on-policy: 学习到的 agent 和与环境交互的是同一个agent,即 agent 一边和环境互动,一边学习。
off-policy: 学习到的 agent 与环境交互的 agent 是不同的,即 agent 通过看别人玩游戏来学习。
下图是一个经典的例子,如果直接和老大爷下棋,就属于on-policy,因为是自身通过与环境的互动来直接学习;而在旁边看老大爷和其他人下棋,就属于off-policy,因为是通过别人的互动中汲取经验。

1)训练慢
policy gradient 是on-policy 方法,只能通过和环境的不断互动,拿到当前的反馈来更新agent。
这就意味要花大量时间在采样上,数据利用率低,训练非常慢。agent 更新参数后,要重新 sample 一堆 trajectory τ ,之前的 trajectory 全部不能用了, sample 一堆 data 后只够做一次参数更新。
2)训练不稳定
policy gradient 对于 learning rate 非常敏感。
如果学习率过大,就会导致学习出bad policy,由于下一轮的采样是基于当前的策略,所以bad policy 导致收集到bad samples,bad samples 又会导致学习出更坏的策略。属于恶性循环了。
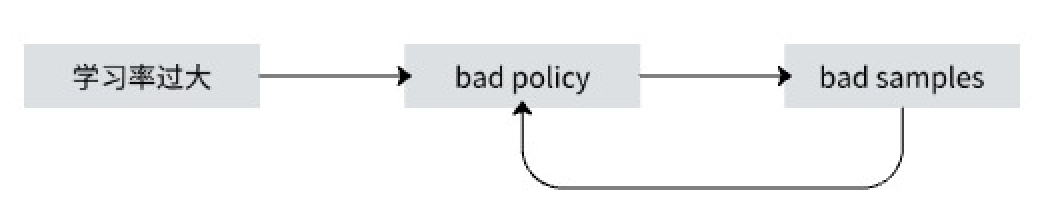
如果学习率过小,则可能学习速度比较慢。
PPO (proximal policy optimization) 能使得policy gradient 更加高效的利用数据,并且使得训练更加稳定。上文中介绍的TRPO 是 PPO的前身,比较复杂,不经常使用,两者效果差不多。
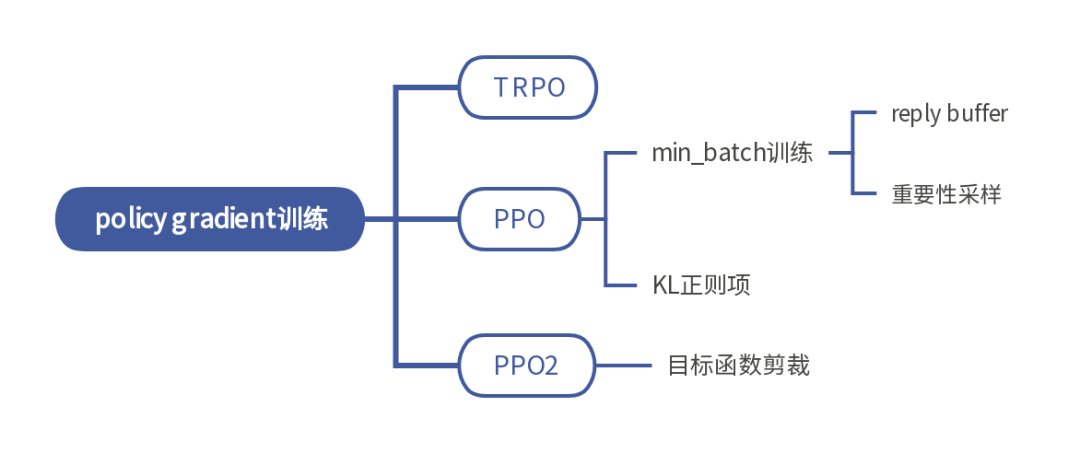
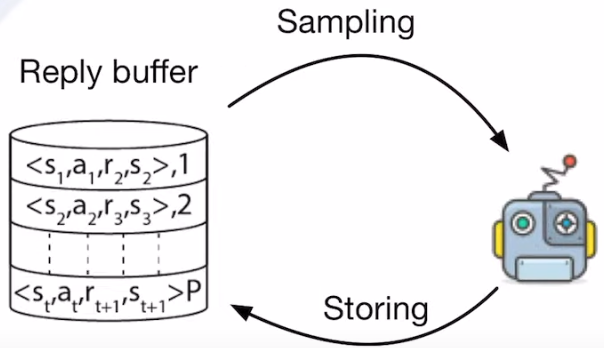
ppo 使用reply buffer 来解决训练效率低的问题,但是用到了 reply buffer 就变成了off-policy,因为 reply buffer 存储的都是曾经参数下的 agent 与环境交互留下来的数据。
而policy gradient 本身是一个 on-policy 的算法,所以 ppo 采用了重要性采样的方式,用重要性权重来修正,使得 off-policy 能近似等同于 on-policy。
policy gradient 是 on-policy 方式,使用 πθ 来收集数据,参数 θ 被更新后,需要重新对训练数据进行采样,这样会造成巨大的时间消耗。而 off-policy 的改进思想是利用 πθ′ 来进行采样,将采集的样本拿来训练 θ ,θ′ 是固定的,采集的样本可以被重复使用。
回顾下 强化学习7:policy gradient & reinforce 的优点是什么呢 介绍的policy gradient 的更新公式:
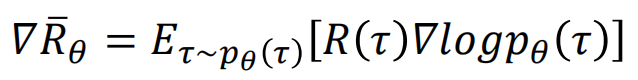
重要性采样是通过如下的推导:
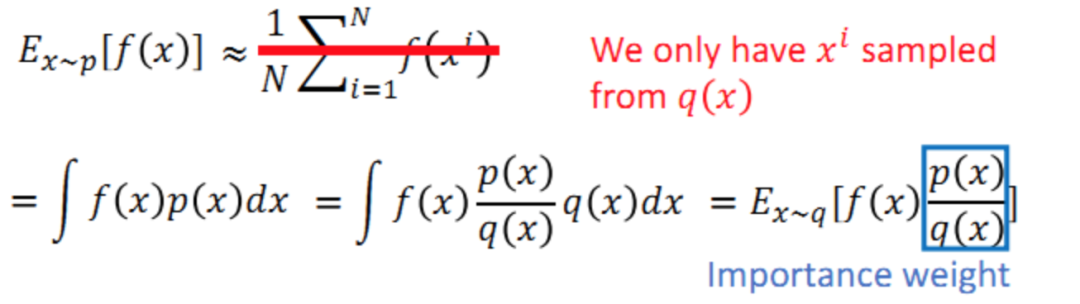
Ex∼p[f(x)] 代表从分布 p 中取样本 x 送入函数 f(x) 并求期望,这可以近似于 sample N 个 xi,然后带入f(x) 求平均,即Ex∼p[f(x)]≈1/N∑Ni=1f(xi) 。现在假设我们不能从分布 p 中 sample 数据,只能从分布 q 中 sample,这样就不能直接套上述近似。而要用:
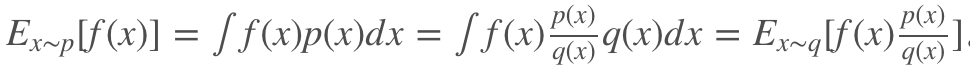
更换分布之后,需要使用重要性权重p(x)/q(x)来修正f(x),这样就实现了使用 q 分布来计算 p 分布期望值。
需要注意的是,p 和 q 的分布差别不能过大,否则需要采样足够多的样本才能保证正确性。下面来举例说明:
下图中,实际分布p和辅助分布q差别较大,横轴左边表示收益为负,右边表示收益为正。蓝色的线表示真实分布p的分布,主要集中在左边,也就是说,真实情况下reward的期望值应该是负的。
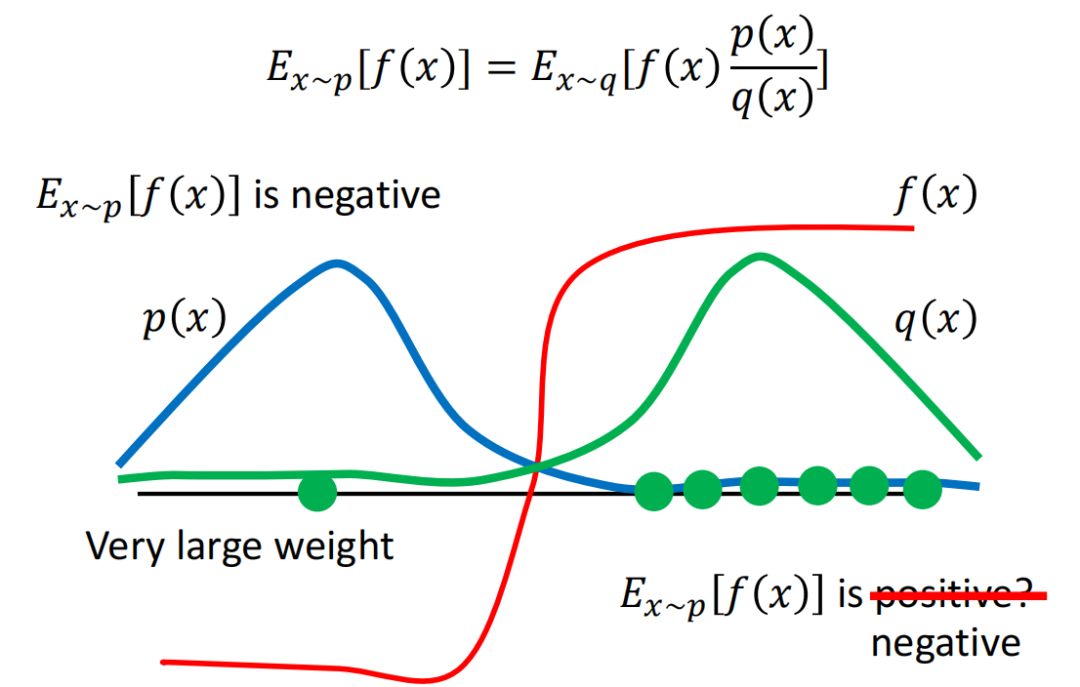
但是由于辅助分布q,即绿色线,主要集中在右侧,因此在采样的时候采到右边的概率更大,可能会导致多轮采样之后,算出来的期望收益为正。
只有当采样到左侧的点,并且乘上较大的修正系数 p/q之后,算出的结果才会变成真实的符号,负号。尽管采样到右侧的点时修正系数 p/q 很小,最终结果可能依旧是正确的,但这样会导致在采样上耗费较大的时间,因此,p q分布之间的差异依旧不宜过大。
先来看看使用重要性采样之后,原先梯度的变化:

在off-policy 要注意的一点就是原来 advantage function中 Aθ(st,at)=R(τn)−b 的 θ 也要改为 θ′ ,因为现在是 πθ′ 在和环境互动。
直接假设 pθ(st)/pθ′(st) =1,因为猜测 state 的出现与 θ 关系不大,况且这一项本来就无法计算,因为state出现的概率我们是不能控制或估计的。
通过梯度,来反推出目标函数如下:
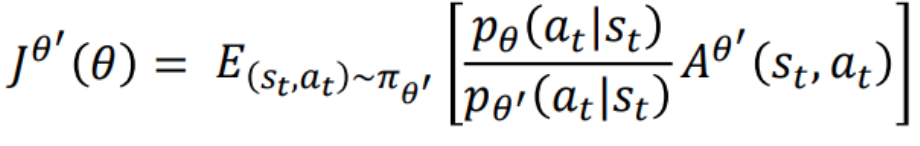
1. 使用随机初始化神经网络
2. 对于every episode:
使用当前策略与环境交互,收集一系列的 trajectory,保存在 reply buffer 中。
对于每轮迭代:
a. 从 reply buffer 中采样 min-batch 的经验
b. 最大化目标函数,更新policy 网络的梯度
使用最新的参数来更新旧的policy,方便之后的与环境互动采样。
3.重复流程,直到收敛。
上面我们论证了需要p(x) 和 q(x) 的分布较为接近,即pθ(at|st) 与 pθ′(at|st) 要比较相近。
KL距离是一个衡量分布距离的很好的指标,KL距离的公式如下:

所以在原先目标函数上加上KL距离正则项:
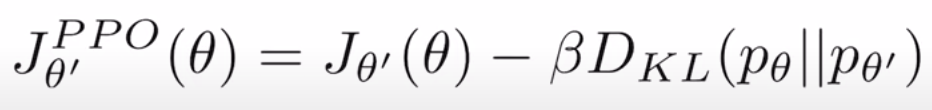
KL距离的权重 β 应该怎么设定呢?
当KL距离比较大的时候,β应该比较大,从而更加关注减小KL距离;
当KL距离比较小的时候,β可以小点,从而更加关注增加J(θ)。
所以PPO 设置一个[δ/1.5, δ*1.5] 的区间,如果KL距离大于上界,则 β 增大为两倍,如果小于下界,则 β 缩小为 0.5倍。

PPO2,是PPO的简化,没有在loss 中加入KL距离,软性减小两分布的差异,而是直接对目标函数的大小进行剪切。
定义 ht(θ) 代表 importance weight。

PPO2 对ht 裁剪后的目标函数为:
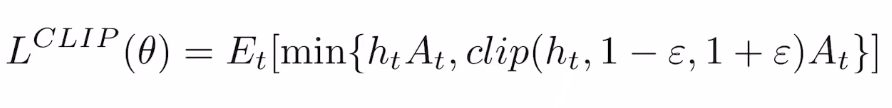
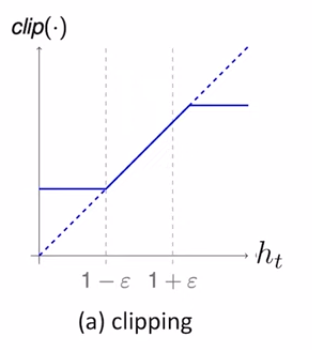
clip函数是限制上下界,函数图像如下:
那为何loss 中要加上min函数呢,直接的理解一下加入min 的必要性:
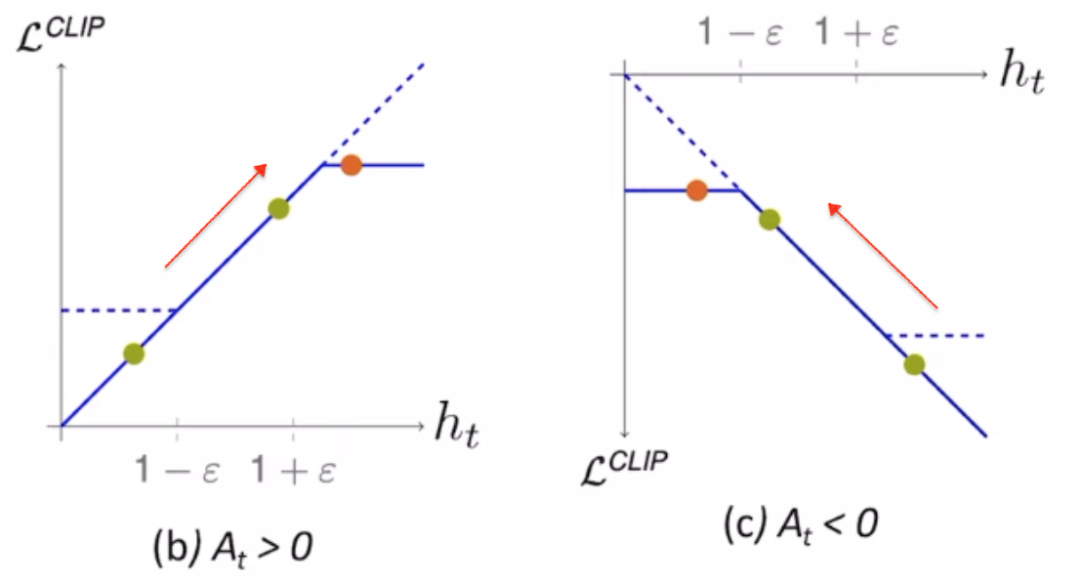
当A>0 时,这个action 是好的,其advantage function 为正,所以希望这个action的概率pθ(at|st)越大越好,这样蓝色曲线也是越来越大(objective function也越来越大),但是pθ(at|st)/pθ`(at|st)不能一直变大(要求相似),提高到1+ε就停了。
当A<0 时,这个action是坏的,其 advantage function 为负,所以希望这个action的概率pθ(at|st)越小越好,这样蓝色曲线也是越来越大(objective function也越来越大),但是pθ(at|st)/pθ`(at|st
) 不能一直变小(要求相似),缩小到1-ε就停了。
所以加入了min函数之后,在训练的动态过程中也保证了分布的差异不会变大。
PPO在原目标函数的基础上添加了KL divergence 部分,用来表示两个分布之前的差别,差别越大则该值越大,施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较小的损失函数。
TRPO 和 PPO 目的都是为了使得训练更加稳定,比如从下图中红色线的震荡更新,变成黑色线的稳定更新。
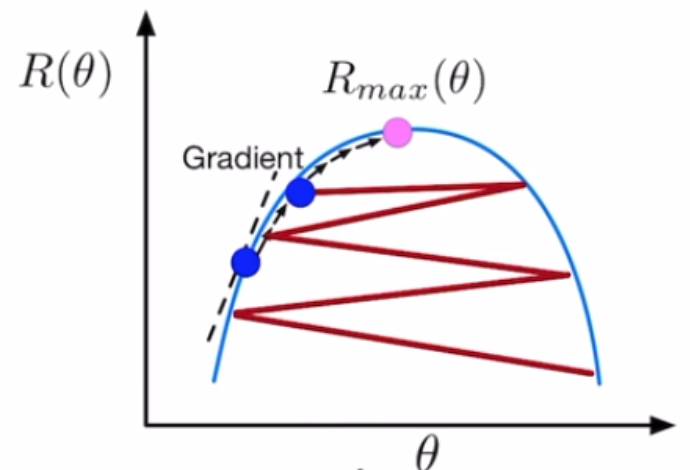
TRPO 与 PPO 之间的差别在于它使用了 KL divergence(KL散度) 作为约束,即没有放到式子里,而是当做了一个额外的约束式子,这就使得TRPO的计算非常困难,因此较少使用。

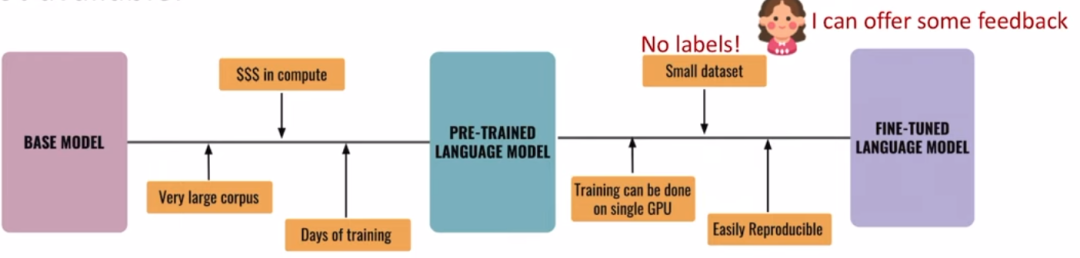
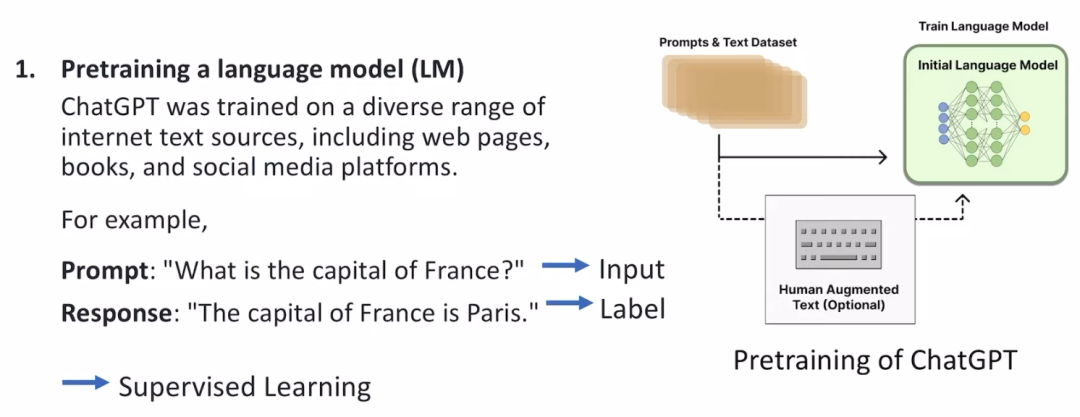
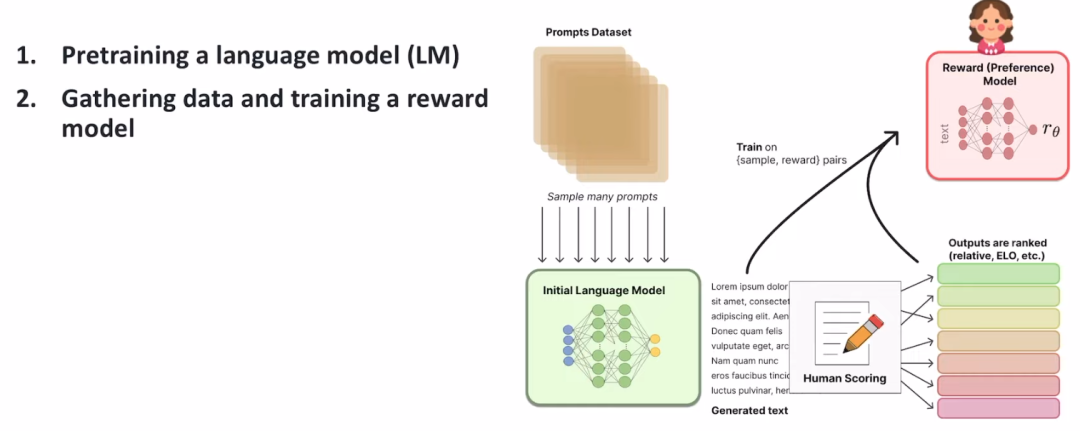
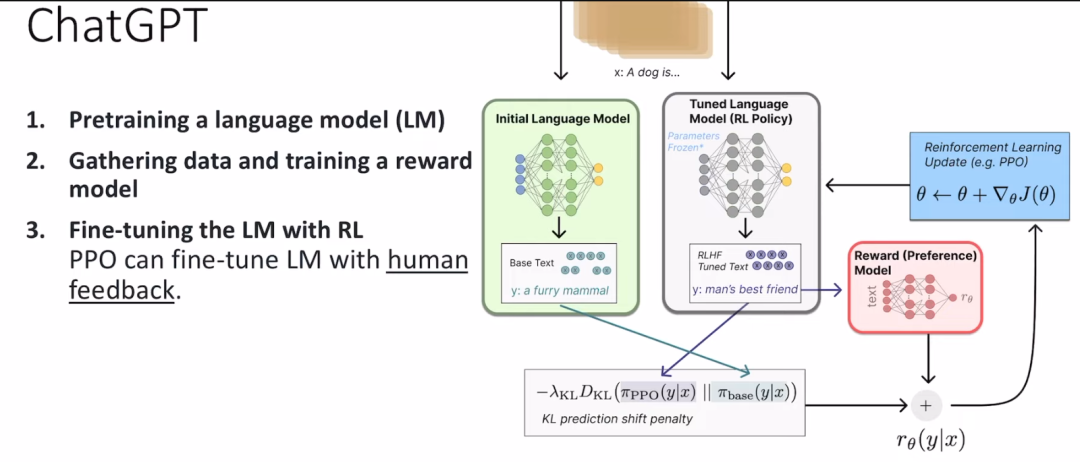
大模型经常采用pre-train + fine-tune 两阶段的训练方式,而在使用小训练集fine-tune 的过程中,可能并没有明确的label,这时候可以利用强化学习的方式,让人给出feedback。
chatgpt 引入了RLHF (reinforcement learning from human feedback),人类通过提供feedback,来帮助提升模型的准确度和泛化性。
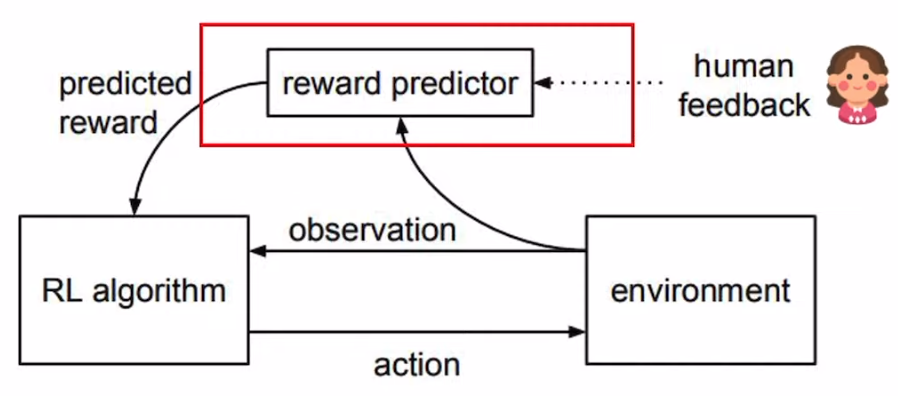
由于人的反馈需要思考,是非常慢的,肯定更不上fine-tune 中网络的训练,所以chatgpt 设计了一个reward predictor 模块,通过学习人类的历史行为来预估人的feedback。
chatgpt 的整个流程分为三步。
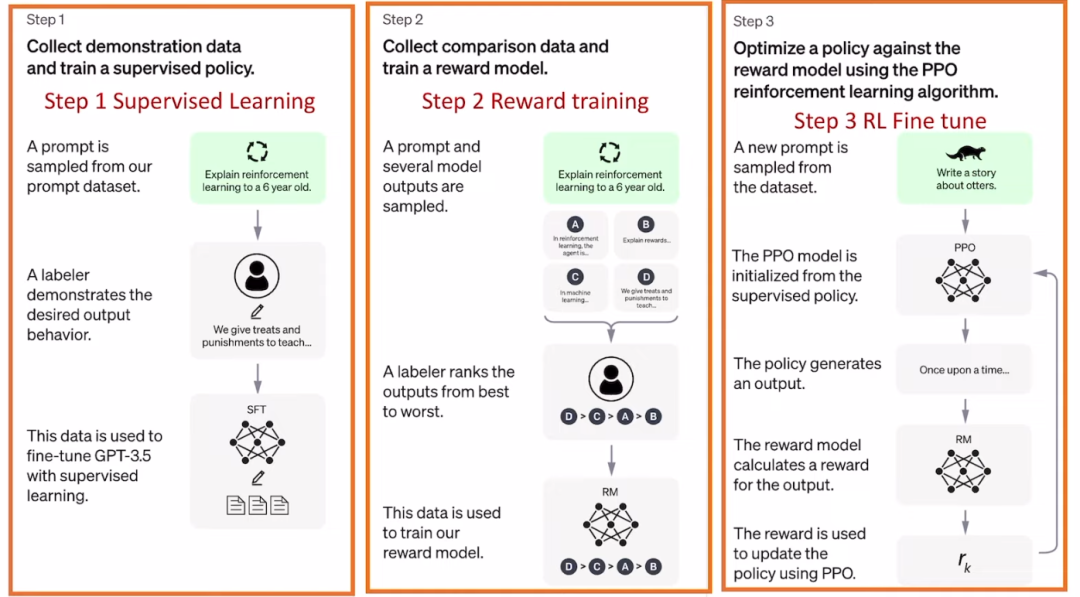
第一步是通过大量数据的有监督训练一个大模型
第二步是收集人的历史feedback,来训练一个打标签器
第三步是通过人的反馈,利用PPO 算法来fine-tune
参考:https://www.youtube.com/watch?v=IScp-mZ7iS0
https://blog.csdn.net/qq_36829091/article/details/83241600
https://blog.csdn.net/cindy_1102/article/details/87905272









