点击下方卡片,关注「魔方AI空间」公众号
❝写在前面
【魔方AI新视界】专栏致力于梳理和探索AIGC领域内的创新技术与有影响力的实际应用案例。我们计划以月刊的形式定期发布内容,目的是让读者站在AI时代的最前沿,紧跟时代发展的步伐,自信而坚定地跟随AI技术的最新趋势。
此外,猫先生也会根据读者的反馈,持续对专栏内容和版面设计进行更新和改进。我们非常欢迎读者提出宝贵的建议,一起交流和学习,共同推动专栏的完善和成长!💪
大家好,我是猫先生,AI技术爱好者与深耕者!!
阅读猫先生整理的《魔方AI新视界》专栏,您将获得以下宝贵收获:
- 前沿技术洞察:深入了解AIGC行业的核心技术动向,涵盖AI绘画、AI视频、大型模型、多模态技术以及数字人等领域的最新进展,让您始终站在技术发展的最前沿。
- 职业发展助力:在专栏中发现那些能够激发创新灵感的关键技术和应用案例,这些内容对您的职业发展具有重要意义,帮助您在专业领域中取得突破。
- 紧跟时代潮流:通过专栏,您将能够准确把握时代的脉搏,自信而坚定地跟随AI技术的最新趋势,确保您在快速发展的AI时代中保持竞争力。
《魔方AI新视界》不仅是一个信息的汇聚地,更是一个促进思考、激发创新的平台,猫先生期待与您一起探索AI的无限可能。
本文是《魔方AI新视界》专栏的第五期,周期为2024年9月1日-2024年9月30日。在本期中,猫先生将采用精炼而扼要的语言,对AI领域的前沿技术进行介绍,并提供详情链接,以便于您能够进一步探索和学习。
❝本文整理自《AIGCmagic社区飞书知识库》的每周AI大事件板块,飞书主页地址:AIGCmagic社区[1],欢迎大家点赞评论!!
 AIGCmagic社区飞书知识库概览
AIGCmagic社区飞书知识库概览
往期回顾
本期速览
1. 阿里发布MIMO:可控角色视频合成
2. OpenMusic:基于QA-MDT的开源文生音乐模型
3. ExAvatar:基于10s视频即可生成3D数字人
4. Meta 发布 Llama 3.2:多模态轻量级,支持手机端
5. 腾讯发布LVCD:基于扩散模型 | 动漫线稿视频着色
6. 腾讯发布DepthCrafter:新颖的视频深度估计方法
7. 上海AI Labs发布书生·筑梦2.0:开源视频生成模型
8. Moshi:用于实时对话的语音-文本基础模型
9. ComfyUI-NodeAligner:轻量级的 ComfyUI 布局插件
10. GOT-OCR-2.0模型开源:下一代OCR模型
11. Draw an Audio:利用多指令进行视频配音
12. Adobe Firefly:视频编辑的新时代
13. 字节发布 Loopy:音频驱动的人像照片说话模型
14. 多模态大模型VideoLLaMB:长上下文视频理解新框架
15. Mini-Omni:首个端到端语音对话模型,具有实时语音交互能力
16. 字节发布Show-o:统一多模态理解和生成
正文开始
1. 阿里发布MIMO:可控角色视频合成[2]
- MIMO是一种用于可控视频合成的通用模型,可以通过对象交互模拟复杂运动中的任何人!
- 它不仅可以合成具有由简单用户输入提供的可控属性(即角色、动作和场景)的角色视频。
- 实现对任意角色的高级可扩展性、对新颖 3D 动作的通用性以及对交互式现实世界场景的适用性在一个统一的框架中。
- 项目主页:https://menyifang.github.io/projects/MIMO/index.html

2. OpenMusic:基于QA-MDT的开源文生音乐模型[3]
- OpenMusic,这是下一代扩散模型,旨在从文本描述中生成高质量的音乐音频!
- 只需输入几句描述氛围的词语,然后观察模型为您的输入生成独特的音轨。
- 基于QA-MDT,使生成模型能够在训练期间识别输入音乐波形的质量。
- 体验地址:https://huggingface.co/spaces/jadechoghari/OpenMusic
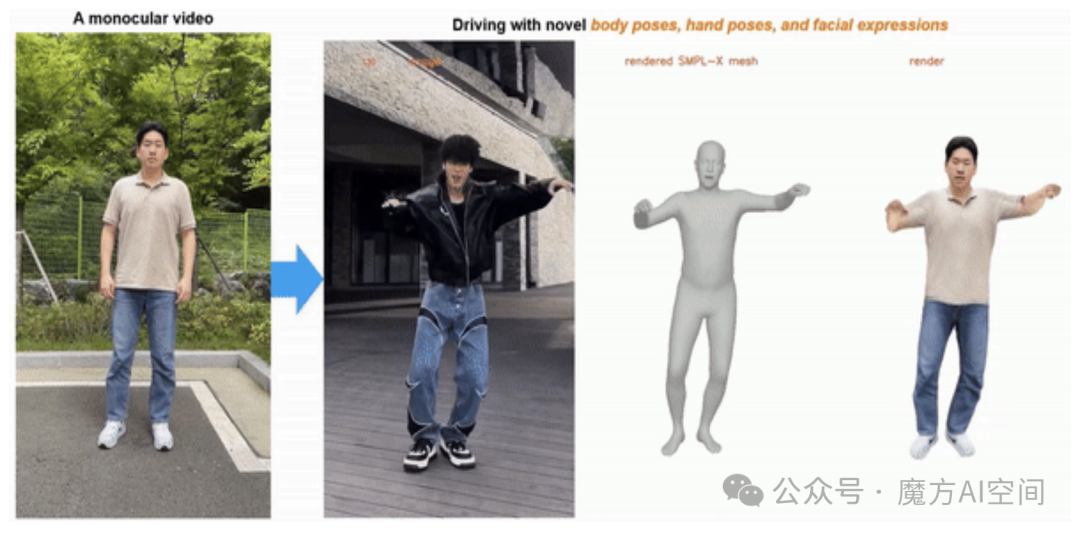
3. ExAvatar:基于10s视频即可生成3D数字人[4]
- 只需拍摄 10 秒视频,即可生成你的 3D 数字人,支持全身动作、手部和面部 表情。
- 原作者对《Expressive Whole-Body 3D Gaussian Avatar》的重新实现。
- 项目地址:https://github.com/mks0601/ExAvatar_RELEASE
4. Meta 发布 Llama 3.2:多模态轻量级,支持手机端[5]
- 适合边缘和移动设备的中小型视觉LLMs(11B 和 90B)和轻量级纯文本模型(1B 和 3B),包括预训练和指令调整版本。
- Llama 3.2 1B 和 3B 模型支持 128K 令牌的上下文长度,是同类产品中最先进的,适用于在边缘本地运行的设备端使用案例,例如摘要、指令跟踪和重写任务。
- 最大的两个模型 11B 和 90B 支持图像推理使用案例,例如文档级理解(包括图表和图形)、图像字幕和视觉基础任务(例如根据自然语言描述定向精确定位图像中的对象)
- 模型地址:https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf

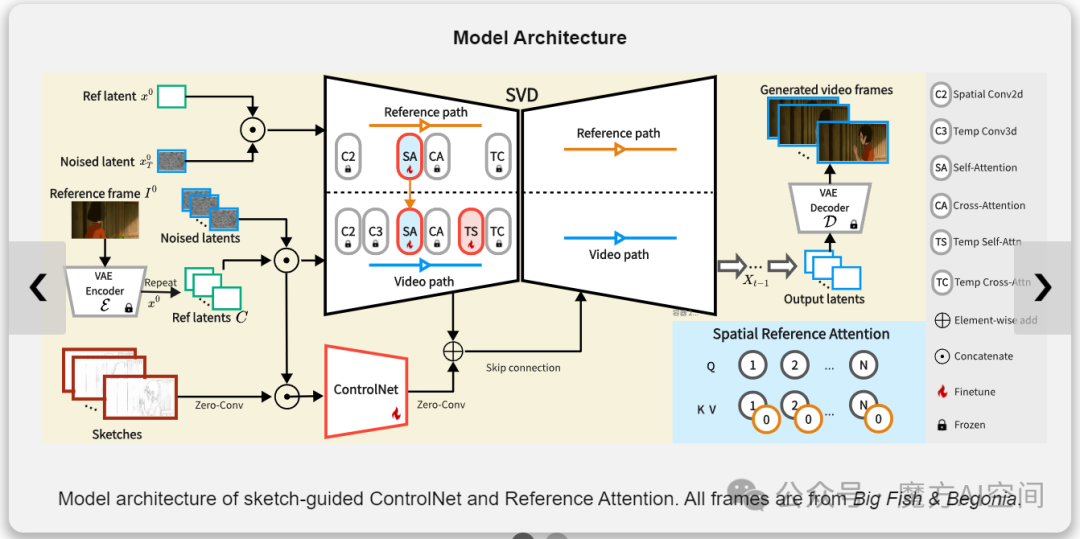
5. 腾讯发布LVCD:基于扩散模型 | 动漫线稿视频着色[6]
- 为基于参考的线稿视频着色设计一个视频扩散框架,能够产生时间上一致的具有大动作的长序列动画。
- 利用大规模预训练视频扩散模型来生成彩色动画视频,可以产生时间上更一致的结果,并且更适合处理大型运动。
-
草图引导的 ControlNet 和 Reference Attention,使模型能够生成由线性草图引导的快速和扩展运动的动画。
- 一种新的顺序采样方案,结合重叠混合模块和前参考注意力,以将视频扩散模型扩展到其原始的固定长度限制之外,以进行长视频着色。
- 项目地址:https://luckyhzt.github.io/lvcd
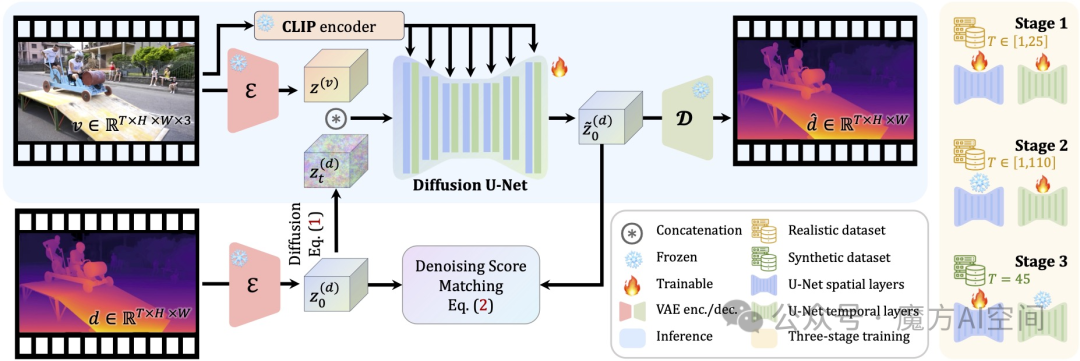
6. 腾讯发布DepthCrafter:新颖的视频深度估计方法[7]
- 为开放世界视频生成具有精细细节的时间一致的长深度序列,而无需摄像机姿势或光流等其他信息。
- DepthCrafter 是一个条件扩散模型,用于对 以输入视频为条件的深度序列上的分布。
- 将视频划分为重叠的片段,并估计每个片段的深度序列 使用噪声初始化策略来锚定深度分布的比例和偏移。
- 项目主页:https://depthcrafter.github.io/
7. 上海AI Labs发布书生·筑梦2.0:开源视频生成模型[8]
- Vchitect-2.0 是一个高质量的视频生成模型,具有 20 亿个参数,支持高达 720x480 的分辨率和 10-20 秒的视频持续时间。此外,我们还在开发一个更大的版本,有 50 亿个参数,未来会发布。
- VEnhancer 是一个生成式时空增强框架。它集成了超分辨率、帧插值和视频优化功能,以 24 FPS 的速度将视频质量提升到 2K 分辨率。
- LiteGen 是一个轻量级且高效的扩散任务训练框架。在 Vchitect-2.0 模型的训练期间,它使用 8 个 NVIDIA A100 GPU 卡支持高达 163 万个令牌的序列长度。
-
VBench 是视频生成模型的综合基准测试套件,涵盖 28 个文本到视频生成模型和 12 个图像到视频生成模型。
- 项目主页:https://github.com/Vchitect/Vchitect-2.0
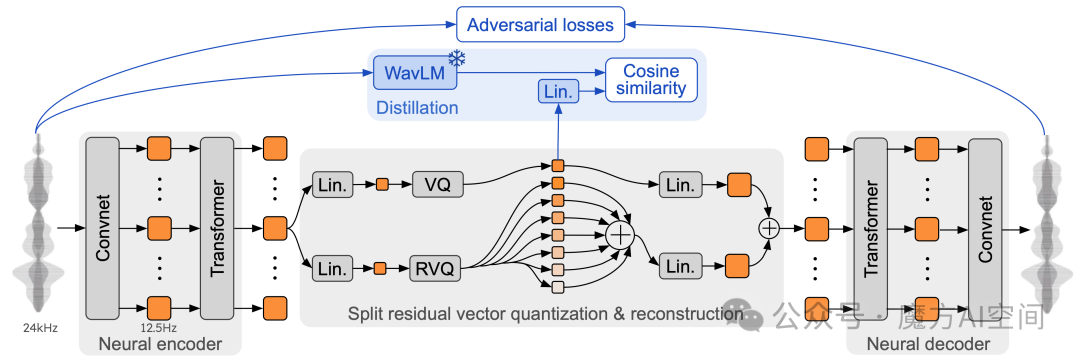
8. Moshi:用于实时对话的语音-文本基础模型[9]
- Moshi[10] 是一个语音文本基础模型和全双工口语对话框架。
- Moshi 对两个音频流进行建模:一个对应于 Moshi,另一个对应于用户。
- 项目地址:https://github.com/kyutai-labs/moshi
9. ComfyUI-NodeAligner:轻量级的 ComfyUI 布局插件[11]
- 该插件旨在简化可视化节点编辑器或自定义 UI 组件中的布局调整,使节点排列更加方便和高效。
- 项目地址:https://github.com/Tenney95/ComfyUI-NodeAligner
10. GOT-OCR-2.0模型开源:下一代OCR模型[12]
- GOT 具有 580M 参数,是一个统一、优雅、端到端的模型,由一个高压缩编码器和一个长上下文解码器组成。
- GOT 可以处理各种 OCR 任务下的各种“字符”,包括纯文本、数学/分子式、表格、图表、乐谱,甚至几何形状;
- 在输入端,该模型支持切片和整页样式中常用的场景和文档样式图像,在输出端,GOT 可以通过简单的提示生成纯文本或格式化的结果 (markdown/tikz/smiles/kern)。
- 项目地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0

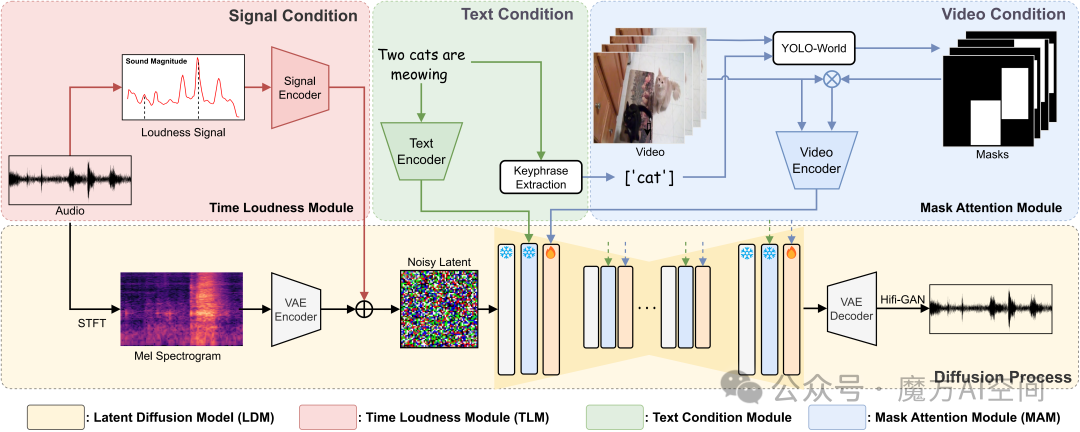
11. Draw an Audio:利用多指令进行视频配音[13]
- 采用多条指令来产生高质量的同步音频,并且可以在多阶段产生混合音频,从而表现出更大的实际应用。
- 基于潜在扩散模型(LDM),融合文本条件模型、掩码注意力模块(MAM)和时间响度模块(TLM)。
- LDM通过变分自编码器(VAE)将音频转换为压缩的潜在空间特征,从而减少计算负担。
- 项目主页:https://yannqi.github.io/Draw-an-Audio/
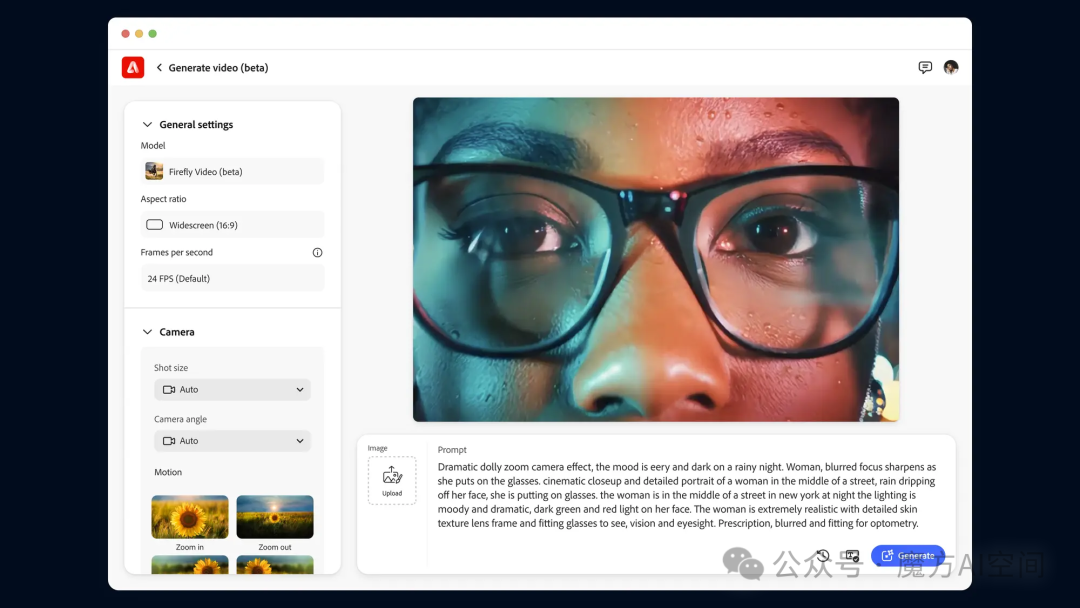
12. Adobe Firefly:视频编辑的新时代[14]
- 2023 年 3 月首次推出 Adobe Firefly;近期,即将推出 Firefly 视频模型。
- 借助 Firefly 文本到视频,可以使用文本提示、各种摄像机控件和参考图像来生成无缝填充时间轴空白的 B-Roll。
- 申请内测地址:https://blog.adobe.com/en/publish/2024/09/11/bringing-gen-ai-to-video-adobe-firefly-video-model-coming-soon
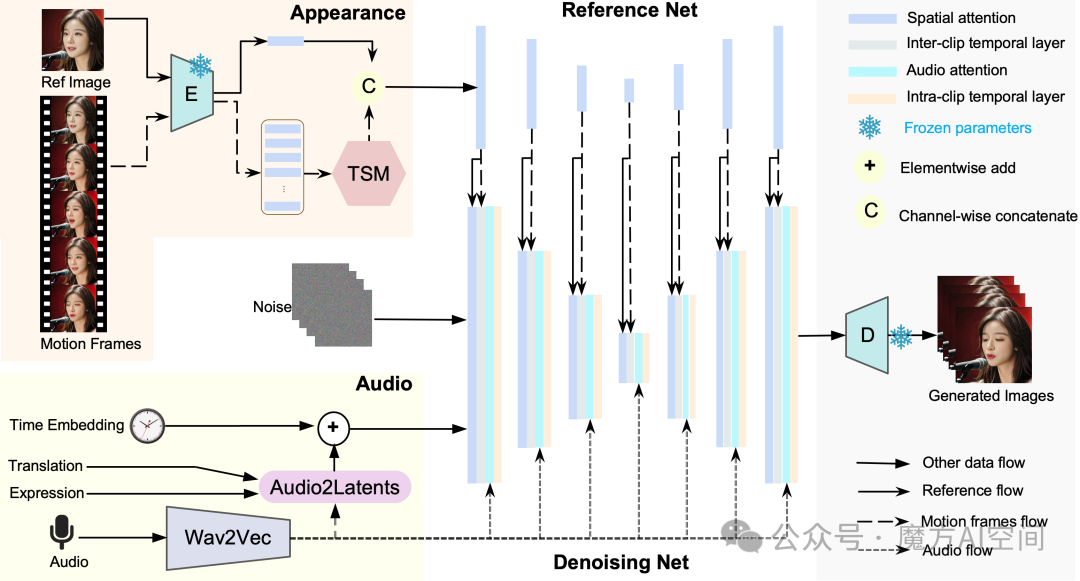
13. 字节发布 Loopy:音频驱动的人像照片说话模型[15]
- Loopy 支持各种视觉和音频样式。 它可以仅从音频中生成生动的运动细节,例如非语音运动(如叹息)、情绪驱动的眉毛和眼球运动以及自然的头部运动。
- Loopy 可以根据不同的音频输入为同一参考图像生成运动适应合成结果,无论它们是快速、舒缓还是逼真的歌唱表演。
- 项目主页:https://loopyavatar.github.io/
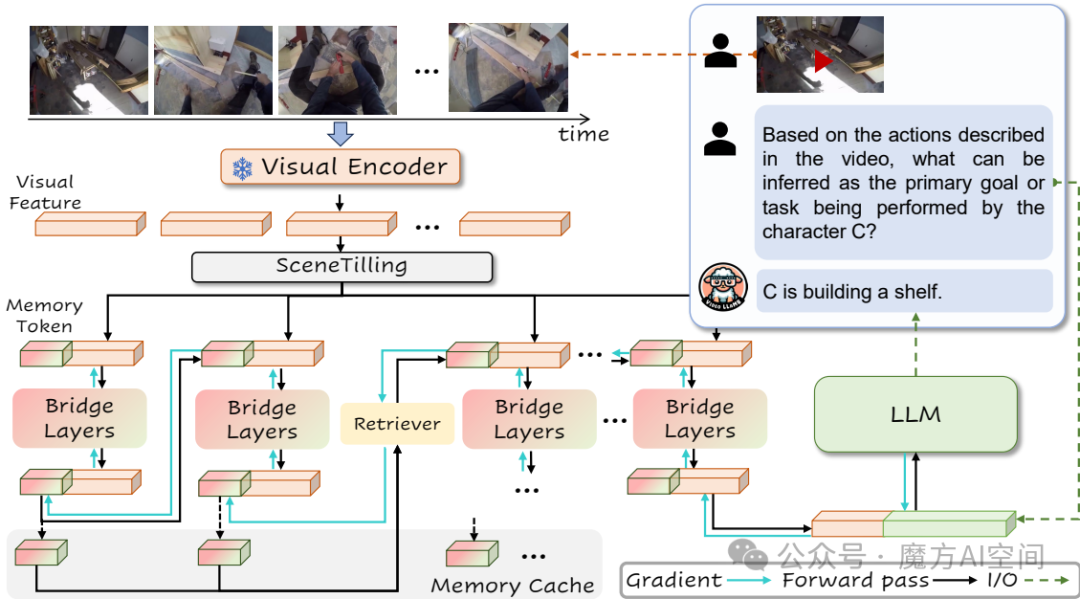
14. 多模态大模型VideoLLaMB:长上下文视频理解新框架[16]
- 一种新颖的长视频理解框架,利用带有递归内存 token 的内存桥接层对 100% 的视频内容进行编码,而不会丢弃关键的视觉提示。
- 全面的长视频理解、基于记忆的以自我为中心的规划、无需训练的流式字幕生成、增强的长视频帧检索能力、高效的计算性能。
- 项目主页:https://videollamb.github.io/
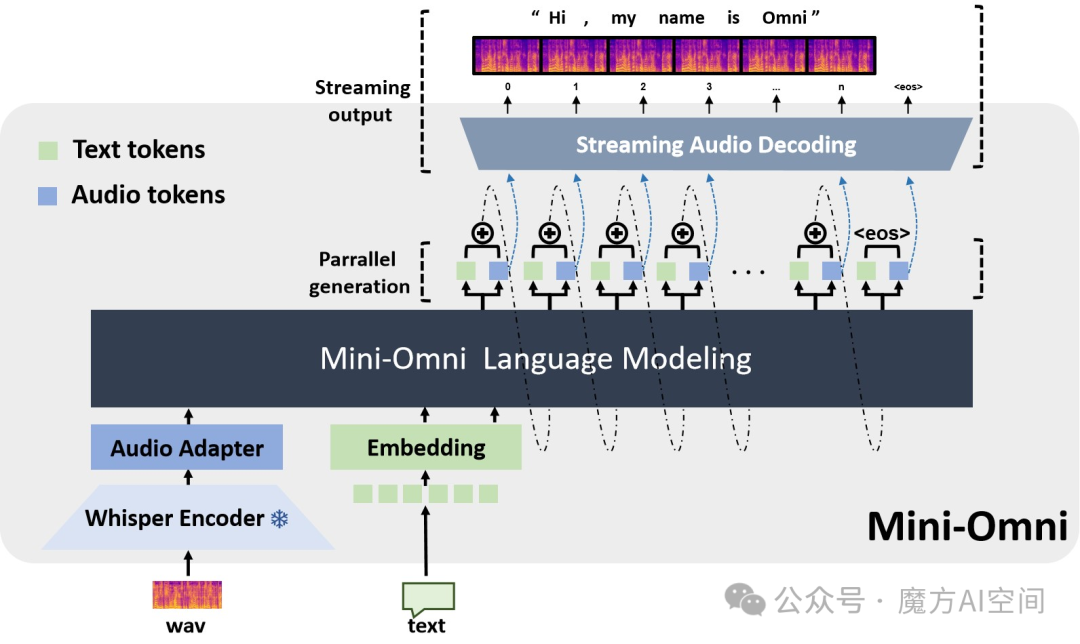
15. Mini-Omni:首个端到端语音对话模型,具有实时语音交互能力[17]
- Mini-Omni 是一个开源的多模态大型语言模型,可以边思考边听、边说。具有实时端到端语音输入和流式音频输出对话功能。具有以下特点:
- 实时语音到语音的对话能力: 无需额外的ASR或TTS模型
- "Any Model Can Talk" 方法: Mini-Omni 可以将语音交互能力添加到其他模型中,为其他模型赋能
- 项目地址:https://github.com/gpt-omni/mini-omni
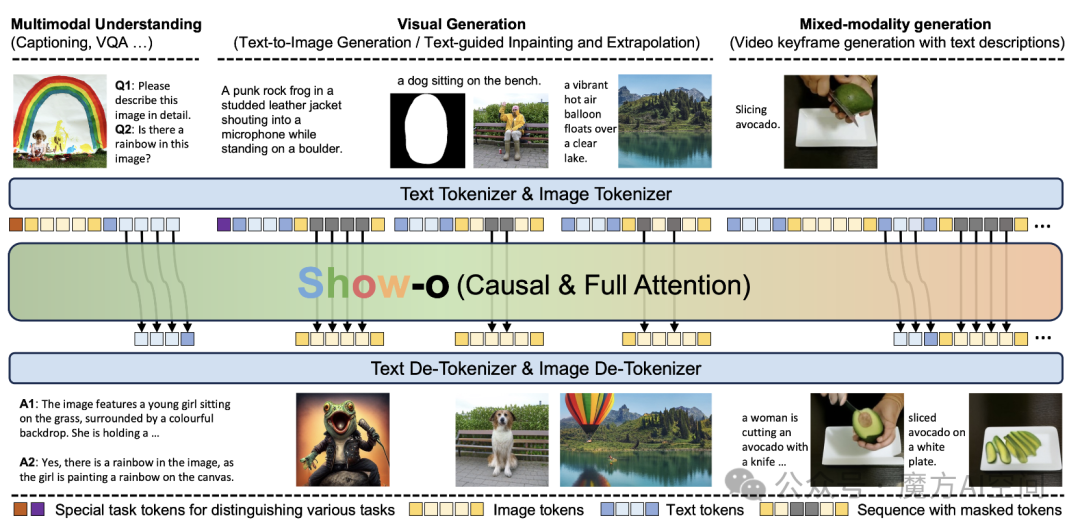
16. 字节发布Show-o:统一多模态理解和生成[18]
- 一种新的统一模型,即 Show-o,能够通过混合自回归和扩散建模同时处理多模态理解和生成任务。
- 创新性地在单个Transformer中结合了自回归和(离散)扩散建模,分别处理文本和图像。作为统一模型,Show-o在多模态理解和生成基准测试中表现出与个别基线模型相当甚至更好的性能。
- Show-o天然支持各种下游应用,如基于文本的修复和外推,无需任何微调。此外,它还展示了混合模态生成的潜力。
- 探索了不同类型表示(离散或连续)对多模态理解性能的影响,为未来统一模型的设计提供了系统性的见解。
-
项目主页:https://showlab.github.io/Show-o/
技术交流
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在「魔方AI空间」,关注了解全栈式 AIGC内容!!
推荐阅读
• AIGCmagic社区共建邀请函!
• 万字长文 | AIGC时代算法工程师的面试秘籍(2024.5.13-5.26第十四式)
• AIGC | 「视频生成」系列之Suno制作MV视频工作流分享(保姆级)
• AIGC|一文梳理「AI视频生成」技术核心基础知识和模型应用
• AIGC潮流:2023年的冲击与2024年的趋势预测
• AIGC|OpenAI文生视频大模型Sora技术拆解(含全网资料汇总)
[1]AIGCmagic社区: https://a1qjvipthnf.feishu.cn/wiki/IQrjw3pxTiVpBRkUZvrcQy0Snnd?from=from_copylink
[2]阿里发布MIMO:可控角色视频合成: https://menyifang.github.io/projects/MIMO/index.html
[3]OpenMusic:基于QA-MDT的开源文生音乐模型: https://github.com/ivcylc/qa-mdt
[4]ExAvatar:基于10s视频即可生成3D数字人: https://github.com/mks0601/ExAvatar_RELEASE
[5]Meta 发布 Llama 3.2:多模态轻量级,支持手机端: https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
[6]腾讯发布LVCD:基于扩散模型 | 动漫线稿视频着色: https://luckyhzt.github.io/lvcd
[7]腾讯发布DepthCrafter:新颖的视频深度估计方法: https://depthcrafter.github.io/
[8]
上海AI Labs发布书生·筑梦2.0:开源视频生成模型: https://vchitect.intern-ai.org.cn/
[9]Moshi:用于实时对话的语音-文本基础模型: https://github.com/kyutai-labs/moshi
[10]Moshi: https://kyutai.org/Moshi.pdf
[11]ComfyUI-NodeAligner:轻量级的 ComfyUI 布局插件: https://github.com/Tenney95/ComfyUI-NodeAligner
[12]GOT-OCR-2.0模型开源:下一代OCR模型: https://github.com/Ucas-HaoranWei/GOT-OCR2.0
[13]Draw an Audio:利用多指令进行视频配音: https://yannqi.github.io/Draw-an-Audio/
[14]Adobe Firefly:视频编辑的新时代: https://blog.adobe.com/en/publish/2024/09/11/bringing-gen-ai-to-video-adobe-firefly-video-model-coming-soon#form
[15]字节发布 Loopy:音频驱动的人像照片说话模型: https://loopyavatar.github.io/
[16]多模态大模型VideoLLaMB:长上下文视频理解新框架: https://videollamb.github.io/
[17]Mini-Omni:首个端到端语音对话模型,具有实时语音交互能力: https://github.com/gpt-omni/mini-omni
[18]字节发布Show-o:统一多模态理解和生成: https://showlab.github.io/Show-o/









