
向AI转型的程序员都关注公众号 机器学习AI算法工程
FastGPT 介绍
人工智能时代,数据就是企业的财富和金矿。
大数据已经成为一种前所未有的数字资源,但同时也为企业带来筛选和处理数据的负担,不仅影响决策效率,还可能导致重要信息被遗漏。
为了充分利用这些“财富”和“金矿”,就需要把数据与大模型有效结合。FastGPT正是为了这样的需求而来,结合多种大模型,帮助你高效管理和利用这些数据。
FastGPT可以整合与优化大量的非结构化数据,例如文本文档、PDF文件、电子邮件等等。它的运作原理就是阅读并理解你提出的问题,在海量数据中快速找到相关信息,然后以自然语言回复,提供精确的问答服务。
你可以把不同格式的文件导入进去,系统会自动对内容进行结构化处理,为后续的信息检索和分析打下基础。在这之后,拥护可以构建专属的知识库,不断更新和扩展库中的内容,实现动态的知识管理。
在使用过程中,你只需要通过自然语言交互,像使用ChatGPT一样查询知识库中的信息,系统会提供快速又准确的回答。除此之外,平台内置了多种机器学习模型,可以根据你与它的互动自动优化答案质量和查询效率。
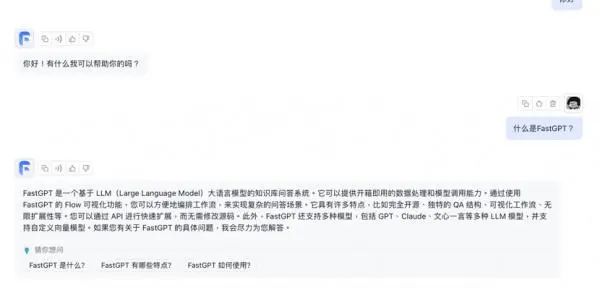
FastGPT还提供了强大的API集成功能,与OpenAI官方接口对齐,支持直接接入现有的GPT应用,也可以轻松集成到其他平台。
对企业来说,FastGPT可以协助处理大量文档、查找和管理大量信息,不仅能够自动化地完成这些文档的数据预处理和向量化,而且通过其强大的搜索和问答功能,企业可以迅速地从海量信息中查找到关键数据,极大地提高信息检索的速度和精准度。
对于个人来说,FastGPT也是一个不错的个人知识管理工具。将个人的文档、笔记和其他类型的信息输入系统,通过AI模型的训练,这些材料就能够转化为一个个人化的问答系统。个人用户可以通过简单的查询,快速获取到存储在系统中的信息,从而有效地提高学习和工作的效率。
FastGPT能够自动化处理大量数据,可以显著提升信息检索和分析的效率,解放人力。基于AI模型,提供针对性的信息解答,能够很好地满足个性化的用户需求。易于集成和扩展的特性,能够提供灵活的API接口,与现有系统快速集成,支持企业按需扩展功能,尤其是在企业信息管理、法律文档分析、学术研究等领域,FastGPT拥有巨大的潜力。
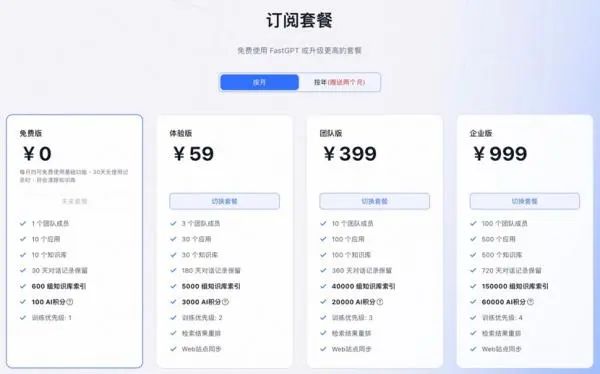
不过部署和维护FastGPT依然需要一定的专业技术知识,对于没有技术基础的小白用户来说,存在学习成本,而且开源版本在功能体验上比每月5000元的Sealos全托管商业版差了一大截。
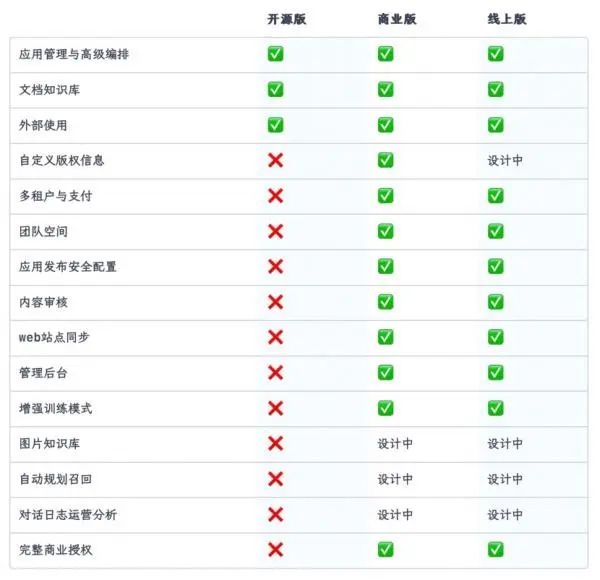

这样看来,线上版的定价似乎更容易接受一些。
除此之外,即便是使用开源版,不论是本地部署还是租赁服务器,尽管长远来看能够节约成本,但初期的设备、软件许可和定制开发等依然需要一定的成本投入。
在生成结果的准确性方面,FastGPT在很大程度上依赖于输入数据的质量,数据的不完整或错误也可能影响结果,所以在使用前依然要自己审视“投喂”数据的质量。
从0到1,手把手教你基于 FastGPT 搭建本地私有化知识库!
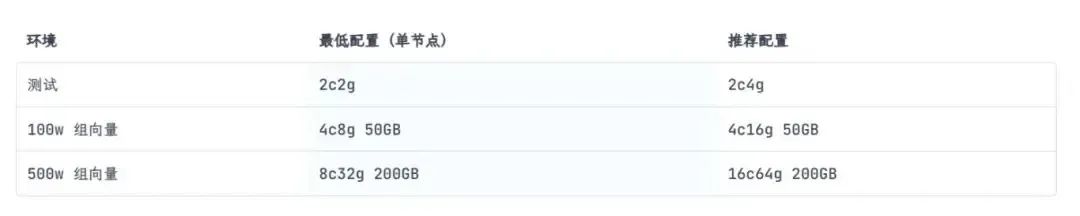
推荐配置
为了满足广大用户的具体需求,FastGPT提供了PgVector、Milvus和zilliz cloud三种版本可供选择。我们可以根据自己的数据规模和性能要求,灵活地在Linux、Windows、Mac等不同的操作系统环境中部署合适的版本。
「PgVector版本」 —— 针对初体验与测试的完美起点
PgVector版本是进行初步体验和测试的理想选择。它简便易用,适合处理中小规模的向量数据,能够迅速掌握并开始工作。
「Milvus版本」 —— 专为千万级向量数据设计的性能强者
当数据处理需求升级至千万级以上,Milvus版本较之其他版本具有卓越的性能优势,是处理大规模向量数据的首选方案。

「zilliz cloud版本」 —— 亿级向量数据的专业云服务解决方案
对于处理亿级及更高量级的海量向量数据,zilliz cloud版本提供了专业的云服务支持,确保您能够获得高效且稳定的数据处理体验。得益于向量库使用了 Cloud,无需占用本地资源,无需太关注配置。
环境准备
FastGpt的部署重度依赖于Docker环境。因此,在本地系统或所管理的服务器上安装Docker环境是确保FastGpt顺畅运行的必要条件。
什么是Docker?这么说吧,FastGpt就像一款需要特定玩具盒子才能玩的电子游戏。这个特定的玩具盒子的名字就叫“Docker”。所以,如果我们想在我们的电脑或服务器上顺利地运行FastGpt,就必须先安装这个玩具盒子,这样FastGpt才能正确地工作。
Windows 系统安装 Docker
在 Windows 系统上,建议将源代码和其他数据绑定到 Linux 容器时,使用 Linux 文件系统而非 Windows 文件系统,以避免兼容性问题。
1.「使用 Docker Desktop」
「推荐使用 WSL 2 后端」:可以通过 Docker 官方文档在 Windows 中安装 Docker Desktop。具体步骤请参考:https://docs.docker.com/desktop/wsl/。
2.「使用命令行版本的 Docker」
「直接在 WSL 2 中安装」:如果不希望使用 Docker Desktop,也可以选择在 WSL 2 中直接安装命令行版本的 Docker。
详细安装步骤请参考:https://nickjanetakis.com/blog/install-docker-in-wsl-2-without-docker-desktop。
macOS 系统安装 Docker
对于 macOS 用户,推荐使用 Orbstack 来安装 Docker。
1.「通过 Orbstack 安装」:
访问 Orbstack 官网 (https://orbstack.dev/)按照指示进行安装。
2.「通过 Homebrew 安装」:
brew install orbstack
在终端运行以上命令
Linux 系统安装 Docker
在 Linux 系统上安装 Docker 的步骤如下:
1.「打开终端,运行以下命令来安装 Docker:」
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
2.「接着安装 docker-compose:」
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
3.「验证安装是否成功」:
docker -v
docker-compose -v
运行以上命令来验证 Docker 和 docker-compose 是否正确安装
开始部署
1.下载 ocker-compose.yml 文件
首先,我们需要访问 FastGPT 的 GitHub 仓库。在仓库的根目录中找到 docker-compose.yml 文件。点击文件,然后点击 “Raw”(原始)按钮,文件内容将显示在浏览器中。接下来,右键点击页面,选择 “保存为”,将其保存到您的计算机上。
2.修改 docker-compose.yml 环境变量
使用文本编辑器(如记事本、Notepad++、VSCode 等)打开下载的 docker-compose.yml 文件,接下来在文件中找到与向量库版本相关的部分。根据您选择的向量库(PgVector、Milvus 或 Zilliz),您需要修改相应的环境变量。
注意:如果选择的是 Zilliz 版本,则需要找到包含 MILVUS_ADDRESS 和 MILVUS_TOKEN 的行,将它们修改为您的 Milvus 服务地址和认证令牌,而另外的两个版本无需修改。
3.启动容器
打开命令行工具(如终端、命令提示符或 PowerShell)。
使用 cd 命令切换到包含 docker-compose.yml 文件的目录。例如:
cd path/to/your/docker-compose.yml/directory
然后运行以下命令来启动容器:
docker-compose up -d
这个命令会在后台启动所有定义在 docker-compose.yml 文件中的服务。
4.打开 OneAPI 添加模型
在浏览器中输入您的服务器 IP 地址后跟 :3001,例如 http://192.168.1.100:3001。
然后使用默认账号 root 和密码 123456 登录 OneAPI。登录后,根据指示添加 AI 模型渠道。
5.访问 FastGPT
在浏览器中输入您的服务器 IP 地址后跟 :3000,例如 http://192.168.1.100:3000。
使用默认用户名 root 和在 docker-compose.yml 文件中设置的 DEFAULT_ROOT_PSW 密码登录 FastGPT。
至此,FastGPT安装部署大功告成!
搭建私有化知识库
当第一次打开网站时,我们会发现界面一片白花花的啥也没有。这个时候,不要慌,来跟我按照以下步骤来搞定你的第一个个人知识库!
在左侧菜单栏选择“知识库”选项。
点击页面右上角的“新建”,开始构建您的第一个知识库。
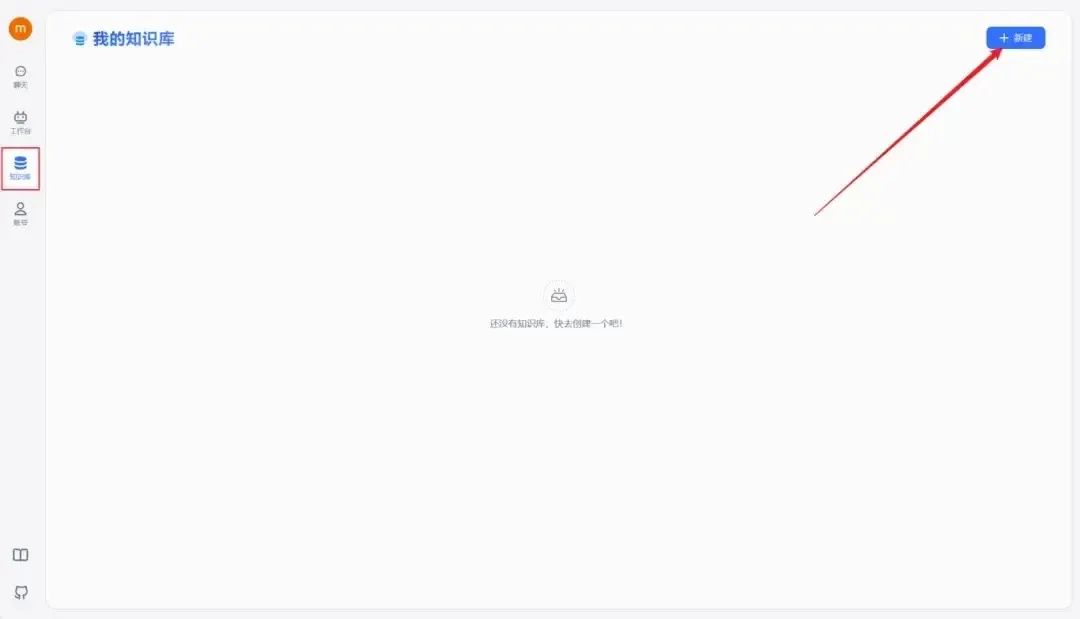
在此过程中,可以根据自身的需求选择合适的知识库类型。紧接着确定我们的知识库名称、索引模型和文件处理模型。
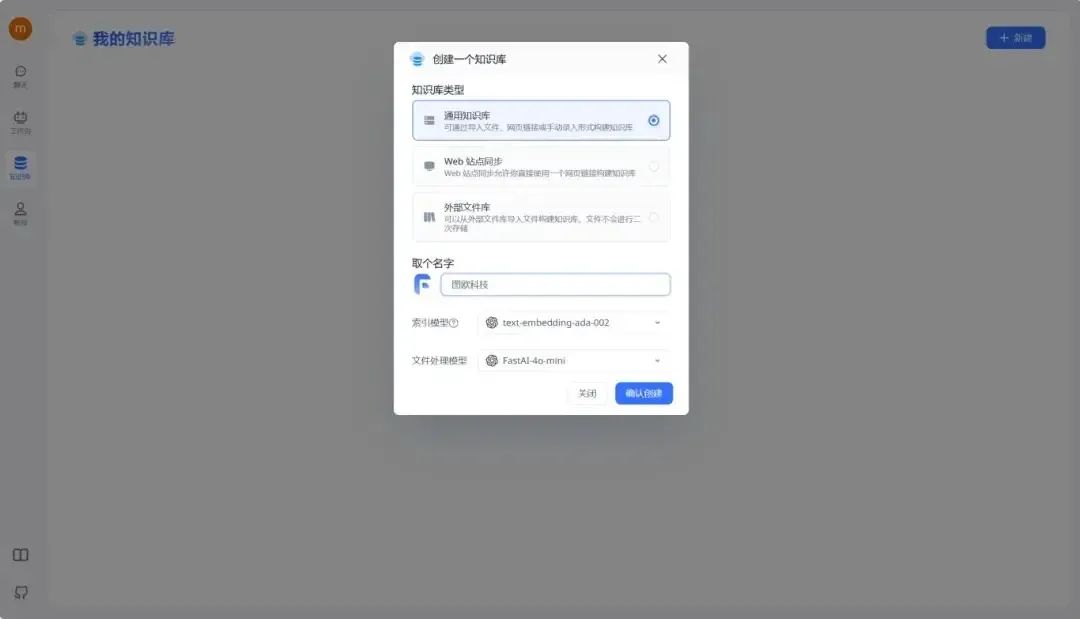
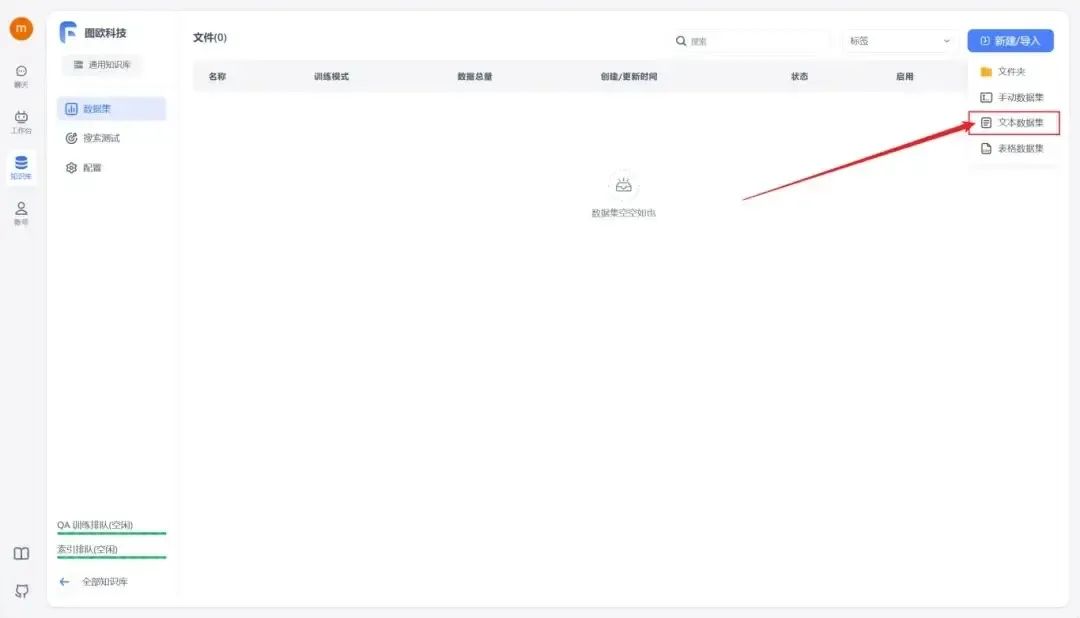
完成创建后,点击右上角的“新建/导入”,根据您的数据集类型选择相应的导入选项。
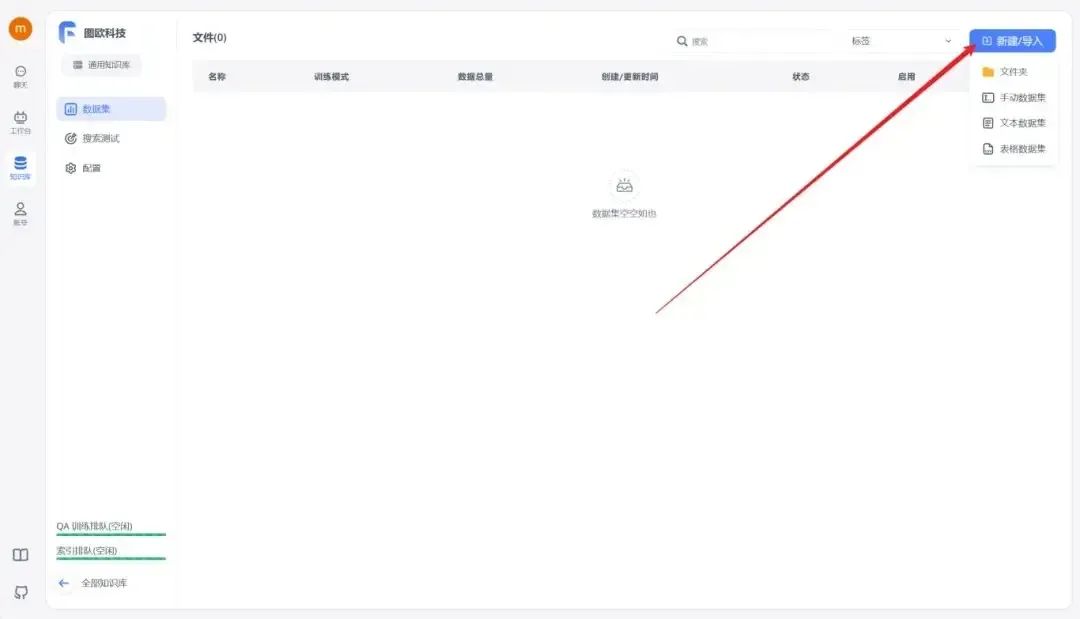
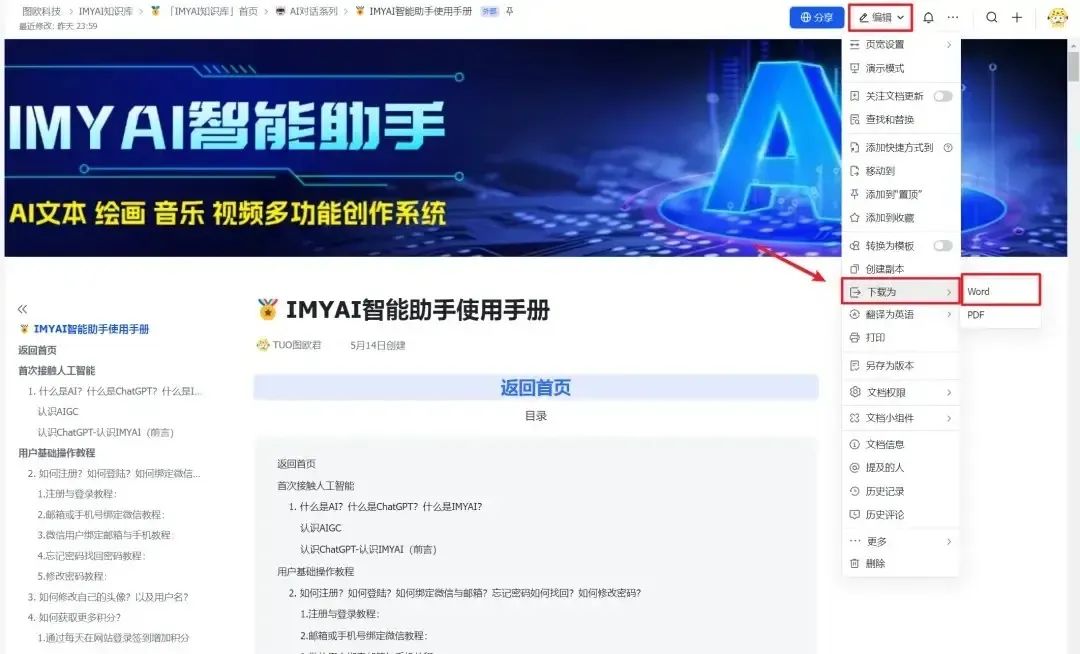
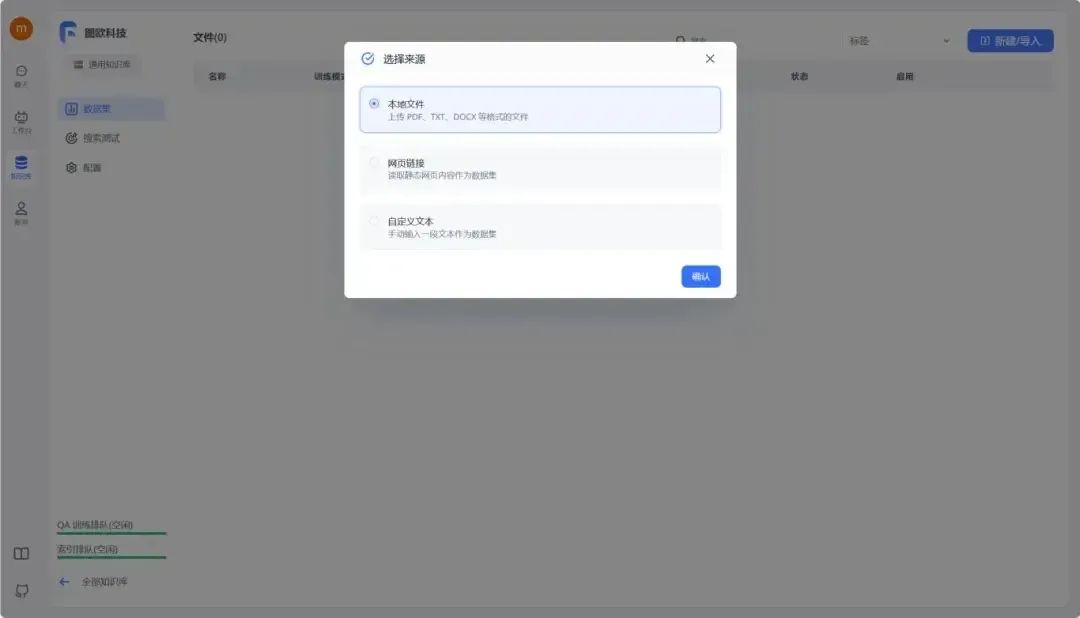
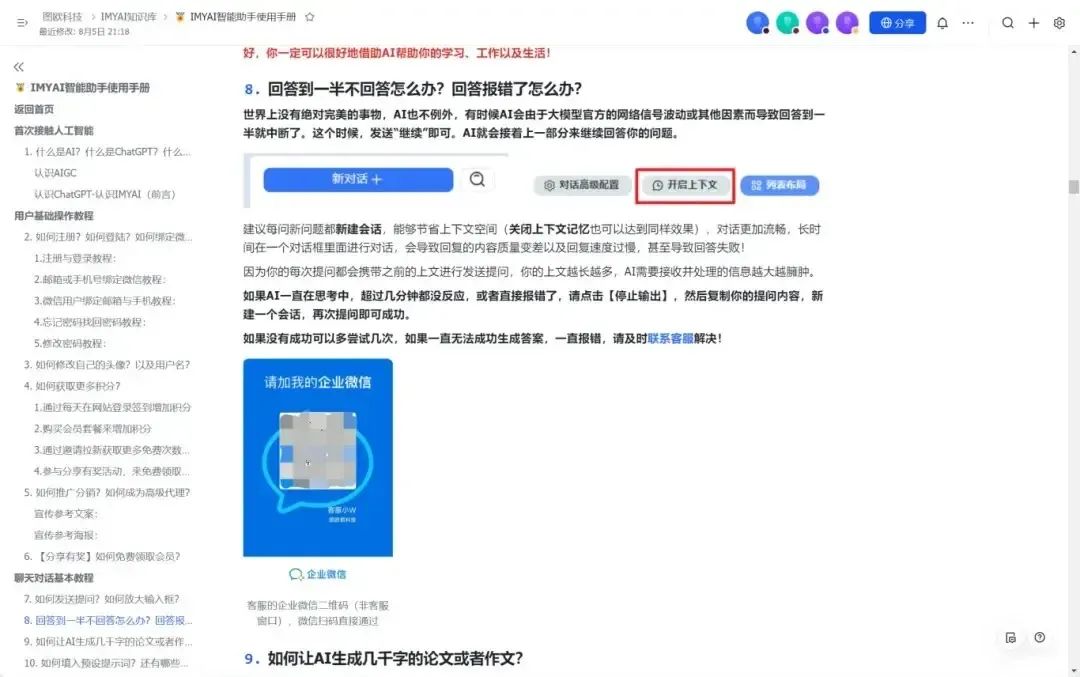
首先需要准备好知识库数据集,可以为DOCX、TXT或者PDF格式,然后选择文本数据集,选择本地文件导入。这里图欧君以咱们的IMYAI知识库为例子,进入飞书云文档《IMYAI智能助手使用手册》之后点击右上角导出为Word文档,文档权限我已经开放为人人都可以创建副本,导出下载,这个大可放心。
IMYAI知识库地址:https://new.imyai.top
等待数据处理并成功上传后,状态栏将显示“已就绪”,这时知识库搭建就完成了。
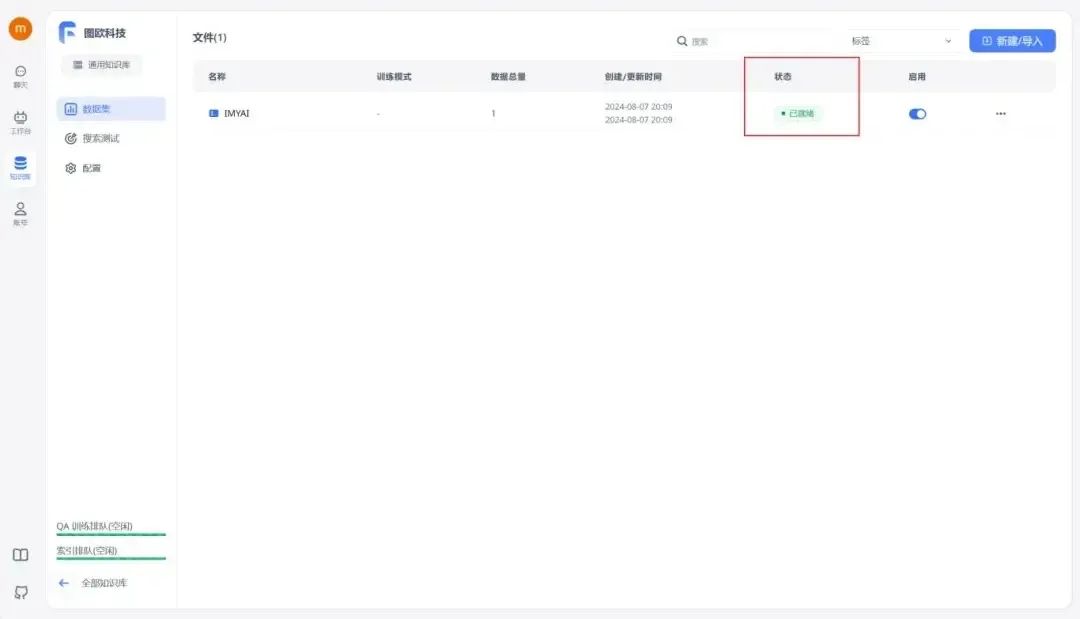
知识库搭建完成之后就可以转到工作台栏进行应用的创建了,一共是提供了四种类型的应用可供我们选择,只需根据自己的需要选择合适的应用即可,图欧君在这里选择了简易应用做个示范。
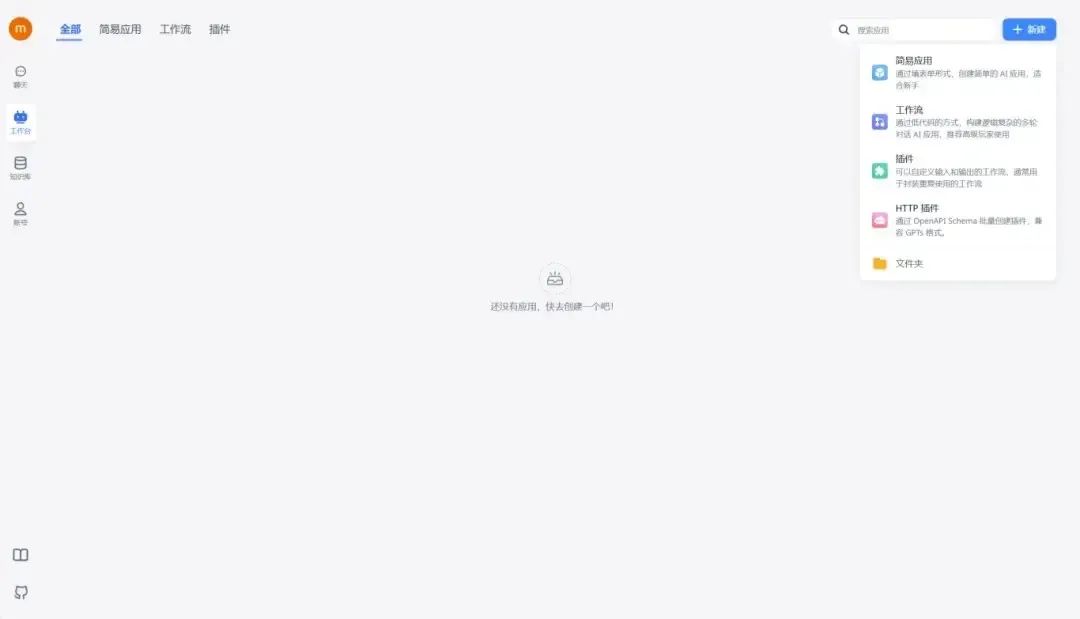
左侧你可以对创建的应用进行一些配置,最后不要忘了把刚刚建立的知识库,关联进来。
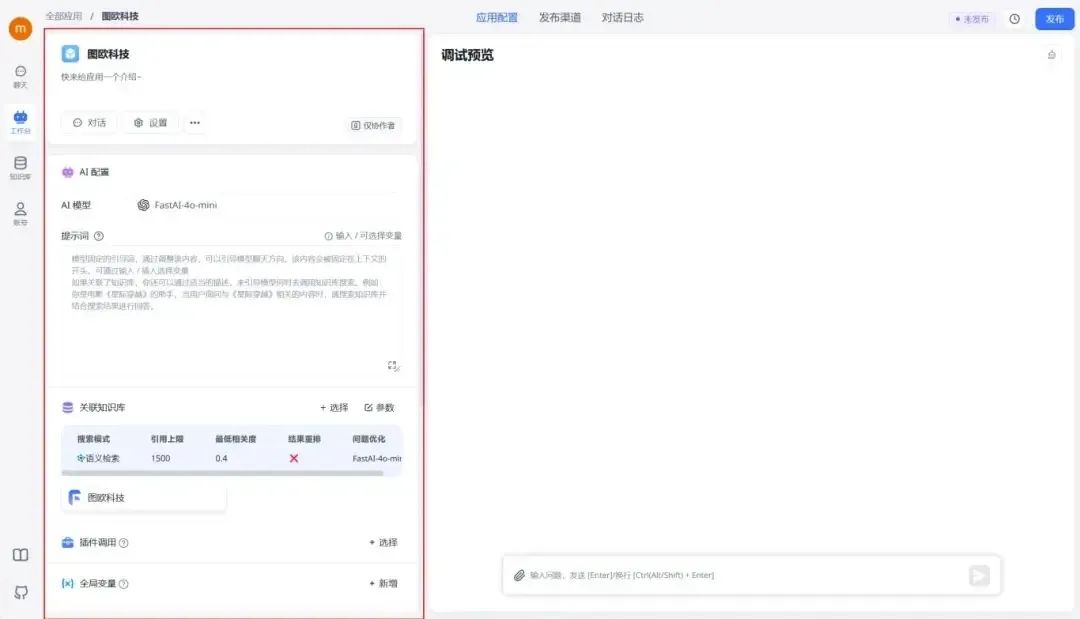
完成配置之后,我们可以在右侧调试一下。比如我问他 “你知道TUO图欧君是谁吗?”,不难发现它会先从知识库中检索到相关信息再回答我。
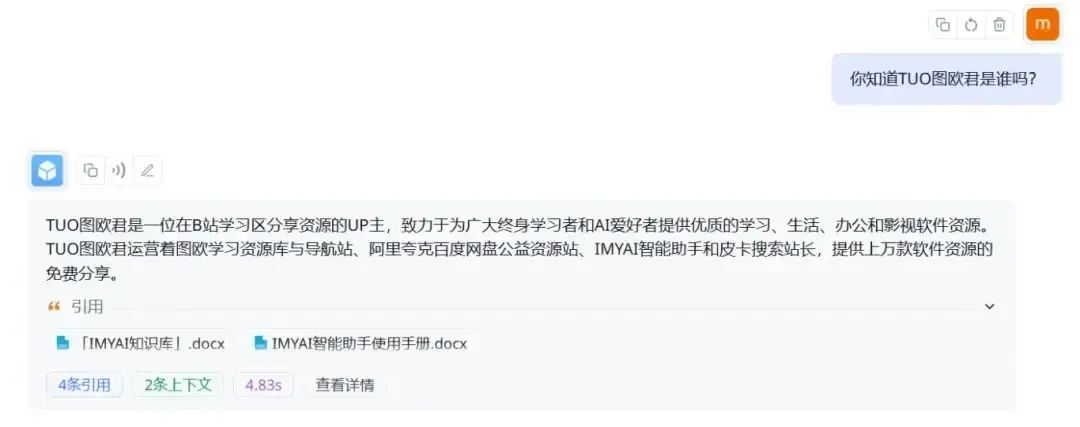
如果在使用IMYAI智能助手的过程中遇到其他问题,也可以随时进行提问,它会根据知识库内容进行梳理总结,减少你寻找答案的时间(不过要记得,先导入知识库内容哦~)
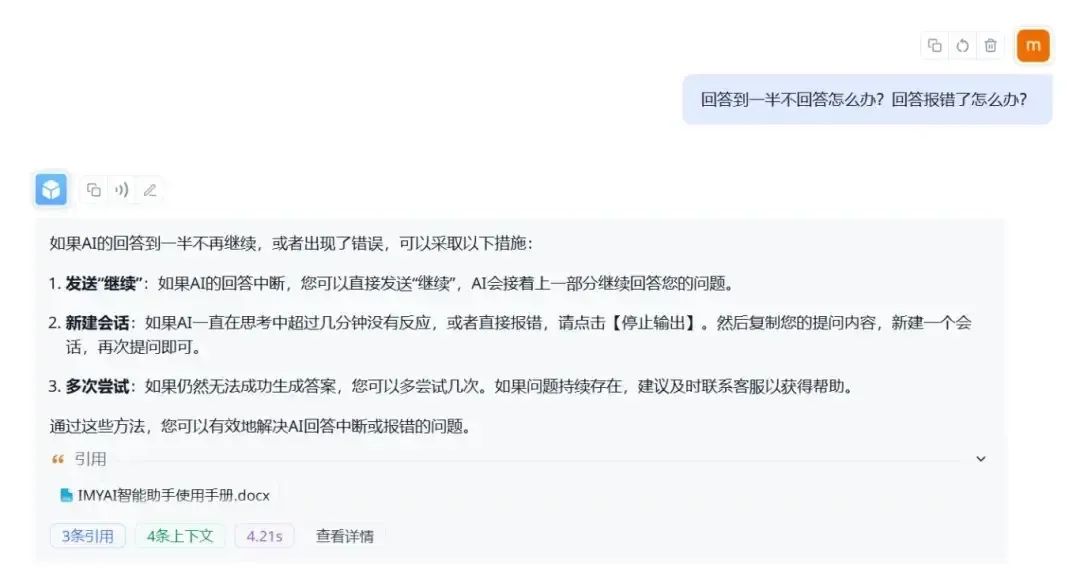
通过对比不难看出,FastGPT这波回答的还是不错的,将原本的内容进行梳理整合之后重新输出,能够更加直观地找到解决问题的答案。
确认调试无误后,点击右上角的“发布”。发布成功后,就可以拥有一个基于本地私有知识库增强的LLM(大型语言模型)啦~
至此,一个私有化的个人知识库就搭建完成了,大家可以随时对知识库中的内容进行提问。作者:TUO图欧君 https://www.bilibili.com/read/cv36899761/?jump_opus=1 出处:bilibili
GitHub API 介绍
GitHub 提供了强大的 API 让我们能够轻松获取 Issues 信息。我们将使用以下接口来获取某个 repo 的 Issues:
这个接口默认返回最近的 30 条 Issues。
可以参考 Github 的 API 文档以获得更多的信息https://docs.github.com/zh/rest/issues/issues?apiVersion=2022-11-28#list-repository-issues。
如今任何项目开发节奏都很快,及时掌握项目动态是很重要滴,GitHub Issues 一般都是开发者和用户反馈问题的主要渠道。
然而,随着 Issue 数量的增加,及时跟进每一个问题会变得越来越困难。
为了解决这个痛点,我们开发了一个自动化 Issue 总结机器人,它的功能很简单:
自动获取项目最新的 GitHub Issues;
智能总结 Issues 内容;
将总结推送到指定的飞书群。
接下来我会提供详细的操作步骤,一步步实现这个机器人。
FastGPT 工作流搭建过程
首先我们要登录 FastGPT 并新建一个工作流:
名字就叫 GitHub Issue 总结机器人吧。
然后开始一步一步添加节点。接下来开始对工作流进行拆解并详细讲解。
1. 构造查询范围
首先我们需要以当前时间节点为基准,获取 24 小时前的具体日期。需要使用到的节点是【代码运行】节点。
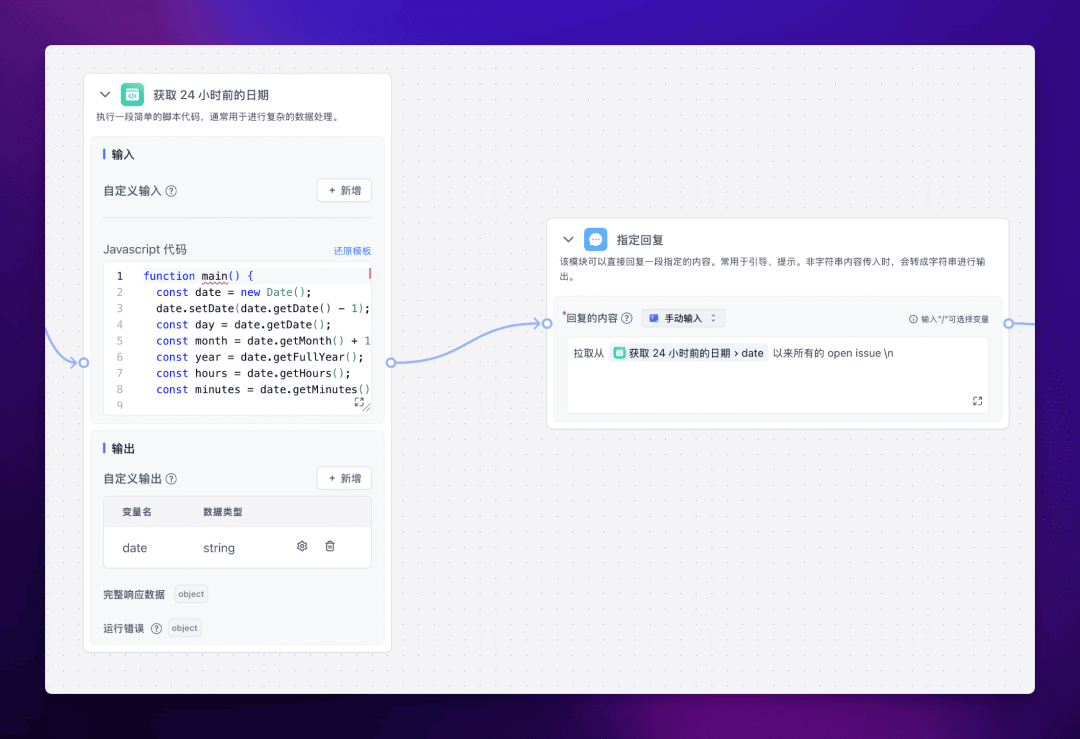
完整代码如下:
function main() { const date = new Date(); date.setDate(date.getDate() - 1); const day = date.getDate(); const month = date.getMonth() + 1; const year = date.getFullYear(); const hours = date.getHours(); const minutes = date.getMinutes();
return { date: `${year}-${month}-${day}T${hours}:${minutes}:000Z`, } }
2. 利用 GitHub API 获取 Issues
这一步我们将使用【HTTP 请求】节点来访问 GitHub API 来获取指定项目过去 24 小时内的 Issues。
这里以 FastGPT 项目为例。
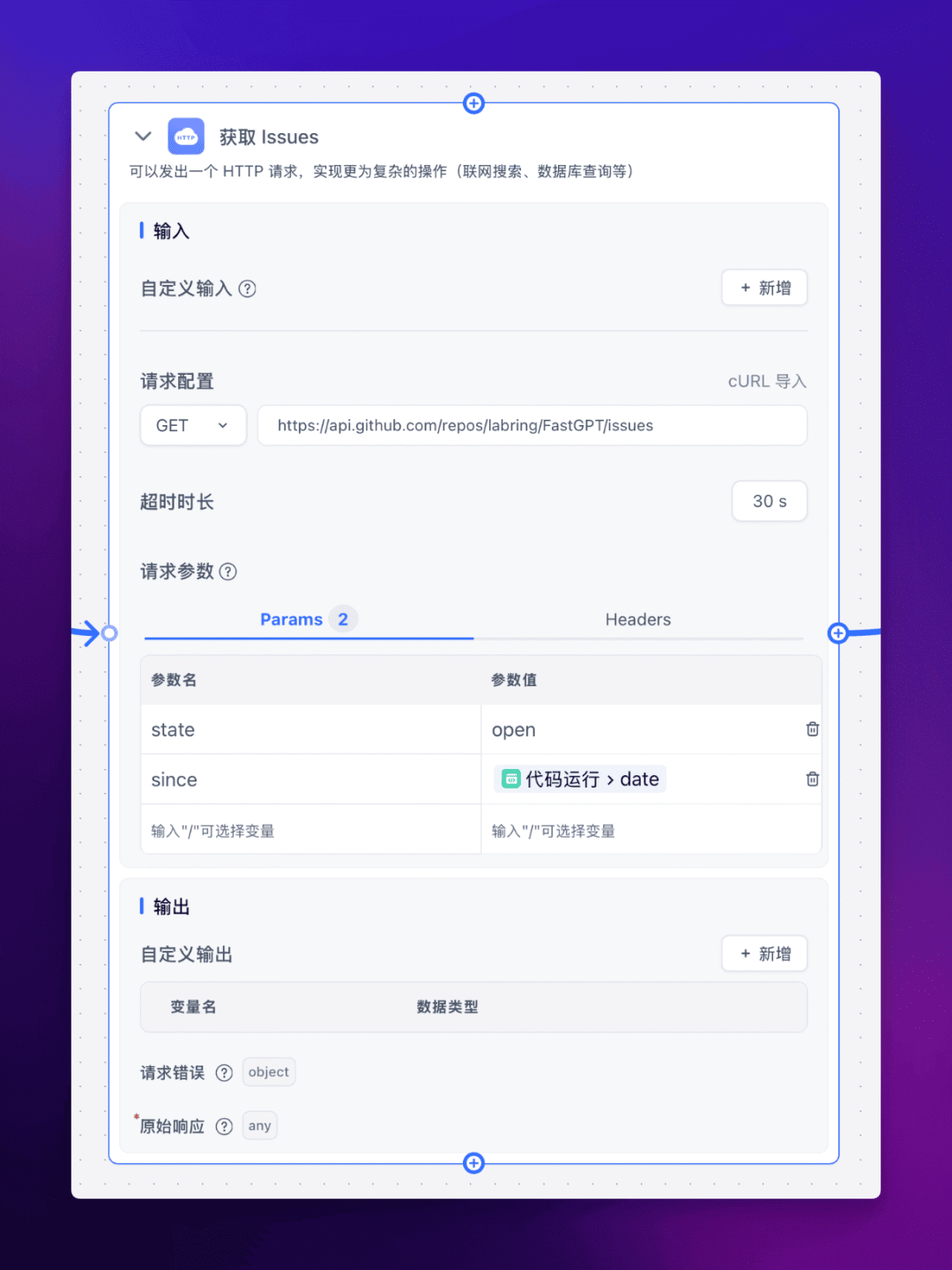
3. 处理 API 响应数据
获取到原始数据后,我们需要对其进行处理,提取出我们需要的信息。同样使用【代码运行】节点。
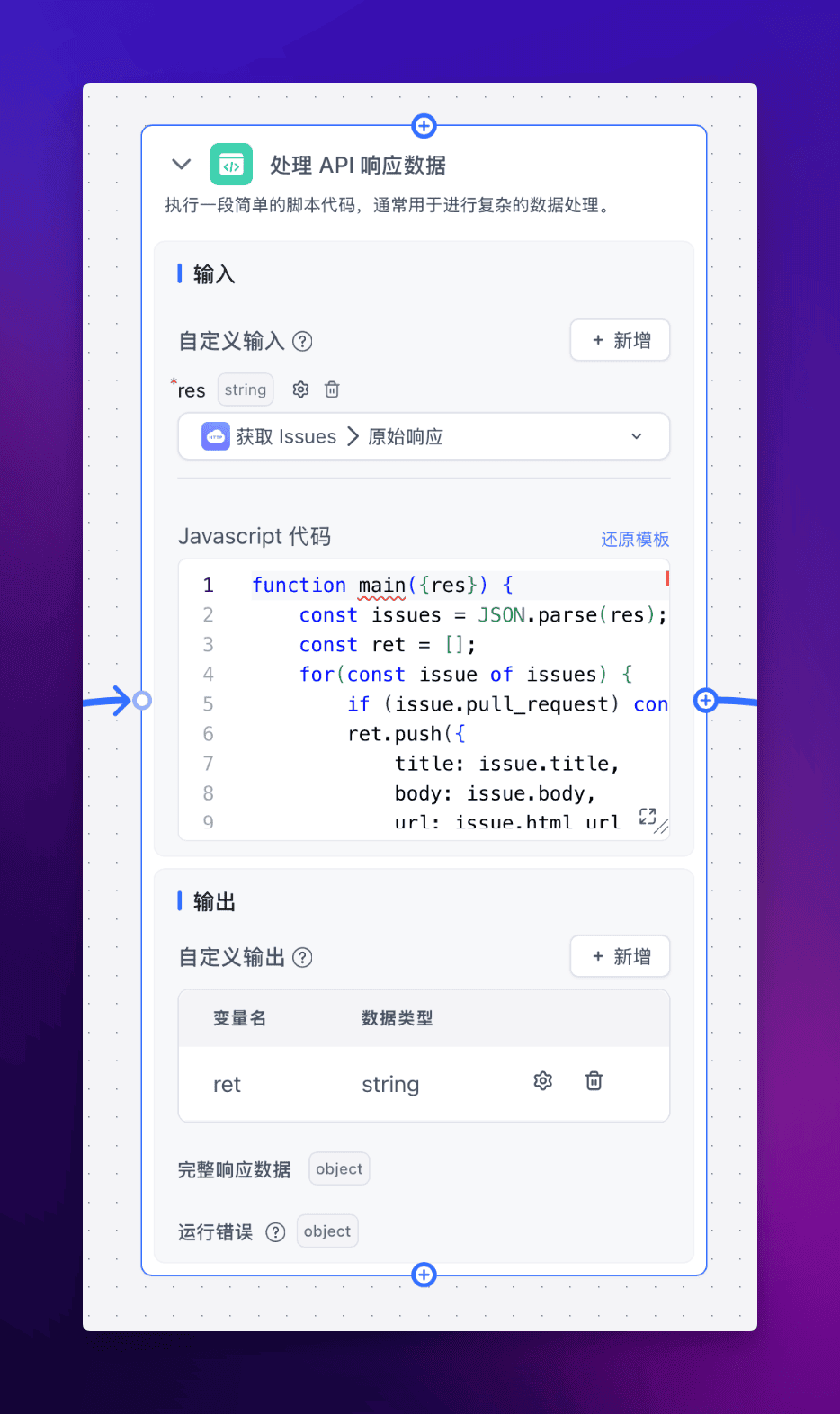
完整代码如下:
function main({res}) { const issues = JSON.parse(res); const ret = []; for(const issue of issues) { if (issue.pull_request) continue; ret.push({ title: issue.title, body: issue.body, url: issue.html_url }) }
return { ret: JSON.stringify(ret) }}
由于 issue 接口会将 pull_request 也视为 issue,所以我们只能在代码里面过滤。
4. 使用大语言模型总结内容
为了生成高质量的摘要,我们使用大语言模型来处理和总结 Issues 内容。
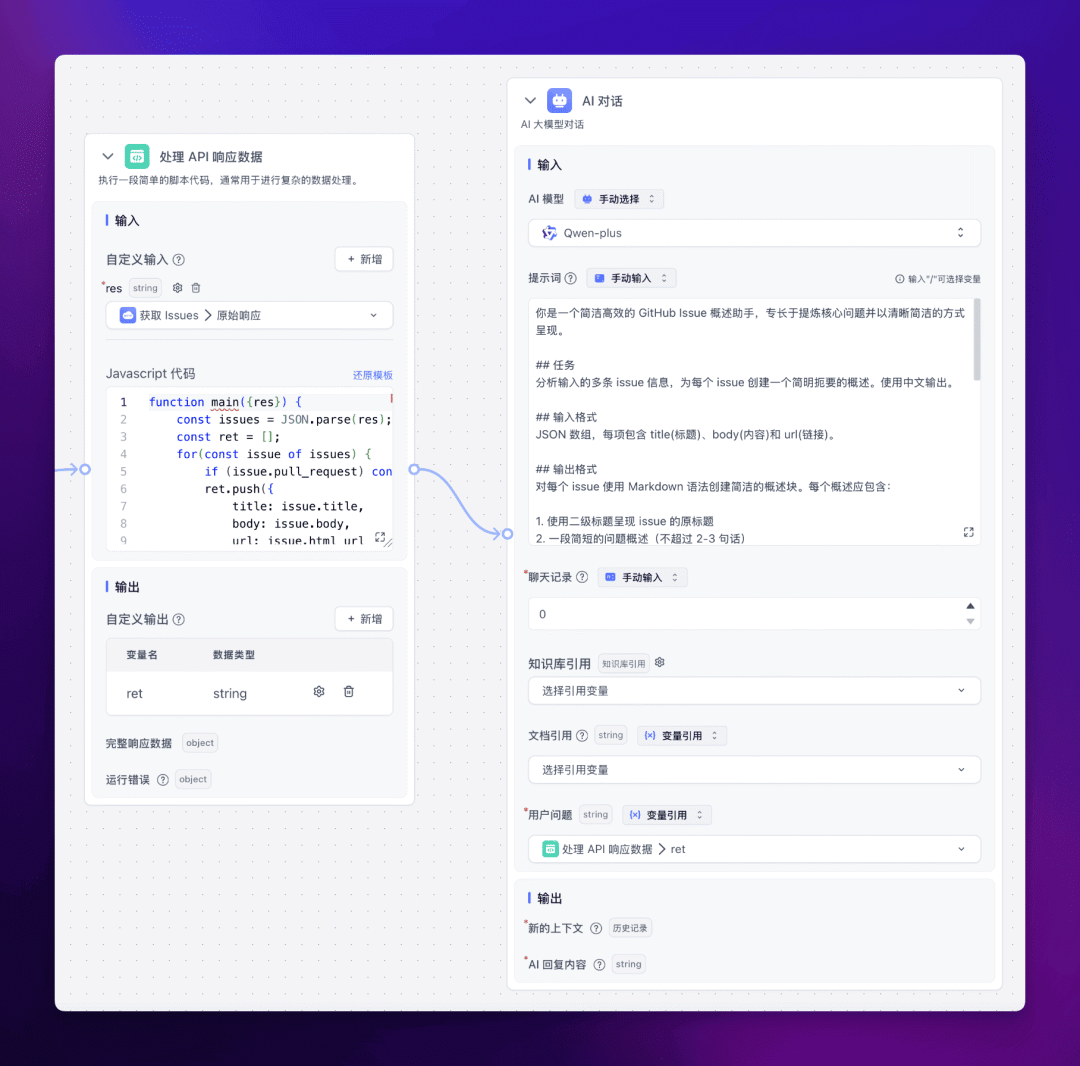
提示词如下:
你是一个简洁高效的 GitHub Issue 概述助手,专长于提炼核心问题并以清晰简洁的方式呈现。
## 任务分析输入的多条 issue 信息,为每个 issue 创建一个简明扼要的概述。使用中文输出。
## 输入格式JSON 数组,每项包含 title(标题)、body(内容)和 url(链接)。
## 输出格式对每个 issue 使用 Markdown 语法创建简洁的概述块。每个概述应包含:
1. 使用加粗呈现 issue 的原标题2. 一段简短的问题概述(不超过 2-3 句话)3. 原 issue 的链接(使用 Markdown 链接语法)
在概述中适当使用 emoji 来增加可读性,但不要过度使用。保持整体风格简洁明了。
示例输出:
---
**🔍 数据可视化组件性能优化**
这个 issue 反映了在处理大量数据时图表加载缓慢的问题。用户在数据点超过一定数量时experiencing明显的性能下降,影响了用户体验。
📎 [查看原 issue](url1)
---
**🐞 移动端界面适配问题**
该 issue 指出在某些特定型号的移动设备上出现了界面布局错乱的情况。这个问题影响了应用在不同尺寸屏幕上的一致性展现。
📎 [查看原 issue](url2)
---
请确保每个 issue 概述都简洁明了,突出核心问题,避免过多细节。保持整体风格统一,让读者能快速理解每个 issue 的要点。
5. 飞书 Webhook 设置
使用飞书机器人的 Webhook URL,我们可以将总结后的内容推送到指定的飞书群。这一步需要用到【飞书机器人 webhook】节点。
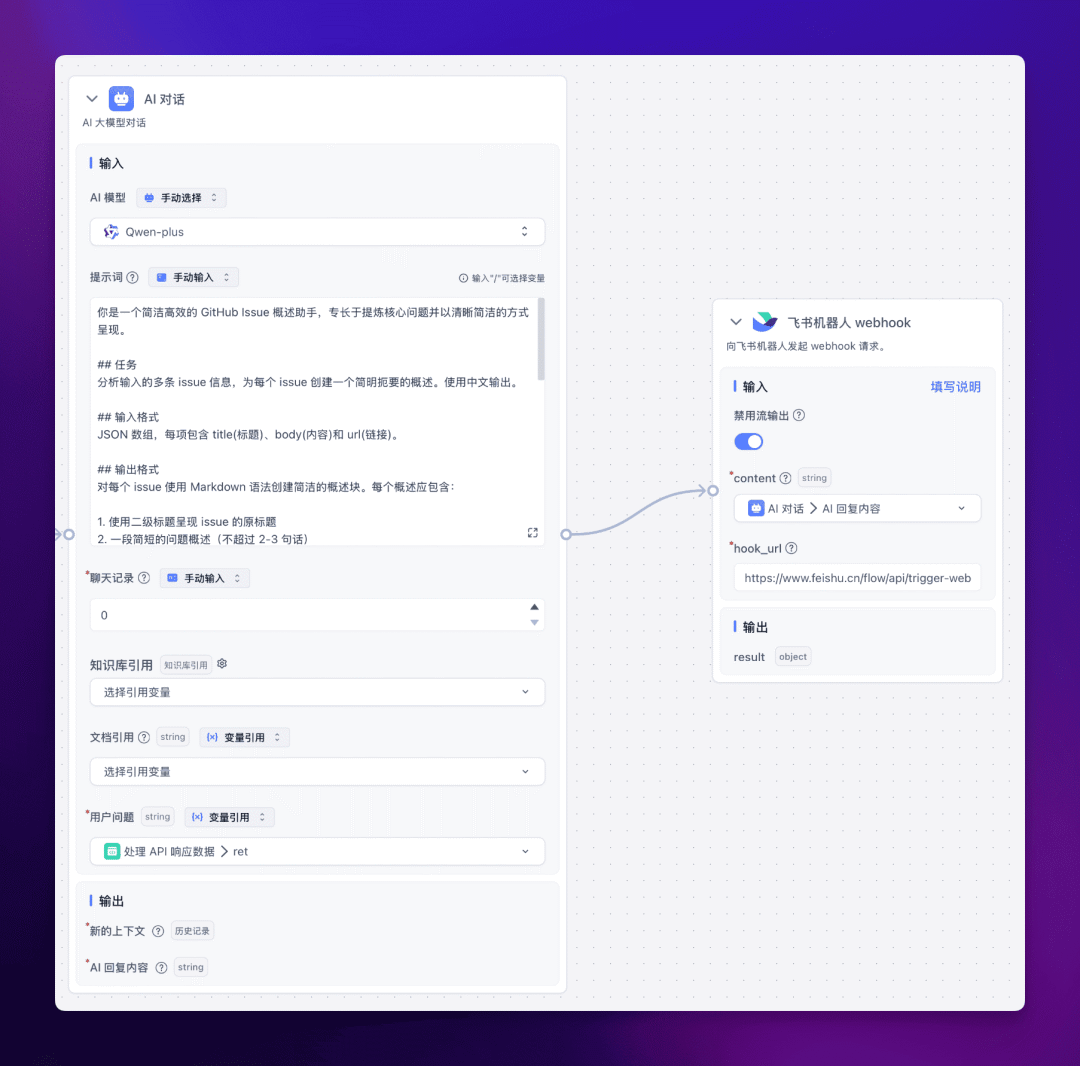
这里的 hook_url 我们将在下一步告诉大家如何获取。
6. 创建并设置飞书机器人
首先需要访问飞书机器人助手页面,然后新建一个机器人应用 --> 创建一个流程。
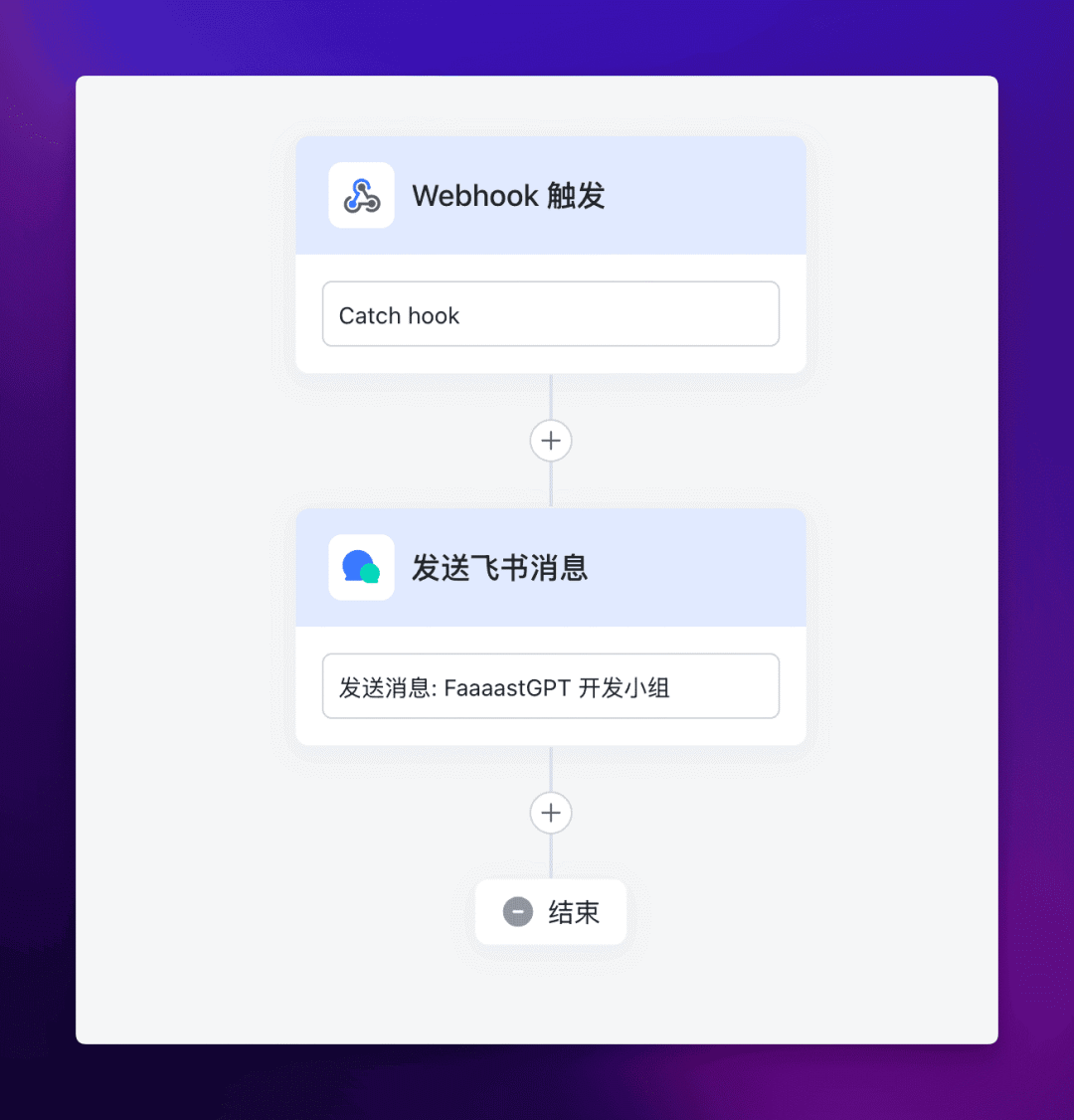
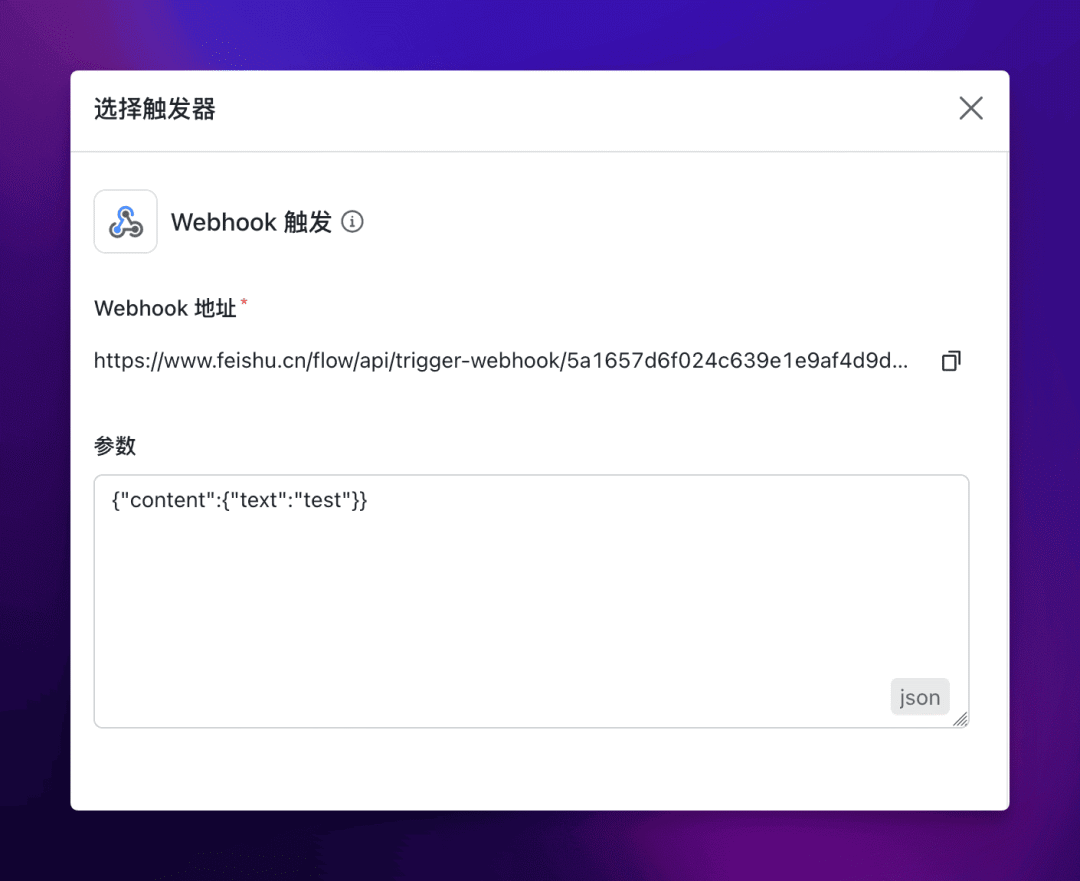
其中 Webhook 触发节点的参数如下:
{"content":{"text":"test"}}
下面一个节点选择【发送飞书消息】,选择发送对象为群消息,并指定群组,自定义一个消息标题。
然后在【消息内容】中点击“加号”,选择 Webhook 触发 --> content.text。
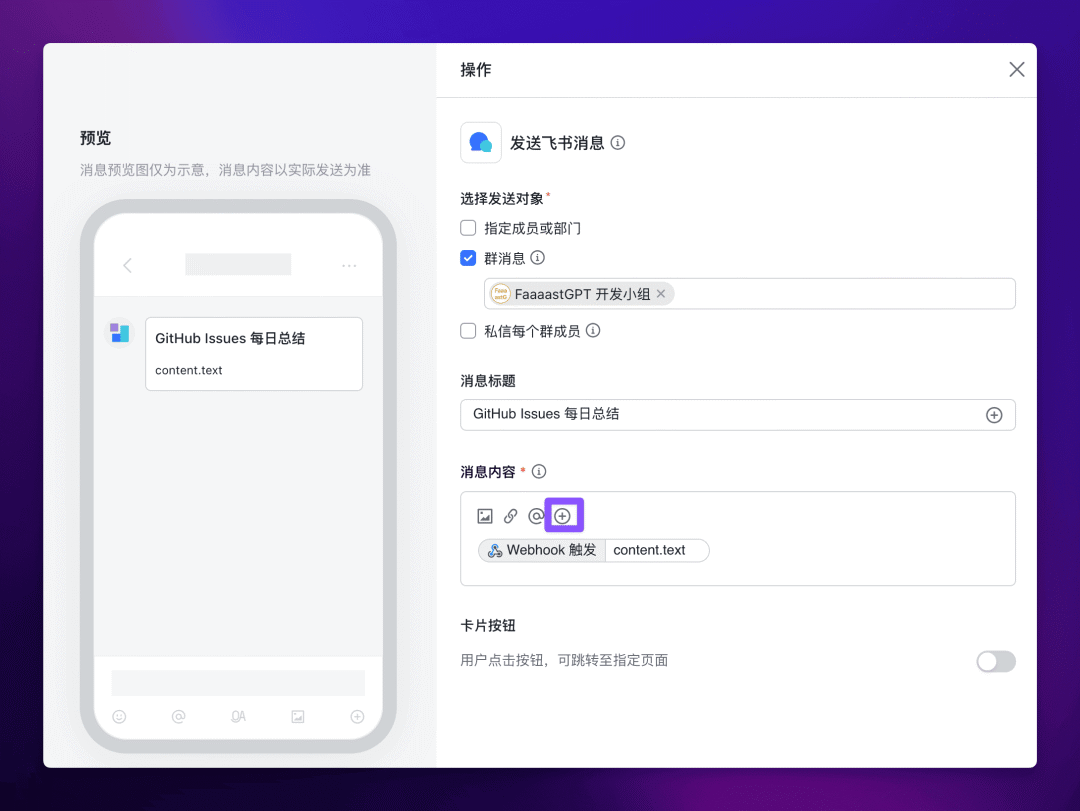
最终保存启用,等待管理员审核通过即可。
审核通过后,将【Webhook 触发】节点的 Webhook 地址填入上述 FastGPT 工作流【飞书机器人 webhook】节点的 hook_url 中。
最终效果
实现这个自动化工具后,你的飞书相关群组每天将会收到类似下图的 Issues 总结:
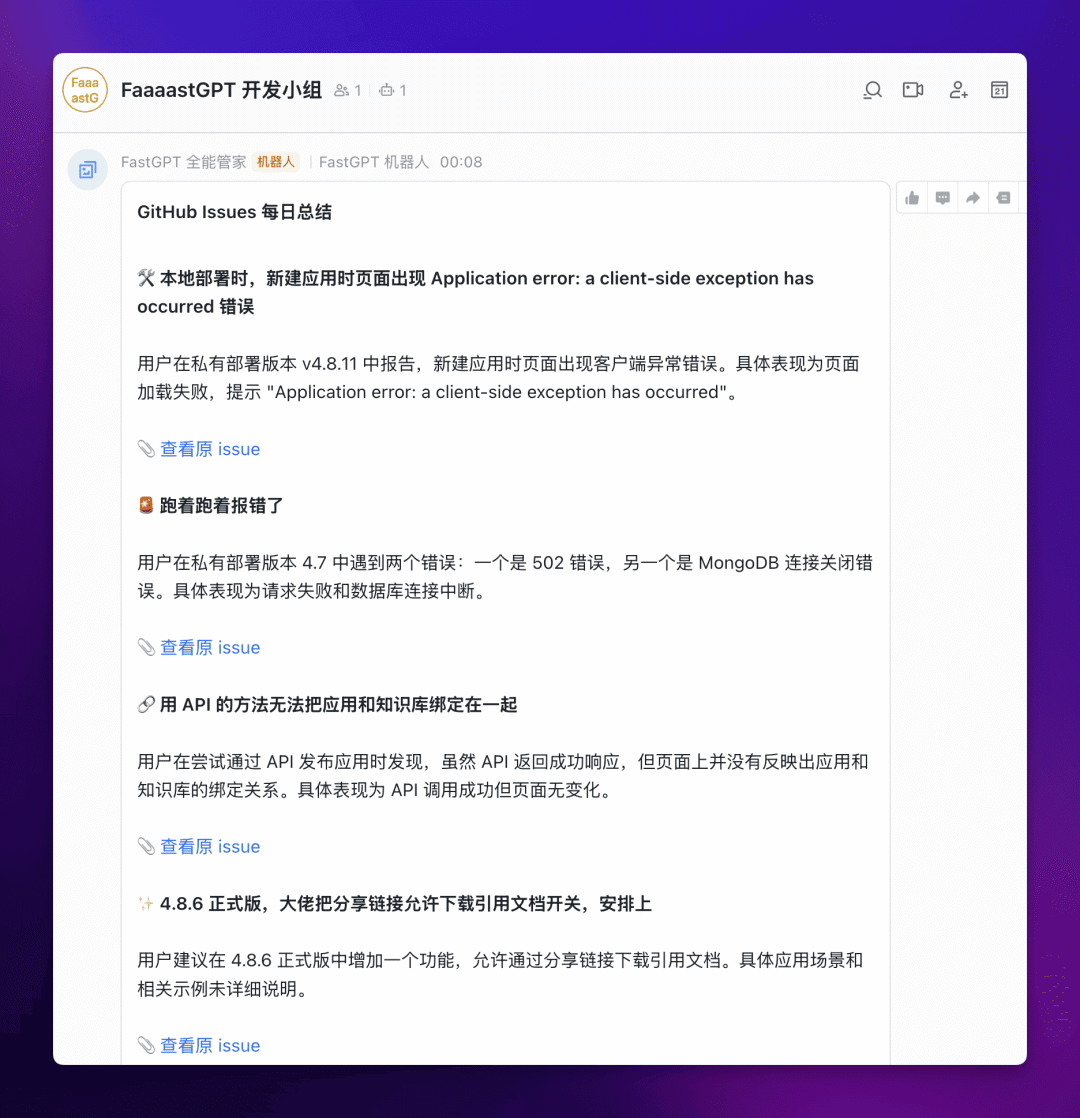
总结
通过本文的教程,大家应该可以发现,一般情况下根本不需要自己写大量代码,只需要拖拉拽一些预设模块,就能让 AI 应用跑起来。即使是总结 GitHub Issues 这样比较复杂的方案,也只需要编写少量的 JS 代码即可完成工作。
如果你连一点点代码都不想写,那也没问题,只需要导入我分享的工作流就可以了。
工作流导入方式:将鼠标指针悬停在新建的工作流左上方标题处,然后点击【导入配置】

完整工作流:https://pan.quark.cn/s/019132869eca
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
实时语义分割ENet算法,提取书本/票据边缘
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
《大语言模型》PDF下载
动手学深度学习-(李沐)PyTorch版本
YOLOv9电动车头盔佩戴检测,详细讲解模型训练
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
《深度学习:基于Keras的Python实践》PDF和代码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx










