历史采集链路比较陈旧,随着公司业务变化,对数据采集要求变高。历史采集能力主要暴露出三个方面的问题。
资源消耗多:采集 3000 多张表增量数据约 1T,消耗资源 1W 多核,表就绪时间 TP90 6 点多甚至更晚,影响数仓表产出和业务看数,尤其是业务高峰期月份;
稳定性弱:表间采集链路、资源不隔离,互相影响明显。例如同集群大表刷数影响小表就绪时间、偶发性更新数据量太大导致任务运行失败、单条数据太大超过 Kafka 限制导致异常等等;
维护成本高:历史包袱重,链路冗长且复杂,全增量采集程序异构。多套采集链路并行,平台管控有限,强依赖研发人员熟悉程度。采集表基数大,出现问题概率比较高,需要持续人工解决。

23 年我们完成了日志采集入湖,整体运行效果很好。为解决上述问题。我们决定将 Mysql 采集由入 Hive 改为 Iceberg。在整个过程中我们还需要平衡以下问题。
方案一:Flink Upsert 方式直接写 Iceberg 表
方案三:写入改为增量,利用 Spark 做 Merge 写入历史 ODS Iceberg 表存储的是 Change Log 数据。为了保证采集流程做到表级别隔离,避免互相影响导致核心表就绪时间晚,采用每组(适配单集群分库分表场景) MySQL 表对应一个 Iceberg 表。将 Iceberg 表抽象为灵活且一致的 Schema,既可以保障字段变化的扩展性,也降低了字段类型映射等平台的开发成本。Iceberg 查询场景为全列 Scan,也不用顾虑复杂类型查询无法下推的影响。
Flink CDC Source 读 Mysql Binlog 数据,同时加入了一些 ETL 处理。例如加解密、数据内容转义等等
-
Router 将数据采集规则(按表拆分或分库表合并输出)进行分发。done tag 基于特定表心跳数据做小时级别就绪状态上报,用于批任务触发判断。
Sink Iceberg Table 负责将 Change Log 写入到具体 Iceberg 表中。作业帮基于腾讯 EMR 和 cos 对象存储实现的存算分离,这个环节因为 Sink 数据到 Cos 上的 Iceberg 表中,处理速度弱于 Flink CDC 处理能力,所以做了并行参数设置,用于处理不同表更新频率差异导致的延迟。
全量初始化采集,为兼容增量逻辑,重写了 Flink Sink Hive 的逻辑,将当前 MySQL 表全量快照数据,同步至 ODS 表首分区。设计数据同步批次大小和并行度,避免对业务线上访问造成影响。当 MySQL 中无数据时模拟产生空分区。
在实际运行过程中还遇到了一些问题。具体情况如下
之前设计主要以 Jar 形式开发全量和增量 Binlog Merge 任务,较 SQL 而言存在明显弊端。例如血缘解析需要额外开发,无法天然享受到计算引擎升级和优化带来的收益,开发效率低。参考了一些湖的设计思路,同时统计了增量 Binlog 数据特点,最新数据更新概率更高。在 SQL 逻辑表达时采用了全量 anti join 减去增量变化的数据,再 union row number 后的增量数据形成最新分区 ODS,较全量 union -> sort -> row number 方式计算效率提升大概 50%。
不同表在数据量、更新频率、单行大小等方面存在的差异较多,为简化任务资源设置,减少人力运维成本,借助 Spark AQE 能力沉淀了一套适合我们场景的集群环境,在保障任务稳定的同时消耗资源也非常少。在实际运行中还遇到一些其他问题。例如
Driver 内存超限,分析内存发现通过 Kyuubi 提交 Spark SQL 任务较 spark submit 命令方式提交内存使用多大概 1 倍,主要为 Kyuubi 依赖的一些类或者线程占用,适当调大内存后解决。相关 issuse 地址 https://github.com/apache/kyuubi/issues/6481
Executor 内存超限,主要原因有两类。1. 执行窗口函数时缓存在内存中数据条数默认为 4096,单行记录过大时导致 OOM,适当调低阈值后解决。2. Spark 读取 parquet 时,默认开启向量化读,BatchSize 4096 行。因为无法准确判断单行大小,当检测到 MySQL 表中存在大文本类型声明时,默认关闭 Parquet 向量化读;
我们一个 Kyuubi 集群对应多个 Yarn 队列,当某些队列没有资源但仍然提交任务后,会触发 Kyuubi 并发上限 kyuubi.engine.startupProcessSemaphore,导致其他有资源队列任务无法提交成功,造成资源浪费;我们在 Kyuubi engine 启动后释放 startupProcessSemaphore 就可以解除限制。相关 PR 地址 https://github.com/apache/kyuubi/pull/6463
为了保障数据准确性,兼顾迁移速度。在对数上采用 sum hash 全部列的方式,然后在通过新老表主键 join,判断最终 sum 值是否一致。既可以计算出数据 diff 率,也方便抽样数据发现问题。在不同特点的数据上采用不同的对数方案,主要以增量对数为主,全量对数补充,当两者都无法满足需要时采用和业务 MySQL 对数的方式;
增量对数:旧链路数据作为新链路初始分区,新旧链路双跑,对比某天全量数据,本质对比增量变化数据;
全量对数:重新拉取 MySQL 全量快照作为新链路初始分区,新旧链路双跑,对比某天结果数据;
MySQL 对数:(旧 Hive、新 Hive、MySQL 三端抽验)
旧链路 Hive 表字段比 MySQL 多;(MySQL字段被删除)
新旧链路字段转义逻辑不对等;(旧链路全量、增量采集转义逻辑不一致,无法做到对等)
新旧链路 Hive 表字段类型、数值变化;(MySQL 字段类型变化、新老采集字段类型映射差异、数值精度差异、默认值差异等等)
资源收益
迁移资源明细统计资源节省占比 81%,按 6 点就绪节省 7000 核 +;
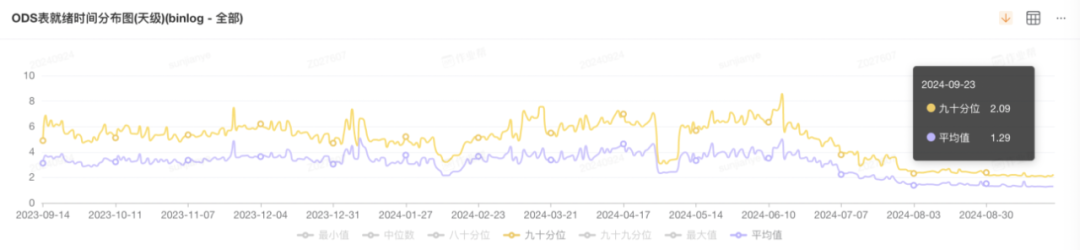
图 1:最新表就绪时间 TP90 2:10 分左右;均值 1:15 分左右;
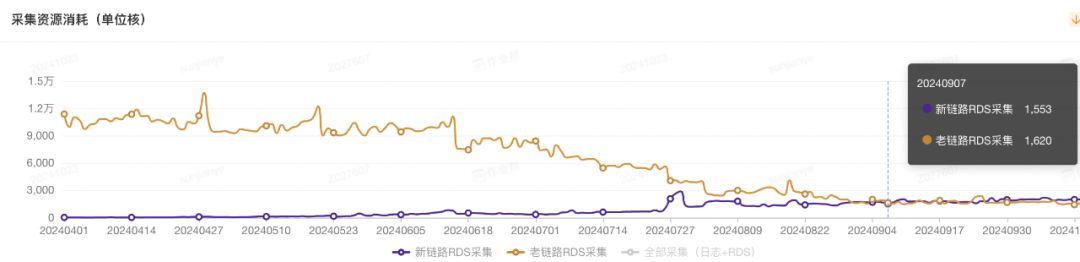
图 2:MySQL 按照 6 点就绪的 cpu 核数消耗明显降低;
架构收益
表级采集独立,可根据业务需求实现分级保障;例如就绪时间、采集数据量大小资源自适配等;
解除对 kafka、任务配置定时同步等中心式依赖,极大程度降低全局故障影响;
平台化管理完整,逻辑更严谨,平台信息、任务配置、采集表等信息完全对齐,解决历史定制化问题;
血缘链路完整,方便治理工作推进;