
神经网络是什么?
神经网络的名字来源于其结构——由多个相互连接的计算单元(称为神经元)组成的网络。
这种结构是受到人类大脑和生物神经网络的启发,每个神经元之间的连接是一个数字,这个数字是根据输入到该神经元的多个输入计算出来的。
每个输入都有一个对应的权重,训练神经网络的目标就是找到最优的权重,从而给出最准确的预测。
感知机:最简单的神经网络
概述与算法
从表面上看,神经网络似乎是推动当前人工智能革命的一颗新星。
然而,它们实际上已经存在相当长的时间了,它们起源于一种叫做感知机的东西,这是由弗兰克·罗森布拉特在20世纪50年代发明的,灵感来自十年前沃伦·麦卡洛克和沃尔特·皮茨的工作。

美国科学家弗兰克· 罗森布拉特与感知机
让我们来看看它是如何工作的:

感知器,最简单的神经网络
这个图表基本上解释了整个感知机算法,该算法用于二分类问题,让我们逐步分解:
输入:这是我们数据的特征。
权重:我们乘以输入的系数。算法的目标是找到最优的权重。
线性加权和:将输入和权重的乘积相加,并加上一个偏置/偏移项b。
阶跃函数:如果线性加权和的值大于0,则我们预测为1,否则为0,这在领域中被称为激活函数。
权重通过以下称为delta规则的学习算法进行优化:
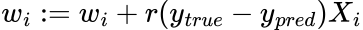
其中r是学习率,这是更著名的反向传播算法的简化版本,基于梯度下降。
大家可能会注意到,感知机与逻辑回归非常相似,它们的主要区别在于,后者使用sigmoid激活函数将输出转换到0和1之间。现代神经网络可以被看作是一系列逻辑回归模型的串联。
局限性与问题
如今,由于感知机的局限性和更好的算法的存在,它很少被使用。
感知机的主要局限在于它是一个严格的线性分类器,因为阶跃函数是线性的,这意味着它对于任何非线性可分的数据都会感到困难。
另一个问题是,感知机无法学习XOR函数/逻辑门,但是通过将多个感知机堆叠在一起,这个问题就得到了解决,我们稍后会详细讨论!
为了帮助大家更快速高效的学习,小墨还为大家整理一份 60天入门机器学习深度学习的学习计划。

点击图片可查看详细介绍
60天学习计划中的资料已经打包下载好了,大家可以任意添加一个小助手,让她发给你。


多层感知机
概述
普通的感知机也被称为单层神经网络,其中“单层”指的是网络只有一个神经元层,数据通过该层传递。
然而,所有现代的神经网络都是由多个神经元堆叠而成的,毕竟,我们不能只有一个神经元的网络!
这就是多层感知机发挥作用的地方,我们将多个感知机堆叠并相互连接。
架构
下面是一个基本多层感知机的示例架构:
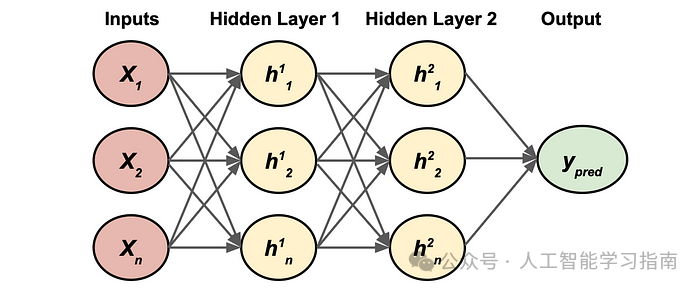
一个基础的双隐藏层多层感知机
让我们分解一下这个图表:
输入:这是我们数据的n个特征。
隐藏层:这是存储多个感知机的地方,每个神经元都是我们之前讨论过的感知机。上标指的是层,下标指的是该层中的神经元/感知机。
边/箭头:这些是网络从相应输入(无论是特征还是隐藏层输出)的权重。图中省略了它们,以免图表变得混乱。
这里不同的是,我们有一个感知机的输出流入另一个感知机,这发生在两个隐藏层之间,除此之外,这与感知机算法相同,但参数更多。
例如,h¹_1的计算将是:
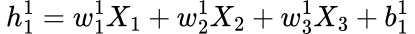
在这其中,w代表权重,b代表该层对应神经元的偏置,在这个例子中,是第一层中的神经元1。
这个计算过程会对第一层隐藏层中的每一个其他神经元重复进行。然后,这些输出会作为输入传递给第二层隐藏层,真的就这么简单!
这种计算通常通过向量化并由点积运算来完成。
局限与问题
多层感知器的问题在于,它仍然使用线性函数来对数据进行分类。
在算法过程中,没有“打破”线性的步骤,使网络能够学习非线性函数。
如何解决?
当然是使用激活函数了!某些激活函数可以使输出非线性,从而满足所谓的“万能逼近定理”。
该定理表明,如果神经网络包含非线性激活函数,那么它可以拟合到任何函数,达到合理的程度。
具有线性激活函数的多层感知器或网络实际上是线性回归的一种形式!
总结与进一步思考
在本文中,我们深入了解了神经网络背后的关键概念和构建块——感知器。
这是一种简单的算法,它接收输入,将其乘以一些权重,求和,然后根据结果是否大于或等于零输出0或1。
这个算法可以被称为神经元,多个神经元可以堆叠在一起形成层,这种结构通常被称为多层感知器,俗称神经网络。
60天学习计划中的资料已经打包下载好了,大家可以任意添加一个小助手,让她发给你。










