作者 | 网易 CodeWave 团队 何少甫、赵雨森、姜天意低代码 +AIGC 在很多人眼里貌似是一个很“新”的领域,怎么就深水区了?去年在同样的时间点,我们规划并上线了多种低代码 +AIGC 的能力,回顾过去,我们也发现了很多问题。
为了解决低代码的几大问题:低代码平台的使用门槛太高,效率太低,开发质量不高,我们在 23 年结合 CodeWave 相继完成了多种 AI 能力的研发,并成功商业交付了多个项目,如:
自然语言生成逻辑
设计稿转低代码
代码推荐
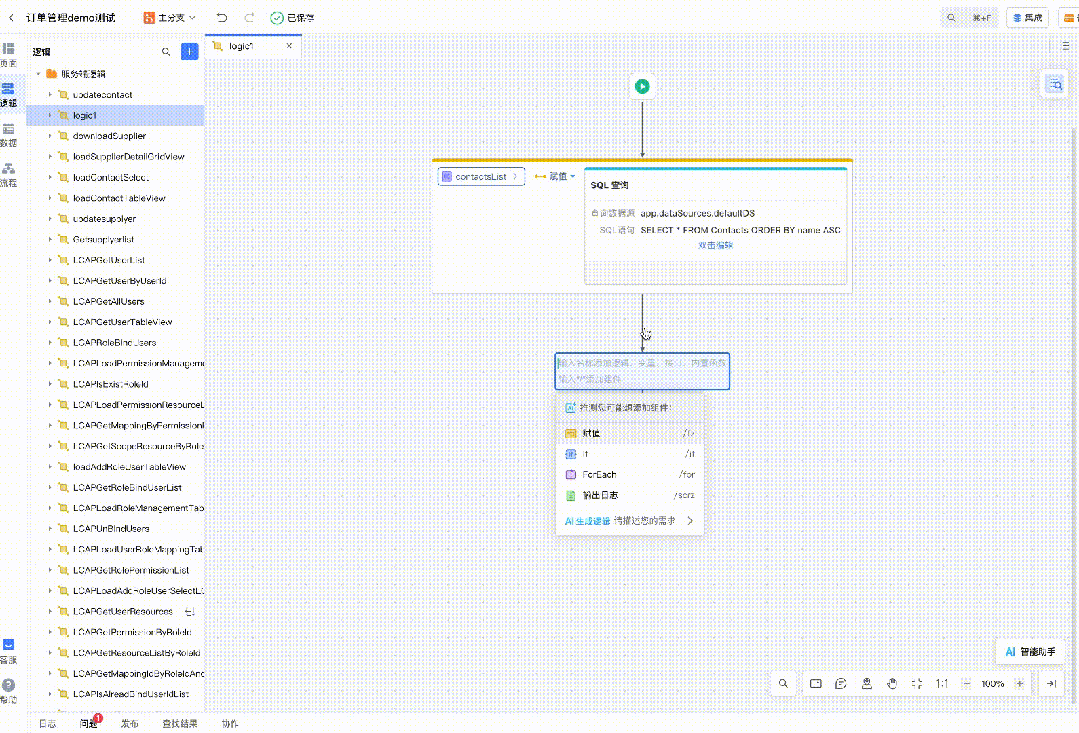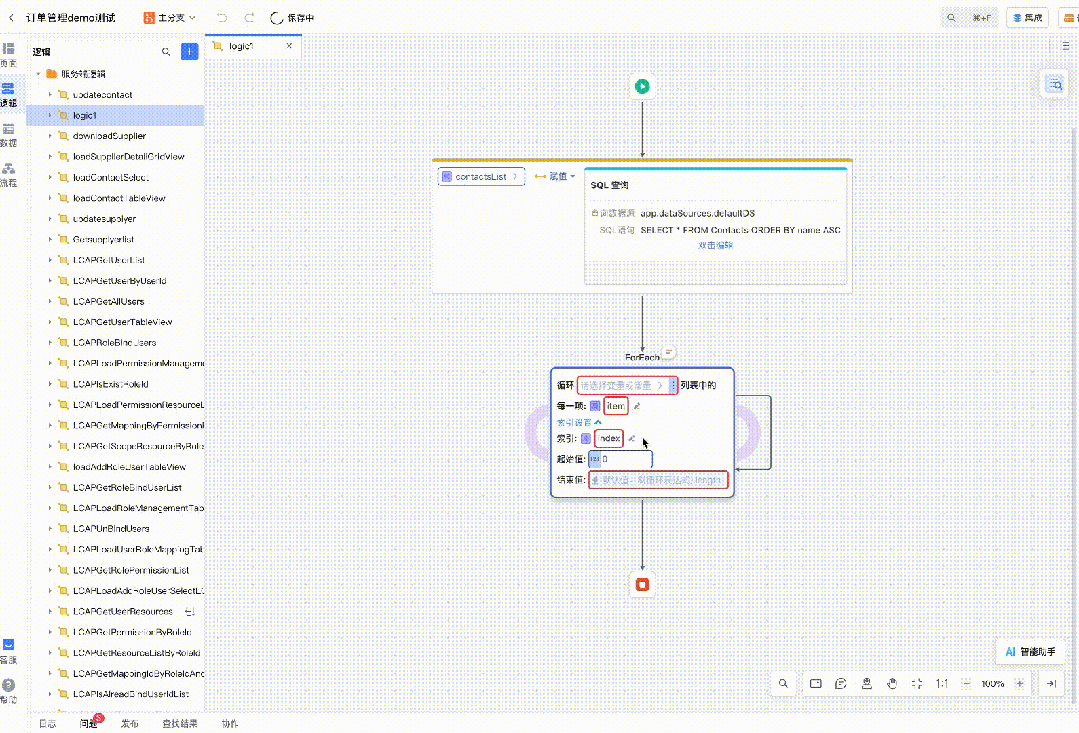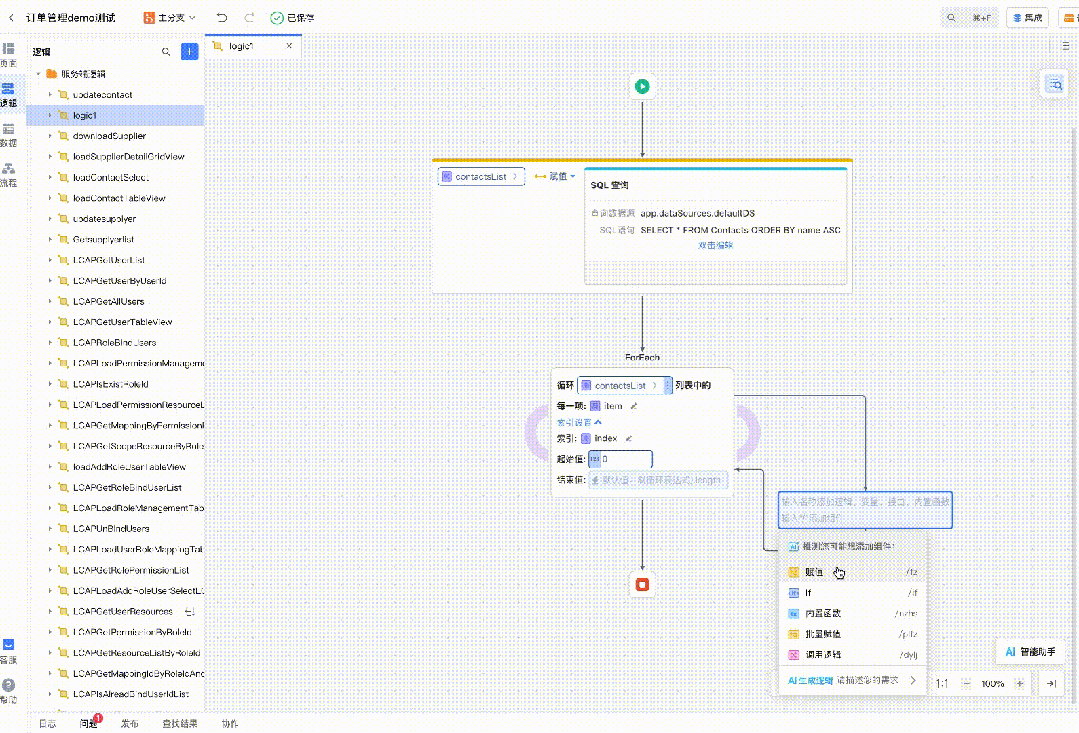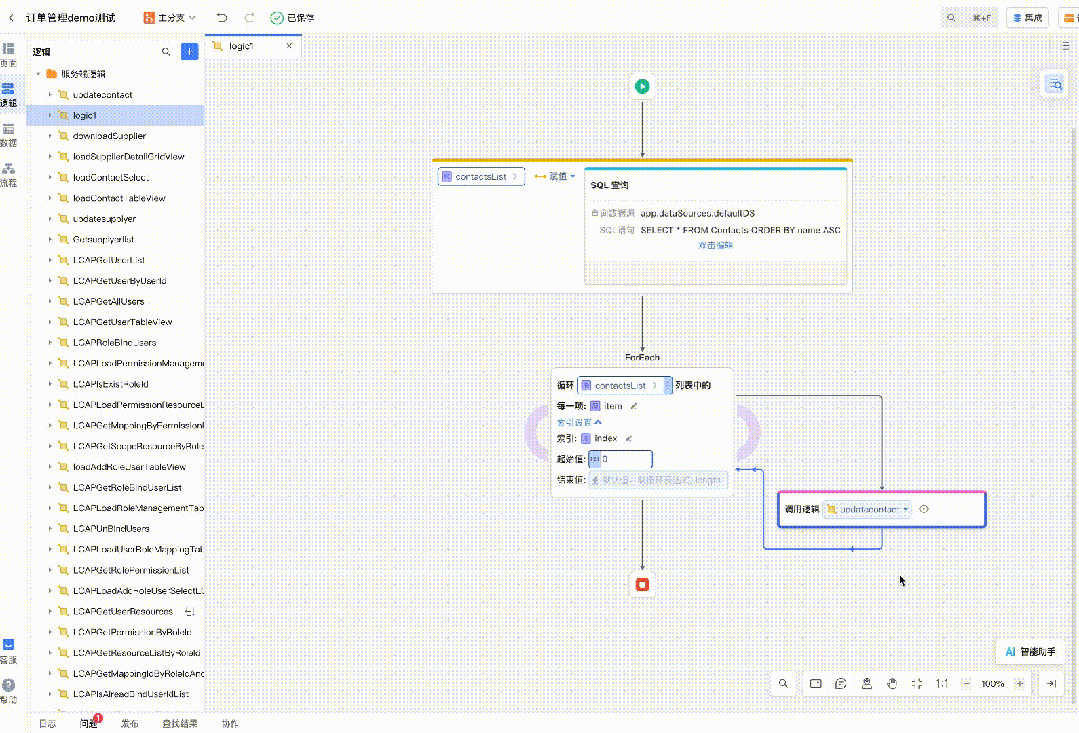
以及图片转低代码、代码解读等等。

今年4月,获InfoQ 【AIGC 最佳技术服务商 TOP10】
对这些技术感兴趣的可以看《如何做一个 GPT 干不掉的低代码产品》。这些 AI 功能为我们带来了巨大的声誉,多次在国内高级别技术会议露脸,并荣获了不少大小奖,以至于团队内(包括我)一直沾沾自喜,完全没有意识到,作为一款商业产品,当时的部分产品能力是达不到商业交付标准的。客户认为产品看起来很酷,但实际产品体验过程中,发现对于它在真实业务使用中能达到什么效果,难以有很好的预期。
同时我们也发现,包括腾讯、阿里、百度的多款低代码产品,在今年上半年做出了几乎不逊色于我们的产品体验,所以我们陷入更深的思考:我们的壁垒到底在哪?
在多个场景下,低代码 +AIGC 效果差。线上数据表明,目前整体的采纳率只有 40% 左右,虽然已经大幅度高于 AI copilot 类产品(业内一般在 20%-25% 左右),但离我们标榜的“ NASL 大模型”数据还差的很远
对低代码的准确度、功能预期难以估量,导致交付困难。很多项目我们自己都会问用户,你们低代码 AI 怎么样才能给我们验收?
低代码的 AI 提效难以度量。每当用户问,低代码 + AI 到底提升了我们多少效率?我们难以应答。
低代码跟 AI 能力割裂。我们发现在产品中,AI 生成的内容难以在低代码中调试修改,同时并没有跟用户当前的操作上下文相关,感觉像是“为了 AI 而 AI”。
重新思考自然语言编程的产品技术能力,发现准确率上不去的原因,保证核心场景的准确率,从而提升使用效果,提升低代码编程的体验。
保证 AI 能力可度量,可量化
在产品上,保证 AI 生成物的可干预和可调试,避免 AI 生成的部分难以维护
从概念性 AI 功能,转变为具体的产品提效点,融入到开发过程中,设计更好的 AI 跟编辑器的结合体验
下面我会从整体的 AI 效果评测,以及细分的自然语言编程和设计稿转页面方向去谈谈,如何更加深入的打磨我们的 AI 产品。
我们都知道 AI 产品需要构建起自己的数据飞轮,才可以在快速构建产品的核心壁垒。CodeWave 通过以下方式构建 CodeWave AI 能力的数据飞轮。
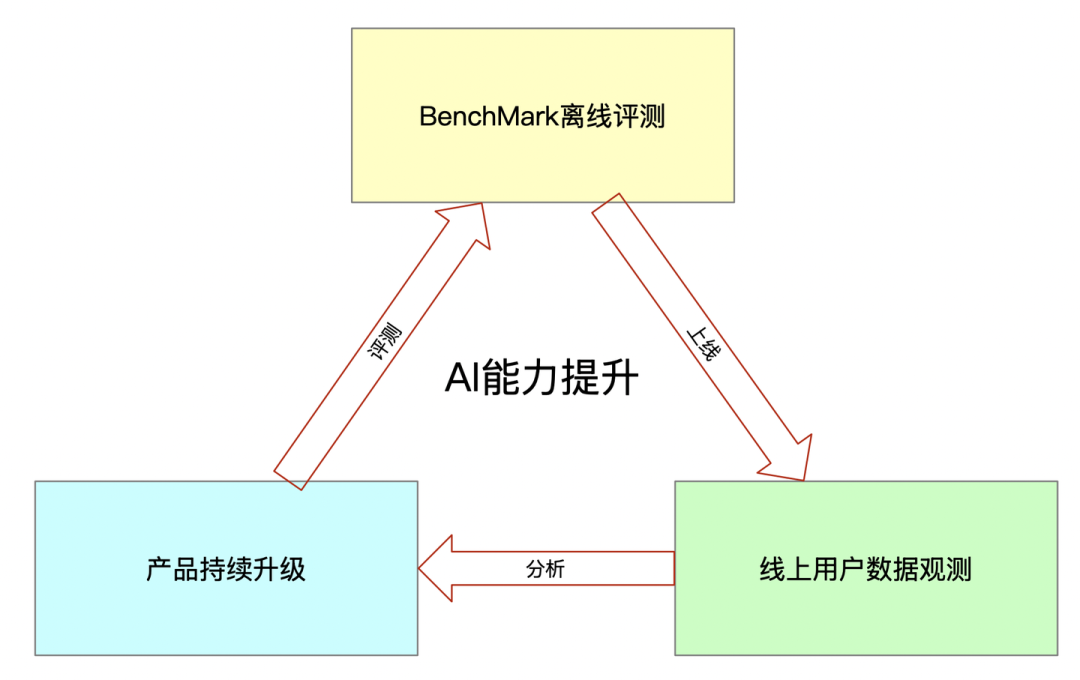
在其中,最重要的点是对 AI 能力的评测。If you can not meature it, you cannot improve it. 这是我工作初期,我老板经常挂在口头的一句话。即使对那如何度量我们的 AI 能力呢,我们从两个角度去展开分析
那我们如何“度量”我们的 AI 能力呢,答案就是通过 Benchmark 的测评来完成。我们通过两套 Benchmark 来评测 AI 的能力:
为了评估 AI 的基础能力,我们会构建通用 BenchMark 来进行 AI 能力的评估,以便于了解 CodeWave AI 能够做到的下限和上限。
通用 BenchMark 主要是指一些通用的 AI 编程能力的评测,与实际客户场景无关的评测。
这类 BenchMark 我们会采用包括 HumanEval 在内的多个编程领域经典数据集,也会通过大模型合成类似的大量通用 AI 能力指令数据,基于此来评价目前 AI 的基础能力。
在自然语言编程场景里,基于 HumanEval 评测集,CodeWave AI 能力做到了 GPT4o 的 80% 以上水平。
评测 AI 在业务场景表现的领域 BenchMark在通用能力评测的基础上,我们同时会构建预备业务属性的领域 BenchMark,来评测用户在使用场景里真实使用 AI 的体验。
为了保证评测的相对科学,我们会通过人工构造和筛选的方式来构建领域 BenchMark 用例,以确保用例在各个主要场景中有比较合理的覆盖度。
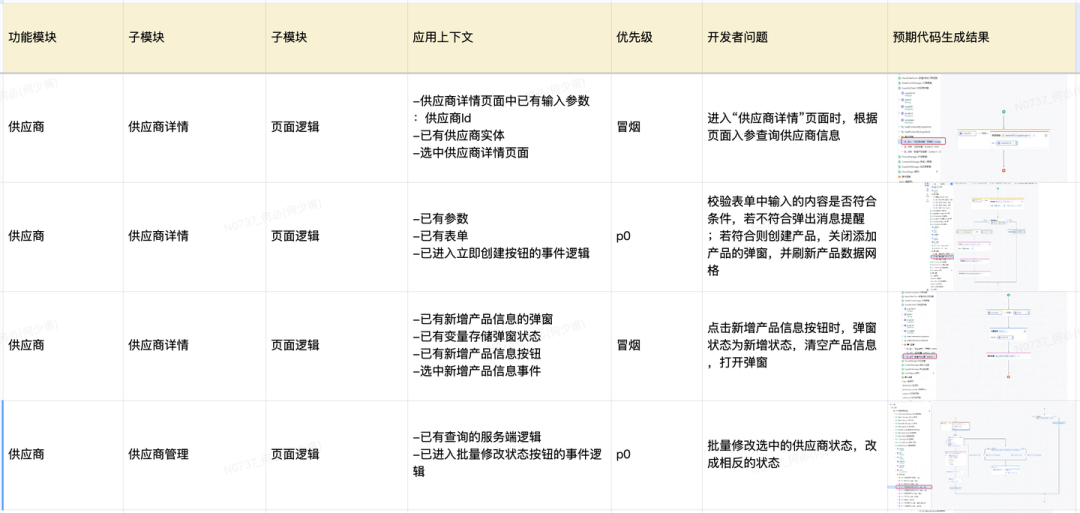
CodeWave AI 在逻辑生成领域评测集下的评测结果,页面逻辑的正确率达到 80%,而服务端逻辑的完全正确率达到 90%。
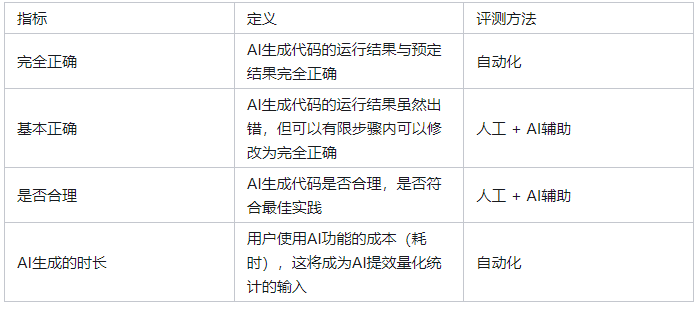
评测的指标也不仅仅只是评测是否正确,还会就合理性,和生成时长进行综合评测,以下为评测的指标示意:
以 BenchMark 的评测结果作为功能上线依据
在有了以后两个两类 BenchMark 之后,CodeWave AI 能力的迭代就有了基准要求。
产品 AI 能力的升级,包括 Prompt、模型或工程方案等技术方案的调整,都需要经过 BenchMark 的评测,只有通过验证的产品升级,才允许上线。
BenchMark 评测的是 AI 能力的表现,但用户最终关心的是 AI 带来的价值。
针对 AI 编程场景,我们也构建一套 AI 功能提效率的量化计算方法,可以计算出:
在 AI 功能上线之前,假设 AI 生成代码正确,用户会直接采纳。那么 BenchMark 评测时正确率与实际提效率的关系,功能上线后才会提效。
AI 功能上线后, AI 生成代码的采纳率与提效率的关系。
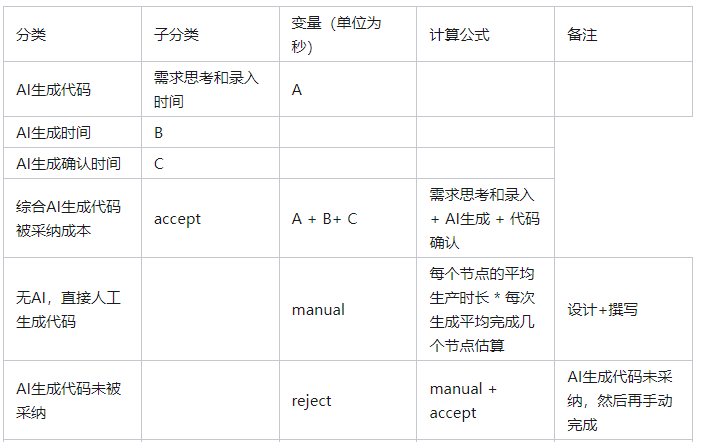

注意:
在以上计算里,当 manual = D 时,E = 0,即没有提升效率
如果要让 E > 0,需要满足两个条件:
通过以上方式计算出 CodeWave 在 AI 逻辑生成能力上的提效率为 25%,这也很好的体现了给用户和业务带来的实际价值。
同时,为了更好的支撑这一系列评测集维护、运行,我们也建立了一整套平台工具来承接这套评测流程。
产品 Benchmark 不是一成不变的,他会根据线上用户的真实使用数据持续迭代,以驱动数据飞轮的运转。
CodeWave 的 AI 工程化平台上管理了各个版本的产品 Benchmark,并且构建了数据回流机制,可以将线上真实使用的数据分批添加到模型训练集、模型验证集和产品 BenchMark 里。
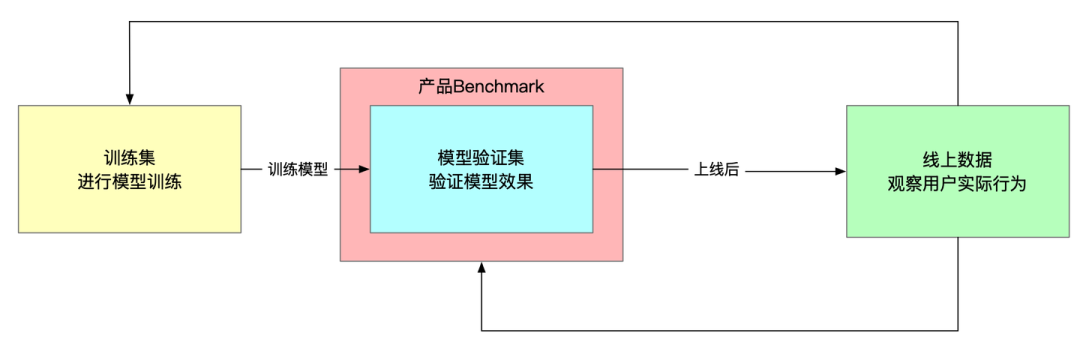
构建测试集:
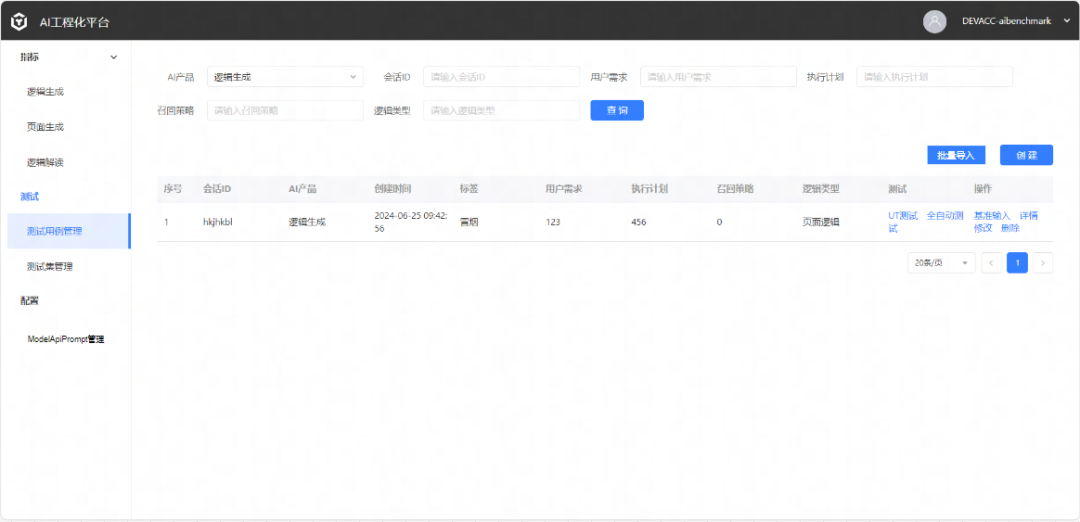
整体流程:
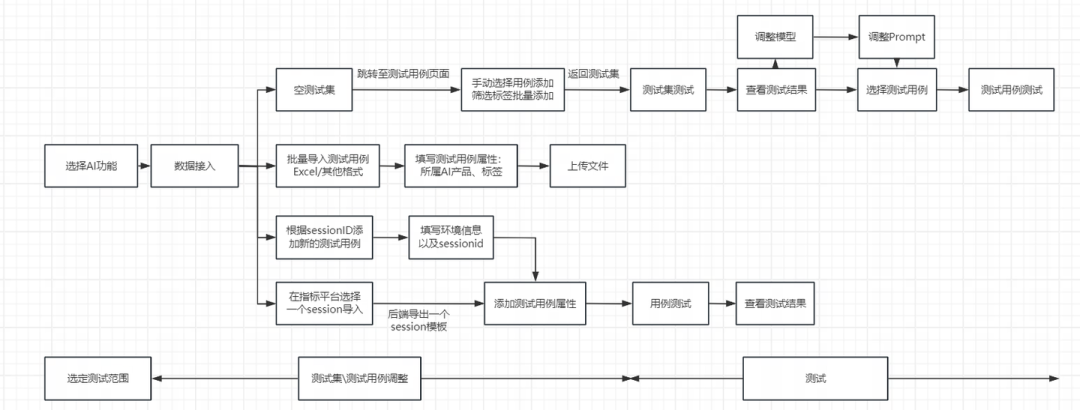
此外,AI 工程化平台还管理了产品 Benchmark 的 UT 测试、E2E 自动化测试等工具,让 AI 功能从改进到评测都能够高效运转,从而大大提升产品迭代的效率。
AI 自动分析:
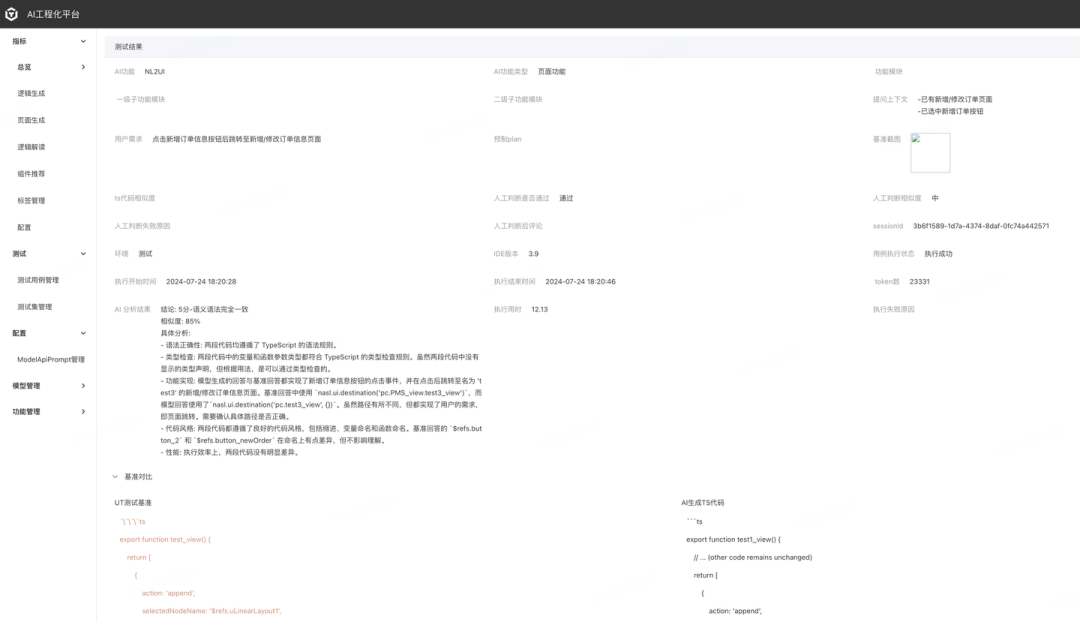
人工确认结果:
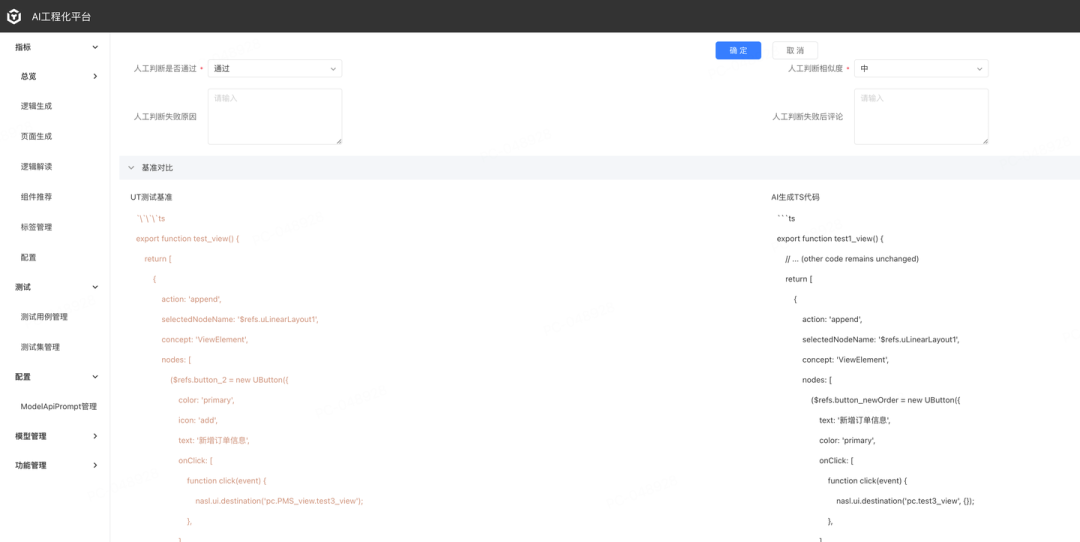
工程能力同时也支撑了目前对外的 AI 服务。
由于低代码很多会面向客户私有化交付,而我们的 SaaS 目前采用的社区较强的模型,导致私有化和 SaaS 的能力有偏移,从用户输入、生成计划到最后生成代码,两条路线存在很多区别,导致 Prompt 优化,后处理校验等逻辑都没法复用。因此考虑到未来的发展,希望通过一个更完善的架构来承接整个 AI 功能。
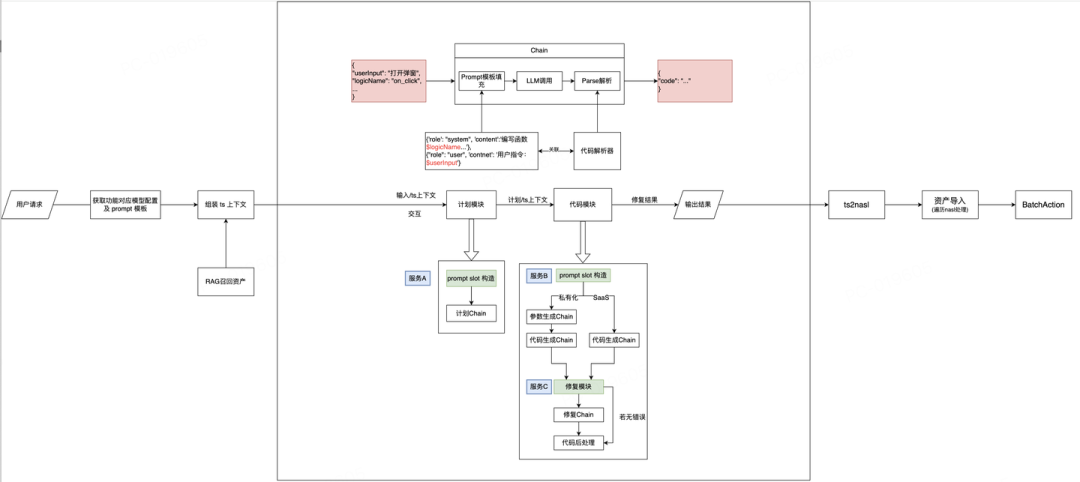
完整的流程为用户请求 - 获取场景 Prompt 模板 - 组装上下文 - 召回需要的资产 - 填充 Prompt 模板 - 调用大模型 - 解析返回值 - 修复代码 - 代码转换。其包括纯 AI 服务和平台侧服务。
AI 侧服务
服务 A:计划 Prompt slot 准备:应用级上下文、函数级上下文、few-shot 召回等
服务 B:代码 Prompt slot 准备:应用级上下文、函数级上下文。
服务 C:代码修复模块,基于规则修复代码,基于检测问题动态组装修复 Prompt。
平台侧服务
上下文信息维护:负责上下文信息的获取,包括系统级上下文、项目级上下文、函数级上下文等等。
Prompt 模板维护:负责不同版本的 Prompt 管理、填充槽管理。
llm 调用维护:负责对不同 LLM 调用进行维护、管理、记录。包括云端 API 调用和私有化 TGI 模型调用。
结果解析模块:负责解析输出的内容并转换为低代码需要的产物。
通过这样的架构,我们不仅可以保证线上线下的 AI 功能,通过一套架构方便维护,同时也可以尽可能地复用各种模型优化策略,提升整体的可用性。
低代码设计之初,采用了 NASL 作为低代码的基础语言,由基础语言和 Web 应用特定领域(如数据定义、数据查询、页面、流程、权限等)的子语言集合。他通过一套基础的语言系统(例如类型、常量变量、表达式等)支撑了各种 Web 应用的领域语言,做到了一套语言就可以描述 Web 应用开发的方方面面。

基于这样的设计构建能够生产 NASL 的低代码平台,并将生成的 NASL 转换为应用实际运行时的前后端代码,就可以完成应用从开发到构建部署的全流程了。
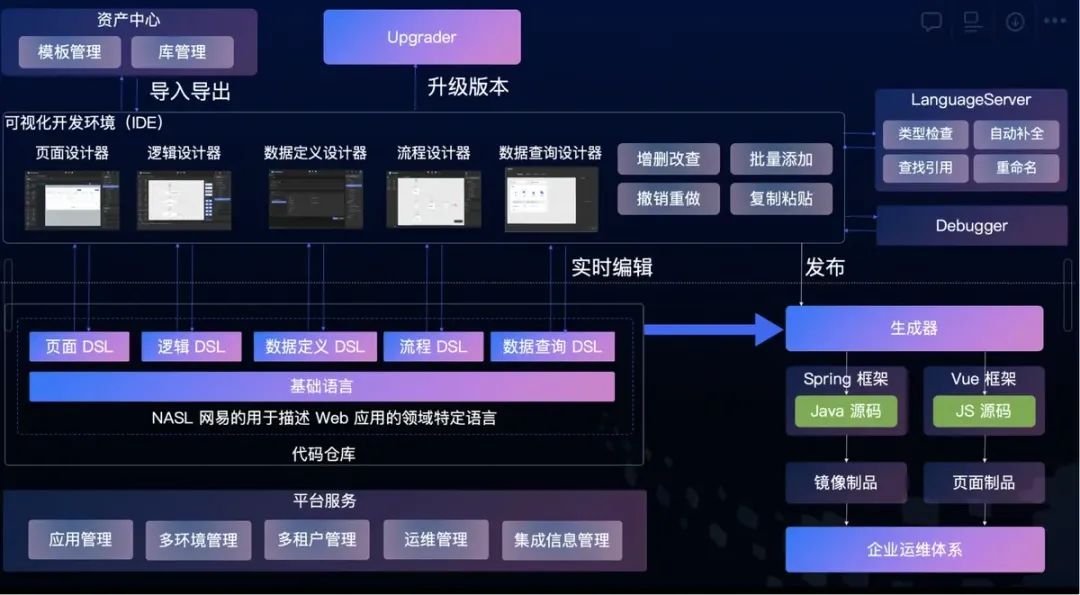
在我们看来,通过 Nasl 来定义编程语言,并以此设计低代码平台架构的优势,主要体现在三点:
产品上限高。能够通过丰富的表达能力来表达 Web 开发中的各种场景,包括页面、数据查询、逻辑、流程等,并且可以根据业务的需求定制翻译能力
质量可控。尽可能减少专业概念的数量,通过类型检查、静态、动态分析和排错来降低用户写出低质量代码的可能性。
AI 友好。通过统一的 NASL 语言及可扩展的定义,可以方便的对大模型进行训练后让其生成,不需要让大模型生成各种语言框架,这点是 CodeWave 平台区别于其他低代码平台的重要因素:一颗大心脏。只有架构本身对 AI 友好, 才能更好的结合 AIGC 能力。
前两者已经通过很多的商业项目验证,第三者本来我们以为是意外之喜,实际上完全不是这个样子。
NASL 早期在浏览器的宿主语言是 TypeScript,我们通过 few shot+finetune 基础模型的方式,让大模型生成 Embedded typescript 再转换成 NASL 来渲染运行。但事实上我们会发现,多种场景下 AI 能够生成 TS 代码,但无法转换成 NASL 。
情况分析
根据之前的训练经验,初步摸排和列举了 NASL 与 TS 的设计差异会导致 AI 生成的正确率降低的情况。主要分成几类:
NASL(语义或 API)表达不出 TS 的语义(也就是说,AI 生成的 TS 代码会超出产品范围)
这类场景一定会导致成功率和正确率下降。如 NASL 的 sort 跟 ts 不一致,NASL 缺少 optional chaining,不支持短路,break continue 等。
TS 转换成 NASL 成本较大,往往 transform 后处理语义不一致
这类场景目前也很容易导致成功率和正确率下降,如 NASL 的异步 return result 跟 TS 差异较大,如块级作用域,如 NASL 中用用 match 实现的 switch 可能会带来语义不一致等。
NASL 限制会增加对 Prompt 的要求和上下文导致 TS 本身质量的下降
由于 AI 生成通用逻辑需求大致可以分成两大类数据和算法(列表、结构、字符串、数值等)+ 低代码框架(跳转页面、事件逻辑、数据查询、实体逻辑调用、组件逻辑调用等)。
为了更加准确的评判 NASL 语言的能力,我们也使用了业内比较流行的 human eval 来进行语言评测,通过 Human Eval Benchmark 牵引产品生成数据和算法类代码能力的提升。,结果如图
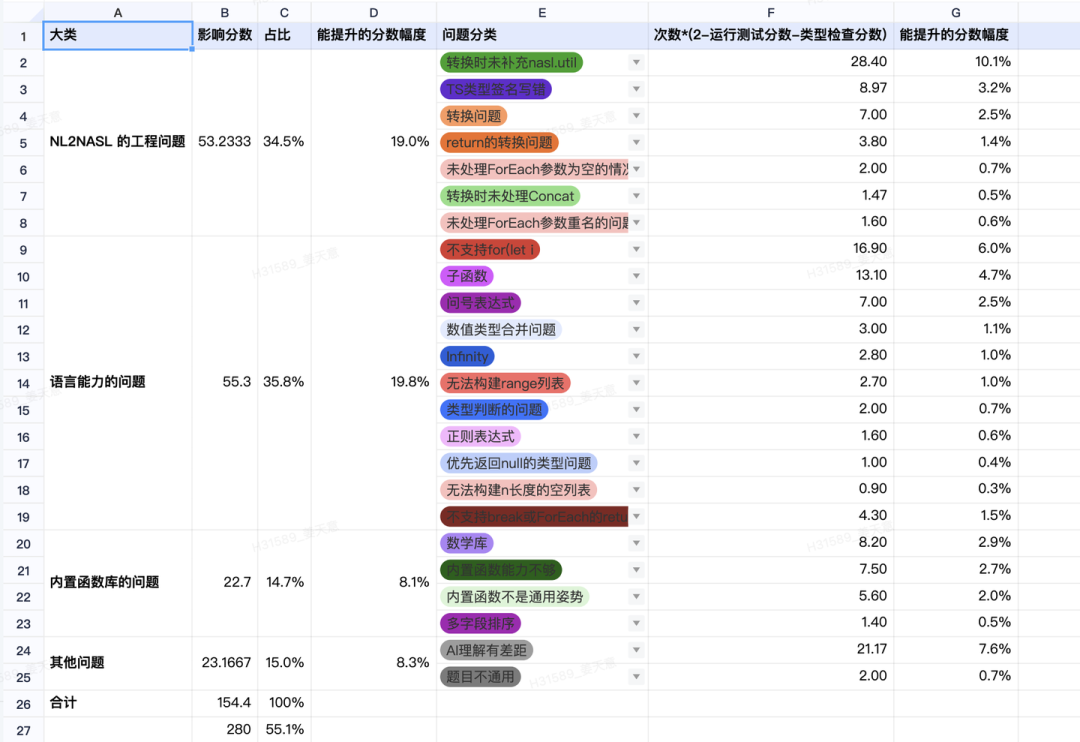
可以看到,通过评测集,我们发现了大量语言和工程层面的问题,有些是工程侧没有兜底,有些是语言能力不支持。通过成熟的 BenchMark 定位到了合适的优化方向,再次印证了前面的 If you can not meature it, you cannot improve it.
有了问题才有了优化方向。解决思路上我们分为工程侧和语言侧来处理。
目前 9 月底已经完成了第一轮工程侧的处理,human eval 的得分已经提升了 10+ 以上分数,同时由于 Human Eval BenchMark 我们也在跟 ai 团队合作,寻找和构建更贴合 web 开发场景,更适合低代码业务的 BenchMark,从更加全面的思路来评判语言本身。
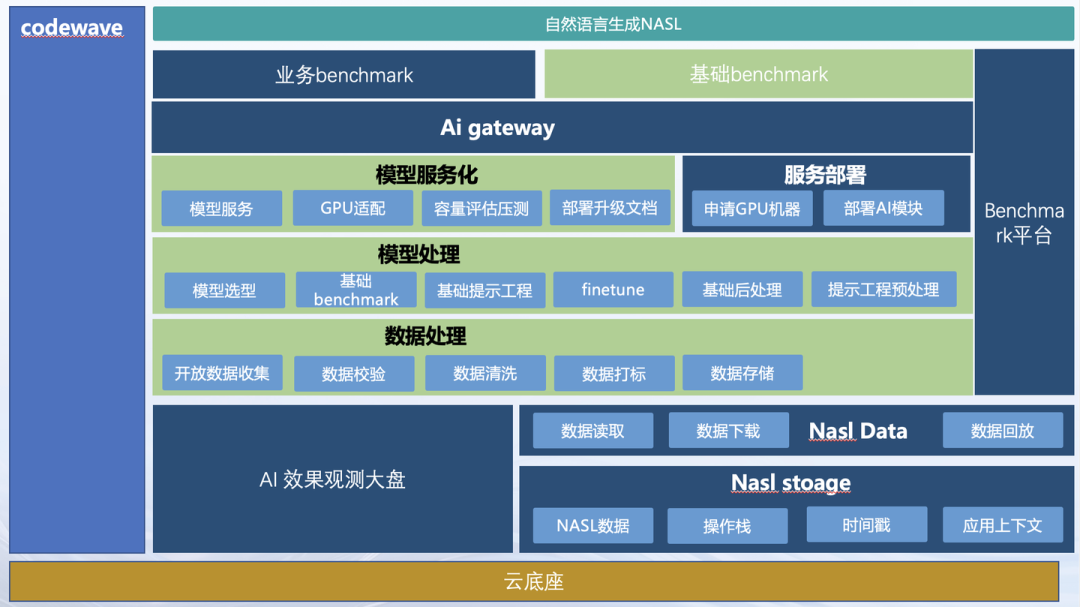
从第一个问题出发,我们思考第二个问题:用户真的会有那么多稀奇古怪的编程场景吗?用户用我们平台是为了解决什么问题?
虽然我们在通用环节,建立了不少的 BenchMark,从线上的采纳率和代码留存率来看,和 BenchMark 的正确率差异较大。理论上如果代码生成正确,用户大概率会采纳代码且代码留存率也会很高。但我们发现
8 月份的数据,采纳率为 60%(数据偏大),平均代码相似度(一小时后留存的代码 / 生成的代码)为 40%,AI 生成的代码最终留存的只有 24%,与 80 -90% 的正确性差别很大。
数据说话,我们拉取了目前内部项目的 NASL 数据,对逻辑进行了详细分析:
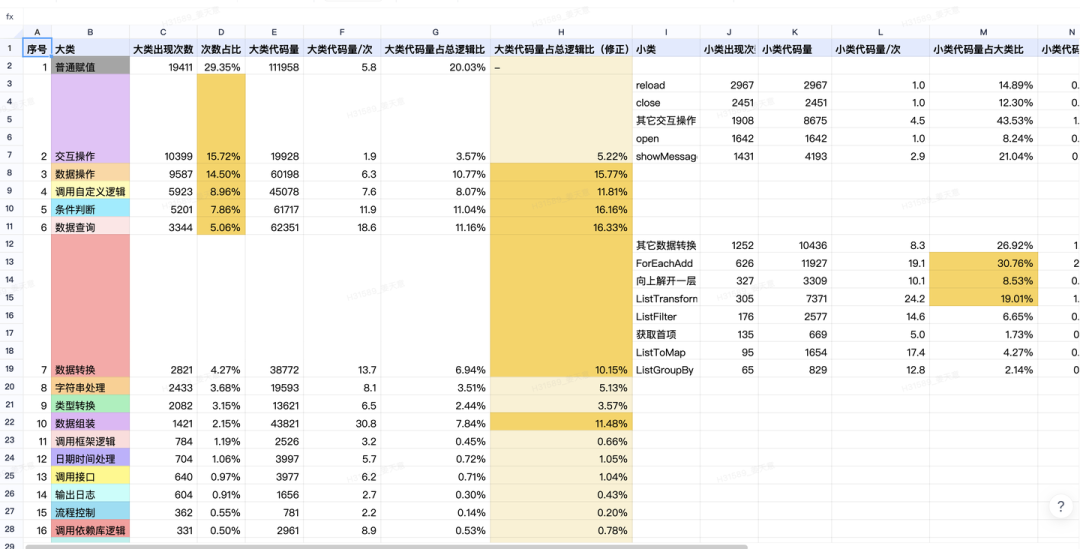
根据分析,对于用户的核心场景,目前的自然语言编程存在以下问题:
因此,为了能够尽可能减少用户的操作,并且保证核心链路的准确性,我们的产品思路逐步转变为特定场景代码生成:
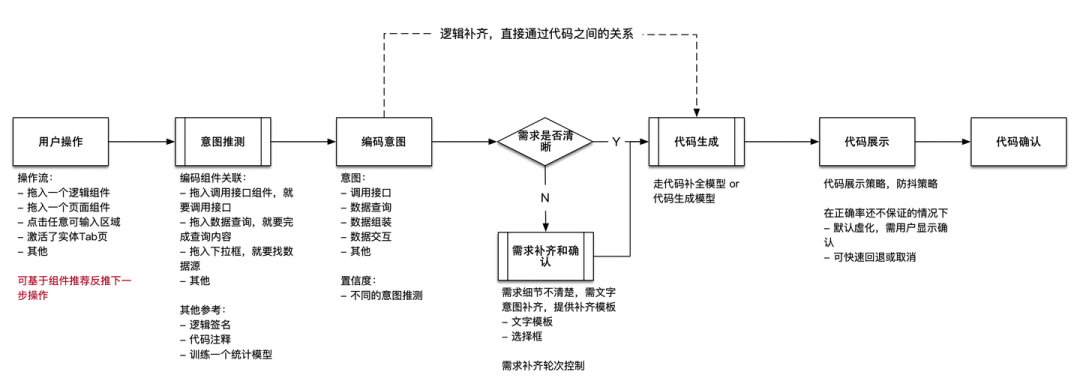
简单来讲,分析用户的意图,根据用户的意图去推断用户想要生成的代码,不局限在自然语言生成这一条途径上。如果找到了明确的高频场景,甚至可以沉淀成平台模板、组件和 Framework 能力。
D2C(Design to code) 能力是智能软件开发中一个成熟的方向,也是 AIGC 重要的落地场景之一。GPT 4V 发布的时候演示的手绘稿转页面也是 D2C 能力。满足了客户对 AIGC 落地的诉求,体现了竞争优势。这块功能我们在对客户讲解的时候,很容易得到客户的认可,也不用费力证明提效价值在哪(显然)。
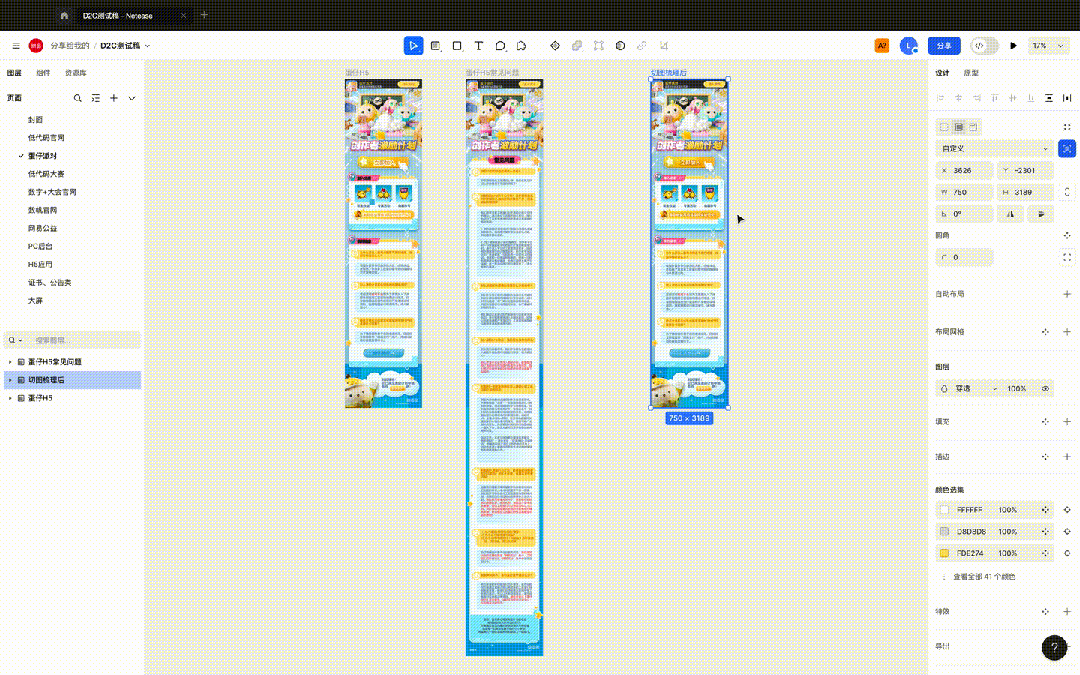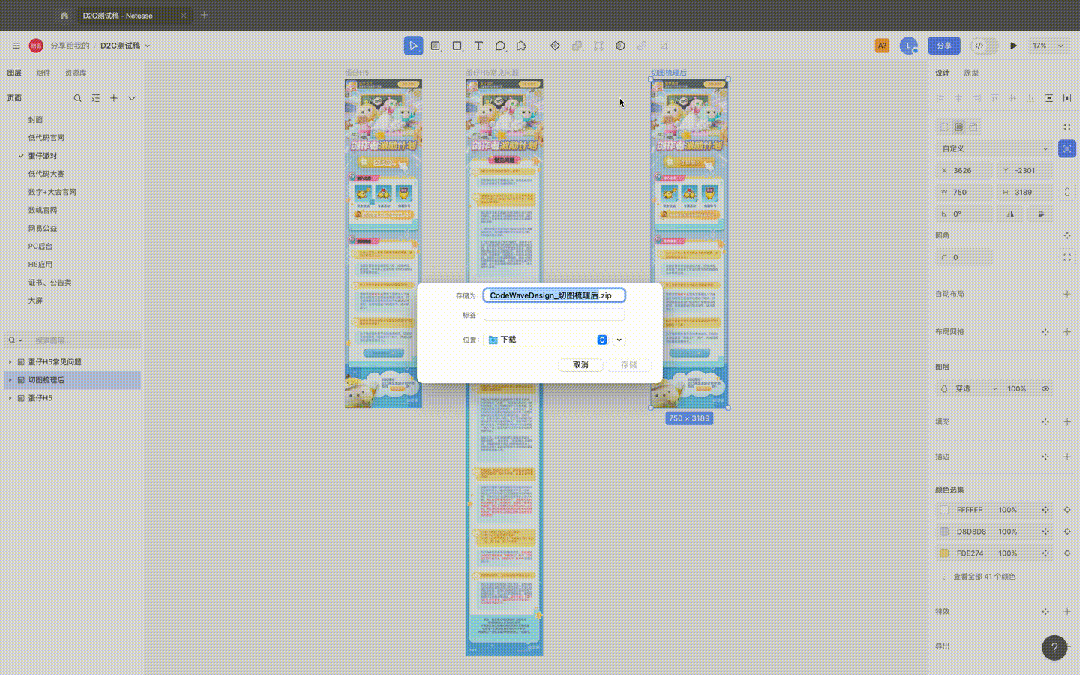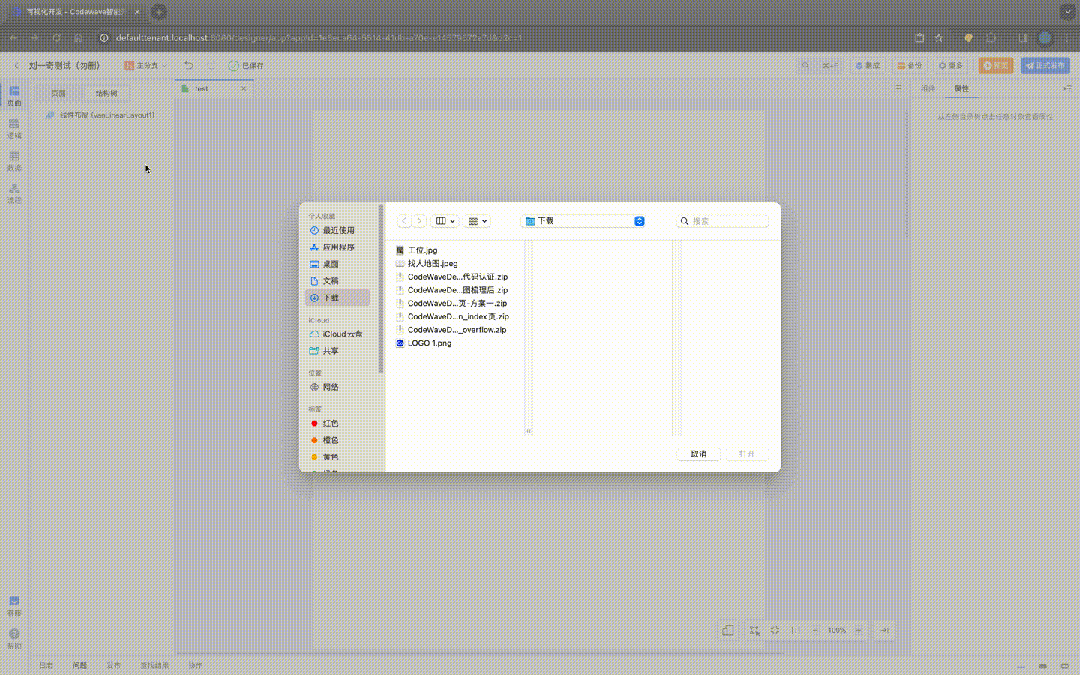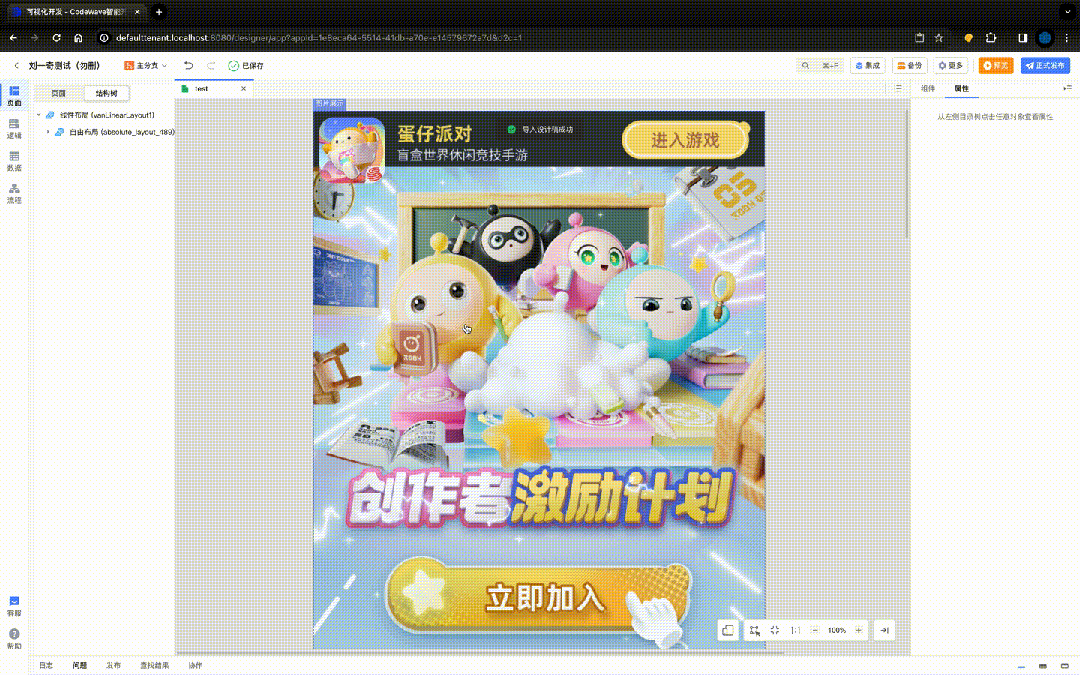
CodeWave 的 D2C 技术早先是先用规则将组件筛选出来,然后让模型确认,这样带来了很高的准确率和识别效率,开发量也较少。举例:

但 D2C 能力在交付的时候,仍然存在以下问题:
难以预估用户的设计稿情况,在用户设计稿不规范的情况下识别准确率会大幅度下降。
基于规则和模型结合的技术方案难以扩展,很多识别规则都是 hard code
识别出来的布局仍然是自由布局,跟低代码以及传统代码编写的布局差异较大。
因此我们首先梳理了整个架构,采用 Pipeline 方式:
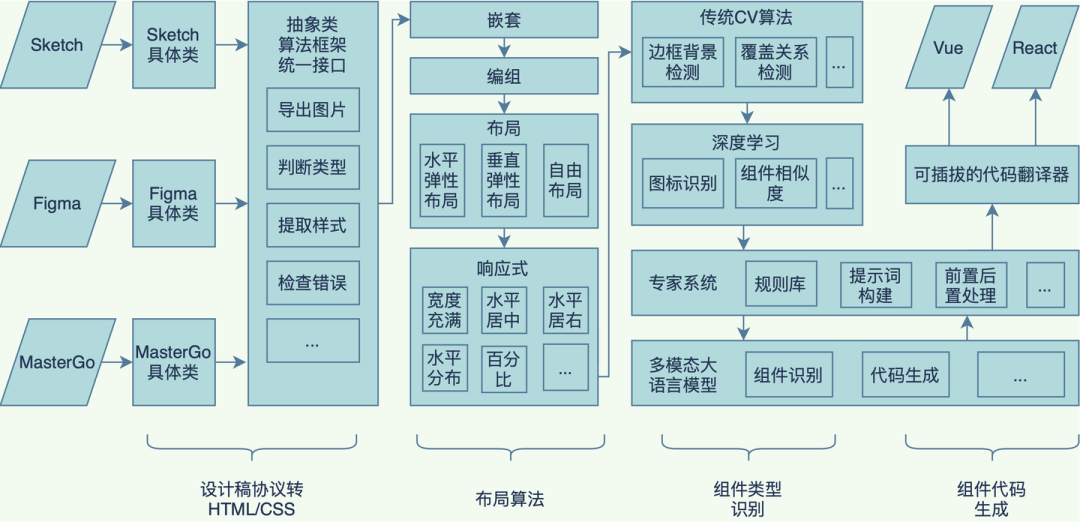
Pipeline 方式可以自由的在组件识别中插拔节点,方便加入布局识别、组件类型识别增强等等,能够带来以下的一些优势:
速度快:对设计稿协议进行预处理,减少大模型需要处理的 Token 数量,进而提升速度。
准确率高:相比将整个设计稿协议输入给大模型识别,本算法进行了任务拆分,将可编程的任务交给确定性更强的编程,其他任务交给深度学习,由于拆分后的子任务的难度降低,因此准确率也更高。
可私有化部署:本算法在 SaaS 环境是基于 GPT4 和 GPT4V 实现的,但由于识别任务已经降级为文本分类和图片分类这样的简单任务,因此无论使用开源多模态大模型或者训练较小的深度学习模型都是可行的。
拓展性强:组件识别采用管道架构,每个组件识别规则均已经插件化,可快速拓展其他组件。
之后我们根据设计稿的不同情况,设计实现了从自由布局转线性布局的能力。
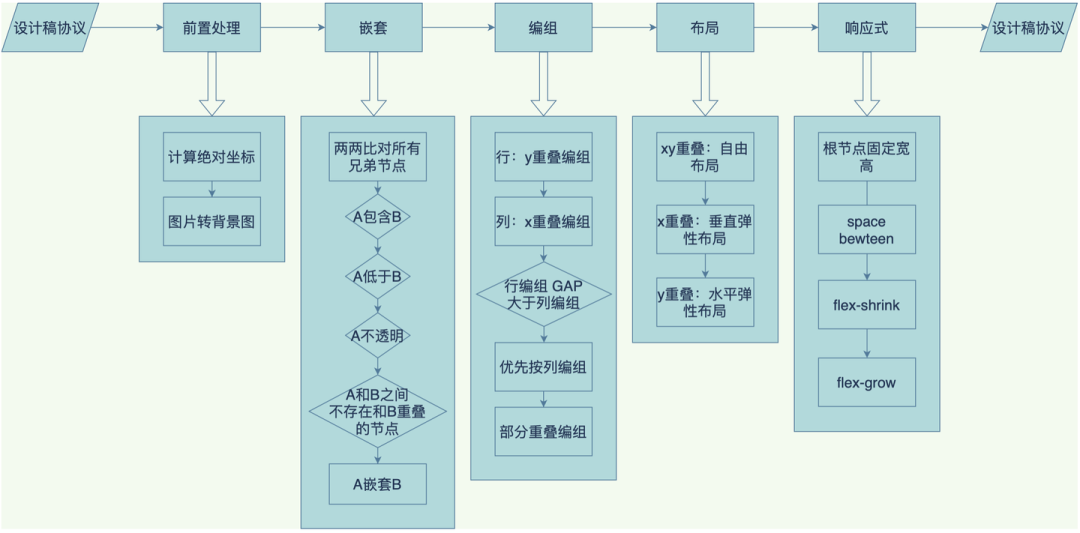
解决了布局问题,顺便也解决了响应式问题。这样 D2C 搭建出来的页面,就符合前端正常的布局开发标准了。
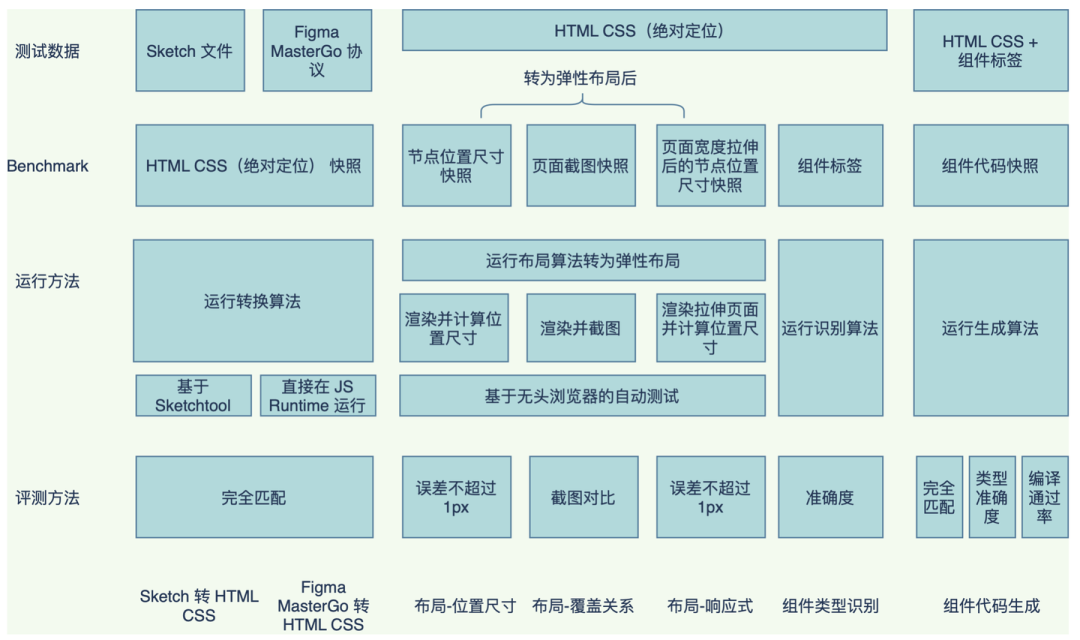
为了保证效果成熟可验证可量化,我们同样参考前文,也建立了完整的 D2C BenchMark 体系,包括:
组件识别 BenchMark,验证整体
组件识别的准确性组件预筛选 BenchMark,验证规则的准确性
布局转换 BenchMark,验证布局处理的准确性
代码生成 BenchMark,验证组件识别后转换为低代码是否准确
自动化测试平台
组件识别 BenchMark 举例:
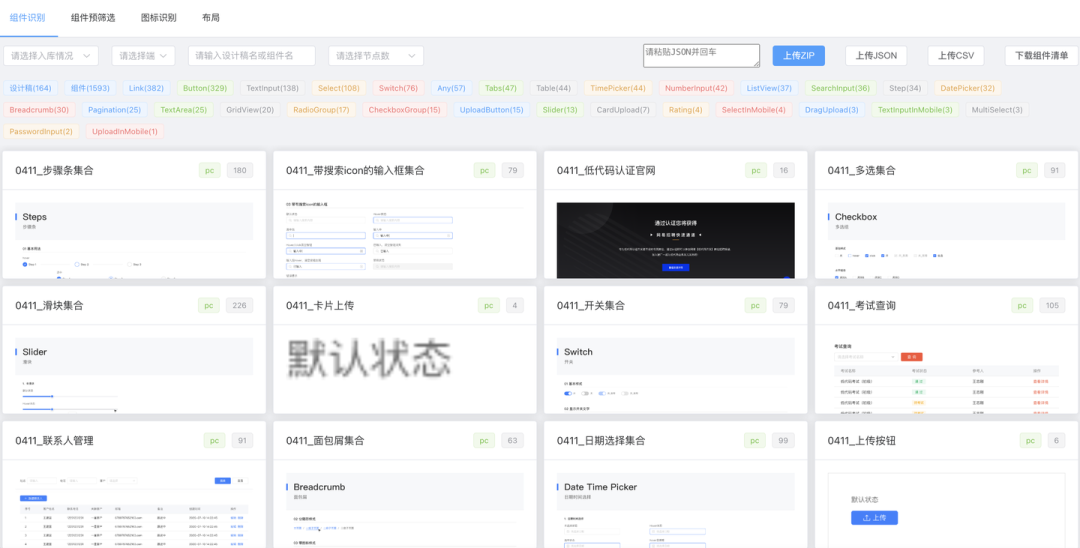
组件预筛选 BenchMark 举例:
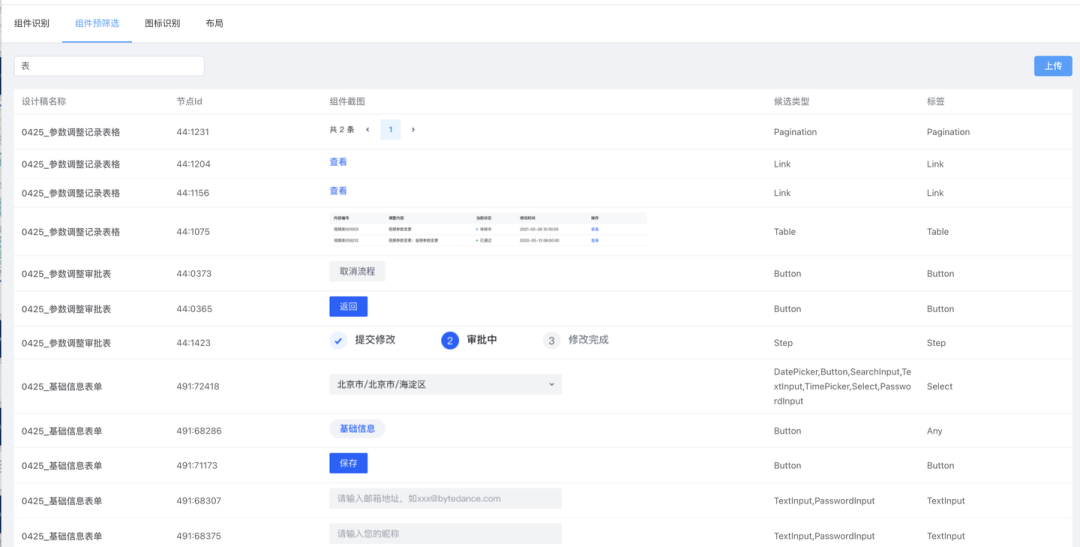
布局识别 BenchMark 举例:
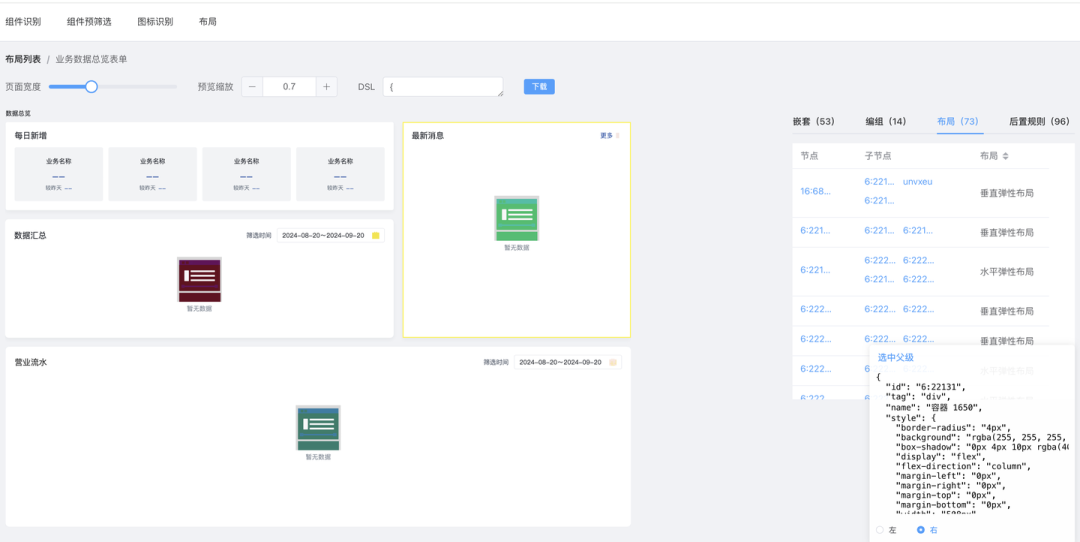
图表识别 BenchMark 举例:
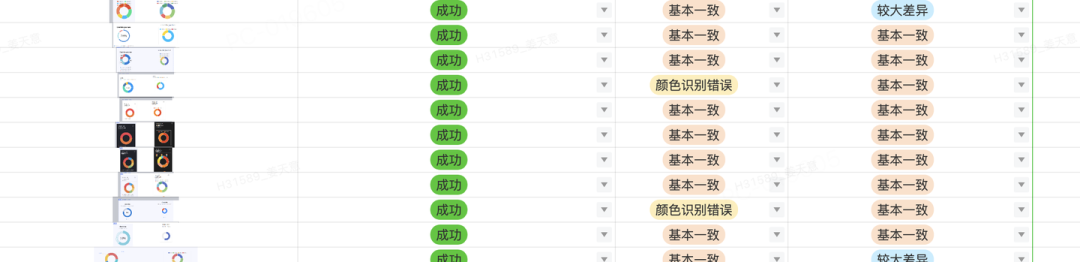
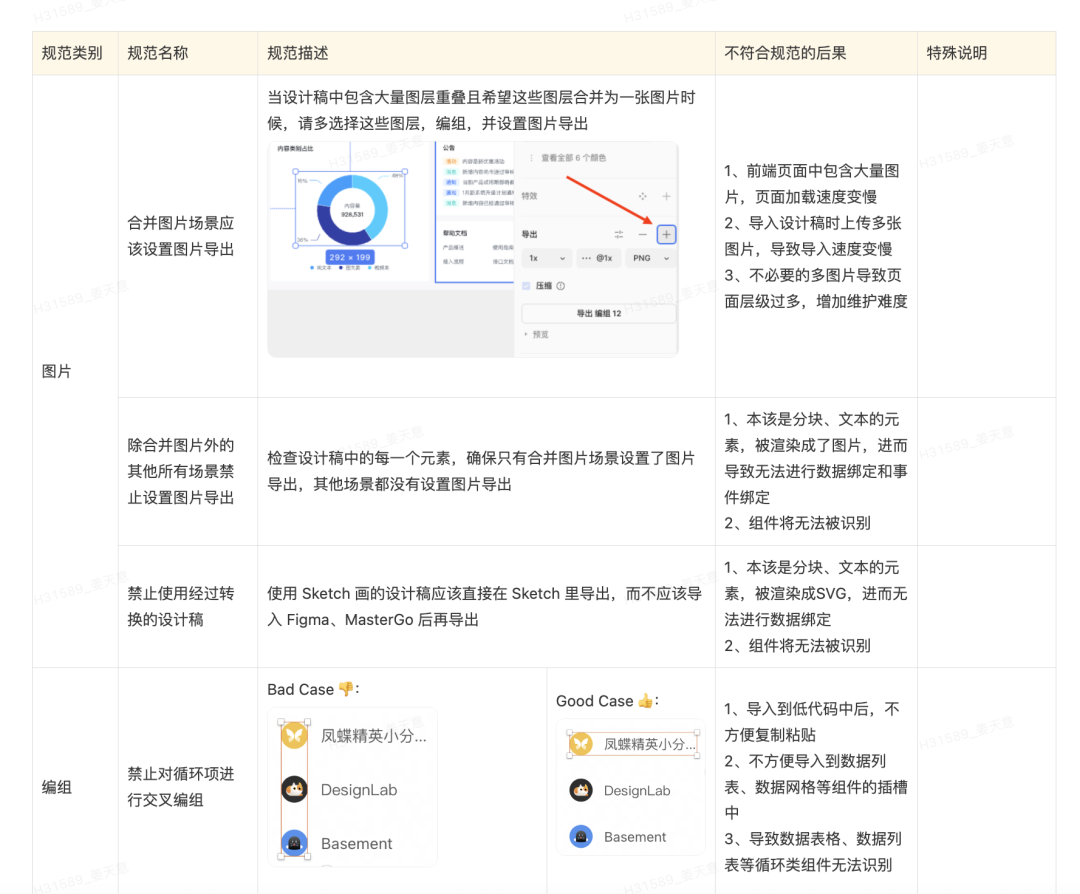
为了更好的同设计团队协作,提升设计稿的规范从而进一步促进 D2C 的识别效果,我们也建立了设计稿标准和检查插件,能够更好的让设计团队同低代码使用者进行协同开发:
CodeWave AI 在今年交付了多个项目,目前设计稿转代码的整体组件准确率达到 80% 以上,代码推荐、代码补全等采纳率均得到明显的改善,基础模型的 human eval 得分也能够提升到 60-70 分,通过工程化、数据 BenchMark、模型以及语言侧的优化,我们把 AI 产品从一个打单的噱头,逐步进化成一个用户可干预,效果可度量,商业可交付的成熟产品。
后续我们也会在其他 IDE 操作层面提供更丰富的能力,如 AI 风格还原,AI 生成实体,AI 生成流程等等。
就在 12 月 13 日 -14 日,AICon 将汇聚 70+ 位 AI 及技术领域的专家,深入探讨大模型与推理、AI Agent、多模态、具身智能等前沿话题。此外,还有丰富的圆桌论坛、以及展区活动,满足你对大模型实践的好奇与想象。现在正值 9 折倒计时,名额有限,快扫码咨询了解详情,别错过这次绝佳的学习与交流机会!











