大家好,我是橙哥!你有没有在为股票预测构建机器学习模型的过程中,碰到寻找优质数据的难题?想要获得可靠的经济金融和市场数据而不花大价钱并不容易,且有很多不可靠的来源。而在机器学习中,数据是你的基础。相比之下,拥有高质量数据的简单模型往往比使用不可靠数据的最先进模型效果更好。点击此处或在文末获取本文完整源码。只需掌握基本的 Python 技能,你就可以获取所有免费且可靠的数据来训练股票预测模型。本文会教你如何自动化收集每日金融数据,并将其准备为机器学习模型可直接使用的格式。这不仅能帮你节省时间和成本,还能保证数据质量。本文的内容概览如下:
获取免费且可靠的每日经济和金融市场数据:
我们将展示如何自动化收集所有可靠数据,用于你的股票市场预测模型。同时,你还可以根据需要自定义查询的日期范围。
快速为你的模型准备数据:
我们将引导你完成数据预处理,将收集到的数据转化为机器学习模型可直接使用的格式。作为示例,我们将用这些数据训练一个基于 Transformer 的模型(NeuralForecast)。
从哪里获取这些免费且可靠的数据?
我们将使用美国圣路易斯联邦储备经济数据(FRED)API。该 API 来源于官方政府机构,更新频繁,并汇总了多个权威机构的信息,因而成为股票预测模型中获取准确可靠数据的理想选择。
第一步是向 FRED API 发出 API 请求,并通过以下链接获取你的免费 API 密钥:https://fred.stlouisfed.org/docs/api/api_key.html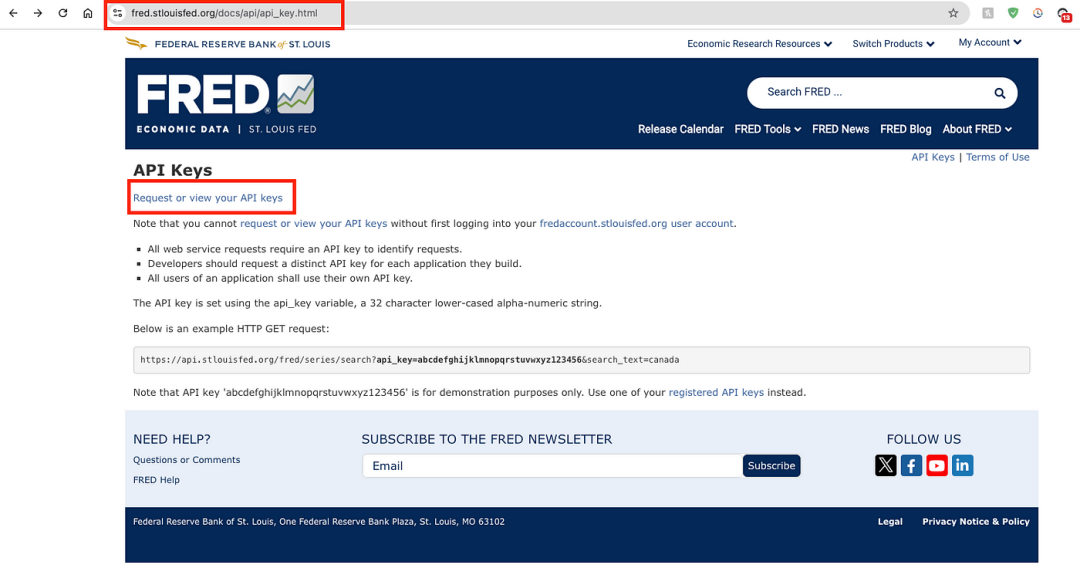
再次点击“登录”按钮(如上图步骤 2 所示)。
4、阅读并接受圣路易斯联邦储备银行的条款
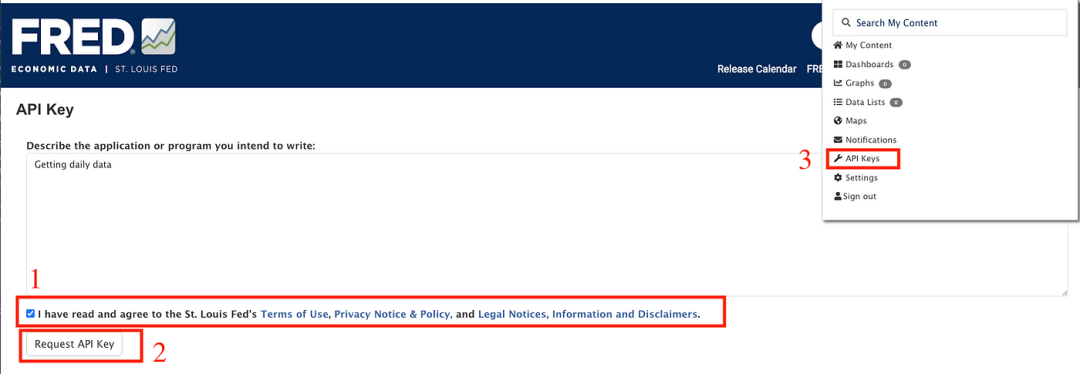
然后你将看到API密钥。需将其复制到Python脚本中,以便向FRED圣路易斯API发出请求。现在我们有了API密钥,可以从FRED API中检索数据。首先将API密钥存储在.env文件中。在终端中运行touch .env命令创建文件。接着,打开.env文件并添加API密钥,如下所示: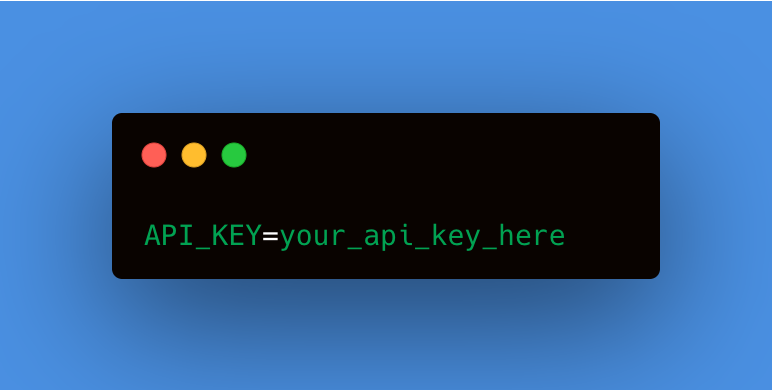
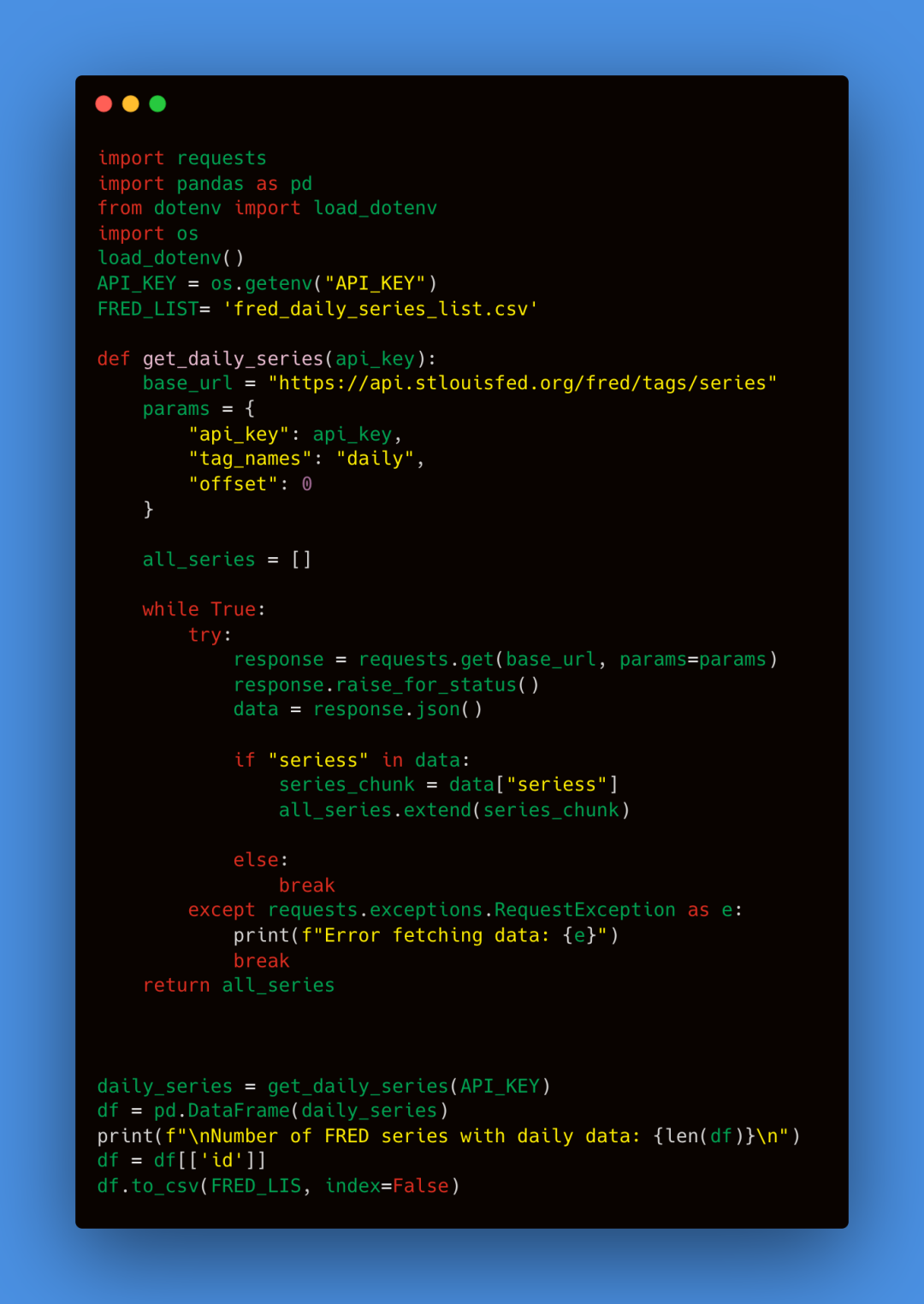
有1759个不同的系列具有每日数据,数据量丰富。我们有足够的数据来训练一个复杂的模型。然后,我们将从2014-10-01到2024-09-05逐一获取实际的系列数据,大约10年的数据。你可以根据需要调整START_DATE和END_DATE来改变日期范围。每个系列将以CSV文件形式保存在data文件夹中。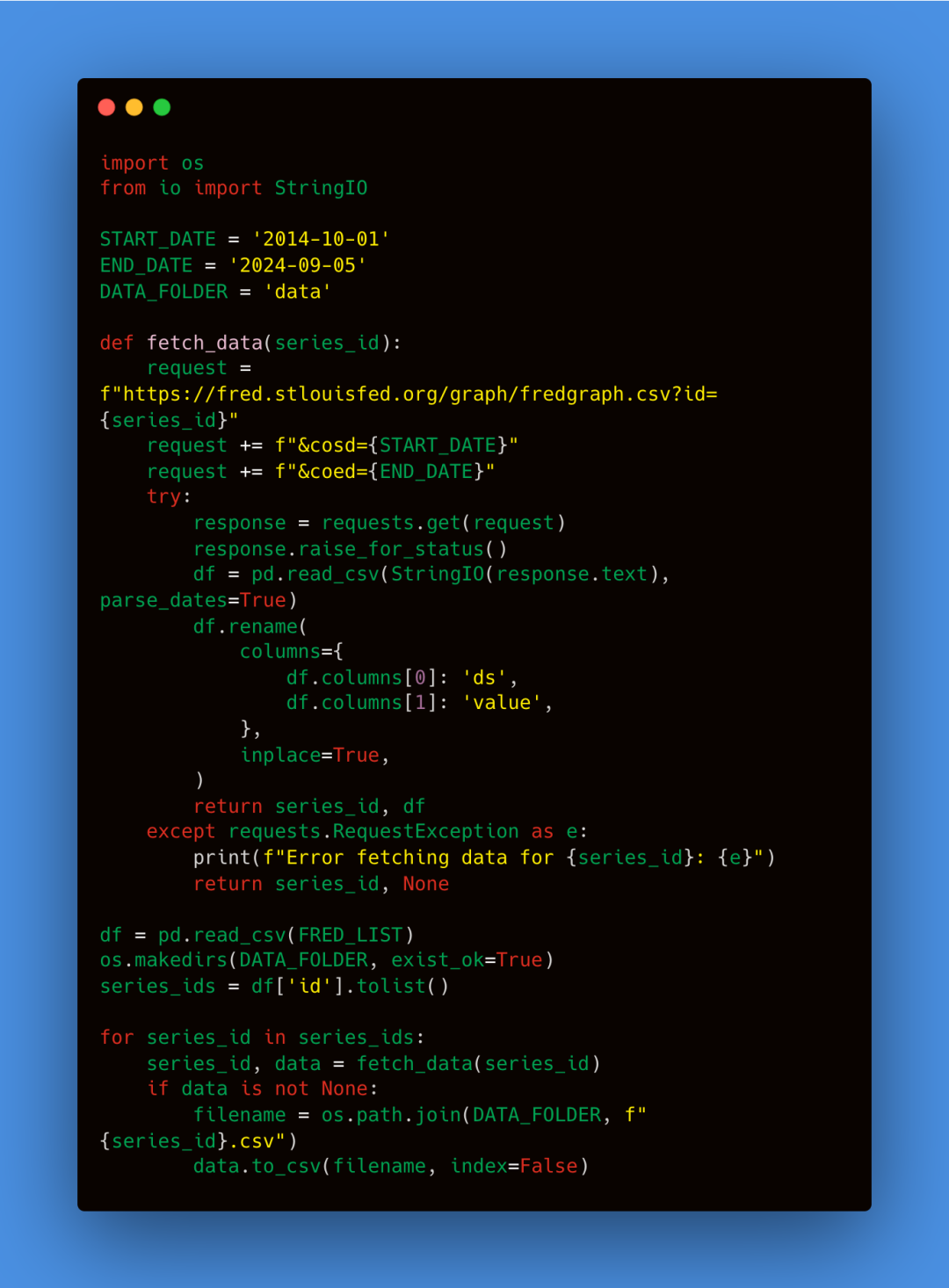
如文章开头所提到的,我们将使用NeuralForecast库和来自FRED的数据来训练一个模型。为了满足NeuralForecast的输入要求,我们需要以特定格式准备我们的数据。Y_df是一个有三列的数据框:unique_id,每条时间序列的唯一标识符;ds列,包含时间戳;以及y列,包含序列的值。因此我们将第一列重命名为ds(df.columns[0] = 'ds')。FRED API返回的日期在第一列,而NeuralForecast要求时间戳使用这个特定的列名,如上所述。接下来,我们将统计数据文件夹中的CSV文件数量,以验证API是否成功获取了我们之前识别的1759个数据序列。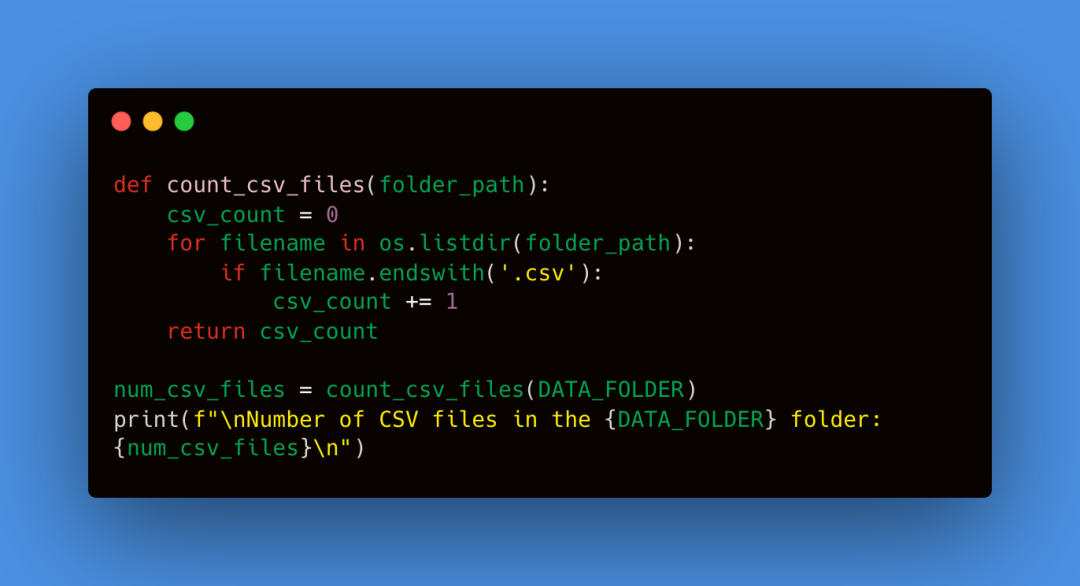

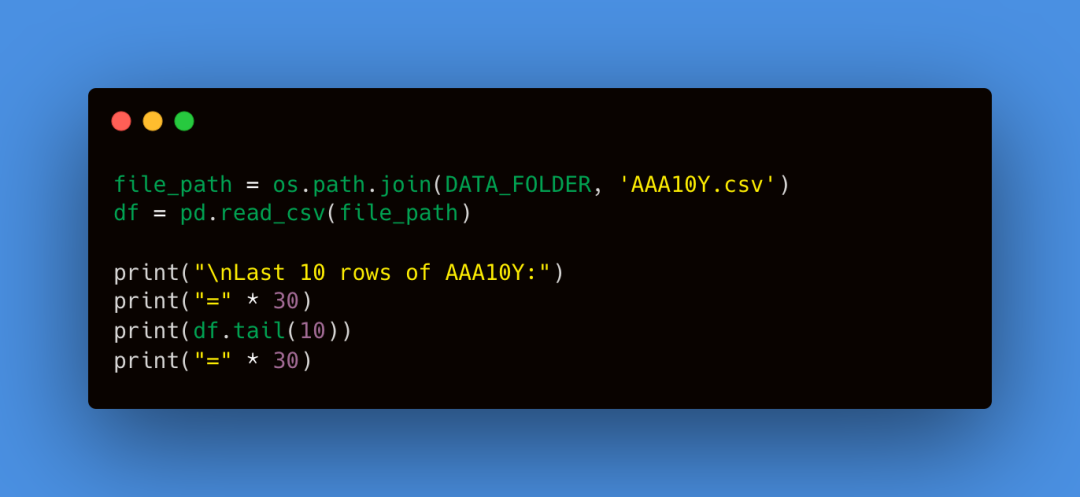
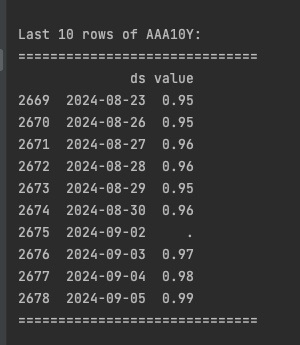
我们缺少劳动节的数据,因为股市在这个假期休市。基于此,接下来我们将准备和清理数据。这个过程对于确保我们的机器学习模型生成准确和稳健的结果至关重要。我们定义了一个函数来确定纽约证券交易所 (NYSE) 交易日,该函数返回纽约证券交易所 (NYSE) 开市的日期。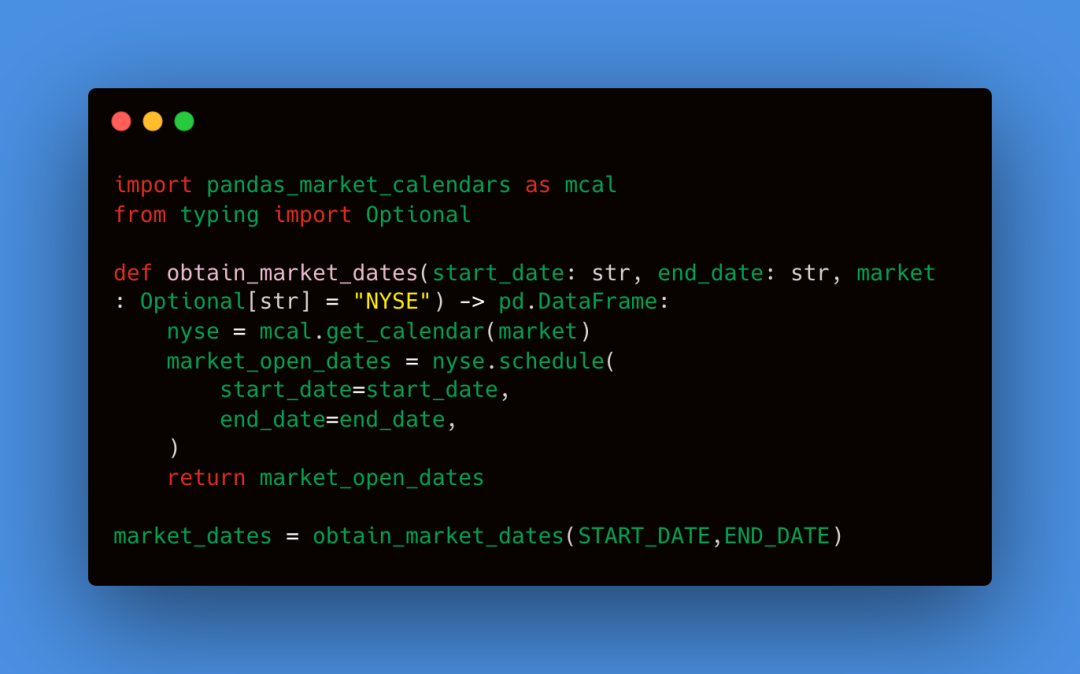
移除缺失值
我们暂时隐藏数据集中的空单元格、None 值或仅包含点号的条目。我们会在下一步替换它们。
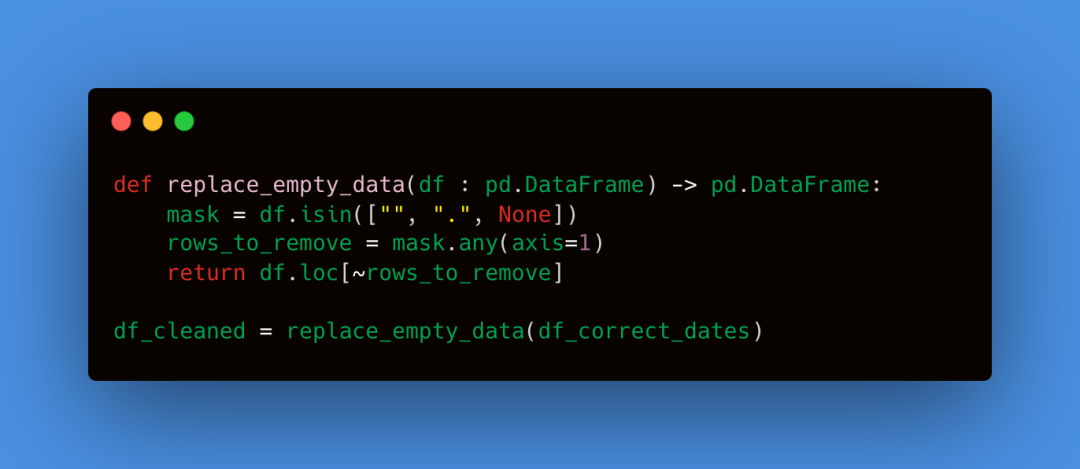
我们用前一个值替换任何缺失值,如果是第一个值,则赋值为 0。为了增强稳健性,我们设定了 2% 的 MAX_MISSING_DATA 阈值,尽管这一阈值可以提高到 5% 而不会引发重大问题。任何缺失数据超过 2% 的序列将被丢弃,并不用于我们的模型。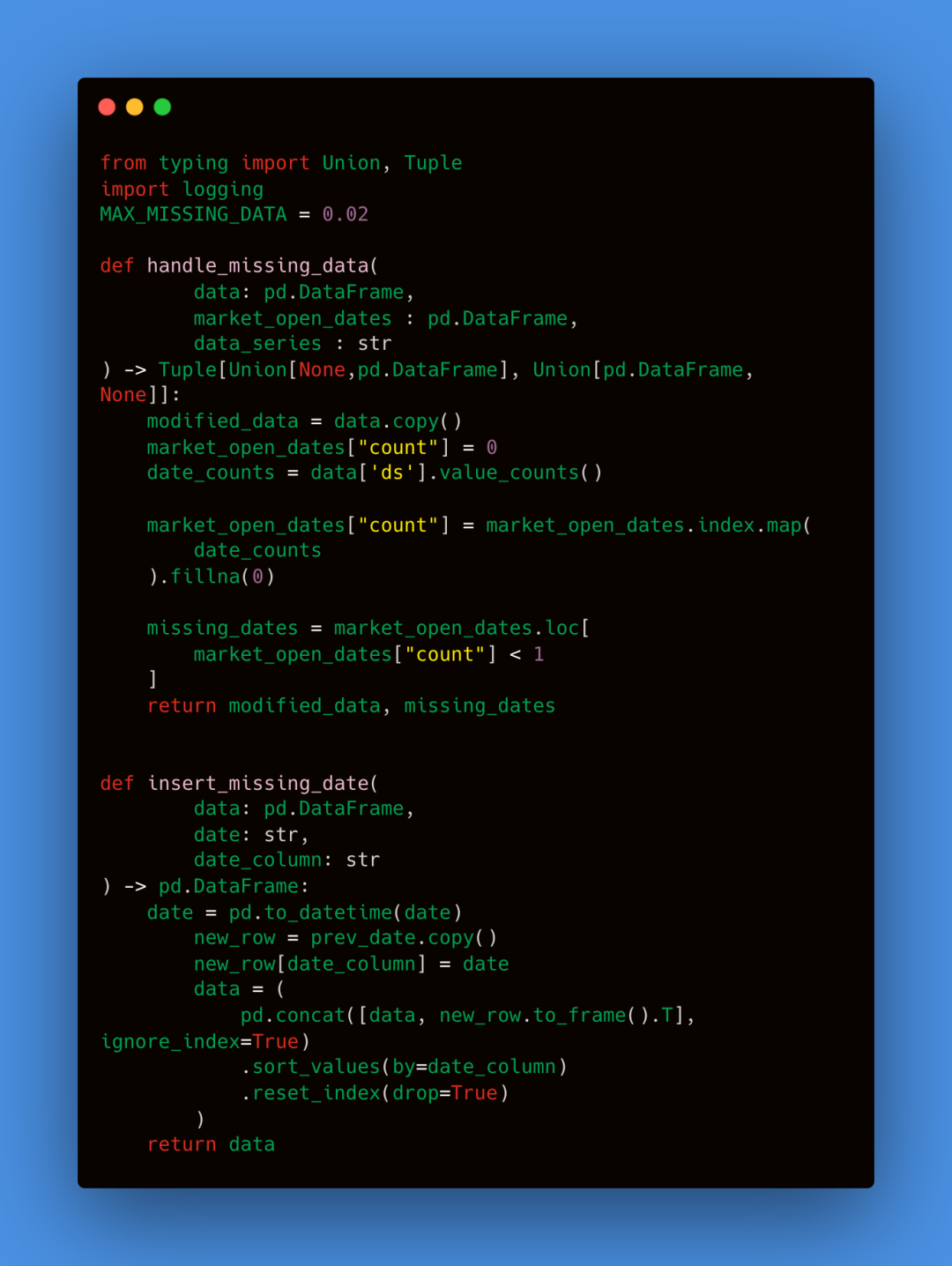
处理单个数据序列
我们分别对每个数据系列应用所有之前的步骤。通过if 'SP500.csv in csv_file:检测到S&P 500系列时,我们直接将其保存在model_data变量中,因为这将是我们预测模型的目标输出。
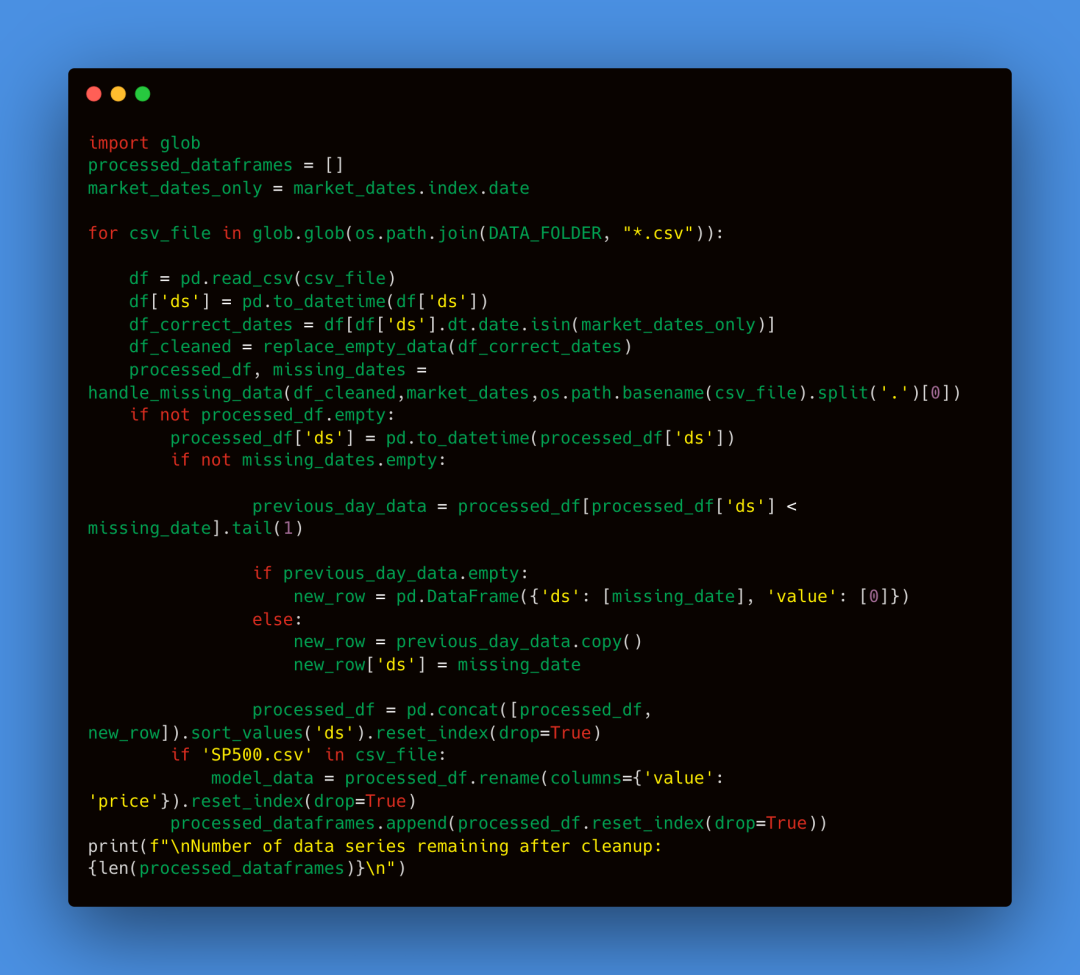

我们从1759个序列中保留了441个,去除了缺失值过多的序列。这种减少部分是由于我们选择了10年的日期范围。然而,剩余的441个序列仍然为我们的深度学习模型构成了一个强大的数据集。理想情况下,我们应该在进行降维之前使数据平稳,如本文详细说明。为了简单起见,我们将跳过这一步。降维虽然是有益的,但是是可选的。尽管我们可以使用所有单独的数据序列来训练模型,但许多数据序列可能高度相关(例如,道琼斯、标普500和罗素等股票指数)。通过降维,我们可以提高模型的鲁棒性和性能。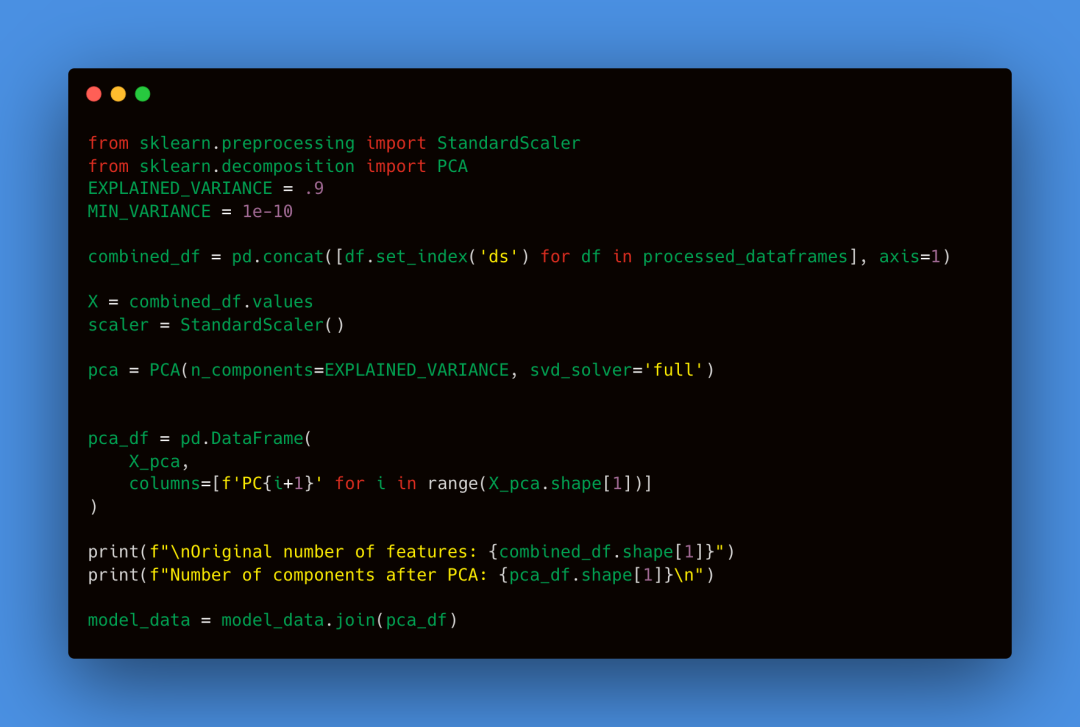
我们使用主成分分析(PCA)进行降维,并使用了90%的解释方差比。这意味着算法将保留足够的主成分以解释原始特征中90%的方差。虽然用PCA进行降维是一种有效且广泛使用的技术,足以满足我们的需求,但它主要考虑特征之间的线性关系。然而,我们将在下一步使用基于Transformer的模型,该模型旨在捕捉数据中的非线性关系。因此,PCA可能会过度简化或忽略模型设计用来检测的复杂非线性模式。我们将使用从FRED获取的数据来预测标准普尔500指数。为此,我们将使用NeuralForecast库中的时间融合Transformer模型(TFT)。值得注意的是,任何包含历史外生变量的NeuralForecast预测模型都适合此任务。
本示例展示了一个基本的预测模型。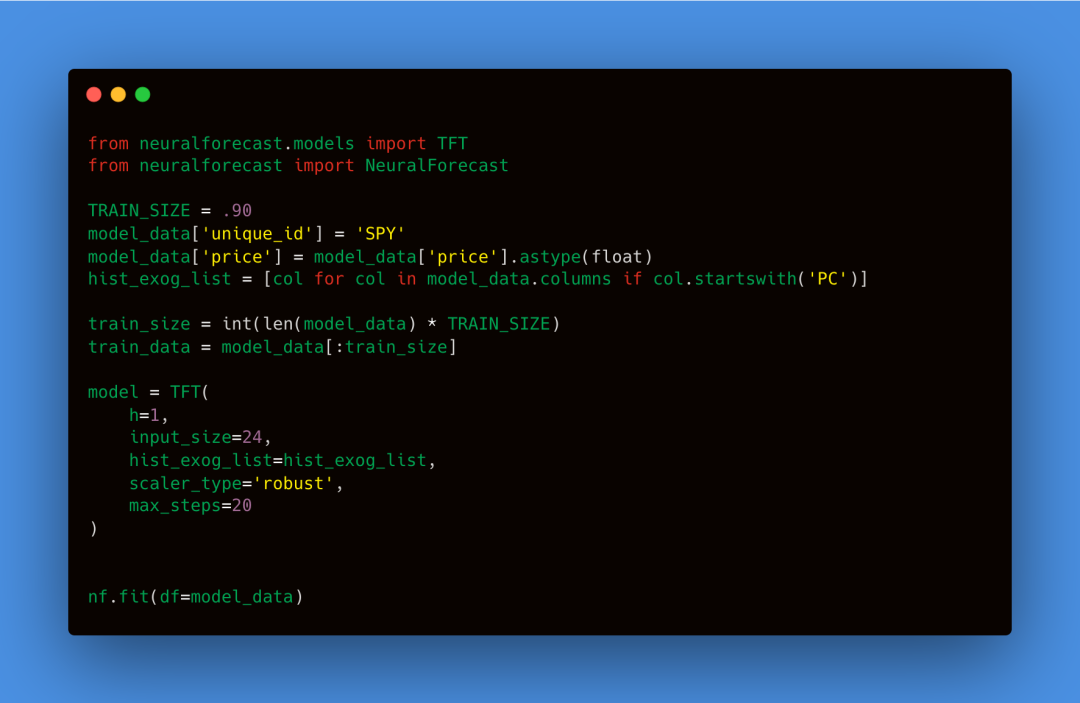
model_data['y'] = model['price'].pct_change()
我们设置了一个1天前的预测时间:h=1
根据NeuralForecast的要求,y表示我们的预测目标,即标准普尔500指数的日回报率。根据NeuralForecast的指南,我们使用hist_exog_list参数指定历史变量。对于我们的模型,这个列表包含了我们之前计算的主成分。
接下来,我们对测试集中的每个数据点生成一天前的预测,预测标准普尔500指数的日回报率。然后,我们通过将每个预测的回报率乘以前一天的价格,将这些回报率预测转换为价格预测。
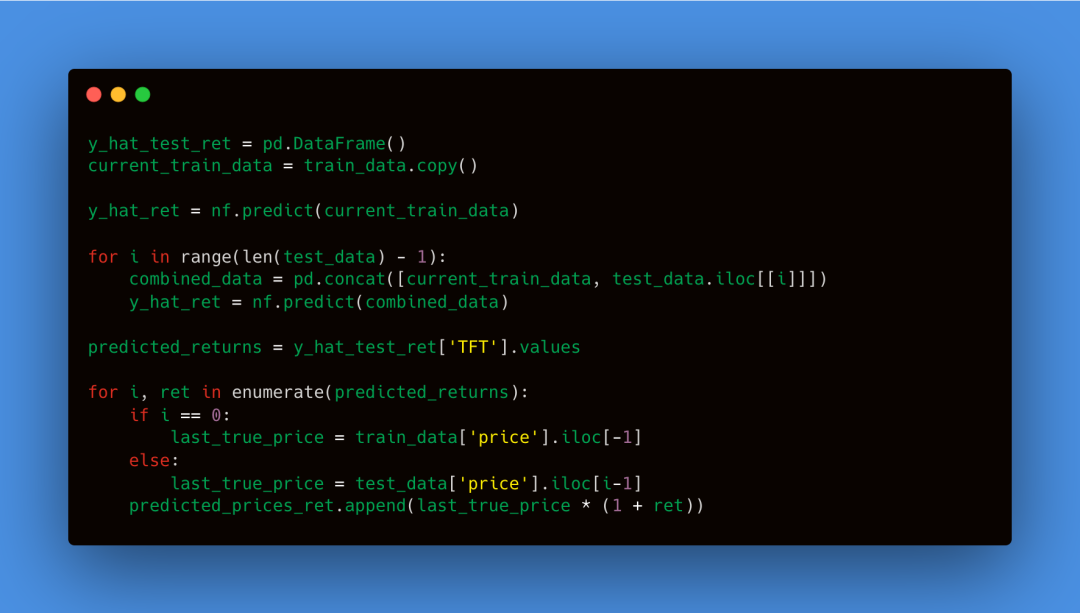
为了展示结果,我们绘制图表,比较模型的预测(红色)与实际的标普500价格(绿色)。
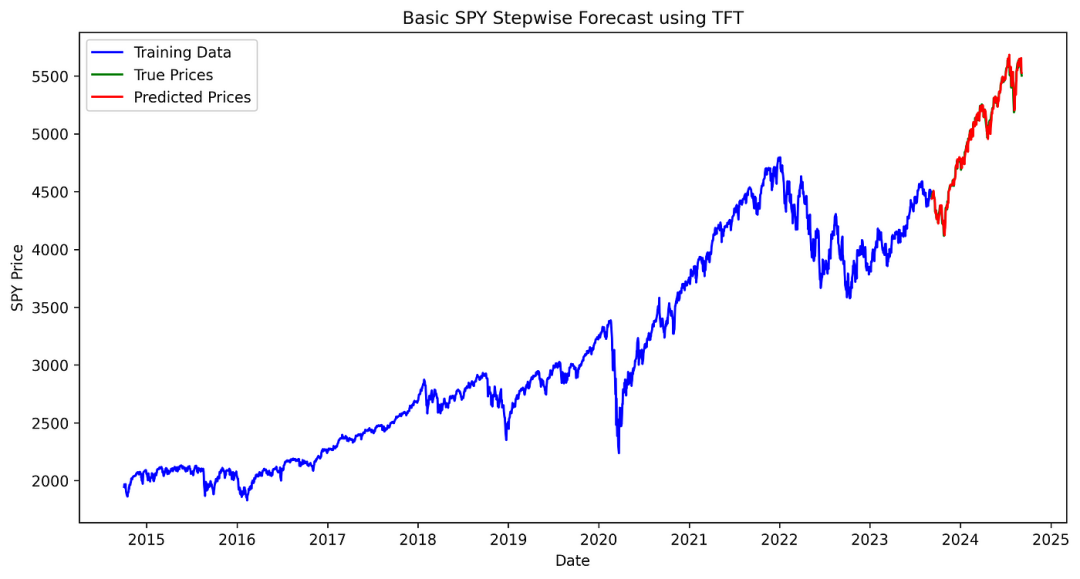
结论
本文学习了如何获取和使用免费且可靠的金融、经济数据来构建股票预测模型。具体来说涵盖了以下内容:1、从FRED API免费获取高质量的金融和经济数据;长按扫码加入宽客邦量化俱乐部获取本文完整源码和文件: