本推文来源:中加中心SCWE

近年来,随着极端降水事件的频发,导致城市洪涝灾害严重,造成财产损失并威胁公共安全。传统洪水监测方法依赖现场观测,难以提供大范围实时数据。为了解决城市洪涝面积难以精准提取的难点问题,南开大学黄津辉教授团队结合社会感知和遥感卫星数据,提出了一种名为EMF的集成模型。目前已将相关研究成果发表在期刊《Sustainable cities and society》上,题为“Urban
flood susceptibility mapping using remote sensing, social sensing and an
ensemble machine learning model”。
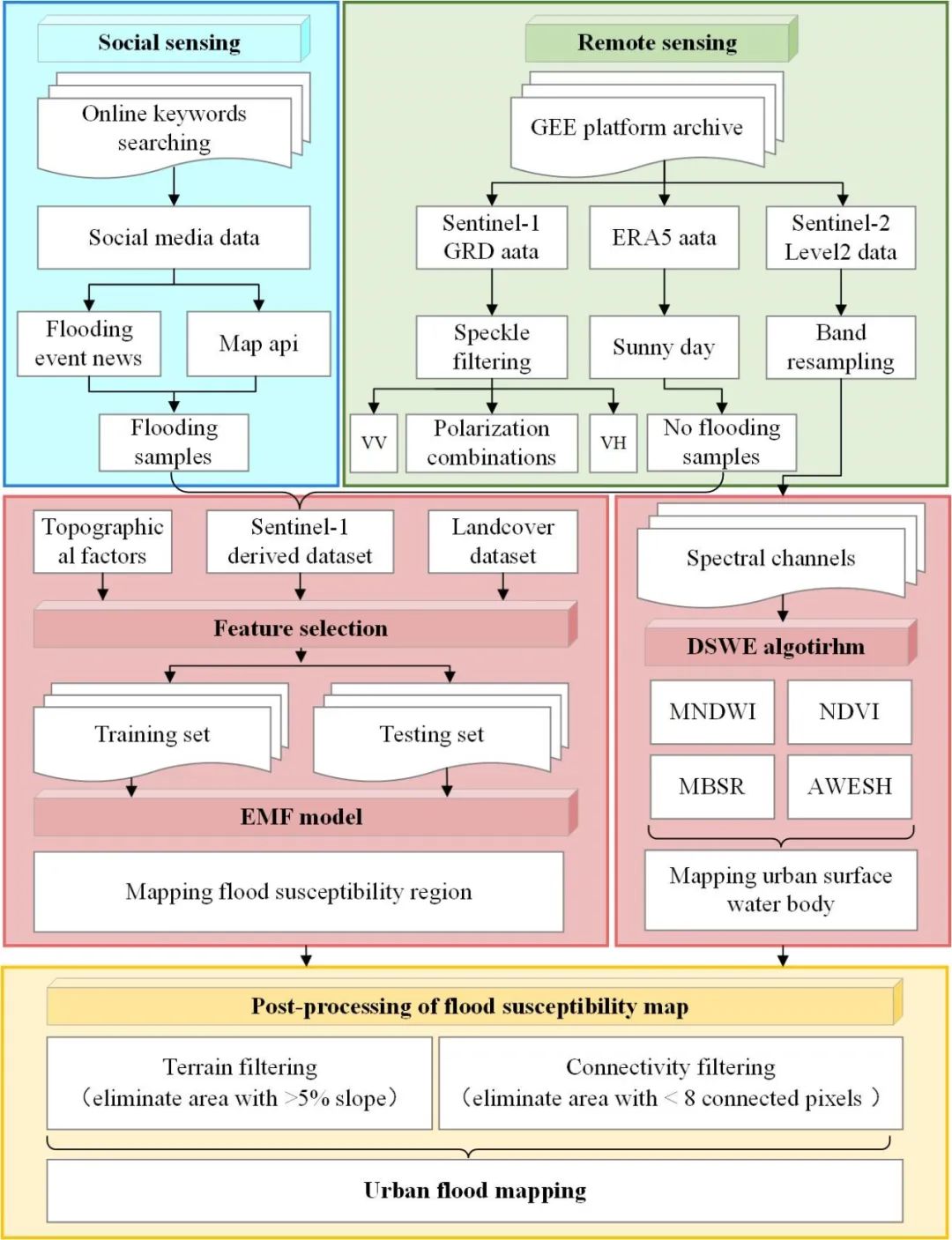
图1 研究技术路线
研究选择了头条、YouTube、TikTok和快手四个社交媒体平台作为社会感知数据来源。这些平台涵盖了官方机构发布的信息和用户生成的内容,能够提供丰富且多样化的洪水相关信息。进一步,研究建立了包含地点名称 (天津)、洪水相关术语 (洪水、淹没、积水) 和事件详细信息 (日期、受影响区域)的关键词系统,用于检索与洪水事件相关的文本数据。利用 Python 库 (Beautifulsoup4 和 Selenium) 自动检索社交平台上的帖子,获取帖子的类型、覆盖范围、简介和网页链接等信息。通过视觉解释,从帖子中提取时间和位置信息,并将其与数字地图结合,获取精确的地理坐标。

图2 社会感知数据提取框架
研究采用随机森林特征重要性排序(FFIR)方法,分析了与洪水发生显著相关的特征的重要性。FFIR 方法通过量化每个特征对模型决策过程的影响程度,实现了特征重要性的量化评估。通过对大量模型迭代结果的统计分析,该方法能够有效地识别出对洪水发生具有关键影响的特征。结果表明,log|VH|、VV/VH、log|VV|、VV*VH 和距河流距离等特征的重要性最高,解释了总特征重要性的90%。这表明,这些特征在区分洪水区域和非洪水区域方面起着至关重要的作用,为模型构建和洪水易发区制图提供了重要的参考依据。

图3 基于随机森林特征贡献度的洪水影响因子的重要性排序
此外,研究害对比了四种独立机器学习模型 (XGBoost、SVC、MLP 和 MDL) 与所提出的集成模型 (EMF) 的性能,并使用准确率、召回率、精确率、误报率 (MR) 和 F1 分数等指标进行了评估。结果表明,EMF 模型在训练集和测试集上都取得了最高的准确率、精确率和 F1 分数,分别为 0.94、0.96和 0.93。这表明 EMF 模型能够有效地识别洪水区域,并具有较高的泛化能力。与其他独立模型相比,EMF 模型的召回率和误报率略低,表明该模型在识别洪水区域时更加谨慎,以减少误分类的风险。

图4 模型对比图
最后,研究利用ERA5数据统计了 2014 年 1 月至 2023 年 11 月天津市的平均每日降水量,并确定了暴雨和强降雨事件的日期。利用训练的EMF模型和 Sentinel-1 SAR 数据绘制了五个暴雨事件期间的洪水淹没区域图,并与土地利用数据进行比较。结果表明,天津市的洪水易发区域主要集中在城郊和山区,且农田是受洪水影响最大的土地利用类型,占总淹没面积的 52.8%。城市道路、桥梁等低洼地区容易受到洪水的影响,管理者应加强这些区域排水设施的建设,以及在后续城市发展过程中融入海绵城市概念,以减少洪水灾害的影响。
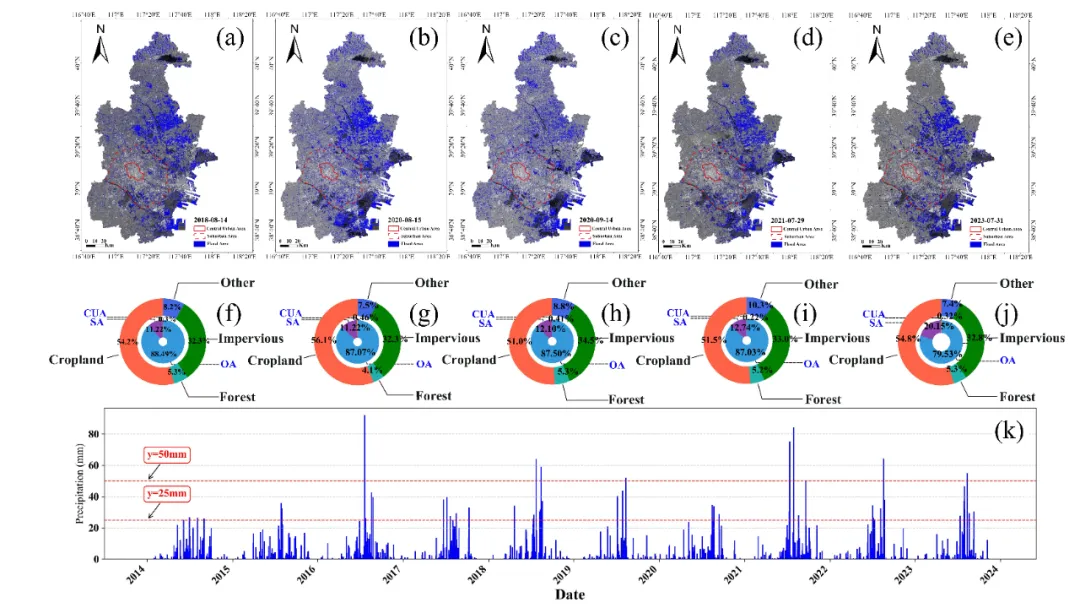
图5 利用Sentinel-1 SAR数据和EMF模型对2018年至2023年五次强降雨事件的洪水制图。(a)-(e)在特定日期的空间分布图。(f)-(j)对应日期不同土地利用类型及中心城区(CUA)、郊区(SA)和偏远地区(OA)的洪水覆盖比例面积。(k)根据ERA5数据获取的2024年1月至2023年11月31日的平均降水量。
研究展示了机器学习模型和卫星数据在城市洪水监测和风险评估中的巨大潜力,所提出的方案可为城市防洪减灾和可持续发展提供技术支持。
文章DOI:https://doi.org/10.1016/j.scs.2024.105508






