在深度学习中,优化器(Optimizer)是一个核心概念,它负责调整神经网络的权重和偏置,以便最小化损失函数
,从而提高模型的准确性和性能。
常见的优化器,包括梯度下降系列(批量梯度下降BGD、随机梯度下降SGD、小批量梯度下降MBGD)、动量法、NAG、Adagrad、RMSprop以及Adam
等,它们的核心目标是通过调整学习率、利用梯度信息等手段,高效地最小化损失函数,从而优化和提升神经网络模型的性能。
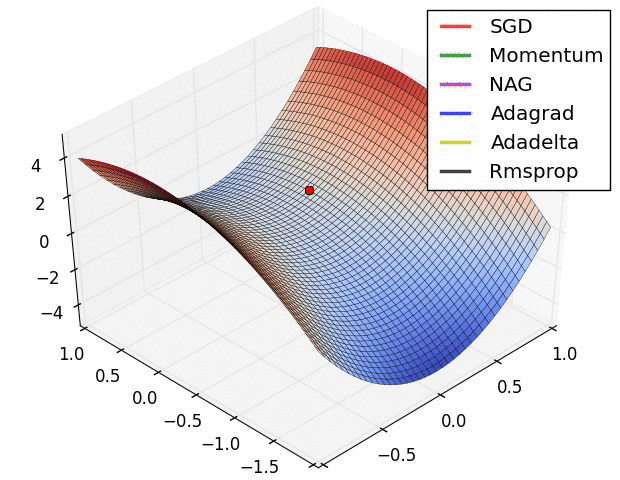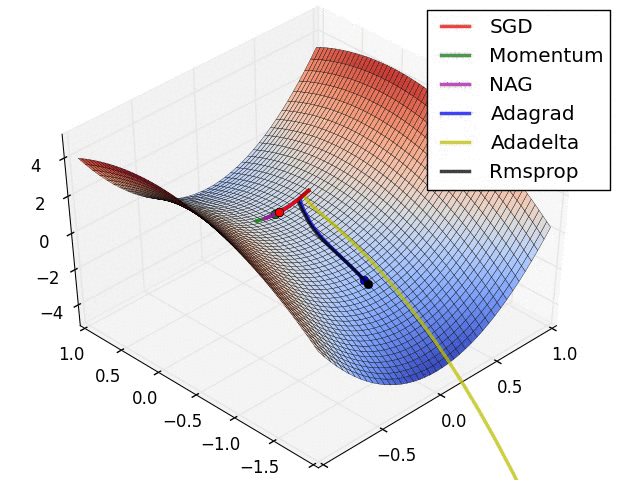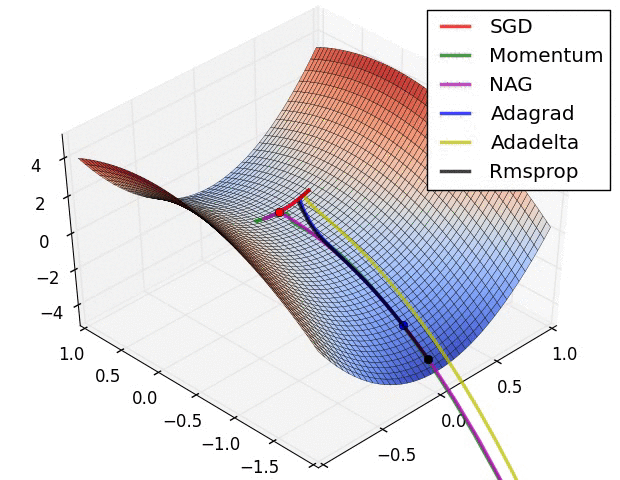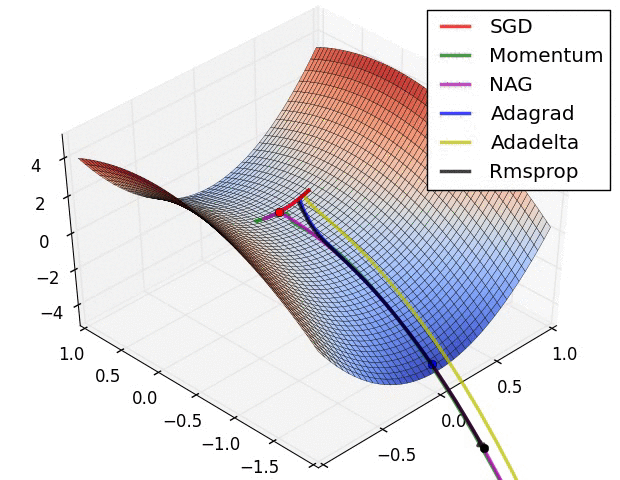
优化器(Optimizer)是什么?优化器是一种特定的深度学习算法,用于在训练深度学习模型时调整权重和偏差,从而更新神经网络参数以最小化某个损失函数。
损失函数衡量了模型的预测值与真实值之间的差异,而优化器的目标是通过调整网络参数来最小化这个差异,从而提高模型的准确性和性能。

为什么需要优化器?由于目标函数拥有众多参数且结构复杂,直接寻找最优参数变得十分困难。因此,我们需要借助优化器
,它能够逐步调整参数,确保每次优化都朝着最快降低损失的方向前进。

什么是优化器的调参?优化器调参即根据模型实际情况,调整学习率、动量因子、权重衰减等超参数,以优化训练效果和性能。需通过经验和实验找最佳组合
,实现快速收敛、减少摆动、防止过拟合。
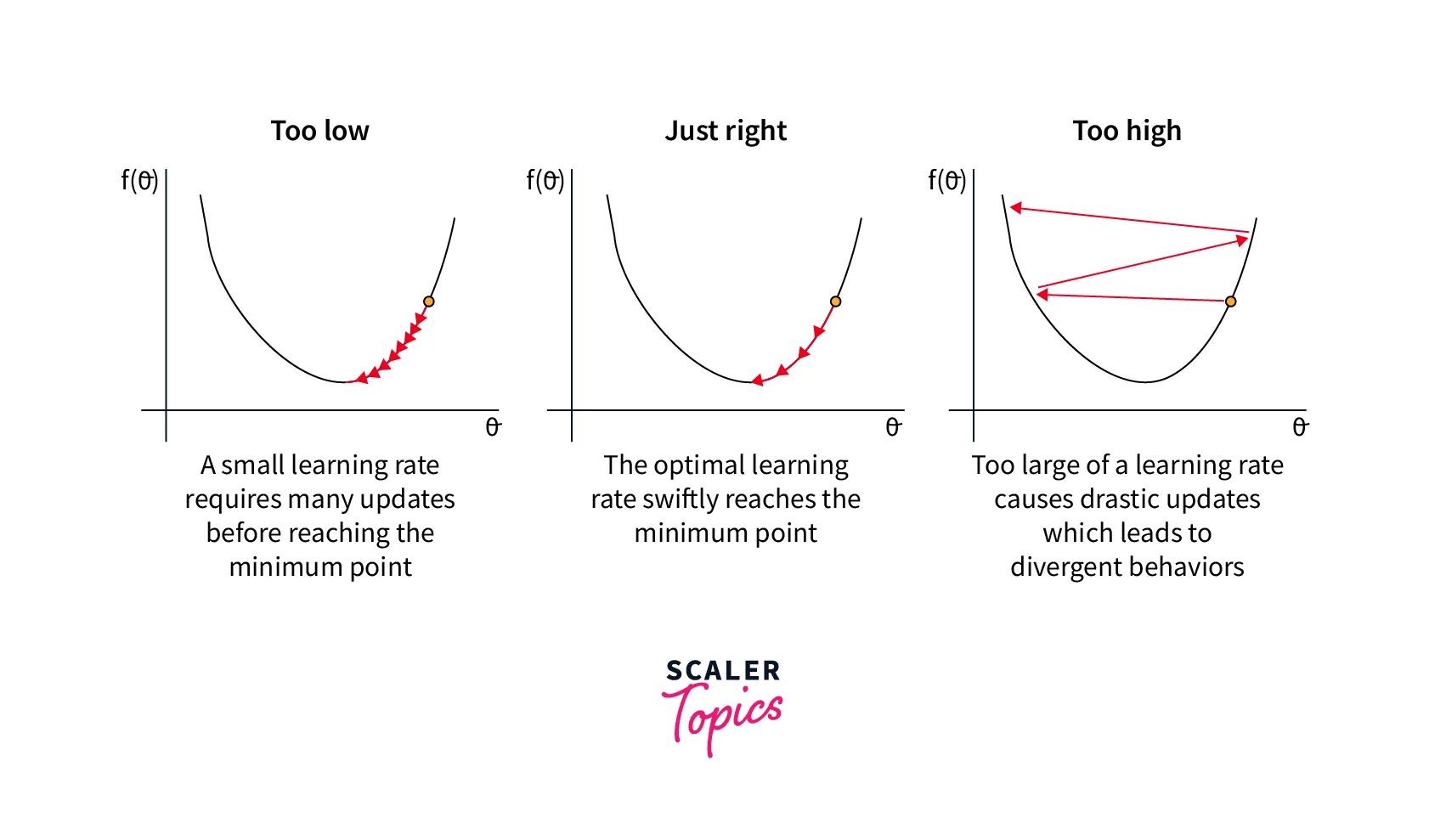
学习率:过大的学习率可能导致模型无法收敛,而过小的学习率则会使训练过程变得缓慢。因此,需要根据实际情况选择合适的学习率。
动量因子:对于使用动量的优化器,动量因子的选择也很重要。动量因子决定了过去梯度对当前梯度的影响程度。合适的动量因子可以加速收敛,减少摆动。
权重衰减:权重衰减是一种正则化方法,用于防止模型过拟合。在优化器中,可以通过添加权重衰减项来减少模型的复杂度。

常用的优化器有哪些?常用的优化器主要包括SGD、BGD、Momentum、NAG、Adagrad、RMSprop、Adadelta和Adam等,它们通过不同的策略调整学习率和梯度方向,以实现快速、稳定的模型训练。
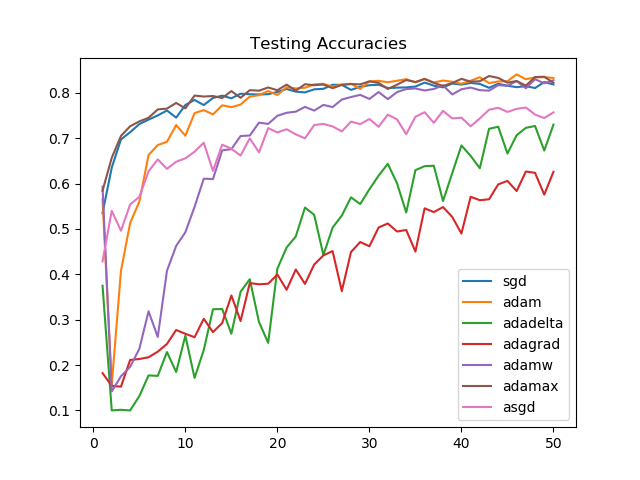
1. 随机梯度下降(SGD)
2. 批量梯度下降(BGD)
3. 动量法(Momentum)
4. NAG(Nesterov Accelerated Gradient)
5. Adagrad
6. RMSprop
8. Adam
为了帮助更多人(AI初学者、IT从业者)从零构建AI底层架构,培养Meta Learning能力;提升AI认知,拥抱智能时代。建立了 架构师带你玩转AI 知识星球
【架构师带你玩转AI】:公众号@架构师带你玩转AI 作者,资深架构师。2022年底,ChatGPT横空出世,人工智能时代来临。身为公司技术总监、研发团队Leader,深感未来20年属于智能时代。
公众号一周年之际,答谢粉丝,特申请了100份星球优惠券










