在深度学习中,正则化通过约束模型的复杂度来防止过拟合,提高模型的泛化能力、鲁棒性和解释性。在深度学习的实践中,可以根据
具体问题和数据集的特点选择合适的正则化技术和参数设置。
常用的正则化方法,包括L1正则化(Lasso Regularization)
、L2正则化(Ridge Regularization)和Dropout等。其中,L1正则化实现特征选择和模型稀疏化,L2正则化
使权重值尽可能小,而Dropout则通过随机丢弃神经元来减少神经元之间的共适应性。
正则化(Regularization)是什么?正则化是一种减少模型过拟合风险的技术。
当模型在训练数据上表现得太好时,它可能会学习到训练数据中的噪声或随机波动,而不是
数据中的基本模式。这会导致模型在未见过的数据上表现不佳,即过拟合。
正则化的目的是通过引入额外的约束或惩罚项来限制模型的复杂度,从而提高模型在未知数据上的泛化能力。
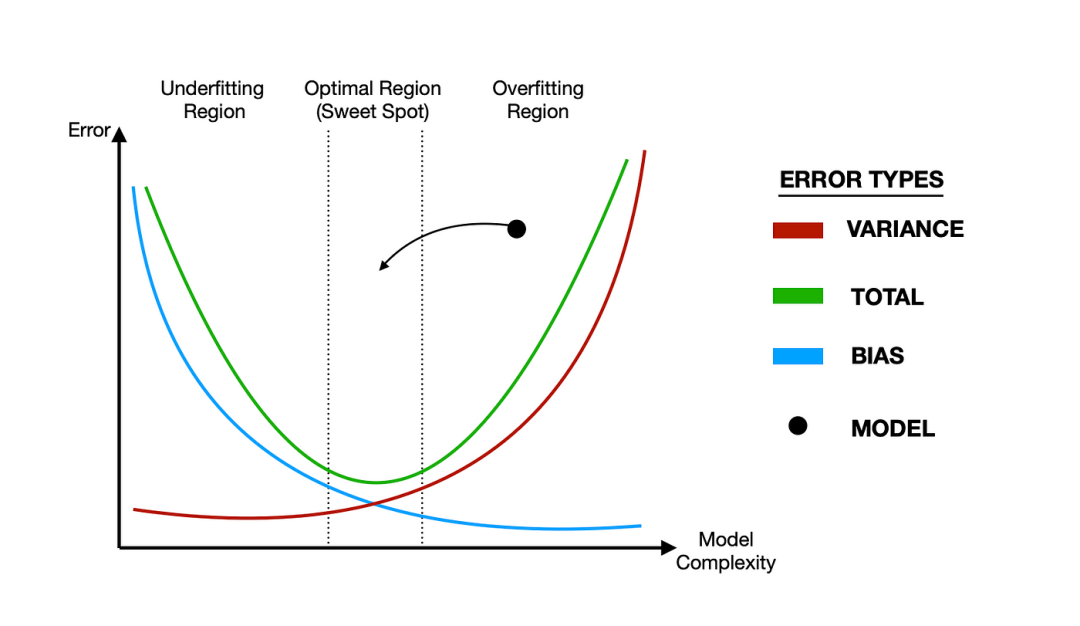
如何实现正则化?正则化是通过在损失函数中添加一个正则项来实现的,这个正则项是基于模型参数而构建的。
L1正则化在损失函数L中添加L1正则项,得到新的损失函数L_new = L + λ∑|w_i|,其中λ是正则化系数,w_i是模型参数。
L2正则化则在损失函数L中添加L2正则项,得到新的损失函数L_new = L + λ∑w_i^2,其中λ是正则化系数,w_i是模型参数。
在训练过程中,L1正则化、L2正则化都是通过优化算法最小化损失函数L_new,从而实现对模型参数的约束。
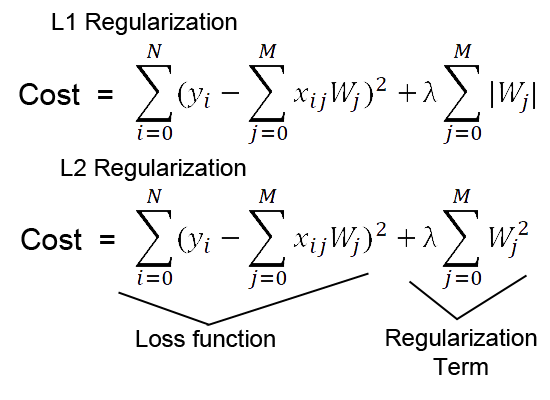
常用的正则化有哪些?常用的正则化方法主要包括L1正则化(产生稀疏权重)、L2正则化(减少权重大小)、Dropout(随机丢弃神经元)、数据增强(扩充数据集)以及提前停止(监控验证误差)等,它们各自通过不同机制减少模型过拟合风险。
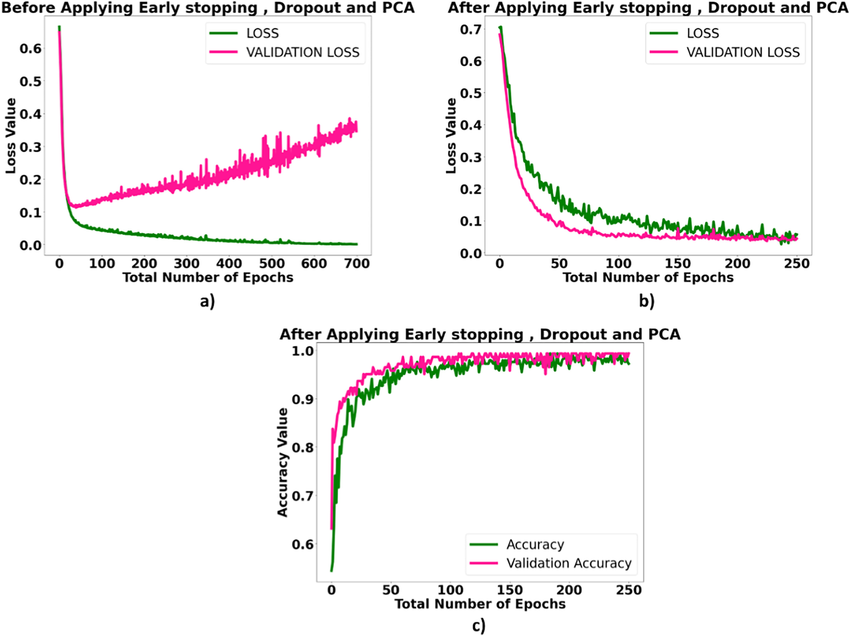
1. L1正则化(Lasso):
2. L2正则化(Ridge):
3. Dropout:
4. 数据增强(Data Augmentation):
5. 提前停止(Early Stopping):
为了帮助更多人(AI初学者、IT从业者)从零构建AI底层架构,培养Meta Learning能力;提升AI认知,拥抱智能时代。从而建立了“架构师带你玩转AI”知识星球。【架构师带你玩转AI】:公众号@架构师带你玩转AI 作者,资深架构师。2022年底,ChatGPT横空出世,人工智能时代来临。身为公司技术总监、研发团队Leader,深感未来20年属于智能时代。












