在机器学习中,梯度下降算法(Gradient Descent)是一个重要的概念。它是一种优化算法,用于最小化目标函数,通常是损失函数。
简而言之,梯度下降帮助我们找到一个模型最优的参数,使得模型的预测更加准确。
本文将深入探讨梯度下降算法的原理、公式以及如何在Python中实现这一算法。
1. 梯度下降算法的理论基础
1.1 什么是梯度?
在数学中,梯度是一个向量,表示函数在某一点的变化率和方向。在多维空间中,梯度指向函数上升最快的方向。
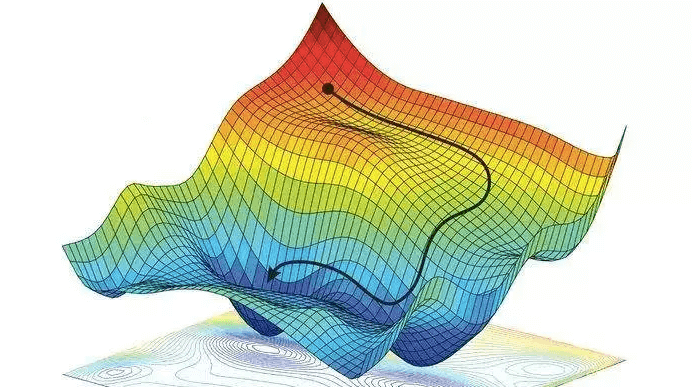
我们可以通过梯度来找到函数的最小值或最大值。对于损失函数,我们关注的是最小值。
1.2 梯度下降的基本思想
梯度下降的核心思想是通过不断调整参数,沿着损失函数的梯度方向移动,从而逐步逼近最小值。具体步骤如下:
1. 初始化参数:随机选择参数的初始值。
2. 计算梯度:计算损失函数对每个参数的梯度。
3. 更新参数:根据梯度信息调整参数,更新规则为:
其中:
是要优化的参数。
是学习率(step size),决定每次更新的幅度。
是损失函数关于参数的梯度。
4. 重复步骤:重复计算梯度和更新参数,直到收敛(即损失函数的变化非常小)。
2. 梯度下降的数学推导
假设我们有一个简单的线性回归问题,目标是最小化均方误差(MSE)损失函数:
其中是模型的预测值。为了使用梯度下降,我们需要计算损失函数关于参数的梯度:
通过求导,我们可以得到梯度表达式,并利用它来更新参数。
3. Python 实现梯度下降算法
接下来,我们将通过一个简单的线性回归示例来实现梯度下降算法。以下是实现代码:
3.1 导入库
import numpy as np
import matplotlib.pyplot as plt
3.2 生成数据
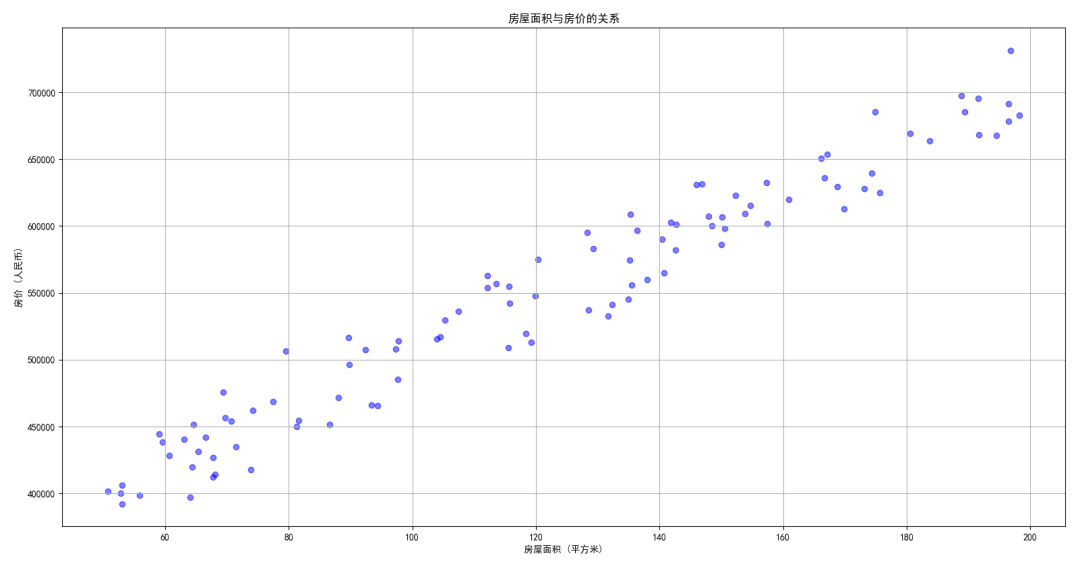
我们将生成一些随机数据来模拟房屋面积与房价之间的线性关系。
np.random.seed(0)
X = 50 + 150 * np.random.rand(100)
Y = 300000 + 2000 * X + np.random.randn(100) * 20000
plt.scatter(X, Y, color='blue', alpha=0.5)plt.title('房屋面积与房价的关系')plt.xlabel('房屋面积 (平方米)')plt.ylabel('房价 (人民币)')plt.grid()plt.show()
3.3 梯度下降实现
我们将实现梯度下降算法的核心部分。
X = (X - np.mean(X)) / np.std(X)Y = (Y - np.mean(Y)) / np.std(Y)
alpha = 0.01 num_iterations = 1000 m = len(Y)
theta_0 = 0 theta_1 = 0
losses = []
for i in range(num_iterations): Y_pred = theta_0 + theta_1 * X loss = (1/m) * np.sum((Y - Y_pred) ** 2) losses.append(loss) gradient_0 = -(2/m) * np.sum(Y - Y_pred) gradient_1 = -(2/m) * np.sum((Y - Y_pred) * X) theta_0 -= alpha * gradient_0 theta_1 -= alpha * gradient_1
print(f'截距 (θ0): {theta_0:.4f}, 斜率 (θ1): {theta_1:.4f}')
截距 (θ0): 0.0000, 斜率 (θ1): 0.9743
3.4 绘制损失曲线
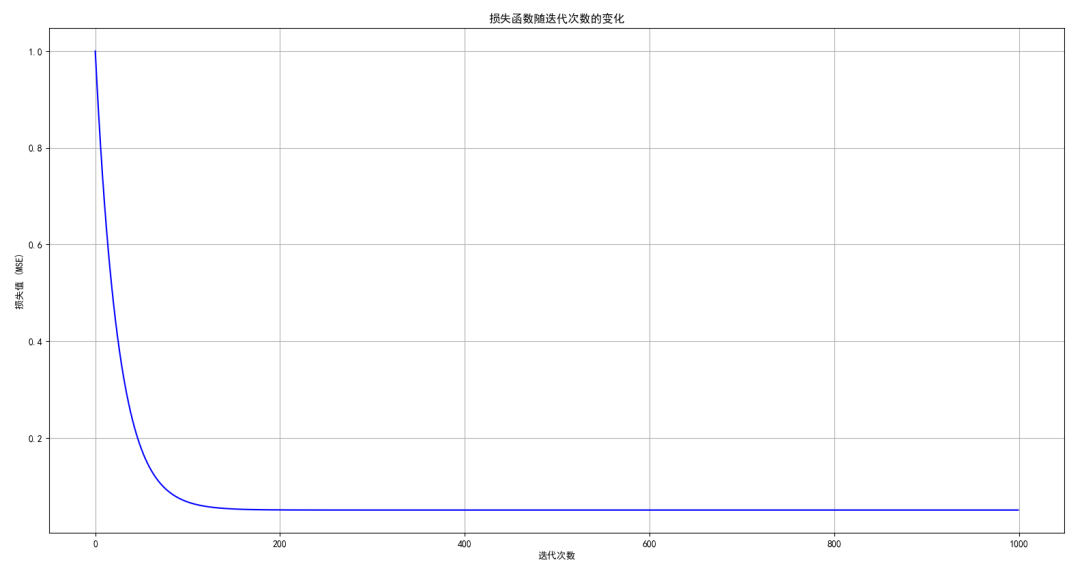
通过绘制损失函数随迭代次数变化的曲线,我们可以观察梯度下降的收敛过程。
plt.figure()plt.plot(range(num_iterations), losses, color='blue')plt.title('损失函数随迭代次数的变化')plt.xlabel('迭代次数')plt.ylabel('损失值 (MSE)')plt.grid()plt.show()
3.5 可视化回归线
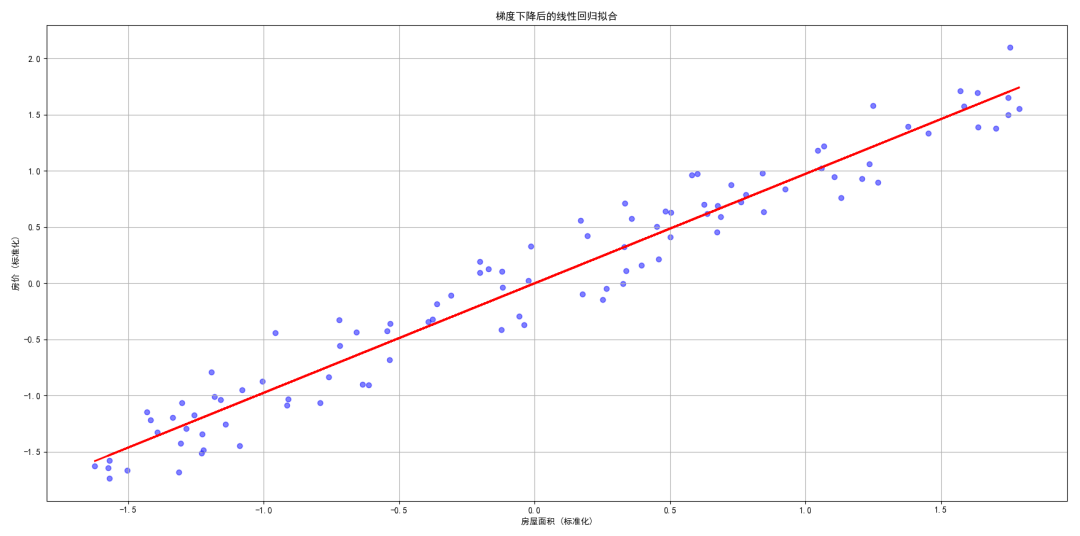
最后,我们可以将训练好的回归线可视化,以观察模型的效果。
plt.figure()plt.scatter(X, Y, color='blue', alpha=0.5)plt.plot(X, theta_0 + theta_1 * X, color='red', linewidth=2)plt.title('梯度下降后的线性回归拟合')plt.xlabel('房屋面积 (标准化)')plt.ylabel('房价 (标准化)')plt.grid()
plt.tight_layout() plt.show()
4. 梯度下降的应用场景
梯度下降算法在许多机器学习算法中得到了广泛应用,包括:
线性回归:如上文示例所示。
逻辑回归:用于分类问题,通过优化对数损失函数。
神经网络:用于深度学习,反向传播算法依赖于梯度下降来更新权重。
我们后面会一一讲到!
总结
梯度下降是一种强大的优化算法,它通过迭代更新参数来最小化损失函数。在实际应用中,选择合适的学习率和迭代次数至关重要,因为学习率过大可能导致发散,而学习率过小则可能导致收敛速度缓慢。
希望本文能够帮助你理解梯度下降算法的基本概念及其在Python中的实现。如果你有任何问题,欢迎在评论区留言!
请备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“加群。
(也可以加入机器学习交流qq群772479961)







