【新智元导读】Ai2和华盛顿大学联合Meta、CMU、斯坦福等机构发布了最新的OpenScholar系统,使用检索增强的方法帮助科学家进行文献搜索和文献综述工作,而且做到了数据、代码、模型权重的全方位开源。
LLM集成到搜索引擎中,可以说是当下AI产品的一个热门落地方向。
前有Perplexity横空出世,后有谷歌Gemini和OpenAI的SearchGPT纷纷加入。
就在11月23日,有人发现搜索引擎大佬Darin Fisher正式加入OpenAI,这让人更加确信:SearchGPT只是一个开始,OpenAI也许会正式打造以LLM为基础的搜索引擎和浏览器,和谷歌展开一场正面battle。
虽然当下的LLM可以应付大多数场景下的常识问答,但在学术打工人眼中,用AI进行文献搜索依旧缺陷重重,还是传统的谷歌搜索和谷歌学术更好用。
为了填补这方面的空白,华盛顿大学NLP实验室和Ai2、Meta等机构合作,开发了专门服务科研人的学术搜索工具OpenScholar。

本质上,OpenScholar是一个进行过检索增强的语言模型,外接一个包含4500万篇论文的数据库,性能可以优于专有系统,甚至媲美人类专家。
为了方便自动化评估,团队还一道推出了全新的大规模基准ScholarQABench,覆盖了CS、生物、物理等多个学科,用于评价模型在引用准确性、涵盖度和质量的等方面的表现。
由UWNLP和Ai2两大顶流机构联手,OpenScholar在开源方面几乎做到了无懈可击。不仅放出了训练数据、代码和模型检查点,还有ScholarQABench的全部数据,以及用于专家评估的自动化脚本。
仓库地址:https://huggingface.co/collections/OpenScholar/openscholar-v1-67376a89f6a80f448da411a6仓库地址:https://github.com/AkariAsai/OpenScholar
论文开头就给出了全部网址,此外团队还构建了一个公开可用的搜索demo,基于一个参数量为8B的语言模型,综合了超过100万篇CS领域的专业文献。

demo传送门:https://openscholar.allen.ai/
论文地址:https://arxiv.org/abs/2411.14199
阅读文献是科研工作的重要部分,不仅能知道同行们的最前沿进展,也是构建自己创新idea的重要来源。科学的进步,依赖于研究者们综合不断增长的文献的能力。
然而,随着发表的文献数量越来越多,全部通读已经是不可能完成的任务,因此就需要依赖实时更新的搜索工具,并能给出信息的准确来源。
虽然LLM在成为科研助手方面非常有前景,但也面临着重大挑战,包括幻觉、过于依赖过时的预训练数据,并且缺乏透明的信息出处,条条对科研领域都是重大弊病。
就拿幻觉来说,实验中让GPT-4引用最新文献时,它在CS、生物医学等领域伪造引用的情况达到了78%~90%。
检索增强(retrieval-augmented)的语言模型可以在推理时检索并集成外部知识源,从而缓解上述问题。然而,许多此类系统依赖于黑盒API或通用的LLM ,既没有针对文献综合的任务进行优化,也没有搭配适合科研的开放式、领域特定的检索数据库。
此外,LLM在科研文献综合任务上的评估也存在限制,现有的基准大多规模较小或只针对单个学科,或者使用了过于简化的任务(如选择题问答)。
OpenScholar的提出就是旨在解决上述问题。模型在推理时会检索相关段落,并使用迭代式自反馈的生成方法来优化输出;搭配的专门基准ScholarQABench旨在对开放式科学问答进行现实且可重复的评估。
OpenScholar概述、ScholarQABench概述和自动化&人类专家评估结果
对于OpenScholar而言,问题定义如下:
给出一个科学查询x ,任务是识别相关论文,综合他们的发现,并生成响应y,其中应附有一组引文, 𝐂=c1, c2 ,…, cK。
为了遵循科学写作的标准实践 ,每个引用ci对应于现有科学文献中的特定段落,并应作为内嵌引用提供,链接到相关文本范围y。这些引文使研究人员能够将输出追溯到原始文献,确保透明度和可验证性。
为了确保能检索到相关论文并生成高质量的输出,OpenScholar由三个关键组件组成:数据库𝐃 、检索器ℛ ,和负责生成的语言模型𝒢 。
推理过程从检索器ℛ开始 ,它从包含大量已发表文献的数据库𝐃中,根据与输入查询的语意相关性 x检索到一组段落 𝐏={p1,p2,…,pN},作为下一步的上下文。
然后,负责生成的语言模型𝒢根据段落𝐏和输入查询x产生输出y以及相应的引文𝐂, 这个过程可以形式化表示为:
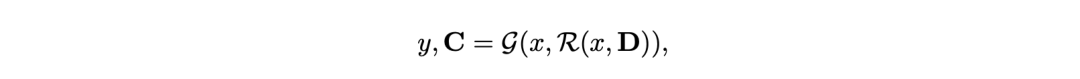
其中,𝐂中但每个ci对应检索到的特定段落𝐏 ,负责生成的LM可以被灵活替换为各种县城的模型,比如GPT-4o。
看起来,OpenScholar的检索和推理流程基本复刻了经典RAG的流水线,但团队做出了以下两方面的贡献:
- 新训练出了小而高效的生成模型OpenScholar-LM
- 开发了自反馈检索增强推理(elf-feedback retrieval-augmented inference),以提高可靠性和引用准确性
检索流程如下图左半部分所示,由数据存储𝐃、bi-encoder检索器θb_i,以及cross-encoder重排序器 θcross组成。最终,从数据库𝐃的4500万篇论文中筛选出N个最相关的段落。
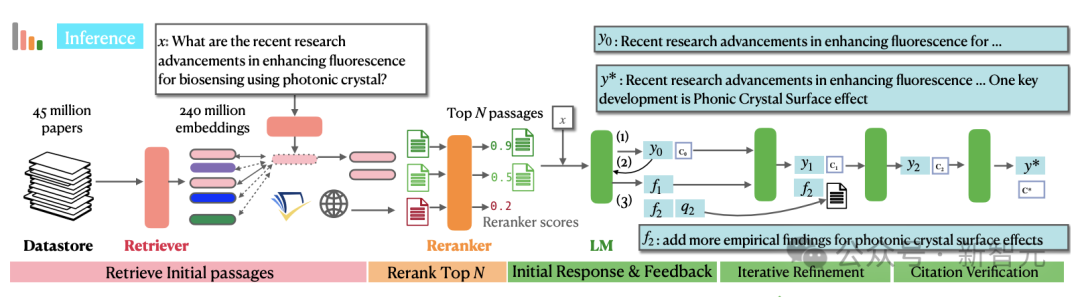
在标准的检索增强生成(RAG)中,生成器LM接收原始输入x和检索到的N个最相关段落𝐏并生成输出 y0 。虽然对于问答等任务有效,但这种「一步登天」的生成方式可能会产生不符合要求的答案,或由于信息缺失而导致输出不完整 。
为了应对这些挑战,OpenScholar引入了一种带有自我反馈的迭代生成方法,包括三个步骤:(1)初始响应和反馈生成以输出初始草稿y0以及一组反馈;(2)使用额外的搜索,根据上一步的反馈迭代改进y0,以及(3)引文验证。
由于缺乏针对该问题的训练数据,构建能够有效综合科学文献的强大LM非常具有挑战性,之前的大多数工作并没有设置开放式检索,而且是单论文任务,而且依赖于没有开源的专有模型,这对复现性和推理成本提出了挑战。
研究团队想到了采用上述的推理pipeline,通过自反馈合成高质量的训练数据,训练出「小而美」的OpenScholar LM模型,具体训练流程如下图所示。
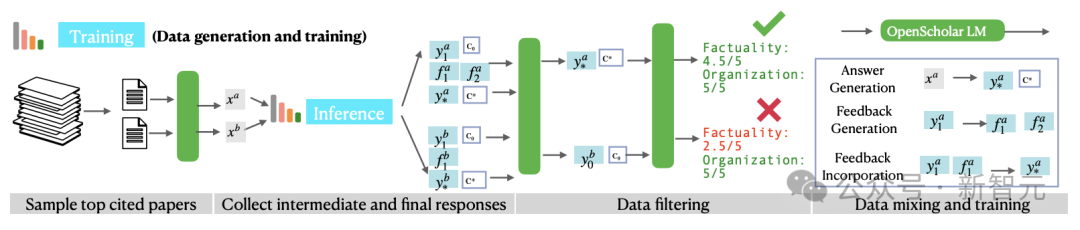
训练数据的生成主要包括三个步骤:
- 从数据库𝐃中筛选出最高引用量的论文
- 根据文章摘要生成一些有信息检索目的的查询
- 使用OpenScholar推理pipeline生成高质量响应
尽管合成数据是有效且可扩展的,但也可能包含幻觉、语句重复、指令遵循有限等问题,因此在上述步骤之后,团队还引入数据过滤步骤,包括「成对过滤」(pairwise-filtering)和标题过滤。判断并筛选出较高质量的输出。
从上述的合成管道中,可以得到三种类型的训练数据:答案生成(x→y),反馈生成(y0→𝐅),以及反馈合并 (yt−1,ft→yt) 。论文指出,在训练期间结合中间结果和最终输出有助于较小的语言模型学习生成更有效的反馈。
最后,研究人员将上述的合成数据与现有的通用领域+科学领域的指令调优数据混合,并确保50%的训练数据来自科学领域。在这些数据上,团队将Llama 3.1 8B Instruct训练成了OpenScholar LM。
ScholarQABench基准旨在评估模型理解和综合现有研究的能力。之前的基准一般会预先划定范围,假设可以在某一篇论文中找到答案,但许多现实场景都需要识别多篇相关论文,并生成带有准确引用的长文本输出。
为了应对这些挑战,研究人员整理了一个包含2967个文献综合问题的数据集,以及由专家撰写的208个长篇回答,涵盖计算机科学、物理、生物医学和神经科学等4个学科。
此外,基准中引入了多方面的评估方案,结合了自动指标和人工评估,以衡量引文准确性、事实正确性、内容覆盖率、连贯性和整体质量,确保评估的稳健和可重复性。
SchlarQA-CS的数据样例和评估概述
评估中使用了开放权重模型Llama 3.1(8B、70B)以及专有模型GPT-4o(gpt-4o-2024-05-13)。
首先,在单论文任务中,每个LM在不连接外部检索的情况下独立生成答案,并提供所有参考论文的标题。如果参考论文确实存在,则检索相应摘要以用作引文。
对于多论文任务,团队还进一步评估其他专有系统,包括Perplexity Pro和PaperQA2,后者是一个并发文献综述智能体系统,使用 GPT-4o进行重排、总结和答案生成。
具体的评估结果如下表所示,其中+OSDS表示外接了数据库OpenScholar-DataStore并检索到top N段落拼接到原始输入中;OS-8B模型经过重新训练,OS-70B和OS-GPT-4o仅仅使用了团队自定义的推理pipeline。
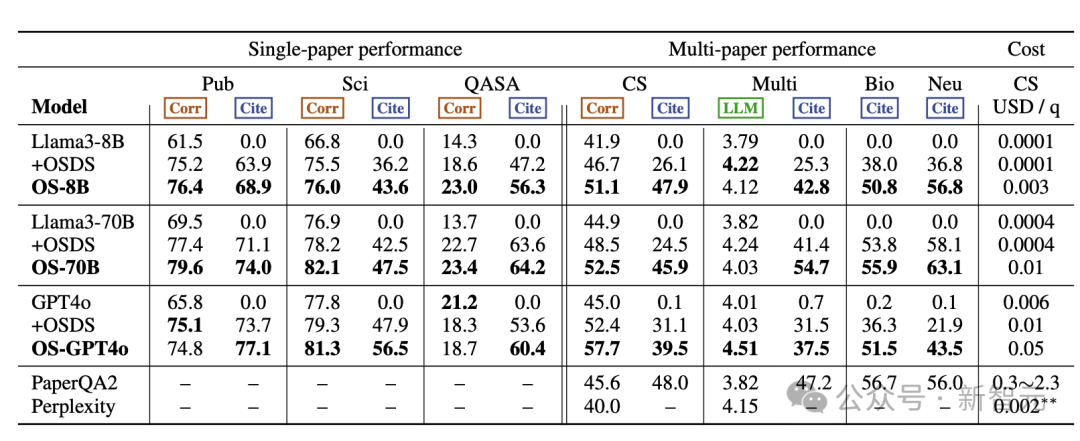
总体而言, OpenScholar实现了SOTA性能,大大优于GPT-4o和相应的标准RAG版本,以及PaperQA2等专用的文献综述系统。
在单篇论文任务中, OpenScholar始终优于其他模型。无论是否有检索增强,OS-8B和OS-70B均优于原来的Llama 3.1模型,OS-70B在PubMedQA和QASA上甚至可以对打GPT-4o。
此外,OS-8B、OS-70B和OS-GPT4o在多论文任务中也表现出强大的性能,OS-GPT4o在Scholar-CS中比单独的GPT-4o提高12.7%,比标准RAG版本提高了5.3 %。结合了重新训练过的OS-8B, OpenScholar 的性能显著优于使用现成的Llama 3.1 8B,说明了特定领域训练的优势。
甚至,在多论文任务的很多指标上,OpenScholar-8B的性能远远优于GPT-4o、Perplexity Pro和PaperQA2。值得注意的是,通过利用轻量的bi-encodeer、cross-encoder构建高效的检索pipeline, OpenScholar-8B 和OpenScholar-GPT4o显著降低了成本,在保持高性能的同时比PaperQA2便宜了几个数量级。
无论是单论文还是多论文任务,没有检索增强的模型几乎都表现的相当糟糕,难以生成正确的引用,甚至会产生严重的幻觉,而增加了检索之后都能大幅提升性能。
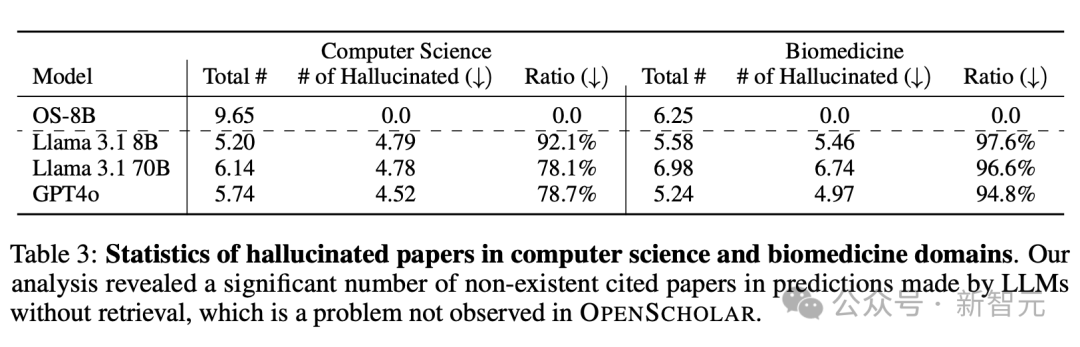
如表3所示,在没有检索增强的情况下,虽然GPT-4o和Llama等模型可以生成看起来靠谱的参考文献列表,但其中78-98%的引文都是捏造的,而且这个问题在生物医学领域更加严重。即使指向了真实论文,大多也没有相应摘要的证实,导致引文准确性接近于零。
除了在ScholarQABench上进行自动评估外,团队还与来自计算机科学、物理学和生物医学等领域的16名科学家合作,进行了详细的专家评估。
他们根据ScholarQABench中专家编写108个对文献综述问题的答案,对OpenScholar的输出进行了成对和细粒度的评估。结果发现,无论是使用GPT-4o还是经过训练的8B模型,OpenScholar的表现始终优于专家编写的答案,胜率分别为70%和51%。
相比之下,没有检索的单独GPT-4o模型被认为不如人类专家有帮助,胜率仅为 31%。这表明OpenScholar生成的输出更加全面、有条理,并且对于文献综述非常有用,不仅可以与专家撰写的答案相媲美,而且在某些情况下甚至超过了专家。
为了研究OpenScholar各个组件的有效性,作者进行了详细的消融实验,涉及推理期的重排、反馈、查找文献出处等步骤,并尝试不进行任何训练,直接使用原始的Llama3-8B模型。
如下图所示,删除这些组件会显著影响模型输出的整体正确性和引用准确性。值得注意的是,删除重排会导致模型性能大幅下降;相比8B模型,GPT-4o对删除反馈循环更加敏感,这表明更强大的模型可以从自反馈循环中受益更多。
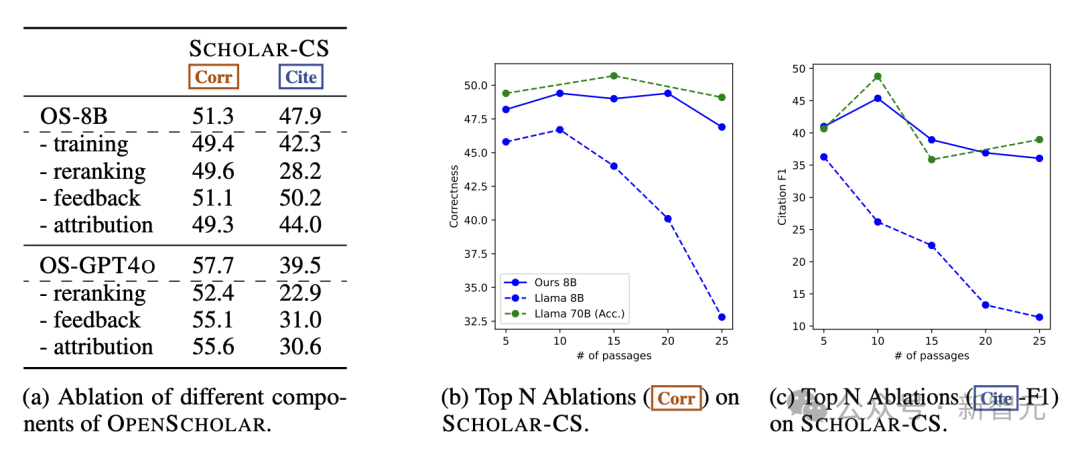
此外,取消论文出处的查找(attribution)会对引文准确性和最终输出正确性产生负面影响;经过训练的OS-8B 与原始模型之间也存在显著性能差距,这表明,对高质量、特定领域数据的进一步训练是构建高效的、针对专门任务的语言模型的关键。
尽管OpenScholar在ScholarQABench在评估中表现出了强大的性能,能够成为支持科研人的效率工具,但负责标注和评估的专家依旧发现了一些局限性。

首先,OpenScholar不能始终如一地检索到最具代表性或相关性的论文,而且输出总可能包含不准确的事实信息,特别是在基于8B模型的版本中,科学知识和指令遵循能力有限。
未来的工作可以进一步探索如何改进OpenScholar-8B的训练。尽管OpenScholar-GPT4o具有竞争力,但依赖于OpenAI的专有黑盒API,无法保证之后仍能精确复现当下的结果。
此外,数据方面也存在诸多繁琐且棘手的问题。
第一,ScholarQABench聘请了领域专家进行数据标注,他们都获得了博士学位或正在从事相关研究。这种人工撰写答案的方式成本很高,因此评估数据集相对较小,比如,CS-LFQA包括110条数据,专家编写的答案有108个。
这种数据集由于规模较小,更容易被注释者的专业知识所影响,从而引入统计方差和潜在偏差。未来的研究需要探索,如何扩大ScholarQABench的规模和范围,实现更加自动化的数据收集和标注pipeline。
第二,最后, ScholarQABench主要关注计算机科学、生物医学和物理学等领域,没有社会科学和其他STEM学科的实例数据。因此,目前的研究结果可能无法完全推广到其他领域,特别是在一些领域中,对论文数据的访问会受到更多限制。
最后,虽然OpenScholar在推理期没有使用版权保护的论文,但如何确保检索增强型的语言模型在训练和推理时做到对版权数据的公平使用,这方面的讨论仍在进行,也只能留待学界和业界在之后的工作中解决。
https://allenai.org/blog/openscholarhttps://x.com/AkariAsai/status/1858875730068738051










