 | 5000.0 | 0 |
|---|
| 23985 | 90000 | 1 | 2 | 1 | 36 | 0 | 0 | 0 | 0 | 0 | ... | 11328.0 | 12036.0 | 14329.0 |
1500.0 | 1500.0 | 1500.0 | 1200.0 | 2500.0 | 0.0 | 1 |
|---|
| 23999 | 50000 | 1 | 2 | 1 | 46 | 0 | 0 | 0 | 0 | 0 | ... | 36535.0 | 32428.0 | 15313.0 | 2078.0 | 1800.0 | 1430.0 | 1000.0 | 1000.0 | 1000.0 | 1 |
|---|
1200 行 × 24 列
在 [11] 中:
## we reset the index of both datasets
data.reset_index(inplace=True, drop=
True)
data_unseen.reset_index(inplace=True, drop=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
Data for Modeling: (22800, 24)
Unseen Data For Predictions: (1200, 24)
拆分数据
我们划分数据集的方式很重要,因为在建模过程中,有些数据我们不会使用,最后我们将通过模拟真实数据来验证我们的结果。我们用于建模的数据对其进行细分,以评估两种情况,即训练和测试。因此,我们做了以下工作
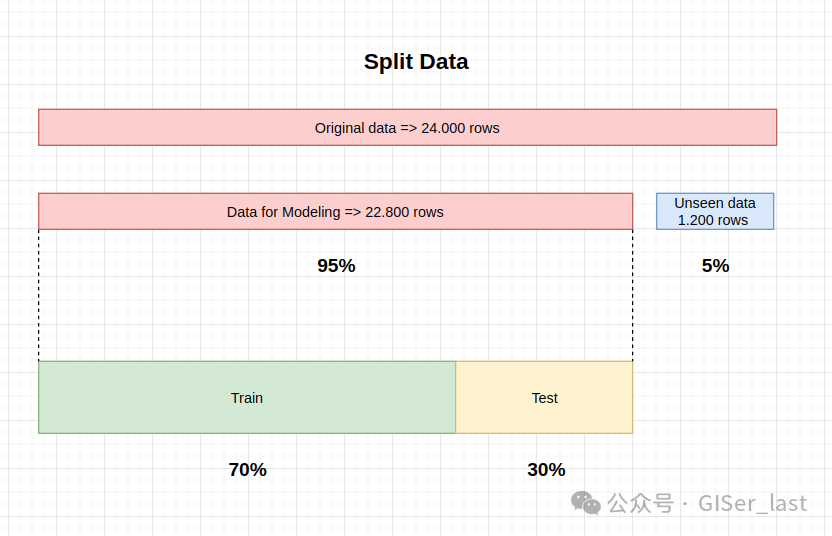
看不见的数据集(也称为验证数据集)
用于提供对最终模型的公正评估的数据样本。
验证数据集提供了用于评估模型的黄金标准。
只有在模型经过完全训练后(使用训练集和测试集)才会使用它。
验证集通常用于评估比赛的模型(例如,在许多 Kaggle 或 DataSource.ai 比赛中,测试集最初与训练集和测试集一起发布,而验证集仅在比赛即将结束时发布,并且验证集模型的结果决定了获胜者)。
很多时候,测试集被用作验证集,但这不是一个好的做法。
验证集通常愈合良好。
它包含仔细采样的数据,涵盖模型在现实世界中使用时将面临的各种类。
训练数据集
训练数据集:用于训练模型的数据样本。
我们用于训练模型的数据集
模型可以看到这些数据并从中学习。
测试数据集
测试数据集:在调整模型的超参数时,用于提供模型无偏评估的数据样本与训练数据集匹配。
随着测试数据集中的技能被纳入模型配置,评估会变得更加偏颇。
测试集用于评估给定模型,但这用于频繁评估。
作为 ML 工程师,我们使用此数据来微调模型的超参数。
因此,模型偶尔会看到这些数据,但从不从中“学习”。
我们使用测试集的结果,并更新更高级别的超参数
因此,测试集会影响模型,但只是间接影响。
测试集也称为 Development 集。这是有道理的,因为此数据集在模型的 “开发” 阶段有所帮助。
术语混淆
有一种趋势是将 test 和 validation 的名称混淆。
根据教程、来源、书籍、视频或老师/导师的术语会发生变化,重要的是保持概念。
在我们的例子中,我们已经在开始时分离了验证集(1,200 个data_unseen)
2- 设置 PyCaret 环境
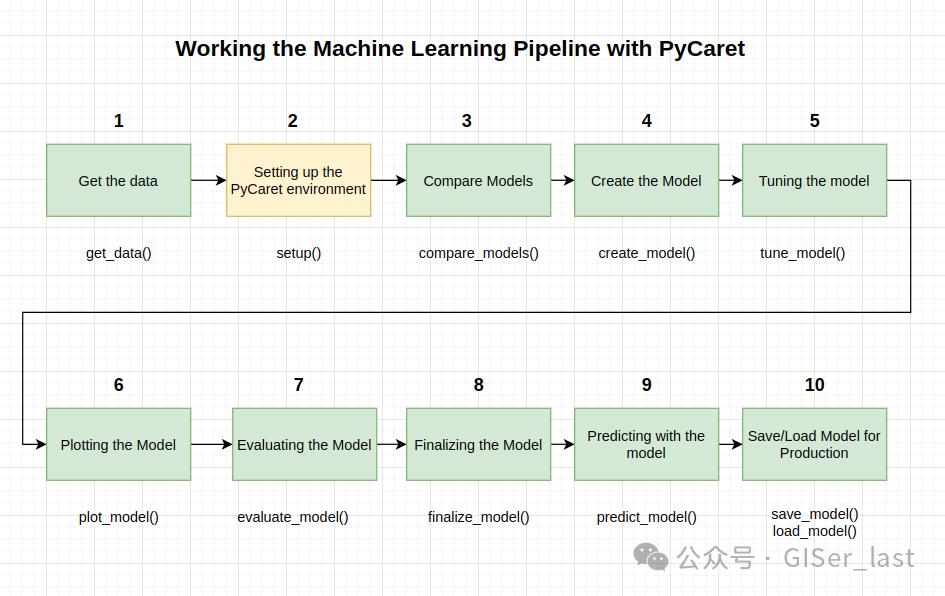
现在让我们设置 Pycaret 环境。该函数在 pycaret 中初始化环境并创建转换管道以准备用于建模和部署的数据。必须在执行 pycaret 中的任何其他函数之前调用。它采用两个必需参数:pandas 数据帧和目标列的名称。这部分配置的大部分是自动完成的,但有些参数可以手动设置。例如:
setup()setup()
在 [12] 中:
## setting up the environment
from pycaret.classification import *
注:运行以下命令后,必须按 Enter 键才能完成该过程。我们将解释他们是如何做到的。设置过程可能需要一些时间才能完成。
在 [13] 中:
model_setup = setup(data=data, target='default', session_id=123)
| 描述 | 价值 |
|---|
| 0 | session_id | 123 |
|---|
| 1 | 目标 | 违约 |
|---|
| 2 | 目标类型 |
二元的 |
|---|
| 3 | 标签编码 | 0: 0, 1: 1 |
|---|
| 4 | 原始数据 | (22800, 24) |
|---|
| 5 | 缺失值 | 假 |
|---|
| 6 | 数值特征 | 14 |
|---|
| 7 | 分类特征 | 9 |
|---|
| 8 | 序数特征 | 假 |
|---|
| 9 | 高基数功能 | 假 |
|---|
| 10 | 高基数方法 | 没有 |
|---|
| 11 |
变换的火车组 | (15959, 88) |
|---|
| 12 | 转换后的测试集 | (6841, 88) |
|---|
| 13 | Shuffle Train-Test | 真 |
|---|
| 14 | 分层训练测试 | 假 |
|---|
| 15 | Fold Generator | 分层 KFold |
|---|
| 16 | 折叠数 | 10 |
|---|
| 17 | CPU 作业 | -1 |
|---|
| 18 | 使用 GPU | 假 |
|---|
| 19 | 对数实验 | 假 |
|---|
| 20 | 实验名称 | clf 默认名称 |
|---|
| 21 | 环旭电子 | 6e18 |
|---|
| 22 | 插补类型 | 简单 |
|---|
| 23 | 迭代插补迭代 | 没有 |
|---|
| 24 | 数字插补器 | 意味 着 |
|---|
| 25 | 迭代插补数值模型 | 没有 |
|---|
| 26 | 分类插补 | 不断 |
|---|
| 27 | 迭代插补分类模型 | 没有 |
|---|
| 28 | 未知分类处理 |
least_frequent |
|---|
| 29 | 正常化 | 假 |
|---|
| 30 | Normalize 方法(Normalize Method) | 没有 |
|---|
| 31 | 转型 | 假 |
|---|
| 32 | 变换方法 | 没有 |
|---|
| 33 | 主成分分析 | 假 |
|---|
| 34 | PCA 方法 | 没有 |
|---|
| 35 | PCA 组件 | 没有 |
|---|
| 36 | 忽略低方差 | 假 |
|---|
|
37 | 结合稀有等级 | 假 |
|---|
| 38 | 稀有级别阈值 | 没有 |
|---|
| 39 | 数字分箱 | 假 |
|---|
| 40 | 删除异常值 | 假 |
|---|
| 41 | 离群值阈值 | 没有 |
|---|
| 42 | 删除多重共线性 | 假 |
|---|
| 43 | 多重共线性阈值 | 没有 |
|---|
| 44 | 聚类 | 假 |
|---|
| 45 | 聚类迭代 | 没有 |
|---|
| 46 | 多项式特征 | 假 |
|---|
| 47 | 多项式次数 | 没有 |
|---|
| 48 | 三角学特点 | 假 |
|---|
| 49 | 多项式阈值 | 没有 |
|---|
| 50 | 集团特点 | 假 |
|---|
| 51 | 特征选择 | 假 |
|---|
| 52 | 特征选择阈值 | 没有 |
|---|
| 53 | 特征交互 | 假 |
|---|
| 54 | 特征比率 |
假 |
|---|
| 55 | 交互阈值 | 没有 |
|---|
| 56 | 修复不平衡 | 假 |
|---|
| 57 | 修复不平衡方法 | 击打 |
|---|
当您运行 PyCaret 的推理算法时,它将根据某些属性自动推断所有特征的数据类型。必须正确推断数据类型,但情况并非总是如此。考虑到这一点,PyCaret 在执行后显示一个包含特征及其推断数据类型的表。如果正确识别了所有数据类型,您可以按 Enter 键继续或退出以结束实验。我们按 Enter,应该会得到与上面相同的输出。setup()setup()
确保数据类型正确在 PyCaret 中至关重要,因为它会自动执行一些对任何 ML 实验都至关重要的预处理任务。对于每种类型的数据,这些任务的执行方式不同,这意味着正确配置这些任务非常重要。
我们可以使用 中的 和 参数覆盖从 PyCaret 推断的数据类型。成功执行设置后,将打印包含几条重要信息的信息网格。大多数信息与运行numeric_featurescategorical_featuressetup()setup()
这些功能中的大多数都超出了本教程的范围,但是,在此阶段需要记住的一些重要事项包括
session_id:在所有函数中作为种子分布的伪随机数,以便以后重现。
目标类型 :Binary 或 Multiclass。系统会自动检测并显示目标类型。
标签编码:当 Target 变量的类型为 string(即“Yes”或“No”)而不是 1 或 0 时,它会自动将标签编码为 1 和 0,并将映射显示为参考(0 : No, 1 : Yes)
Original data :显示数据集的原始格式。在这个实验中 ==> 记住:“看到数据”(22800, 24)
缺失值 :当原始数据中存在缺失值时,将显示为True
Numerical features :推断为数值的特征数。
Categorical features :推断为分类的特征数
变换的火车集:请注意,对于变换后的火车集,原始形式 被转换为 ,并且由于分类编码,特征数量已从
24 个增加到 91 个(22800, 24)(15959, 91)
转换后的测试集:测试集中有样本。此拆分基于默认值,可以使用配置中的参数更改其默认值。6,84170/30train_size
请注意一些必须执行建模的任务是如何自动处理的,例如缺失值的插补(在这种情况下,训练数据中没有缺失值,但我们仍然需要看不见的数据的插补)、分类编码等。
大多数参数都是可选的,用于自定义预处理管道。setup()
3- 比较模型
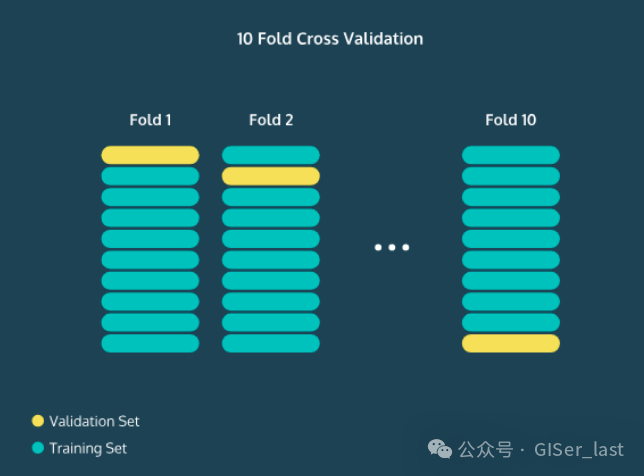
为了理解 PyCaret 如何比较模型和管道中的后续步骤,有必要理解 N-Fold Coss-Validation 的概念。
N-fold Coss-验证
计算应该将多少数据划分到测试集中是一个微妙的问题。如果您的训练集太小,您的算法可能没有足够的数据来有效学习。另一方面,如果您的测试集太小,那么您的准确度、精确率、召回率和 F1 分数可能会有很大的变化。
你可能非常幸运或非常不走运!一般来说,将 70% 的数据放在训练集中,将 30% 的数据放在测试集中是一个很好的起点。有时,您的数据集非常小,以至于将其除以 70/30 将导致大量方差。
一种解决方案是执行 N-Fold 交叉验证。这里的中心思想是,我们将完成整个过程时间,然后平均精度。例如,在 10 次交叉验证中,我们将测试集设为前 10% 的数据,并计算准确率、精度、召回率和 F1 分数。N
然后,我们将进行交叉验证,建立第二个 10% 的数据,并再次计算这些统计数据。这个过程我们可以做 10 次,每次测试集都会是不同的数据。然后,我们平均所有精度,我们将更好地了解我们的模型的平均工作原理。
注意:在我们的例子中,Validation Set(此处为黄色)是 Test Set
了解模型的准确性非常宝贵,因为您可以开始调整模型的参数以提高其性能。例如,在 K 最近邻算法中,您可以看到随着 精度的增加或减少而发生的变化。对模型的性能感到满意后,就可以输入验证集了。这是您在 Experiment 开始时拆分的数据部分(在我们的例子中)。Kunseen_data
它应该是您真正感兴趣的真实世界数据的替代品。它的工作原理与测试集非常相似,不同之处在于您在构建或优化模型时从未接触过此数据。通过找到精确率指标,您可以很好地了解您的算法在现实世界中的表现。
比较所有模型
PyCaret 完成后,推荐的建模起点是比较所有模型以评估性能(除非您确切知道需要什么类型的模型,但通常情况并非如此),此函数训练模型库中的所有模型,并使用分层交叉验证对它们进行评分以评估指标。setup()
输出打印一个分数网格,该网格显示折叠中 Accuracy、AUC、Recall、Precision、F1、Kappa 和 MCC 的平均值(默认情况下)以及训练时间。让我们开始吧!10
在 [14] 中:
best_model = compare_models()
| 型 | 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 | TT (秒) |
| 脊 | Ridge 分类器 | 0.8254 | 0.0000 | 0.3637 | 0.6913 | 0.4764 | 0.3836 | 0.4122 | 0.0360 |
|---|
| LDA | 线性判别分析 | 0.8247 | 0.7634 | 0.3755 | 0.6794 | 0.4835 | 0.3884 | 0.4132 | 0.2240 |
|---|
| GBC | 梯度提升分类器 | 0.8226 | 0.7789 | 0.3551 | 0.6806 | 0.4664 | 0.3725 | 0.4010 | 1.8550 |
| ADA | Ada Boost 分类器 | 0.8221 | 0.7697 | 0.3505 | 0.6811 | 0.4626 | 0.3690 | 0.3983 | 0.4490 |
|---|
| 猫助推器 | CatBoost 分类器 | 0.8215 | 0.7760 | 0.3657 | 0.6678 | 0.4724 | 0.3759 | 0.4007 | 5.0580 |
|---|
| lightgbm |
Light Gradient Boost 机器 | 0.8210 | 0.7750 | 0.3609 | 0.6679 | 0.4683 | 0.3721 | 0.3977 | 0.1440 |
|---|
| 射频 | 随机森林分类器 | 0.8199 | 0.7598 | 0.3663 | 0.6601 | 0.4707 | 0.3727 | 0.3965 | 1.0680 |
|---|
| XGBoost | 极端梯度提升 | 0.8160 | 0.7561 | 0.3629 | 0.6391 | 0.4626 | 0.3617 | 0.3829 | 1.6420 |
|---|
| et |
额外树分类器 | 0.8092 | 0.7377 | 0.3677 | 0.6047 | 0.4571 | 0.3497 | 0.3657 | 0.9820 |
|---|
| LR | Logistic 回归 | 0.7814 | 0.6410 | 0.0003 | 0.1000 | 0.0006 | 0.0003 | 0.0034 | 0.7750 |
|---|
| KNN | K 邻域分类器 | 0.7547 | 0.5939 | 0.1763 | 0.3719 | 0.2388 | 0.1145 | 0.1259 | 0.4270 |
|---|
| DT | 决策树分类器 |
0.7293 | 0.6147 | 0.4104 | 0.3878 | 0.3986 | 0.2242 | 0.2245 | 0.1430 |
|---|
| SVM | SVM - 线性内核 | 0.7277 | 0.0000 | 0.1017 | 0.1671 | 0.0984 | 0.0067 | 0.0075 | 0.2180 |
|---|
| QDA | 二次判别分析 | 0.4886 | 0.5350 | 0.6176 | 0.2435 | 0.3453 | 0.0485 | 0.0601 | 0.1760 |
|---|
| 铌 | 朴素贝叶斯 | 0.3760 |
0.6442 | 0.8845 | 0.2441 | 0.3826 | 0.0608 | 0.1207 | 0.0380 |
|---|
该功能允许您一次比较多个模型。这是使用 PyCaret 的一大优势。在一行中,您有一个多个模型之间的比较表。两个简单的代码单词(甚至没有一行)已经使用 N-Fold 交叉验证训练和评估了超过 15 个模型。compare_models()
上面打印的表格突出显示了最高性能指标,仅用于比较目的。默认表格使用 “Accuracy” (从最高到最低) 进行排序,可以通过传递参数来更改。例如,将按 Recall 而不是 Accuracy 对网格进行排序。compare_models(sort = 'Recall')
如果要将参数从默认值更改为其他值,可以使用该参数。例如,将在 5 折交叉验证中比较所有模型。减少折叠次数将缩短训练时间。Fold10foldcompare_models(fold = 5)
默认情况下,根据默认排序顺序返回性能最佳的模型,但可用于使用参数返回前 N 个模型的列表。此外,它还返回一些指标,例如准确性、AUC 和 F1。另一个很酷的事情是库如何自动突出显示最佳结果。选择模型后,您可以创建模型,然后对其进行优化。让我们使用其他方法。compare_modelsn_select
在 [15] 中:
print(best_model)
RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=123, solver='auto',
tol=0.001)
4- 创建模型
create_model是 PyCaret 中最精细的函数,通常是 PyCaret 大多数功能的基础。顾名思义,此函数使用交叉验证来训练和评估模型,该交叉验证可通过参数 进行设置。输出将打印一个评分表,按 Fold the Precision、AUC、Recall、F1、Kappa 和 MCC 显示。fold
在本教程的其余部分,我们将使用以下模型作为候选模型。这些选择仅用于说明目的,并不一定意味着它们是此类数据的最佳执行者或理想之选
决策树分类器 ('dt')
K 邻域分类器 ('knn')
随机森林分类器 ('rf')
PyCaret 模型库中有 18 个分类器可用。要查看所有分类器的列表,请查看文档或使用函数查看库。models()
在 [16] 中:
models()
出[16]:
| 名字 | 参考 | 汽 |
|---|
| 身份证 |
|
|
|
|---|
| LR | Logistic 回归 | sklearn.linear_model._logistic.LogisticRegression (逻辑回归) | 真 |
|---|
| KNN | K 邻域分类器 | sklearn.neighbors._classification。KeighborsCl... | 真 |
|---|
| 铌 | 朴素贝叶斯 | sklearn.naive_bayes。GaussianNB (高斯NB) | 真 |
|---|
| DT | 决策树分类器 | sklearn.tree._classes。决策树分类器 | 真 |
|---|
| SVM | SVM - 线性内核 | sklearn.linear_model._stochastic_gradient 的SGDC ... |
真 |
|---|
| RBFSVM | SVM - 径向内核 | sklearn.svm._classes。SVC | 假 |
|---|
| 全球电脑 | 高斯过程分类器 | sklearn.gaussian_process._gpc 的 gpc 中。GaussianProcessC... | 假 |
|---|
| MLP | MLP 分类器 | pycaret.internal.tunable.TunableMLPClassifier | 假 |
|---|
| 脊 | Ridge 分类器 | sklearn.linear_model._ridge.Ridge分类器 | 真 |
|---|
| 射频 | 随机森林分类器 | sklearn.ensemble._forest。RandomForestClassifier (随机森林分类器) | 真 |
|---|
| QDA | 二次判别分析 | sklearn.discriminant_analysis。QuadraticDiscrim... | 真 |
|---|
| ADA |
Ada Boost 分类器 | sklearn.ensemble._weight_boosting。AdaBoostClas... | 真 |
|---|
| GBC | 梯度提升分类器 | sklearn.ensemble._gb。GradientBoostingClassifier | 真 |
|---|
| LDA | 线性判别分析 | sklearn.discriminant_analysis。LinearDiscrimina... | 真 |
|---|
| et | 额外树分类器 | sklearn.ensemble._forest。ExtraTrees分类器 | 真 |
|---|
| XGBoost | 极端梯度提升 | xgboost.sklearn.XGBClassifier | 真 |
|---|
| lightgbm | Light Gradient Boost 机器 | lightgbm.sklearn.LGBMClassifier | 真 |
|---|
| 猫助推器 | CatBoost 分类器 | catboost.core.CatBoost分类器 | 真 |
|---|
在 [17] 中:
dt
= create_model('dt')
| 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 |
|---|
| 0 | 0.7343 | 0.6257 | 0.4327 | 0.4005 | 0.4160 | 0.2444 | 0.2447 |
|---|
| 1 | 0.7325 | 0.6277 | 0.4384 | 0.3984 | 0.4175 | 0.2443 | 0.2448 |
|---|
| 2 | 0.7431 | 0.6282 | 0.4241 |
0.4146 | 0.4193 | 0.2544 | 0.2544 |
|---|
| 3 | 0.7274 | 0.6151 | 0.4155 | 0.3856 | 0.4000 | 0.2240 | 0.2242 |
|---|
| 4 | 0.7187 | 0.6054 | 0.4040 | 0.3691 | 0.3858 | 0.2038 | 0.2042 |
|---|
| 5 | 0.7187 | 0.6014 | 0.3897 | 0.3656 | 0.3773 | 0.1958 | 0.1960 |
|---|
| 6 | 0.7206 |
0.6128 | 0.4212 | 0.3760 | 0.3973 | 0.2162 | 0.2168 |
|---|
| 7 | 0.7331 | 0.5986 | 0.3610 | 0.3830 | 0.3717 | 0.2024 | 0.2026 |
|---|
| 8 | 0.7206 | 0.6045 | 0.3983 | 0.3707 | 0.3840 | 0.2036 | 0.2038 |
|---|
| 9 | 0.7442 | 0.6272 | 0.4195 | 0.4148 | 0.4171 | 0.2533 | 0.2533 |
|---|
| 意味 着 |
0.7293 | 0.6147 | 0.4104 | 0.3878 | 0.3986 | 0.2242 | 0.2245 |
|---|
| 标清 | 0.0092 | 0.0112 | 0.0218 | 0.0174 | 0.0173 | 0.0218 | 0.0218 |
|---|
在 [18] 中:
#trained model object is stored in the variable 'dt'.
print(dt)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=123, splitter='best')
在 [19] 中:
knn = create_model('knn')
| 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 |
|---|
| 0 | 0.7469 | 0.6020 | 0.1920 | 0.3545 | 0.2491 | 0.1128 | 0.1204 |
| 1 | 0.7550 | 0.5894 | 0.2092 | 0.3883 | 0.2719 | 0.1402 | 0.1500 |
|---|
| 2 | 0.7506 | 0.5883 | 0.1576 | 0.3459 | 0.2165 | 0.0923 | 0.1024 |
|---|
| 3 | 0.7419 | 0.5818 | 0.1519 | 0.3136 | 0.2046 | 0.0723 |
0.0790 |
|---|
| 4 | 0.7563 | 0.5908 | 0.1490 | 0.3611 | 0.2110 | 0.0954 | 0.1085 |
|---|
| 5 | 0.7550 | 0.5997 | 0.1748 | 0.3720 | 0.2378 | 0.1139 | 0.1255 |
|---|
| 6 | 0.7638 | 0.5890 | 0.1891 | 0.4125 | 0.2593 | 0.1413 | 0.1565 |
|---|
| 7 | 0.7613 | 0.6240 | 0.1633 | 0.3904 |
0.2303 | 0.1163 | 0.1318 |
|---|
| 8 | 0.7619 | 0.5988 | 0.1862 | 0.4037 | 0.2549 | 0.1356 | 0.1500 |
|---|
| 9 | 0.7549 | 0.5756 | 0.1897 | 0.3771 | 0.2524 | 0.1246 | 0.1351 |
|---|
| 意味 着 | 0.7547 | 0.5939 | 0.1763 | 0.3719 | 0.2388 | 0.1145 | 0.1259 |
|---|
| 标清 | 0.0065 | 0.0126 |
0.0191 | 0.0279 | 0.0214 | 0.0214 | 0.0230 |
|---|
在 [20] 中:
print(knn)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=-1, n_neighbors=5, p=2,
weights='uniform')
在 [21] 中:
rf = create_model('rf')
| 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 |
|---|
| 0 | 0.8133 | 0.7673 | 0.3610 | 0.6269 | 0.4582 | 0.3551 | 0.3749 |
|---|
| 1 | 0.8239 | 0.7615 | 0.3782 |
0.6735 | 0.4844 | 0.3882 | 0.4117 |
|---|
| 2 | 0.8258 | 0.7708 | 0.3467 | 0.7076 | 0.4654 | 0.3756 | 0.4098 |
|---|
| 3 | 0.8177 | 0.7605 | 0.3725 | 0.6436 | 0.4719 | 0.3710 | 0.3913 |
|---|
| 4 | 0.8208 | 0.7642 | 0.3725 | 0.6599 | 0.4762 | 0.3780 | 0.4006 |
|---|
| 5 | 0.8283 |
0.7638 | 0.3954 | 0.6866 | 0.5018 | 0.4070 | 0.4297 |
|---|
| 6 | 0.8127 | 0.7647 | 0.3582 | 0.6250 | 0.4554 | 0.3522 | 0.3721 |
|---|
| 7 | 0.8283 | 0.7390 | 0.3553 | 0.7168 | 0.4751 | 0.3861 | 0.4202 |
|---|
| 8 | 0.8108 | 0.7496 | 0.3610 | 0.6146 | 0.4549 | 0.3496 | 0.3678 |
|---|
|
9 | 0.8176 | 0.7565 | 0.3621 | 0.6462 | 0.4641 | 0.3645 | 0.3867 |
|---|
| 意味 着 | 0.8199 | 0.7598 | 0.3663 | 0.6601 | 0.4707 | 0.3727 | 0.3965 |
|---|
| 标清 | 0.0062 | 0.0089 | 0.0131 | 0.0335 | 0.0139 | 0.0172 | 0.0202 |
|---|
在 [22] 中:
print(rf)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
请注意,所有模型的平均分数与 上打印的分数一致。这是因为分数网格中打印的指标是所有折叠的平均分数。compare_models()compare_models()
您还可以在每个模型中查看构建它们时使用的超参数。这非常重要,因为它是改进它们的基础。您可以查看
print()RandomForestClassifier
max_depth=None
max_features='auto'
min_samples_leaf=1
min_samples_split=2
min_weight_fraction_leaf=0.0
n_estimators=100
n_jobs=-1
5- 调整模型
使用该函数创建模型时,默认超参数用于训练模型。要优化超参数,请使用该函数。此函数在预定义的搜索空间中使用 Random Grid Search 自动调整模型的超参数。create_model()tune_model()
输出打印一个分数网格,其中显示最佳模型的准确率、AUC、召回率、精度、F1、Kappa 和 MCC(按 Fold)。要使用自定义搜索网格,您可以在函数中传递参数custom_gridtune_model
在 [23] 中:
tuned_rf = tune_model(rf)
| 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 |
|---|
| 0 | 0.8158 | 0.7508 | 0.3181 | 0.6647 | 0.4302 | 0.3363 |
0.3689 |
|---|
| 1 | 0.8283 | 0.7675 | 0.3295 | 0.7419 | 0.4563 | 0.3719 | 0.4152 |
|---|
| 2 | 0.8139 | 0.7337 | 0.3181 | 0.6529 | 0.4277 | 0.3321 | 0.3628 |
|---|
| 3 | 0.8246 | 0.7588 | 0.3095 | 0.7347 | 0.4355 | 0.3514 | 0.3976 |
|---|
| 4 | 0.8170 | 0.7567 | 0.3438 | 0.6557 |
0.4511 | 0.3539 | 0.3805 |
|---|
| 5 | 0.8258 | 0.7506 | 0.3324 | 0.7205 | 0.4549 | 0.3676 | 0.4067 |
|---|
| 6 | 0.8170 | 0.7530 | 0.3324 | 0.6629 | 0.4427 | 0.3474 | 0.3771 |
|---|
| 7 | 0.8221 | 0.7507 | 0.3381 | 0.6901 | 0.4538 | 0.3621 | 0.3951 |
|---|
| 8 | 0.8177 | 0.7201 |
0.2980 | 0.6933 | 0.4168 | 0.3286 | 0.3699 |
|---|
| 9 | 0.8207 | 0.7484 | 0.3132 | 0.6987 | 0.4325 | 0.3439 | 0.3831 |
|---|
| 意味 着 | 0.8203 | 0.7490 | 0.3233 | 0.6915 | 0.4402 | 0.3495 | 0.3857 |
|---|
| 标清 | 0.0045 | 0.0126 | 0.0135 | 0.0310 | 0.0129 | 0.0140 | 0.0165 |
|---|
如果我们将这个优化的 RandomForestClassifier 模型的 Accuracy 指标与之前的 RandomForestClassifier 进行比较,我们会看到差异,因为它从 Accuracy 变为 Accuracy 。0.8199
0.8203
在 [24] 中:
#tuned model object is stored in the variable 'tuned_dt'.
print(tuned_rf)
RandomForestClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
现在让我们比较一下超参数。我们以前有过这些。
max_depth=None
max_features='auto'
min_samples_leaf=1
min_samples_split=2
min_weight_fraction_leaf=0.0
n_estimators=100
n_jobs=-1
现在这些:
max_depth=5
max_features=1.0
min_samples_leaf=5
min_samples_split=10
min_weight_fraction_leaf=0.0
n_estimators=150
n_jobs=-1
您可以自己进行相同的比较,并探索超参数中的差异。knndt
默认情况下,优化 Accuracy (精度),但这可以使用参数进行更改。例如:将查找导致最高 AUC 而不是准确性的决策树分类器的超参数。在此示例中,我们仅使用 Accuracy 的默认指标来简化操作。tune_modeloptimizetune_model(dt, optimize = 'AUC')
通常,当数据集不平衡时(就像我们正在处理的信用数据集一样),准确性不是一个值得考虑的好指标。选择正确量度来评估评级的方法不在本教程的讨论范围之内。
在选择最佳生产模型时,指标本身并不是您应该考虑的唯一标准。其他需要考虑的因素包括训练时间、k 折的标准差等。现在,让我们继续考虑 Random Forest Classifier ,作为本教程其余部分的最佳模型tuned_rf
6- 绘制模型
在最终确定模型之前(步骤 # 8),该函数可用于通过 AUC、confusion_matrix、决策边界等不同方面分析性能。此函数采用经过训练的模型对象,并返回基于训练/测试集的图形。plot_model()
有 15 种不同的绘图可用,请参阅文档以获取可用绘图的列表。plot_model()
在 [25] 中:
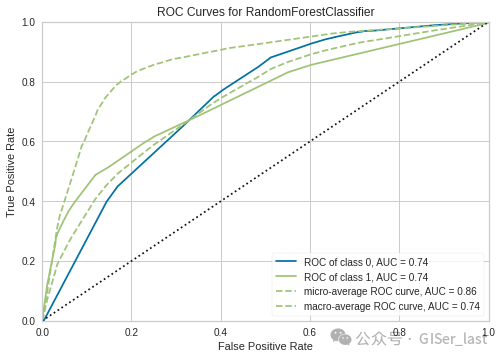
## AUC Plot
plot_model(tuned_rf, plot = 'auc')
在 [26] 中:
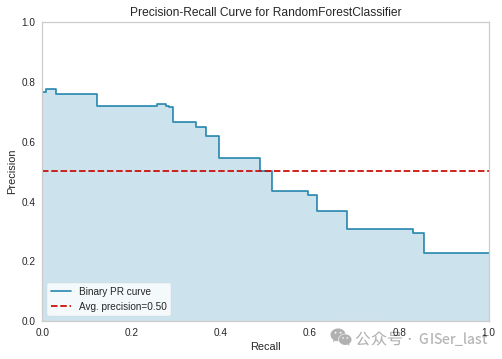
## Precision-recall curve
plot_model(tuned_rf, plot = 'pr')
在 [27] 中:
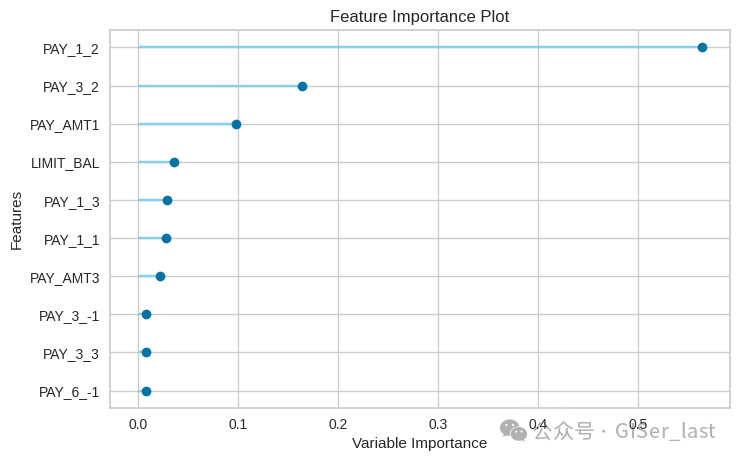
## feature importance
plot_model(tuned_rf, plot='feature')
在 [28] 中:
## Consufion matrix
plot_model(tuned_rf, plot = 'confusion_matrix')
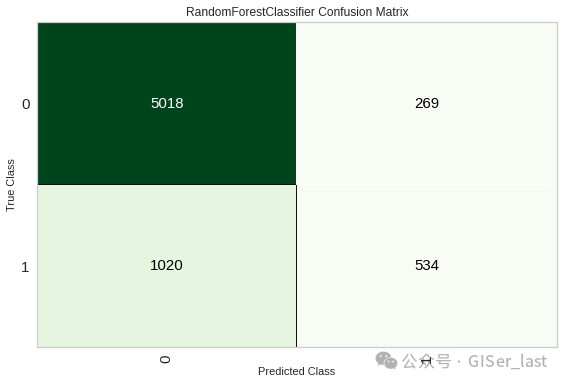
7- 评估模型
分析模型性能的另一种方法是使用函数,该函数显示给定模型的所有可用图形的用户界面。它在内部使用该功能。evaluate_model()plot_model()
在 [29] 中:
evaluate_model(tuned_rf)
8- 最终确定模型
模型的完成是实验的最后一步。PyCaret 中的正常机器学习工作流程从 开始,然后比较所有模型,使用和预选一些候选模型(基于感兴趣的指标)来执行各种建模技术,例如超参数拟合、组装、堆叠等。setup()compare_models()
此工作流最终将引导您找到用于对新数据和未见过的数据进行预测的最佳模型。该函数将模型拟合到完整的数据集,包括测试样本(在本例中为 30%)。此函数的目的是在将模型部署到生产环境之前,在完整的数据集上训练模型。我们可以在 .我们将在它之后执行它。finalize_model()predict_model()
最后要提醒你。使用 完成模型后,整个数据集(包括测试集)将用于训练。因此,如果使用模型对测试集进行预测,则打印的信息网格将具有误导性,因为它试图对用于建模的相同数据进行预测。finalize_model()finalize_model()
为了证明这一点,我们将使用 in 将信息网格与前一个进行比较。final_rf
predict_model()
在 [30] 中:
final_rf = finalize_model(tuned_rf)
在 [31] 中:
#Final Random Forest model parameters for deployment
print(final_rf)
RandomForestClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
9- 使用模型进行预测
在最终确定模型之前,建议通过预测测试/保持集(在本例中为 data_unseen)并查看评估指标来执行最终检查。如果您查看信息表,您将看到 30%(6841 个样本)的数据已被分离为训练/集样本。
我们上面看到的所有评估指标都是仅基于训练集 (70%) 的交叉验证结果。现在,使用存储在变量中的最终训练模型,我们针对测试样本进行预测并评估指标,以查看它们是否与 CV 结果存在重大差异tuned_rf
在 [32] 中:
predict_model(final_rf)
| 型 | 准确性 | AUC | 召回 | Prec. | F1 系列 | 卡帕 | MCC 公司 |
|---|
| 0 | 随机森林分类器 | 0.8184 | 0.7526 | 0.3533 |
0.6985 | 0.4692 | 0.3736 | 0.4053 |
|---|
出[32]:
| LIMIT_BAL | 年龄 | BILL_AMT1 | BILL_AMT2 | BILL_AMT3 | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | ... | PAY_6_2 | PAY_6_3 | PAY_6_4 | PAY_6_5 | PAY_6_6 | PAY_6_7 | PAY_6_8 | 违约 | 标签 | 得分 |
|---|
| 0 | 80000.0 | 29.0 | 6228.0 |
589.0 | 390.0 | 390.0 | 390.0 | 383.0 | 589.0 | 390.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.8051 |
|---|
| 1 | 180000.0 | 30.0 | 149069.0 | 152317.0 | 156282.0 | 161163.0 | 172190.0 | 148963.0 | 7500.0 | 8000.0 | ... | 1.0 | 0.0 | 0.0 | 0.0 |
0.0 | 0.0 | 0.0 | 1 | 0 | 0.9121 |
|---|
| 2 | 100000.0 | 26.0 | 18999.0 | 23699.0 | 9390.0 | 5781.0 | 8065.0 | 17277.0 | 5129.0 | 1227.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.8051 |
|---|
| 3 | 500000.0 | 36.0 | 396.0 |
1043.0 | 19230.0 | 116696.0 | 194483.0 | 195454.0 | 1043.0 | 19230.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.9121 |
|---|
| 4 | 190000.0 | 47.0 | 192493.0 | 193297.0 | 193400.0 | 193278.0 | 192956.0 | 193039.0 | 7200.0 | 7222.0 | ... | 0.0 | 0.0 | 0.0 |
0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.9121 |
|---|
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 6836 | 120000.0 | 44.0 | 75294.0 |
76465.0 | 74675.0 | 79629.0 | 77748.0 | 82497.0 | 3000.0 | 0.0 | ... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 | 1 | 0.5013 |
|---|
| 6837 | 50000.0 | 26.0 | 47095.0 | 48085.0 | 49039.0 | 49662.0 | 0.0 | 0.0 | 2073.0 | 2027.0 | ... | 0.0 | 0.0 | 0.0 |
0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.8603 |
|---|
| 6838 | 80000.0 | 39.0 | 46401.0 | 39456.0 | 30712.0 | 29629.0 | 28241.0 | 28030.0 | 1560.0 | 1421.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.8051 |
|---|
| 6839 | 200000.0 | 33.0 |
50612.0 | 10537.0 | 5552.0 | 2506.0 | 9443.0 | 11818.0 | 10023.0 | 27.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.8051 |
|---|
| 6840 | 210000.0 | 35.0 | 25806.0 | 5861.0 | 1666.0 | 1010.0 | 300.0 | 300.0 | 1035.0 | 1666.0 | ... | 0.0 | 0.0 |
0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.9121 |
|---|
6841 行 × 91 列
将测试集的准确性与 的结果中实现的准确性进行比较。这并不是一个显著的差异。如果测试集和训练集的结果之间存在很大差异,这通常表明过度拟合,但也可能是由于其他几个因素造成的,需要进一步调查。0.81990.8203tuned_rf
在这种情况下,我们将继续完成模型和对看不见的数据(我们一开始分开的 5% 并且从未暴露给 PyCaret)进行预测。
(TIP:在使用 时,查看训练集结果的标准差总是好的。create_model()
该函数还用于预测看不见的数据集。唯一的区别是这次我们将传递 参数 . 是在本教程开始时创建的变量,其中包含从未向 PyCaret 公开的原始数据集的 5%(1200 个样本)。predict_model()data_unseendata_unseen
在 [33] 中:
unseen_predictions = predict_model(final_rf, data=data_unseen)
unseen_predictions.head()
出[33]:
| LIMIT_BAL | 性 | 教育 | 婚 | 年龄 | PAY_1 | PAY_2 |
PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 违约 | 标签 | 得分 |
|---|
| 0 | 100000 | 2 | 2 | 2 | 23 | 0 | -1 | -1 | 0 | 0 | ... | 567.0 | 380.0 | 601.0 | 0.0 | 581.0 | 1687.0 | 1542.0 |
0 | 0 | 0.8051 |
|---|
| 1 | 380000 | 1 | 2 | 2 | 32 | -1 | -1 | -1 | -1 | -1 | ... | 11873.0 | 21540.0 | 15138.0 | 24677.0 | 11851.0 | 11875.0 | 8251.0 | 0 | 0 | 0.9121 |
|---|
| 2 | 200000 | 2 | 2 | 1 | 32 | -1 |
-1 | -1 | -1 | 2 | ... | 3151.0 | 5818.0 | 15.0 | 9102.0 | 17.0 | 3165.0 | 1395.0 | 0 | 0 | 0.8051 |
|---|
| 3 | 200000 | 1 | 1 | 1 | 53 | 2 | 2 | 2 | 2 | 2 | ... | 149531.0 | 6300.0 | 5500.0 | 5500.0 | 5500.0 | 5000.0 |
5000.0 | 1 | 1 | 0.7911 |
|---|
| 4 | 240000 | 1 | 1 | 2 | 41 | 1 | -1 | -1 | 0 | 0 | ... | 1737.0 | 2622.0 | 3301.0 | 0.0 | 360.0 | 1737.0 | 924.0 | 0 | 0 | 0.9121 |
|---|
5 行 × 26 列
请转到上一个结果的最后一列,您将看到一个名为 Score
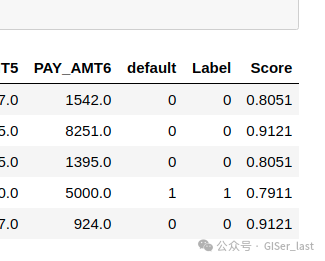
Label 是预测,score 是预测的概率。请注意,预测结果与原始数据集连接,而所有转换都在后台自动执行。
我们已经完成了实验,最终确定了现在存储在变量中的模型。我们还使用存储的模型来预测 。实验到此结束,但仍然存在一个问题:当您有更多新数据需要预测时会发生什么?你得再做一遍整个实验吗?答案是否定的,PyCaret 的内置功能允许您保存模型以及所有转换管道以备后用,并存储在本地环境中的 Pickle 中tuned_rf
final_rffinal_rfdata_unseensave_model()
(提示:保存模型时,最好在文件名中使用日期,这对版本控制有好处)
让我们在下一步中看看
10- 保存/加载模型以进行生产
保存模型
在 [1] 中:
save_model(final_rf, 'datasets/Final RF Model 19Nov2020')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
----> 1save_model(final_rf, 'datasets/Final RF Model 19Nov2020')
NameError: name 'save_model' is not defined
负载模型
要加载在相同或替代环境中保存的模型,我们将使用 PyCaret 的函数,然后轻松地将保存的模型应用于新的看不见的数据以进行预测load_model()
在 [37] 中:
saved_final_rf = load_model('datasets/Final RF Model 19Nov2020')
Transformation Pipeline and Model Successfully Loaded
一旦模型加载到环境中,它就可以简单地用于使用同一函数预测任何新数据。接下来,我们应用加载的模型来预测我们之前使用的相同模型。predict_model()data_unseen
在 [38] 中:
new_prediction = predict_model(saved_final_rf, data=data_unseen)
在 [39] 中:
new_prediction.head()
出[39]:
| LIMIT_BAL | 性 |
教育 | 婚 | 年龄 | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | 违约 | 标签 | 得分 |
|---|
| 0 | 100000 | 2 | 2 | 2 | 23 | 0 | -1 | -1 | 0 | 0 | ... | 567.0 |
380.0 | 601.0 | 0.0 | 581.0 | 1687.0 | 1542.0 | 0 | 0 | 0.8051 |
|---|
| 1 | 380000 | 1 | 2 | 2 | 32 | -1 | -1 | -1 | -1 | -1 | ... | 11873.0 | 21540.0 | 15138.0 | 24677.0 | 11851.0 | 11875.0 | 8251.0 | 0 | 0 | 0.9121 |
|---|
| 2 |
200000 | 2 | 2 | 1 | 32 | -1 | -1 | -1 | -1 | 2 | ... | 3151.0 | 5818.0 | 15.0 | 9102.0 | 17.0 | 3165.0 | 1395.0 | 0 | 0 | 0.8051 |
|---|
| 3 | 200000 | 1 | 1 | 1 | 53 | 2 | 2 | 2 | 2 | 2 | ... |
149531.0 | 6300.0 | 5500.0 | 5500.0 | 5500.0 | 5000.0 | 5000.0 | 1 | 1 | 0.7911 |
|---|
| 4 | 240000 | 1 | 1 | 2 | 41 | 1 | -1 | -1 | 0 | 0 | ... | 1737.0 | 2622.0 | 3301.0 | 0.0 | 360.0 | 1737.0 | 924.0 | 0 | 0 | 0.9121 |
|---|
5 行 × 26 列
在 [41] 中:
from pycaret.utils import check_metric
check_metric(new_prediction.default, new_prediction.Label, 'Accuracy')
出[41]:
0.8167
优点和缺点
与任何新库一样,仍有改进的余地。我们将列出我们在使用该库时发现的一些优缺点。
优点:
缺点:
结论
本教程涵盖了整个 ML 流程,从数据摄取、预处理、模型训练、超参数拟合、预测和存储模型以备后用。我们在不到 10 个命令中完成了所有这些步骤,这些命令是自然构建的并且非常直观易记,例如 .在没有 PyCaret 的情况下重新创建整个实验在大多数库中需要 100 多行代码。create_model(), tune_model(), compare_models()
该库还允许您执行更高级的操作,例如高级预处理、汇编、广义堆叠和其他技术,这些技术允许您完全自定义 ML 管道,并且是任何数据科学家的必备工具。
本文链接:https://www.datasource.ai/uploads/624e8836466a40923b64b901b5050c0f.html








